【学习笔记】【Pytorch】五、DataLoader的使用
- 学习地址
- 主要内容
- 一、DataLoader模块介绍
- 二、DataLoader类的使用
- 1.使用说明
- 2.代码实现
- 好的文章
学习地址
PyTorch深度学习快速入门教程【小土堆】.
主要内容
一、DataLoader模块介绍
介绍:分配数据集。
二、DataLoader类的使用
作用:数据加载器。组合数据集和采样器,在给定数据集上时可迭代的。
一、DataLoader模块介绍
from torch.utils.data import DataLoader
介绍:通常在使用pytorch训练神经网络时,DataLoader模块是整个网络训练过程中的基础前提且尤为重要,其主要作用是根据传入接口的参数将训练集分为若干个大小为batch size的batch以及其他一些细节上的操作。
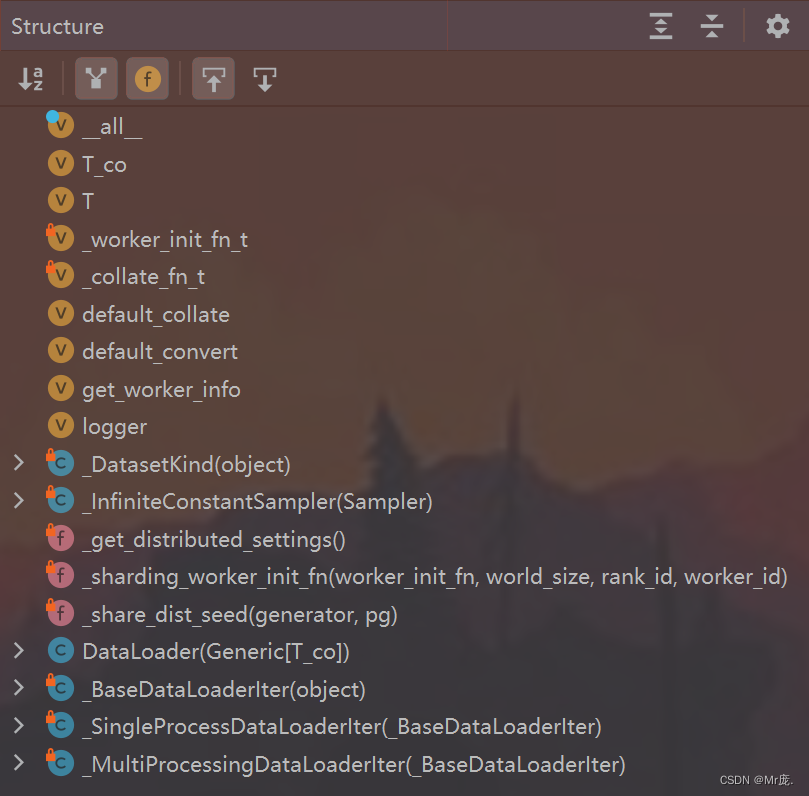
DataLoader.py文件结构:
二、DataLoader类的使用
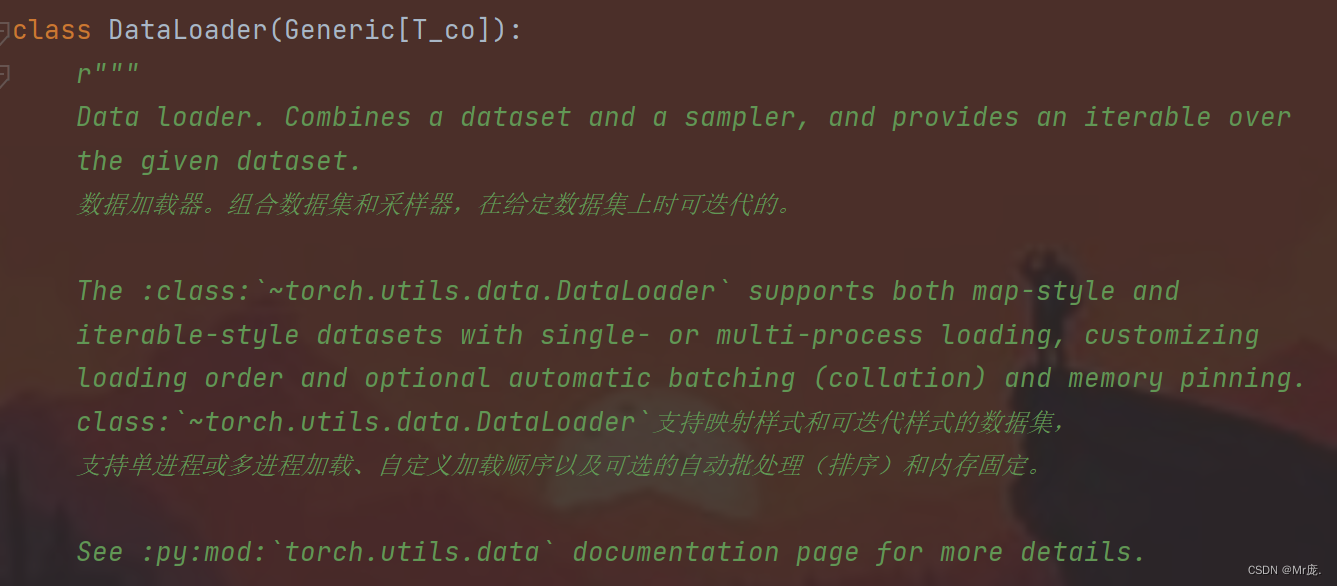
作用:数据加载器。组合数据集和采样器,在给定数据集上时可迭代的。
1.使用说明
【实例化】DataLoader(dataset: Dataset[T_co],
batch_size: Optional[int] = 1,
shuffle: Optional[bool] = None,
sampler: Union[Sampler, Iterable, None] = None,
batch_sampler: Union[Sampler[Sequence],
Iterable[Sequence], None] = None,
num_workers: int = 0,
collate_fn: Optional[_collate_fn_t] = None,
pin_memory: bool = False, drop_last: bool = False,
timeout: float = 0,
worker_init_fn: Optional[_worker_init_fn_t] = None,
multiprocessing_context=None, generator=None,
*, prefetch_factor: int = 2,
persistent_workers: bool = False,
pin_memory_device: str = “”)
-
作用:创建一个数据集的实例。
-
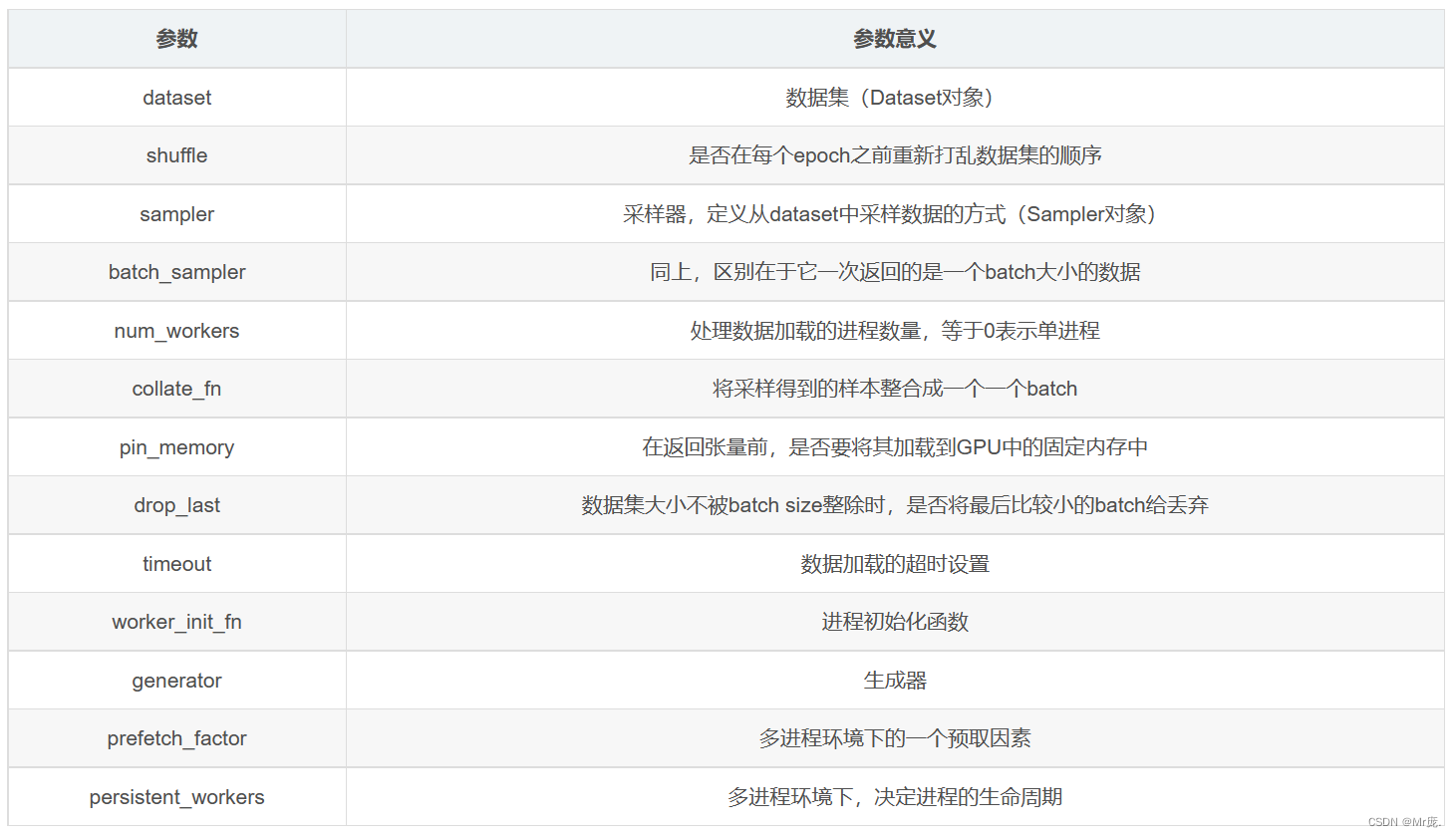
参数说明:
batch_size(int,可选):每个batch(批次)要加载多少个样本(默认值:1)。
-
例子:
# 创建 CIFAR10 实例,测试集(注:初始为PIL图片)
test_set = datasets.CIFAR10(root="./dataset", train=False, transform=transforms.ToTensor())
# 创建 DataLoader 实例
test_loader = DataLoader(dataset=test_set, batch_size=4, shuffle=True, num_workers=0, drop_last=False)
【可迭代对象】for data in DataLoader_object
- 作用:依次遍历每一个batch(批次),每一个batch有batch_size张图片。
for data in test_loader: # 可迭代对象
imgs, targets = data # 两个参数
# torch.Size([4, 3, 32, 32]),参数1-打包几张图片;参数2-图片通道;参数3、4-图片像素大小
print(imgs.shape)
# tensor([3, 3, 8, 9]),4张图片的分别的类别索引
print(targets)
2.代码实现
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
# 创建 CIFAR10 实例,测试集(注:初始为PIL图片)
test_set = datasets.CIFAR10(root="./dataset", train=False, transform=transforms.ToTensor())
# 创建 DataLoader 实例
test_loader = DataLoader(dataset=test_set, batch_size=4, shuffle=True, num_workers=0, drop_last=False)
# 测试数据集中的第一张图片及target
img, target = test_set[0] # __getitem__:下标获取类中对应元素值
print(img.shape)
print(target)
writer = SummaryWriter("dataloader_logs") # 创建实例
print("test_loader-len:", len(test_loader))
for epoch in range(2): # 演示不同epoch,数据集的顺序是否打乱(shuffle=True)
step = 0
for data in test_loader: # 可迭代对象
imgs, targets = data
# torch.Size([4, 3, 32, 32]),参数1-打包几张图片;参数2-图片通道;参数3、4-图片像素大小
print("\nimgs.shape:\n", imgs.shape)
# tensor([3, 3, 8, 9]),4张图片的分别的类别索引
print("\ntargets:\n", targets)
writer.add_images("Epoch {} test_data".format((epoch)), imgs, step) # 注:writer.add_image()适用于单张图片
step += 1
writer.close()
控制台输出:
torch.Size([3, 32, 32])
3
test_loader-len: 2500
imgs.shape:
torch.Size([4, 3, 32, 32])
targets:
tensor([1, 1, 4, 6])
imgs.shape:
torch.Size([4, 3, 32, 32])
targets:
tensor([9, 7, 8, 0])
....
....
....
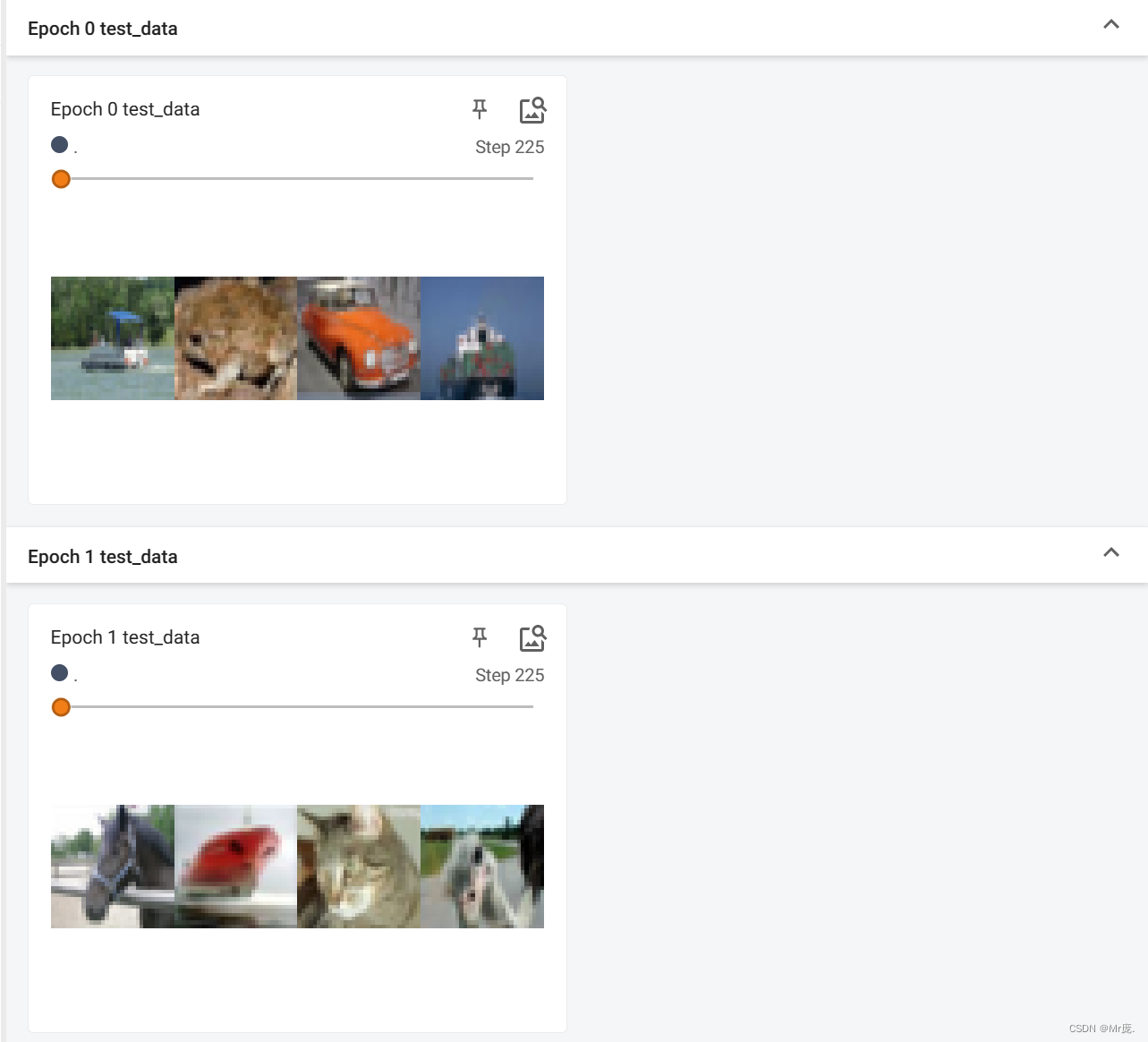
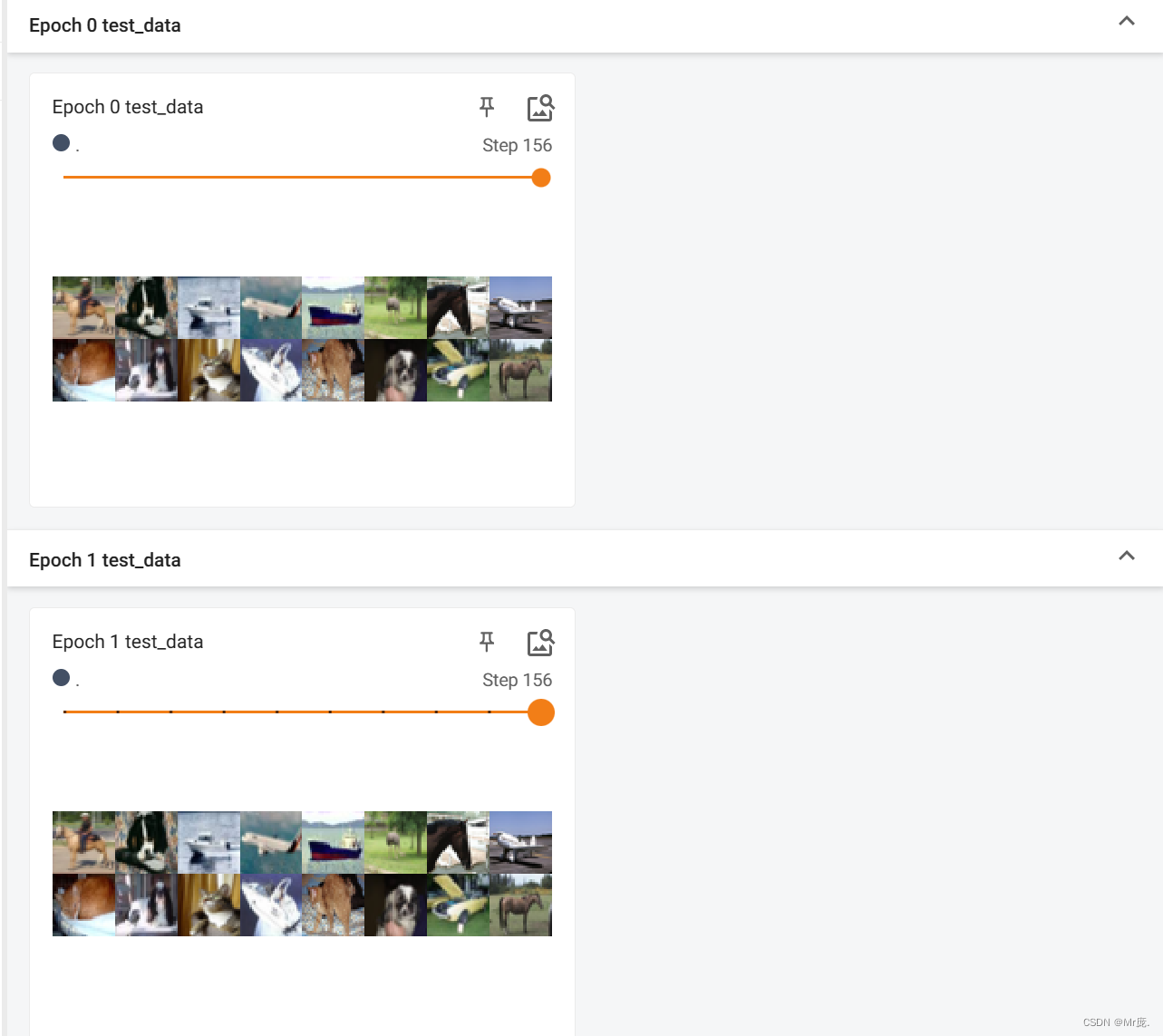
TensorBoard输出:
- 不同epoch,数据集的顺序打乱。(shuffle=True)
- 数据集大小不被batch size整除时,不将最后比较小的batch给丢弃。(drop_last=False)
- batch_size=4
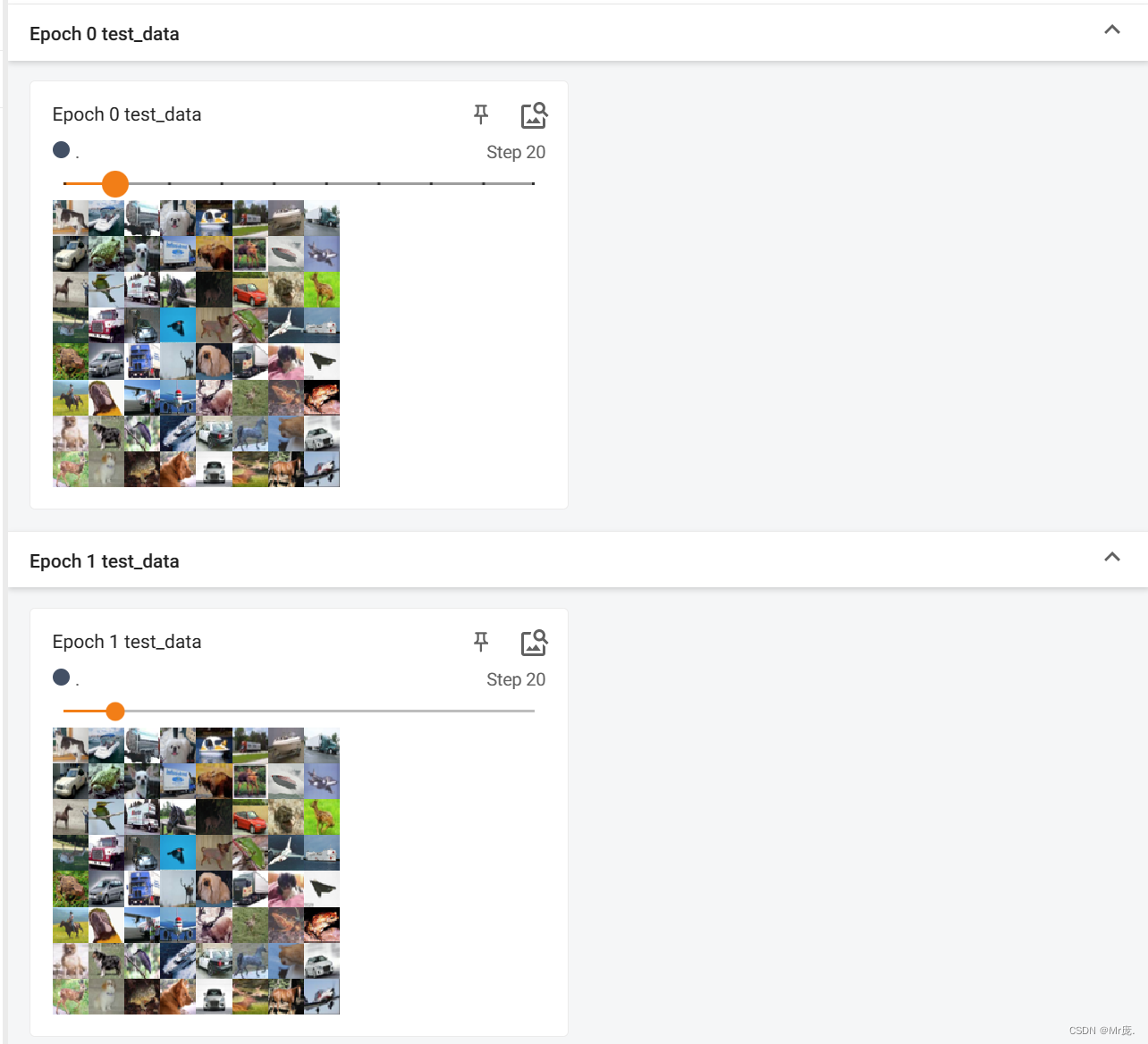
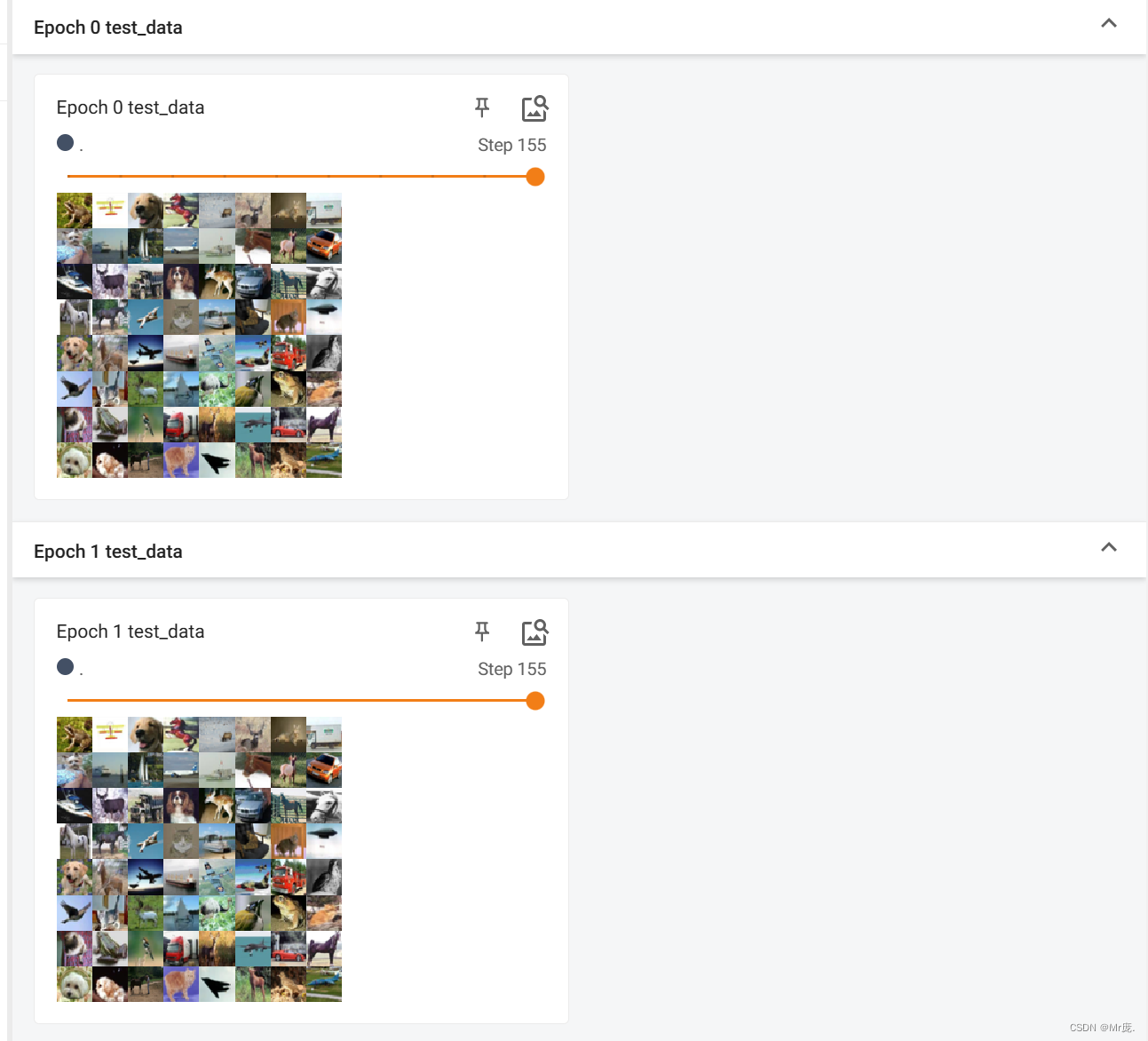
TensorBoard输出: - 不同epoch,数据集的顺序不打乱。(shuffle=False)
- 数据集大小不被batch size整除时,不将最后比较小的batch给丢弃。(drop_last=False)
- batch_size=64
TensorBoard输出:
- 数据集大小不被batch size整除时,将最后比较小的batch给丢弃。(drop_last=True)
好的文章
Pytorch源码解读——DataLoader模块