NoSQL数据库是用来解决性能问题的,分很多类。redis是NoSQL的一种。
NoSQL的引入:
随着Web2.0时代的到来。可以进行网络请求的不仅限与电脑。用户还可以通过手机端,平板甚至汽车等来进行网络请求。网络请求极具增加,增加了服务器CPU和内存的压力,如果还进行了数据库的访问,增加了IO的压力,导致效率下降。
于是分布式架构(集群)多台服务器,配合上反向代理如nginx,实现负载均衡,反向代理可以实现将请求均衡的发送到各各服务器中,但是由于可上网的工具和用户在不断增加,集群的方式同样可能出现上面的问题。而NoSQL可以很好解决上面的问题。
解决CPU和缓存问题:直接通过内存进行读取。
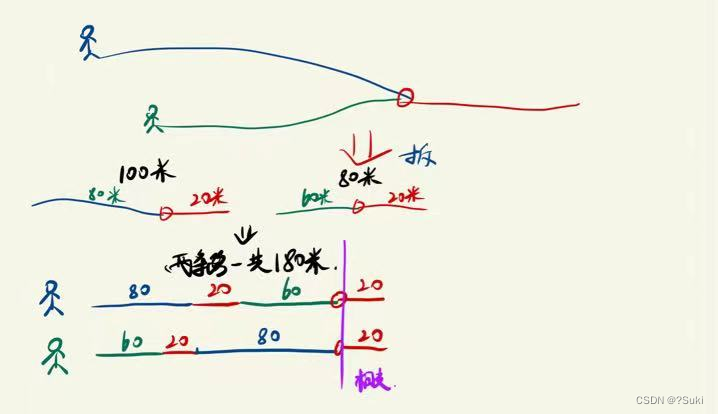
做成集群会有一个问题,session如何保存?比如:当请求经过nginx到了集群的第一台服务器。session保存在第一台服务器中,第二次请求,可能通过nginx到了集群的第二台服务器中,第二台服务器中没有保存用户session,认证不成功了。
几种解决方案:
1. 将用户信息保存到cookie中,保存在客户端,每次请求都带着cookie。但是会不安全。
2. 将session复制多份到集群其他 服务器中。 缺点:session数据冗余,空间浪费。
3. 将用户信息保存带NoSQL数据库中,需要验证用户信息,直接访问NoSQL数据库。有点直接在内存中,不需要进行IO操作,速度快。
解决IO问题:作为缓存使用。
当数据库中保存了大量的数据,服务器频繁的访问数据库会产生IO问题,使用NoSQL,将经常访问的数据保存到NoSQL中,可以减少IO操作。(还可以将特定的数据,使用特定的方式保存到特定数据库中)。
NoSQL数据库简介:
关系型数据库(通过业务逻辑存储有关联的数据):Mysql,Oracle等。
NoSQL:泛指非关系型数据库。不依赖业务逻辑方式存储,而是以简单的key-value的模式存储。提高了数据库的高可扩展性。
特点:
1. 不遵循SQL标准。
2. 不支持ACID,即事务的四个特性:原子性,一致性,隔离性,持久性。但是支持事务。
3. 远超SQL性能,因为不按照业务逻辑存储,而是按照key-value存储。
适用场景:
1. 对于数据读写高并发,比如电商的秒杀功能。
2. 海量数据的读写。
3. 数据的高可扩展性。
不适用场景:
1. 需要事务支持
2. 结构化存储,需要处理复杂的关系。因为是key-value形式保存的
3. 用不着sql和用不了sql的情况,考虑使用NoSQL。
常见NoSQL数据库:
| 数据库 | 特点 |
| Memcache | 1. 数据都在内存中,不支持持久化; 2. 支持简单的key-value形式,支持类型单一; 3. 一般作为缓存数据库辅助持久化的数据库。即辅助关系型数据库。 |
| Redis | 1. 几乎覆盖了Memcache的绝大部分功能 2. 数据都在内存中,数据可以持久化,主要用作备份恢复。 3. 除了支持简单的key-value模式,还支持多种数据结构的存储。比如:list,set,hash,zset等。 4. 一般作为缓存数据库辅助持久化的数据库。即辅助关系型数据库。 |
| mongoDB | 1. 高性能,开源,模式自由的文档型数据库,因为存储结构与json类似。 2. 数据都在内存中,如果内存不足,把不常用的数据保存到硬盘。 3. 虽然是key-value模式,但是对于value(尤其是json)提供了丰富的查询功能。 4. 支持二进制数据及大型对象。 5. 可以根据数据的特点代替RDBMS,成为独立的数据库。或者配合RDBMS,存储特定的数据。 |
常见存储方式:
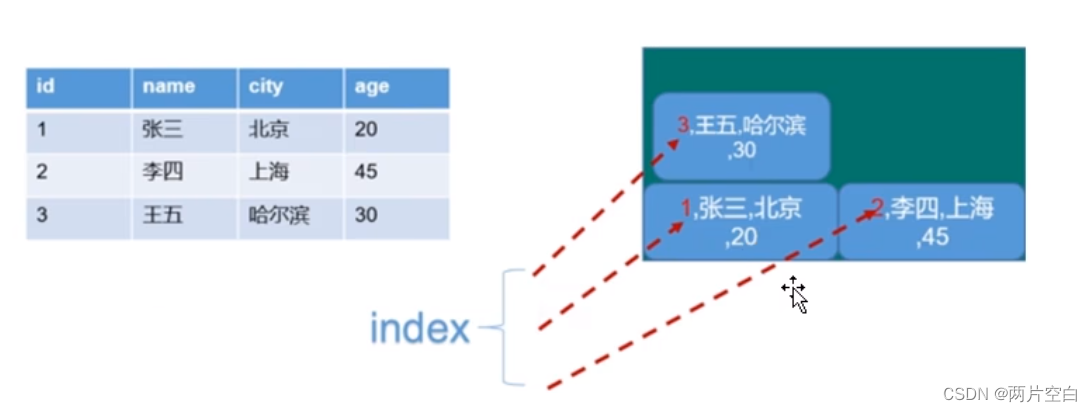
1. 行式数据库
将数据以行为单位保存起来。
优缺点:
进行查询:select * from users where id=3; 查询的会很快。只需要找到id等于3的这一行。
select avg(age) from users; 查询得会很慢,需要对每一行进行查询。
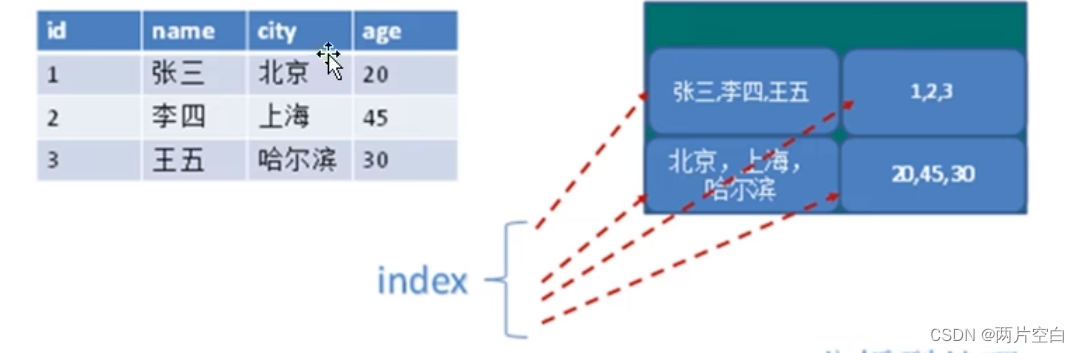
2. 列式数据库:
以列为单位进行存储。
优缺点:
进行查询:select * from users where id=3; 查询的会很慢。需要查询每一列
select avg(age) from users; 查询得会很快,只需要找到age这一列。
根据实际情况来寻找行存储方式还是列存储方式。目的都是为了提高效率。
图关系型数据库
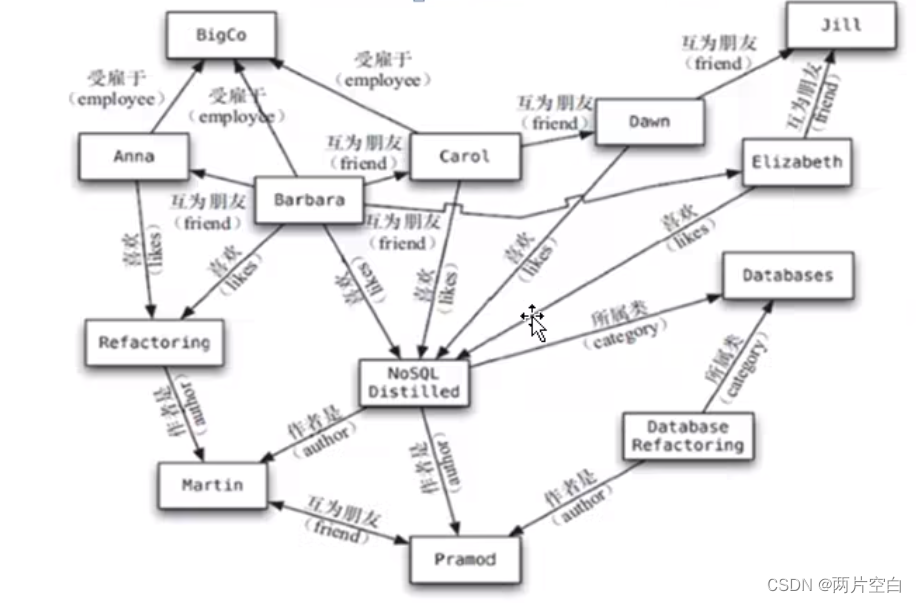
主要应用于:社会关系,公告交通网络,地图及网络拓扑。
比如:好友推荐系统,你好友的好友可以推荐成你的好友。
Redis的概述
1. 概述
- Redis是一个开源的key-value系统。
- 支持存储的value类型包括string(字符串),list(链表),set(集合),zset(有序集合)和hash(哈希类型)。
- 这些数据类型都支持push/pop,add/remove及提取交集和差集及更加丰富的操作。而且这些操作都是原子性的。
- Redis支持各种不同方式的排序。
- 为了保证效率,数据缓存在内存中。
- Redis会周期性的将数据更新到磁盘或者把修改操作写入追加的记录文件中。
- 实现了master-slave(主从)同步。
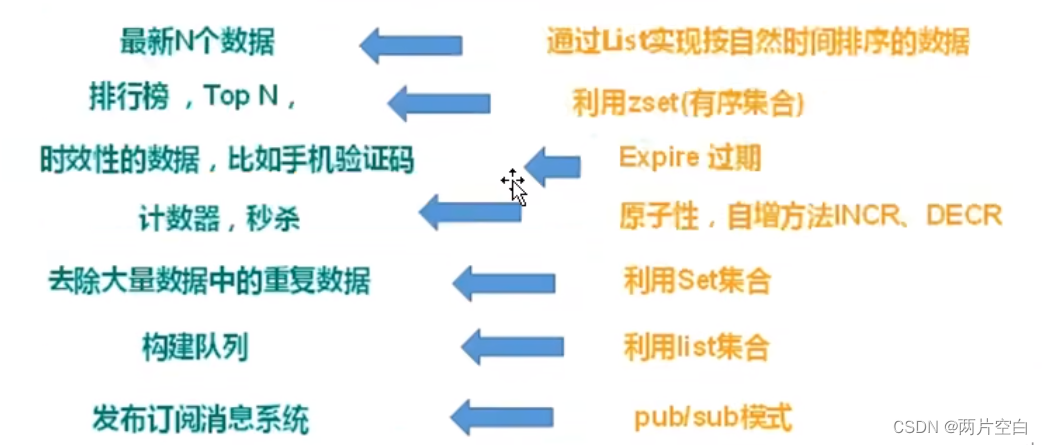
2. 配合关系型数据库做高速缓存
- 高频次,热门访问的数据,降低数据库IO。
- 分布式架构,做session共享。
3. 多样化数据结构存储持久化数据
4. 其他相关知识
Redis的默认端口是6379。
默认有16个数据库,类似数组下标从0开始,初始默认使用0号库。使用命令select <lib>来切换数据库。如:select 1。

统一密码管理,所有库使用同样的密码。
dbsize:查看库中key的数量。
flushdb:清空当前数据库。
flushall:通杀所有数据库。
Redis是单线程+多路IO复用技术:多路复用是指使用一个线程来检查多个文件描述符(Socket)的就绪状态,比如调用select,poll和epoll。传入多个文件描述符,如果有一个文件描述符就绪,则返回,否则阻塞直到超时。得到就绪状态后进行真正的操作可以在同一个线程中执行,也可以启动线程执行(比如线程池)。
6. Redis和Memcache的区别
Memcache:数据类型单一;数据保存在内存中,不支持持久化;使用的是多线程+锁的技术。
Redis:数据类型多样;数据保存在内存中,但支持周期性将数据保存到硬盘或者记录日志中;使用单线程+多路IO复用技术。
Redis键值操作
1. 常用5大数据类型
- 字符串(string)
- 列表(list)
- 集合(set)
- 哈希(hash)
- 有序集合(zset)
2. 键(key)操作
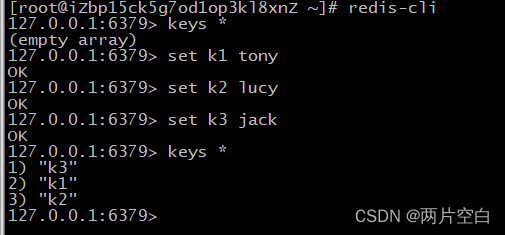
- keys *:查看当前库中所有的key。
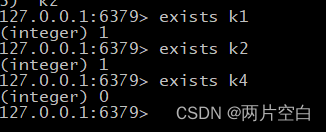
- exists key:判断key是否存在。
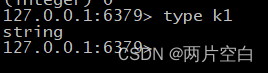
- type key:查看key的类型。
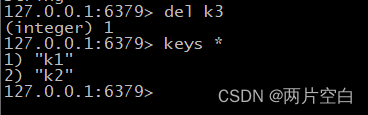
- del key:删除指定key的数据。
- unlink key:根据value选择非阻塞删除。仅将keys从元数据中删除,真正的删除会在后续异步操作。使用unlink key时,虽然返回已经删除,但是实际并没有删除,会在后续异步进行删除。
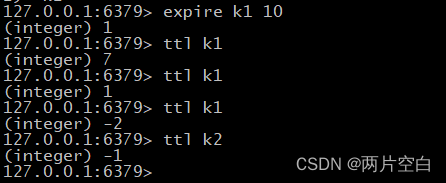
- expire key second:为指定的key设置过期时间。key过期表示,对应值已经取不到了。
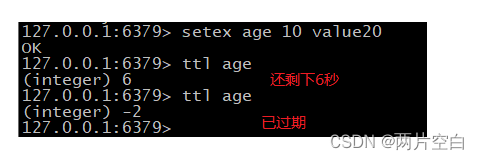
- ttl key:查看还有多少秒过期。-1表示永不过期,-2表示已经过期。
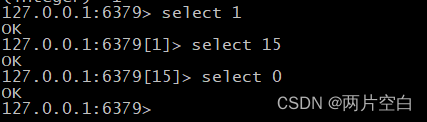
- select num:选择使用哪个库。redis中有16个库,默认时用的时0号库。
- dbsize:查看当前库中有多少数量的key。
- flushdb:清空当前库。
- flushall:通杀全部库。
3. 数据类型介绍
数据类型都是指value的数据类型。
3.1 string类型
3.1.1 简介
string是redis最基本的类型,是二进制安全的,意味着redis的string可以包含任何数据,比如:jpg图片或者序列化的对象。一个redis中的字符串的value最多512M.
3.1.2 数据结构
redis中的string类型数据结构为一个简单的动态字符串,是可以修改的字符串,内部结构类似与C++中的vector,采用预分配冗余空间的方式来减少空间的频繁分配。

当设置一个长度为len的字符串时,实际申请的空间会大于len。由于字符串可以进行修改,当len大于capacity时,会进行扩容。当字符串长度小于1M时,一般扩容为当前空间的2倍。如果超过1M,扩容一次只会多扩1M空间。并且字符串最大长度为512M。
注意:这里说的是value值类。
3.1.2 常用命令
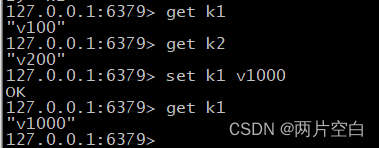
- set key value:在当前数据库中添加键值对,或者修改键值对。
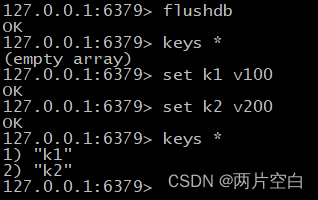
- get key:查询键值对。
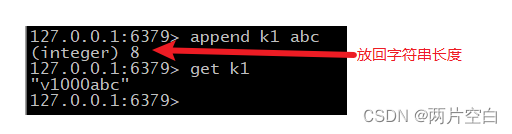
- append key value:将给定的value追加到key对应value末尾,返回对应追加后对应字符串长度。
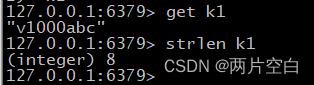
- strlen key:获得值的长度。
- setnx key value:也是设置值的。但是只能设置不存在的值,值存在的话,设置会失败。
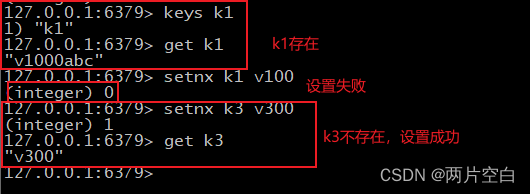
- incr key:将key对应的数字值增1。只能对数字类型操作,如果为空,新增值为1。
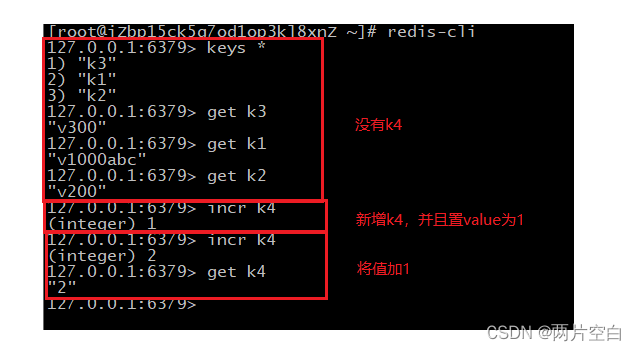
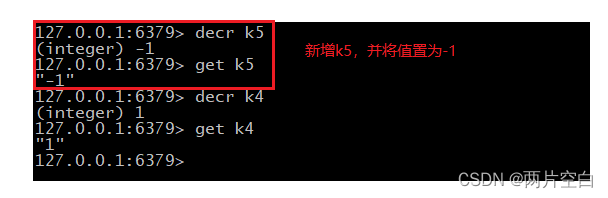
- decr key:将key保存的数字值减1。只能对数字类型操作,如果为空,新增值为-1。
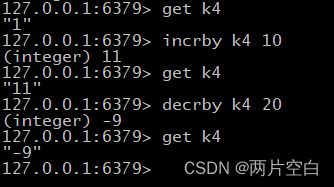
- incrby/decrby key 步长:将key保存的数字值增/减步长值。只针对数字类型。
原子性:
概念:原子操作是指不会被线程调度机制打断。这个操作一旦开始,一直到运行结束,中间不会切换到另外的线程。
- 在单线程中,能够在单条指令中完成的操作都可以认为是“原子操作”,因为中断只发生在指令之间。
- 在多线程中,不能被其他进程(线程)打断的操作就叫原子操作。
Redis单命令的原子性主要得益于Redis的单线程。
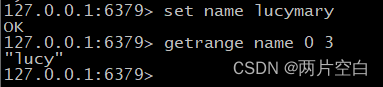
- mset key1 value1 key2 value2...:同时设置多个key-value键值对。
- mget key1 value1 key2 value2...:同时获取一个或者多个value。
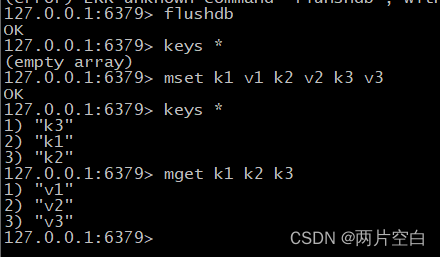
- msetnx key1 value1 key2 value2...:同时设置一个或者多个key-value键值对,当且仅当所有给定的key不存在时。如果设置的key中有一个存在,该命令会执行失败。因为是原子性的,当有一个失败,全部都失败。
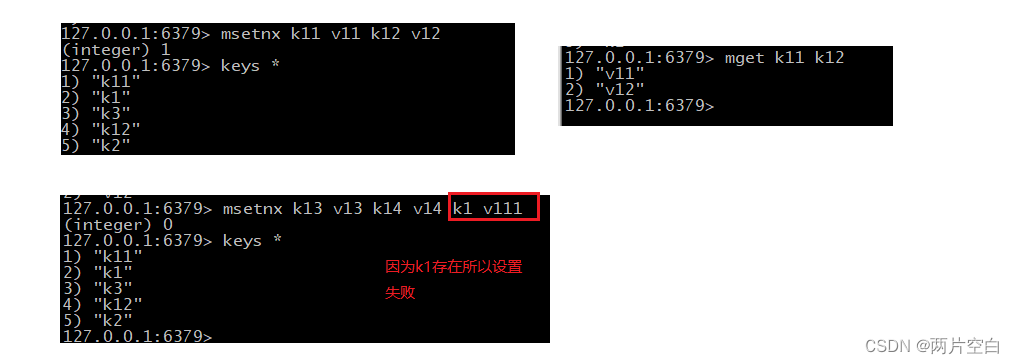
- getrange key 起始位置 结束位置:获得值的范围。包括起始位置和结束位置。
- setrange key 起始位置 value:用value覆盖key对应value从起始位置开始的字符串。

- setex key 过期时间 value:在设置值的同时设置过期时间,单位为秒。
- getset key newvalue:以新值换旧值。设置新值的同时获得旧值。
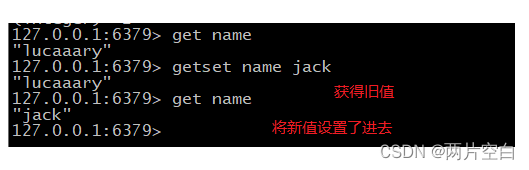
3.2 列表List类型
3.2.1 简介
单键多值。
Redis列表是一个简单的字符串列表,按照插入顺序排序,你可以添加一个元素到列表的头或者尾部。
它的底层实际是一个双向链表,对两端操作的性能很高,通过索引下标操作中间的元素性能会比较差。

3.2.2 常用命令
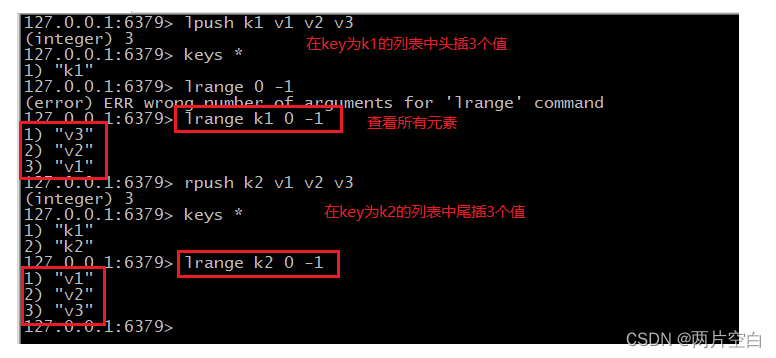
- lpush/rpush key value1 value2...:从左边或者右边插入一个或者多个值,即头插/尾插一个获知多个值。
- lrange key start stop:按照索引下标获得元素。(从左到右)。查看元素。
lrange key 0 -1 查看所有元素。0表示头部第一个元素,-1表示尾部第一个元素。
- lpop/rpop key count 从头部/尾部吐出count 个元素,count不填默认1个。值在键在,值光键完。

- rpoplpush key1 key2:从key1列表尾取出一个值,插入到key2列表头。

- lindex key index:取到key下标中索引为index的值。从头到尾,索引从0开始。

- llen key:获取key列表的长度。

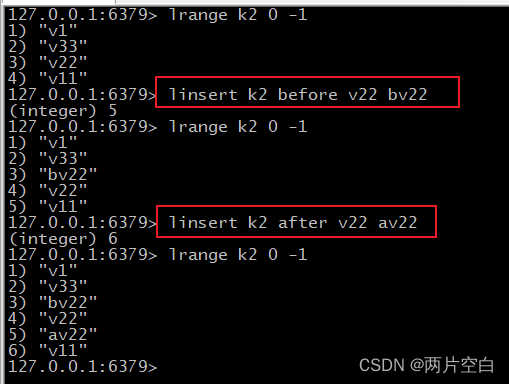
- linsert key before/after value newvalue:在key列表的value前/后插入newvalue。
- lrem key n value:在key列表中从左到右,删除n个value值。

- lset key index value:将列表key中索引为index的值替换成value。

3.2.3数据结构
List的数据结构为快速列表quickList。
首先在元素较少的情况下会使用一块连续的内存空间。这个结构是ziplist,也就是压缩列表。它将所有的元素连续存储,分配的是一块连续空间。
当数据量比较多的时候才会改成quicklist。
由于普通链表需要附加指针的空间太大,比较浪费空间,比如:这个链表中保存一个int类型的数据,结构里还需要保存前一个结点和后一个节点的指针。

Redis将链表和ziplist结合起来组成了quicklist,也就是将多个ziplist使用双向指针串起来使用,即满足快速的插入和删除性能,又不会出现太大的空间冗余。
3.3 集合set
3.3.1 简介
Redis中的set对外提供的功能与list类似是一个列表的功能,不同之处在于set是可以自动去重的。当你需要存储一个列表数据,但是又不希望出现重复数据,set是一个很好的选择。并且set提供了判断某个成员是否在一个set集合中的接口,list中没有。
Redis的set是string类型的无序集合(list是按照插入的顺序,set不是按照插入顺序),它的底层是一个value为null的hash表,所以添加,删除,查找的时间复杂度是O(1)。
3.3.2 常用命令
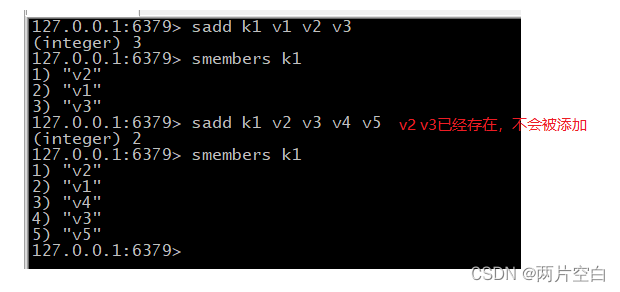
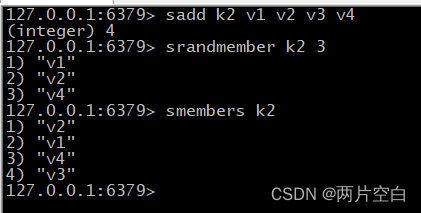
- sadd key value1 valu2...:将一个或者多个value元素加到集合key中,已经存在的元素将被忽略。
- smembers key:取出key集合的所有值。
- sismenber key value:判断集合key中是否存在value,存在返回1,不存在返回0。
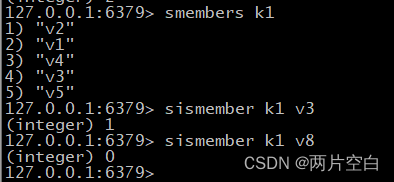
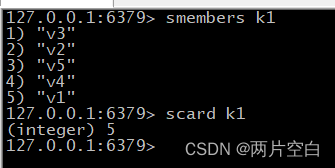
- scard key:返回集合key中元素的个数。
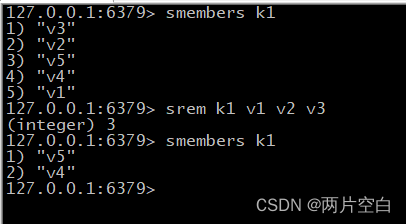
- srem key value1 value2...:删除集合中的某个元素。
- spop key:随机从集合中拿出一个值。当集合中没有值了,集合也就不存在了。

- srandmember key n:随机从集合中随机取出n个值,不会从集合中删除。
- smove src des value:把集合中的一个值,从一个集合移动到另外一个集合。
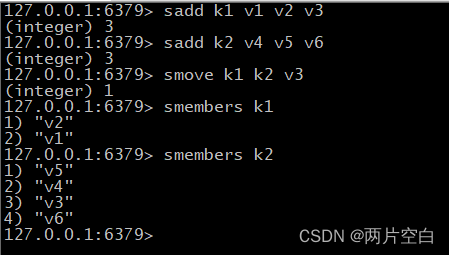
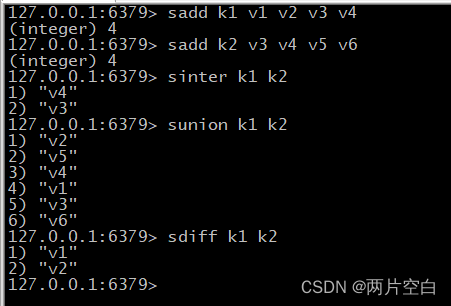
- sinter key1 key2:返回两个集合的交集元素。
- sunion key1 key2:返回两个集合的并集元素。
- sdiff key1 key2:返还两个交集的差集元素。(key1存在的,不包含key2的)。
3.3.3 数据结构
Set集合的数据结构是使用哈希表实现的。相当于C++中的set。
3.4 Hash(哈希)
3.4.1 简介
Redis中的hash是一个键值对的集合。
Redis中的hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。类似于C++中的map。
结构说明:
redis是key:value结构,哈希结构不同的在于value也是field:value结构。
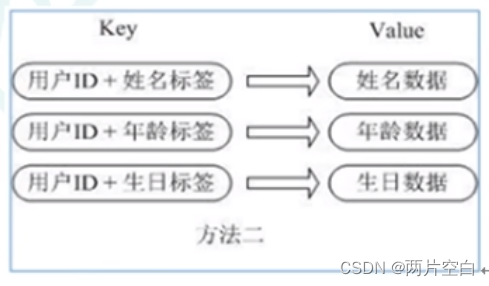
比如:需要存储用户信息{id=1,name=zhangsan,age=20},有三种保存方式。
1. 自定义key,将用户信息转化为字符串作为value进行保存。
缺点:当需要修改用户信息时:需要将数据全部取出,进行反序列化,修改,再序列化,再进行保存。
2.自定义key,用户信息分开保存。
缺点:用户数据冗余,实际保存的是一个信息。
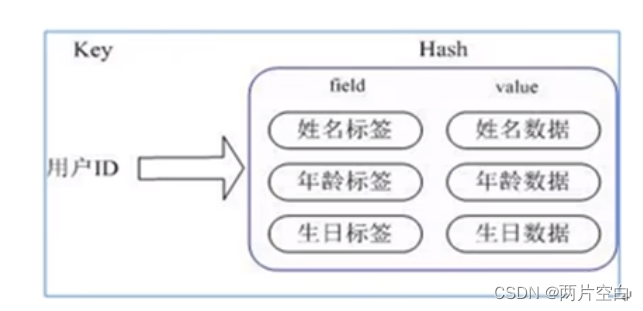
3. 使用Hash哈希
优点:用户数据不冗余,并且修改数据时,不需要进行反序列化和序列化操作。

3.4.2 常用命令
- hset key field value:给key哈希中给field键赋值value。
- hget key field:从哈希key中取出field键的值。
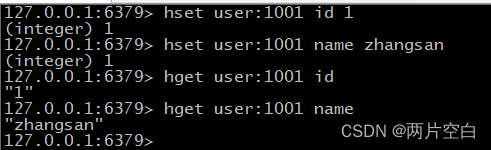
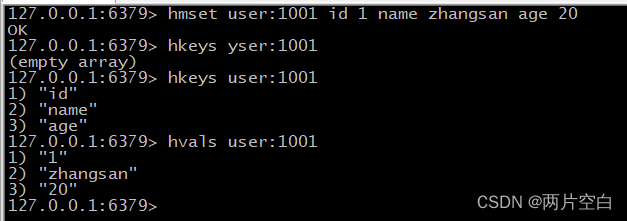
- hmset key field1 value1 field2 value2...:批量设置哈希key的值。
- hexists key field:查看哈希key中键field是否存在。

- hkeys key:查看key哈希中所有的field。
- hvals key:查看key哈希中所有的value。
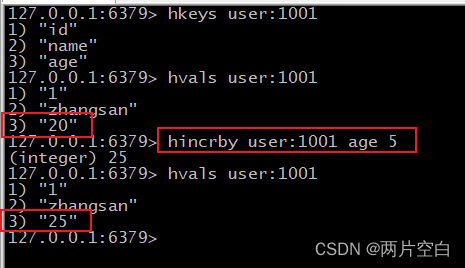
- hincrby key field num:将哈希表key中的键key的值增加num。
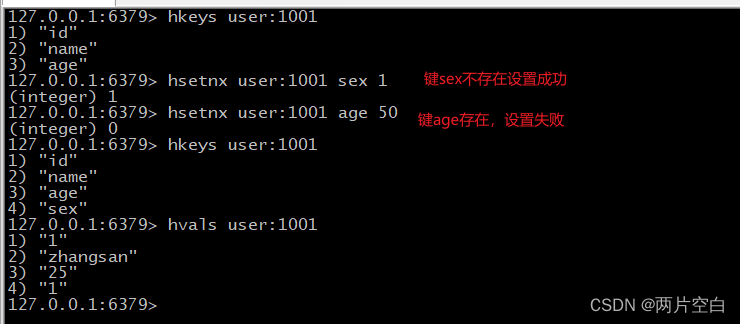
-
hsetnx key field value:将哈希表key中的键field的值设置为value。仅当键field不存在时才会设置成功。
3.4.3 数据结构
redis的哈希有两种数据结构ziplist和hashtable。
当field-value数据量少时,使用ziplist,否者使用hashtable。不是结合使用的。
3.5 Zset(有序集合)
3.5.1 简介
Redis的有序结合Zset和普通集合set非常类似,区别是一个有序且没有重复元素的字符串集合。
有序集合的每一个成员都关联了一个评分(score)。这个评分被用作按照从最低分到最高分的方式排序集合成员。集合的成员是唯一的,但是评分可以重复。
因为元素是有序的,所以你可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。
访问有序集合的中间元素也是很快的,因此你能够使用有序集合作为一个没有重复成员的智能列表。
3.5.2 基本命令
- zadd key score1 value1 score2 value2...:将一个或者多个member元素及score加入到有序集合key中。
- zrange key start end [withscores]:返回有序集合key中,下标在start和stop中的元素。带上withscores可以让分数一起和值返回。
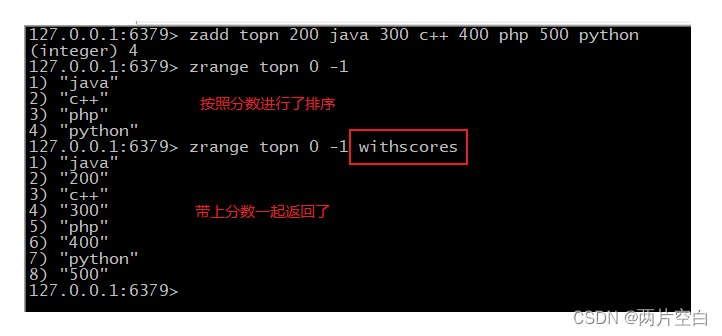
- zrangebyscore key minscore macscore [withscores] [limit offset count]:返回有序集合key中,所有score介于且包括minscore和maxscore之间的成员,有序集合按照score值递增从小到大排序。
- zrevrangebyscore key maxscore minscore [withscores] [limit offset count]:同上,改为按照score从大到小排序。
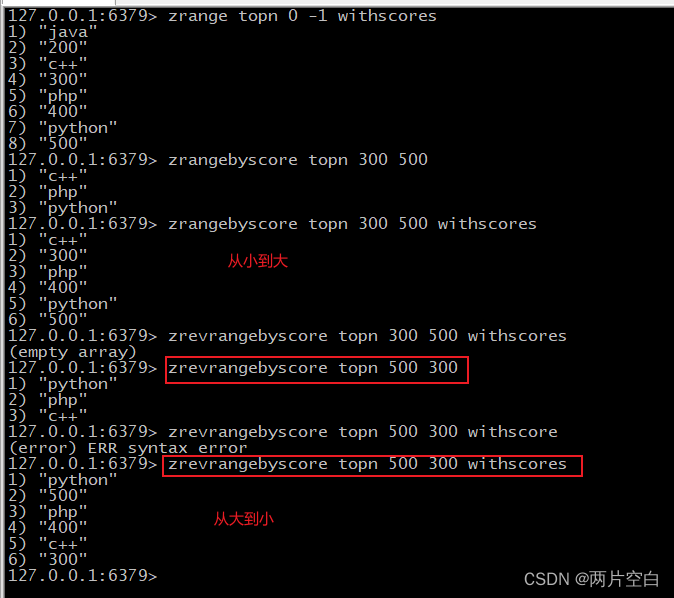
- zincrby key num value:给有序集合key为元素value的score加上增量num。

- zrem key value:删除有序集合key下的元素value。

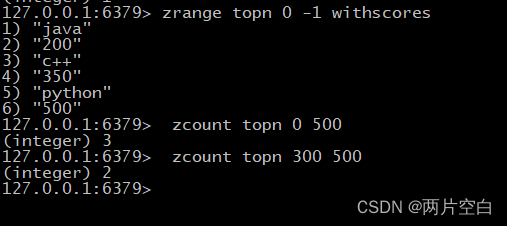
- zcount key minscore maxscore:统计该集合分数区间内的元素个数。包括分数区间。
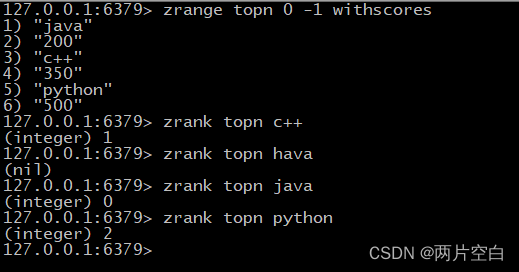
- zrank key value:返还该值在集合中的排名(索引)。从0开始。
3.5.3 数据结构
Redis中的zset(有序列表)提供了一个非常特别的数据结构,一方面它等价于C++中的map数据结构,map的key是zset的value,map的value是zset的score。另一方面,它有类似与C++的set,内部的元素可以按照权重score进行排序。可以得到每个元素的名次,还可以通过score的范围来获取元素的列表。
zset底层使用了两个数据结构。
- hash:hash的作用就是关联元素value和权重score,保证value的唯一性,可以通过value找到对应的score值。
- 跳跃表:跳跃表的作用在于给元素value排序,根据score的范围获取元素的列表。
3.5.4 跳跃表(跳表)
1. 简介
对于Redis有序集合的底层实现,可以使用数值,平衡树,链表等。但是,数组不便于元素的插入和删除。平衡树或者红黑树虽然效率高,但是结构复杂。链表查询需要遍历所有的节点,效率低。Redis使用的是跳跃表,跳跃表效率堪比红黑树,实现比红黑树简单。
2. 实例
对比有序链表和跳跃表,从链表中查出51。
(1) 有序链表
要查找51,需要从第一个元素开始依次查找并比较才能找到。需要6次比较。

(2) 跳跃表
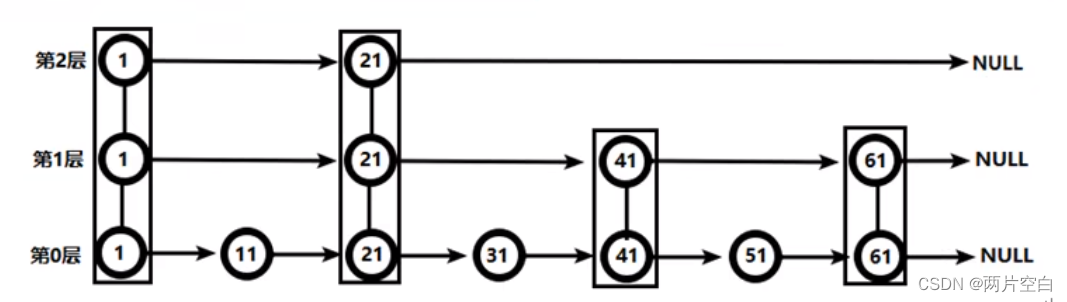
先从最高层进行查找,当节点值小于需要查找的值时,查找当前层的下一个节点。
当找到当前层的节点值比查找值大,找前一个节点的下一层。
当找到当前层的null还没有找到,就找null前一个节点的下一层的节点。
按照上面的规则在当前层查找,直到找到对应值,或者没有层数了,即没找到。
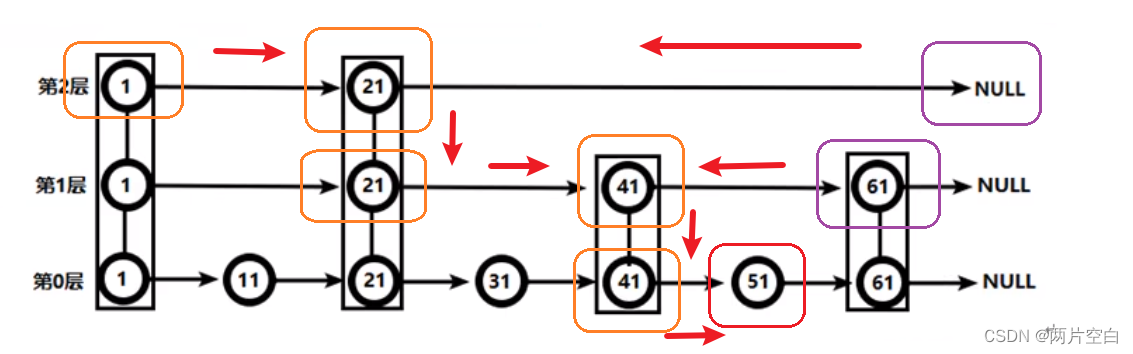
按照上面的规则。在跳跃表中找到51,只需要进行4次查找。
虽然从上面看,好像比较了8次,当时当数据多时,和跳跃表合理,效率还是很高的。