原理大家可以参考这篇文章,我这边主要介绍几个公式和整体源码理解。

- 提出了多尺度可变形注意力(Multi-scale Deformable Attention, MSDA).基于此设计了 DETR 特有的利用多尺度特征检测的流程,对之后的很多工作有指导意义。
- 提出了两阶段 DETR 的思路,利用编码器输出特征来初始化解码器的 query及其对应的位置。
- 最早提出在解码器层之间优化 query对应位置的思路(iterative box refinement)
公式理解
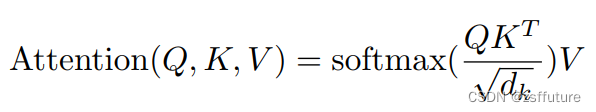

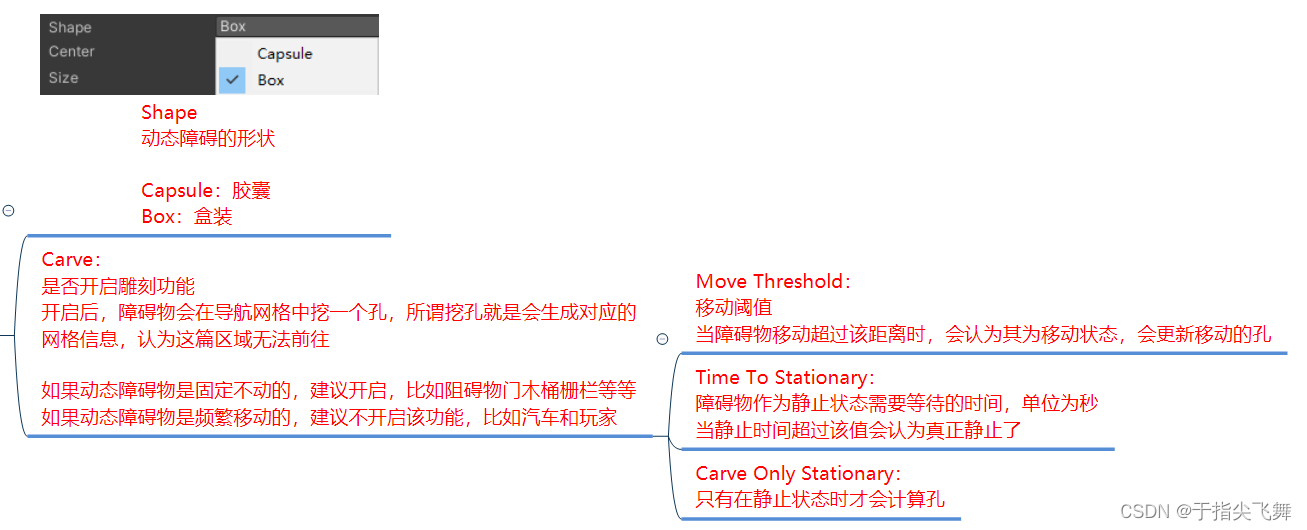
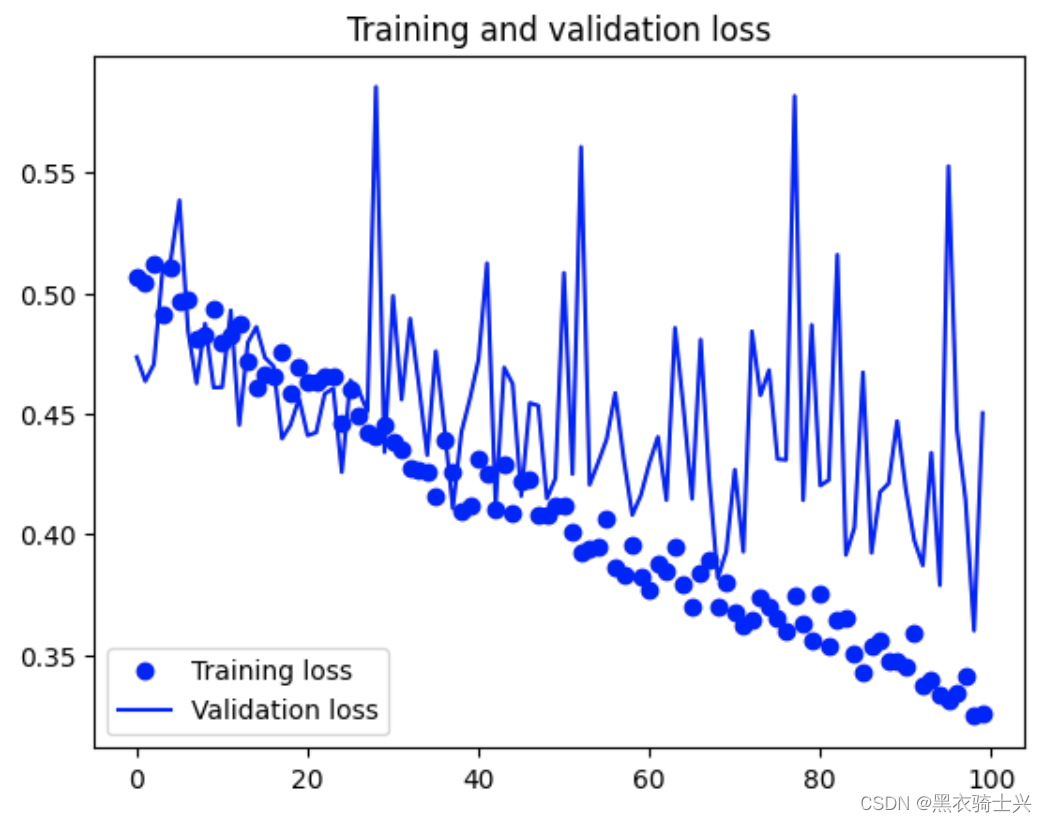
其实大家看到最多的注意力公式是第一个,第一个是针对一句话或者一个通道或者一张图片而言,即Q代表所有的query,K代表所有的键key,V代表所有的value,但是对于DeformableDETR他们的公式也是类似的,只是他针对的是一个query进行描述了注意力机制,这是从单个query的角度进行描述,通过计算输入的query和整张特征图关系进行计算注意力。把所有的query和在一起就是我们大家都熟悉的第一个公式了,这里大家需要明确的是,自注意力机制的qkv都是来源一个特征图,每个q都会和所有的可以计算然后乘上v得出结果,大家看到常见的公式其实是所有的q组成的矩阵,DeformableDETR只是拿出了一个q进行定义,下面就仔细分析DeformableDETR的针对一个query是怎么描述注意力机制的。
第二个公式的输出是MultiHeadAttn 这个是代表多头注意力机制的公式,大家可以观察蓝色的注释,可以发现就是需要计算得到query特征而下标就是query的索引即第几个query,
就是特征图可以理解为key和value,当然query也在
中的,
中的k代表
特征的索引,
就是取出第k个的
特征而
就是代表可以训练的权重,此时
可以看做是value即
,
可以看到公式其实就是QK的计算了,uv是对应的权重,结果和
相乘就是注意力值了,至于m和
其实就多头的意思,因此整个公式代表代表了一个query特征的计算,因为根据注意力机制我么你知道每个query都会和所有的key进行点积,然后再和value计算出最后的值
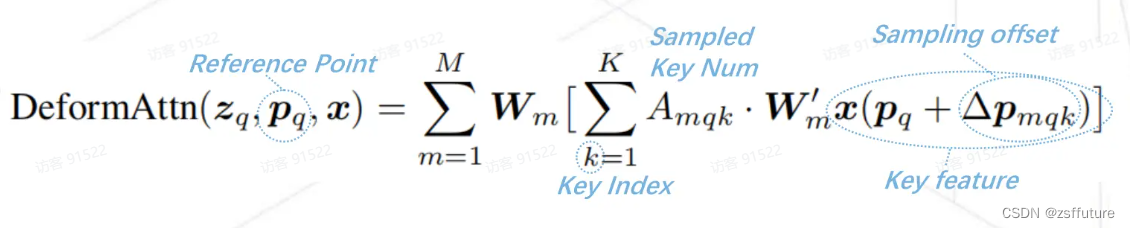
上面的公式在MultiHeadAttn公式的基础上怎么了和
然后得到了
,而这个公式就是DeformableDETR的核心,我们仔细看看,首先大家需要理解DeformableDETR的初衷是为了解决attention的计算量大的问题,计算量大主要是因为每个query都需要和整个特征图的key进行计算,计算量和特征图的平方成正比,因此DeformableDETR的降低计算量的策略是觉得query并不需要和所有的key进行计算,query只和特征图的几个key有关,其他的相关性不大,因此DeformableDETR设计者认为模型只需要自适应的选择几个更有利学习特征的key即可,因此上面的公式也是这个从发点,
计算位置参考点,该值其实就是query的在特征图的位置,
就是相对于参考位置的偏移,因此
就是对应的特征索引,此时的K就是选择相对于参考位置的几个特征图的key进行计算,
就是这样的过程,至于怎么选择这个参考点
和
,简单来说
参考位置是来源于query的在特征所得位置,
是预测相对于参考位置的偏移量,后续在仔细解释。
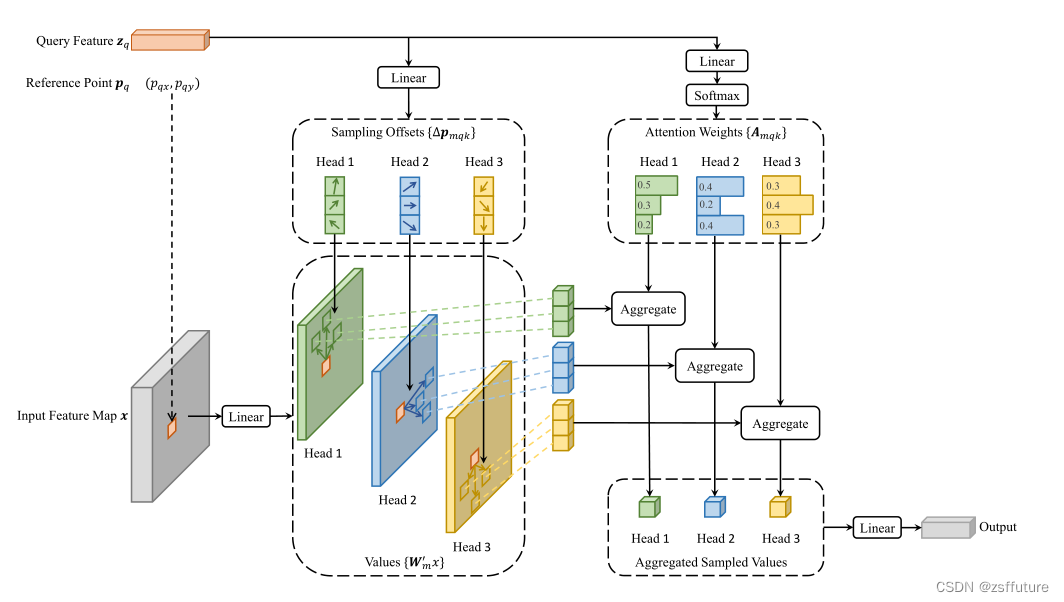
从上图可以发现是从input feature Map x 获取的一个特征,参考点就是
的位置,大家需要仔细理解和观察。上面是单尺度的可变性注意力机制,简单来说就是通过参考位置让模型自己寻找关键的位置去聚合有用的信息,这样就可以降低大量的计算量。
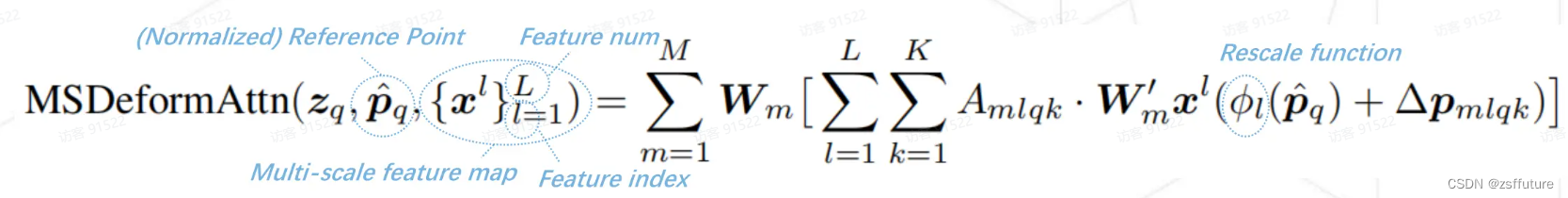
上面的公式是在单尺度基础上增加了多尺度的特征融合,因为通过resnet50的特征图可以多尺度的,而
是在一个尺度的特征平面进行计算了,为了利用不同尺度的特征信息,DeformableDETR采用了多尺度的特征聚合方法,但是因为每个尺度的特征大小不同,对应的特征位置不同,因此模型有个对齐的操作,体现在上面的公式是
的函数上,后续根据代码解释。
我简单看了一下代码,还挺麻烦,我自己看完了,但是还有基础无法理解,代码后续再补,