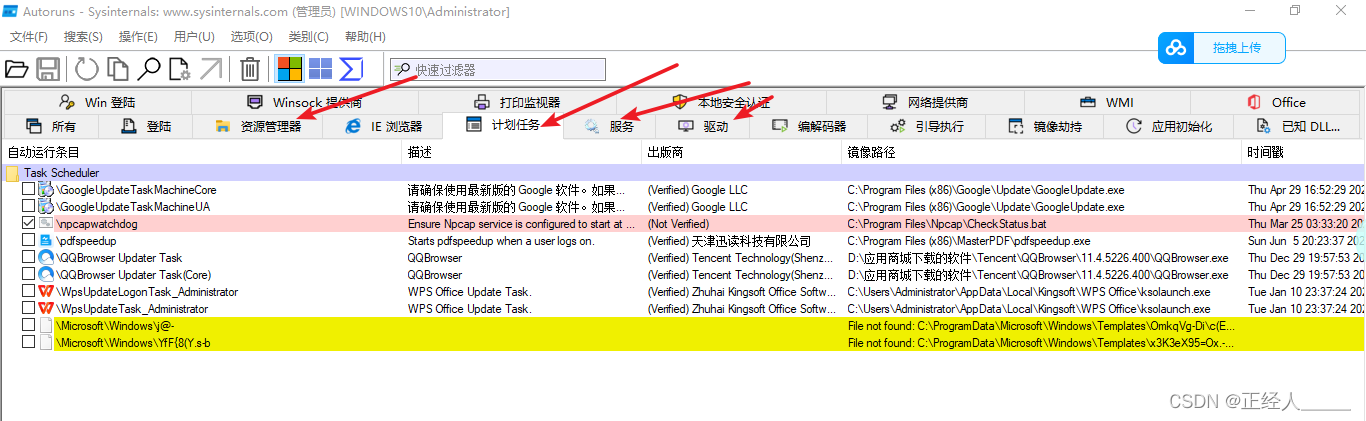
Request
Request 继承体系
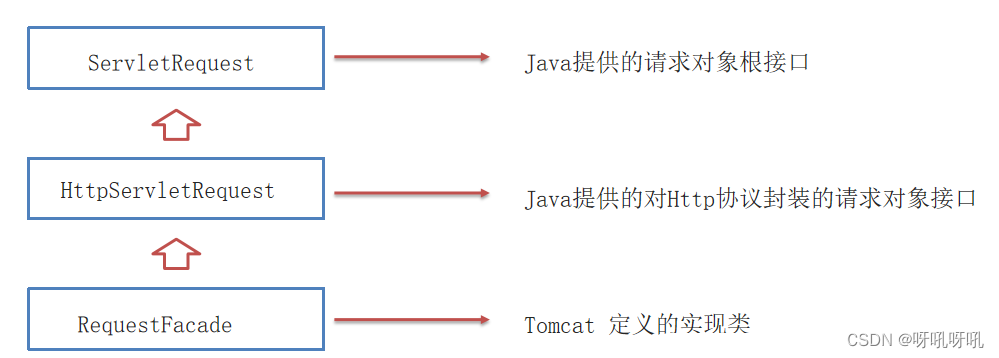
Tomcat解析请求数据,封装为request对象,并且创建request对象传递到service方法中
。Java提供了接口,tomcat的RequestFacade提供了实现。
Request 获取请求数据
请求数据分为3部分:
请求行:
GET /request-demo/req1?username=zhangsan HTTP/1.1
String getMethod():获取请求方式: GET
String getContextPath():获取虚拟目录(项目访问路径): /request-demo
StringBuffer getRequestURL(): 获取URL(统一资源定位符):http://localhost:8080/request-demo/req1
String getRequestURI():获取URI(统一资源标识符): /request-demo/req1
String getQueryString():获取请求参数(GET方式): username=zhangsan&password=123
请求头:
浏览器客户端版本信息:User-Agent: Mozilla/5.0 Chrome/91.0.4472.106
请求体:
username=superbaby&password=123
ServletInputStream getInputStream():获取字节输入流
BufferedReader getReader():获取字符输入流reader.readLine为读取一行。
Request 通用方式获取请求参数
GET请求获取方式:String getQueryString()
POST请求获取方式:BufferedReader getReader()
通用方式获取请求参数:
Map<String, String[ ]> getParameterMap():获取所有参数Map集合(之所以值是字符串数组是因为)
String[ ] getParameterValues(String name) :根据名称获取参数值(数组)
String getParameter(String name):根据名称获取参数值(单个值)
网关过滤器里,给请求放header:
//存储header中
ServerHttpRequest serverHttpRequest = request.mutate().headers(httpHeaders -> {
httpHeaders.add("userId", userId + "");
}).build();
//重置请求
exchange.mutate().request(serverHttpRequest);
Tomcat7的乱码问题
根源在于浏览器采取UTF-8编码,而tomcat定义好了ISO-8859-1的编码方式(Tomcat 8.0 之后,已将GET请求乱码问题解决,设置默认的解码方式为UTF-8)
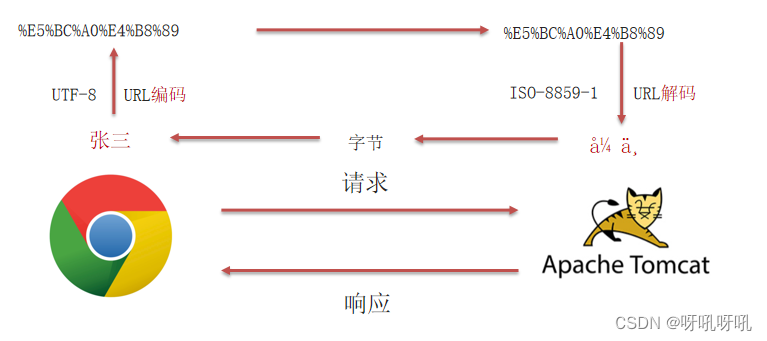
post请求解决乱码:
req.setCharacterEncoding(“UTF-8");
get/post通用解决乱码:
new String(获取到的菜蔬.getBytes("ISO-8859-1"),"UTF-8");
拓展:URL编码时,每个汉字占三个字节
1. 将字符串按照编码方式转为二进制
2. 每个字节转为2个16进制数并在前边加上%
请求转发(forward)
一种在服务器内部的资源跳转方式。
转发方式:
req.getRequestDispatcher("/访问路径").forward(req,resp);
请求转发的服务间共享数据:
使用Request对象
void setAttribute(String name, Object o):存储数据到 request域中;
Object getAttribute(String name):根据 key,获取值
void removeAttribute(String name):根据 key,删除该;键值对。
请求转发特点:
浏览器地址栏路径不发生变化;
只能转发到当前服务器的内部资源
一次请求,可以在转发的资源间使用request共享数据。
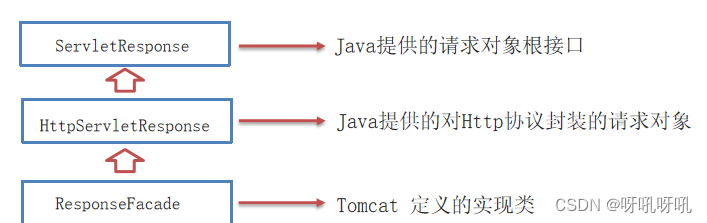
Response
Response继承体系
响应数据分为3部分:
响应行:HTTP/1.1 200 OK
void setStatus(int sc) :设置响应状态码
响应头:Content-Type: text/html
设置响应头键值对:void setHeader(String name, String value)
响应体:<html><head>head><body></body></html>
PrintWriter getWriter():获取字符输出流
ServletOutputStream getOutputStream():获取字节输出流
Response 的重定向功能(Redirect)
实现方式:
resp.setStatus(302);
resp.setHeader(“location”,“要跳转的路径");
简化的写法就是:
resp.sendRedirect("要跳转的路径");
重定向特点:
浏览器地址栏路径发生变化;
可以重定向到任意位置的资源(服务器内部、外部均可);
两次请求,不能在多个资源使用request共享数据。
路径问题(加不加虚拟路径)
浏览器使用:需要加虚拟目录(项目访问路径)
服务端使用:不需要加虚拟目录
Response 响应字符数据
先获取字符流。
PrintWriter writer = resp.getWriter();
writer.write("aaa");
这个流不需要关闭,随着响应结束,response对象销毁,由服务器关闭。
中文数据乱码:
原因通过Response获取的字符输出流默认编码:ISO-8859-1
resp.setContentType("text/html;charset=utf-8");
Response 响应字节数据
案例,向前端输出一张图片。
ServletOutputStream outputStream = resp.getOutputStream();
outputStream.write(字节数据);
借助io工具类复制流:
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
IOUtils.copy(输入流,输出流);
@GetMapping("/getPic")
public void getPic(HttpServletRequest req, HttpServletResponse res) throws IOException {
FileInputStream fio = new FileInputStream("C:\\Users\\YUAN\\Desktop\\tii.webp");
ServletOutputStream os = res.getOutputStream();
IOUtils.copy(fio, os);
fio.close();
os.close();
}



![[Python逆向] 逆向Pyinstaller打包的exe文件源码及保护](https://img-blog.csdnimg.cn/db9958375cd4439abfda11b891789261.png)