目录
前言
1、激活函数的定义与作用
2、激活函数的性质
二、常见的激活函数
2.1 Sigmoid函数:
1. 作用
2. 优点
3. 缺点
4. 数学公式
5.Sigmoid函数实现及可视化图像
2.2 Tanh函数
1. 函数定义
2.优点
3.缺点
4.Tanh函数实现及可视化图像
2.3ReLU 函数 :
1.函数定义
2.优点
3.缺点
4.ReLU函数图像及可视化
2.4 Leaky ReLU函数
1.函数定义
2.优点
3.缺点
4.函数图像及可视化
2.5 PReLU函数
1.函数定义
2.优点
3.缺点
4.函数图像及可视化
2.6 ELU函数
1.函数定义
2.优点
3.缺点
4.函数图像及其可视化
2.7 SELU函数
1.函数定义
2.优点
3.缺点
4.函数图像及其可视化
2.8 Swish函数
1.函数定义
2.优点
3.缺点
4.函数图像及其可视化
2.9 Mish函数
1.函数定义
2.优点
3.缺点
4.函数图像及其可视化
2.10 Softmax函数
1.函数定义
2.优点
3.缺点
4.函数图像及其可视化
2.11 GELU函数
1.函数定义
2.优点
3.缺点
4.函数图像及其可视化
2.12 Maxout函数
1.函数定义
2.优点
3.缺点
4.函数图像及其可视化
总结
博主介绍:✌专注于前后端、机器学习、人工智能应用领域开发的优质创作者、秉着互联网精神开源贡献精神,答疑解惑、坚持优质作品共享。本人是掘金/腾讯云/阿里云等平台优质作者、擅长前后端项目开发和毕业项目实战,深受全网粉丝喜爱与支持✌有需要可以联系作者我哦!
🍅文末三连哦🍅
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
前言
深度学习中的激活函数是人工神经网络中非常重要的组成部分,它们负责将神经元的输入映射到输出端。激活函数在人工神经网络模型学习、理解复杂和非线性函数时起着关键作用,它们将非线性特性引入网络中。下面,我将详细讲解激活函数的定义、作用、常见的激活函数及其优缺点。

1、激活函数的定义与作用
激活函数(Activation Function)是在人工神经网络的神经元上运行的函数,它的主要作用是对神经元的输出进行缩放或转换,使其具备非线性特性。这种非线性特性对于神经网络来说至关重要,因为它能够帮助网络学习和表示复杂的数据模式。此外,激活函数还能增强网络关注的特征,减弱不关注的特征,从而优化网络的性能。
2、激活函数的性质
-
非线性性:激活函数引入了非线性,使得神经网络可以学习复杂的非线性关系。如果没有激活函数,多层神经网络将等效于单个线性层,无法捕捉到非线性特征。
-
可微性:激活函数通常要求是可微的,因为在反向传播算法中需要计算梯度来更新网络参数。绝大多数常见的激活函数都是可微的,但有些如ReLU,在零点不可导,但是可以在零点处约定一个导数值。
-
单调性:激活函数最好是单调的,这样可以保证损失函数是凸函数,使得优化问题更容易求解。大多数常用的激活函数都是单调的。
-
输出范围:不同的激活函数有不同的输出范围。有些激活函数的输出范围在0,1之间,适用于二元分类问题,比如sigmoid函数;有些输出范围在0,
之间,如ReLU函数,适用于回归问题;还有一些输出范围在[-1, 1]之间,如tanh函数,也适用于分类和回归问题。
-
饱和性:激活函数的饱和性指的是在某些输入范围内,函数的梯度很小,导致梯度消失问题。一些激活函数在输入很大或很小时会饱和,导致梯度接近于零,这会减缓学习速度或导致梯度消失。因此,一些激活函数被设计成在一定范围内不会饱和,如Leaky ReLU、ELU等。
-
计算效率:激活函数的计算效率也是一个考虑因素。一些激活函数的计算比较复杂,会增加训练和推理的时间成本,而有些激活函数计算较简单,如ReLU。
-
稀疏性:有些激活函数具有稀疏性,即在网络训练过程中,部分神经元的输出会趋向于零,这可以起到正则化的作用,有助于减少过拟合。
-
归一化:归一化的主要思想是使样本自动归一化到零均值、单位方差的分布,从而稳定训练,防止过拟合。

二、常见的激活函数
2.1 Sigmoid函数:
Sigmoid函数的图像呈现一种S形曲线,当输入值较大时,趋近于1;当输入值较小时,趋近于0。虽然Sigmoid函数在某些情况下被广泛使用,但由于其存在的梯度消失问题,随着深度学习的发展,其在隐藏层中的应用逐渐被ReLU、Leaky ReLU、ELU等激活函数所取代。
1. 作用
- 将输入值映射到一个区间
之间,实现非线性变换。
- 常用于二分类问题的输出层,将输出值转化为概率值。
- 在浅层网络中,用于处理二元分类任务。
2. 优点
- 具有很好的数学性质,具备平滑性和连续性。
- 输出范围在
之间,可以被解释为概率。
- 相对简单,易于理解和实现。
3. 缺点
- 容易出现梯度消失问题:在函数两端,梯度接近于零,导致在反向传播过程中,参数更新缓慢,特别是在深度网络中。
- 输出不是以零为中心的:这可能导致网络的收敛速度变慢。
- 饱和区域梯度较小:在输入较大或较小时,梯度会变得很小,导致训练过程中的梯度消失问题。
4. 数学公式
Sigmoid激活函数的数学公式如下:
其中,是自然对数的底数,
是输入值。
5.Sigmoid函数实现及可视化图像
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(x):
return sigmoid(x) * (1 - sigmoid(x))
# 生成一系列输入值
x_values = np.linspace(-10, 10, 100)
# 计算Sigmoid函数及其导数的值
y_values_sigmoid = sigmoid(x_values)
y_values_derivative = sigmoid_derivative(x_values)
# 可视化Sigmoid函数及其导数
plt.figure(figsize=(10, 6))
plt.plot(x_values, y_values_sigmoid, label='Sigmoid', color='blue')
plt.plot(x_values, y_values_derivative, label='Sigmoid Derivative', color='red', linestyle='--')
plt.title('Sigmoid Function and Its Derivative')
plt.xlabel('Input')
plt.ylabel('Output')
plt.grid(True)
plt.legend()
plt.show()函数(蓝线)及导数(红线)图像如下:

2.2 Tanh函数
1. 函数定义
Tanh函数(双曲正切函数),它具有 Sigmoid 函数的形状,但输出值的范围在之间。Tanh函数的定义为:
2.优点
- 零中心性:Tanh函数的输出以0为中心,当输入为负时,输出接近-1;当输入为正时,输出接近1。相比于ReLU函数,Tanh函数的零中心性有助于网络学习更好的特征表示。
- 非线性:Tanh函数是一个非线性函数,可以使神经网络具有更强的拟合能力,有助于学习复杂的非线性关系。
- 平滑性:Tanh函数是连续可导的,具有平滑的曲线,有利于梯度的计算和优化。
3.缺点
- 梯度消失问题:虽然Tanh函数相对于Sigmoid函数在输出范围上增加了一倍,但在输入很大或很小时,Tanh函数仍然会出现饱和现象,导致梯度消失问题。
- 计算开销:Tanh函数的计算相对于ReLU函数来说稍微复杂一些,因为它涉及到指数运算。在大规模数据和深度网络中,可能会带来一些计算开销。
4.Tanh函数实现及可视化图像
def tanh(x):
return (np.exp(x) - np.exp(-x)) / (np.exp(x) + np.exp(-x))
def tanh_derivative(x):
return 1 - np.square(tanh(x))
# 生成一系列输入值
x_values = np.linspace(-10, 10, 100)
# 计算Tanh函数及其导数的值
y_values_tanh = tanh(x_values)
y_values_derivative = tanh_derivative(x_values)
# 可视化Tanh函数及其导数
plt.figure(figsize=(10, 6))
plt.plot(x_values, y_values_tanh, label='Tanh', color='blue')
plt.plot(x_values, y_values_derivative, label='Tanh Derivative', color='red', linestyle='--')
plt.title('Tanh Function and Its Derivative')
plt.xlabel('Input')
plt.ylabel('Output')
plt.grid(True)
plt.legend()
plt.show()
函数(蓝线)及导数(红线)图像如下:

2.3ReLU 函数 :
1.函数定义
ReLU(Rectified Linear Unit)其定义为:
即当输入大于0时,输出等于输入
;当输入
小于等于0时,输出为0。
2.优点
- 非线性:ReLU函数是一个非线性函数,允许神经网络学习和表示非线性关系,使得神经网络能够更好地拟合复杂的数据。
- 计算高效:ReLU函数的计算非常简单,只需要进行比较和取最大值操作,因此计算速度较快,适用于大规模数据和深度网络。
- 稀疏激活性:在ReLU函数中,当输入小于等于0时,输出为0,因此部分神经元会处于非活跃状态,实现了稀疏激活性,有助于网络的泛化能力和参数的稀疏性。
- 缓解梯度消失问题:相较于一些其他激活函数,ReLU函数在正区间的导数为1,因此可以缓解梯度消失问题,使得网络更容易训练。
3.缺点
- Dead ReLU问题:当输入小于等于0时,ReLU函数的输出为0,导致相应的神经元不会激活,称为“死亡神经元”问题。在训练过程中,这些“死亡神经元”可能无法被激活,导致相应的参数无法更新,从而使得这些神经元对于网络的预测结果没有贡献。
- 输出不是零中心:由于ReLU函数在负值区域输出为0,因此它的输出不是以零为中心的,这可能导致一些问题,比如梯度更新的方向性较强。
- 不适用的场景:虽然ReLU函数在大多数情况下表现良好,但它并不适用于处理一些数据分布不均匀或者具有较大的负值区间。
4.ReLU函数图像及可视化
def relu(x):
return np.maximum(0, x)
def relu_derivative(x):
return np.where(x > 0, 1, 0)
# 生成一系列输入值
x_values = np.linspace(-10, 10, 100)
# 计算ReLU函数及其导数的值
y_values_relu = relu(x_values)
y_values_derivative = relu_derivative(x_values)
# 可视化ReLU函数及其导数
plt.figure(figsize=(10, 6))
plt.plot(x_values, y_values_relu, label='ReLU', color='blue')
plt.plot(x_values, y_values_derivative, label='ReLU Derivative', color='red', linestyle='--')
plt.title('ReLU Function and Its Derivative')
plt.xlabel('Input')
plt.ylabel('Output')
plt.grid(True)
plt.legend()
plt.show()
函数(蓝线)及导数(红线)图像如下:

2.4 Leaky ReLU函数
1.函数定义
Leaky ReLU(Leaky Rectified Linear Unit)函数是对ReLU函数的改进,它在输入小于0时引入一个小的斜率,从而解决了ReLU函数存在的“死亡神经元”问题。Leaky ReLU函数的数学定义如下:
其中,是一个小的斜率,通常取一个很小的值,比如0.01。相较于ReLU函数,在输入小于0时,Leaky ReLU函数引入了一个小的斜率
,使得神经元在负区间也能有些许激活。
2.优点
- 解决了“死亡神经元”问题:Leaky ReLU函数在负区间引入了一个小的斜率,使得神经元在负区间也有一定的激活,避免了ReLU函数中神经元死亡的问题。
- 非线性:与ReLU函数一样,Leaky ReLU函数也是一个非线性函数,有助于神经网络学习和表示复杂的非线性关系。
- 计算效率:Leaky ReLU函数的计算与ReLU函数类似,简单高效。
3.缺点
- 不具备严格的零界点:由于Leaky ReLU函数在负区间引入了一个小的斜率,因此它不具备ReLU函数严格的零界点,可能导致一些训练问题。
- 需要调节斜率参数:在实践中,Leaky ReLU函数需要调节斜率参数 �α,但对于什么值是最合适的通常是一个经验性的选择。
4.函数图像及可视化
def leaky_relu(x, alpha=0.01):
return np.where(x > 0, x, alpha * x)
def leaky_relu_derivative(x, alpha=0.01):
return np.where(x > 0, 1, alpha)
# 生成一系列输入值
x_values = np.linspace(-10, 10, 100)
# 计算Leaky ReLU函数及其导数的值
y_values_leaky_relu = leaky_relu(x_values)
y_values_derivative = leaky_relu_derivative(x_values)
# 可视化Leaky ReLU函数及其导数
plt.figure(figsize=(10, 6))
plt.plot(x_values, y_values_leaky_relu, label='Leaky ReLU', color='blue')
plt.plot(x_values, y_values_derivative, label='Leaky ReLU Derivative', color='red', linestyle='--')
plt.title('Leaky ReLU Function and Its Derivative')
plt.xlabel('Input')
plt.ylabel('Output')
plt.grid(True)
plt.legend()
plt.show()
函数(蓝线)及其导数(红线)图像如下:

2.5 PReLU函数
1.函数定义
PRelu(Parametric ReLU)是一种激活函数,是 ReLU 函数的一种扩展形式。与 ReLU 不同的是,PRelu 具有一个可学习的参数,用于调整激活函数在负值区域的斜率。PRelu 函数的数学表达式如下:
其中,是一个可学习的参数,通常在训练过程中被调整以提高模型的性能。
2.优点
- 自适应性:PRelu 具有可学习的参数,可以自适应地调整激活函数的斜率,有助于模型适应不同数据分布和任务的特性。
- 减轻梯度消失问题:PRelu 在负值区域的斜率不为零,有助于减轻梯度消失问题,使得模型更容易训练。
- 保持稀疏性:与其他激活函数相比,PRelu 可以保持输入的稀疏性,因为在负值区域的输入会被放大或缩小,而不会被完全抑制。
3.缺点
- 计算成本:PRelu 具有额外的可学习参数,导致模型的计算成本增加,特别是在模型规模较大时可能会增加训练和推理的时间。
- 过拟合风险:由于 PRelu 具有额外的可学习参数,模型有可能过度拟合训练数据,特别是在数据量较小或噪声较多时。
4.函数图像及可视化
class PRelu:
def __init__(self, alpha):
self.alpha = alpha
def activate(self, x):
return np.where(x > 0, x, self.alpha * x)
def gradient(self, x):
return np.where(x > 0, 1, self.alpha)
# 创建 PRelu 实例
prelu = PRelu(alpha=0.1)
# 生成一系列输入值
x_values = np.linspace(-5, 5, 100)
# 计算 PRelu 函数及其导数的值
y_values_prelu = prelu.activate(x_values)
y_values_derivative = prelu.gradient(x_values)
# 可视化 PRelu 函数及其导数
plt.figure(figsize=(10, 6))
plt.plot(x_values, y_values_prelu, label='PRelu', color='blue')
plt.plot(x_values, y_values_derivative, label='PRelu Derivative', color='red', linestyle='--')
plt.title('PRelu Function and Its Derivative')
plt.xlabel('Input')
plt.ylabel('Output')
plt.grid(True)
plt.legend()
plt.show()
函数(蓝线)及其导数(红线)图像如下:

2.6 ELU函数
1.函数定义
ELU(Exponential Linear Unit)函数是一种激活函数,它在负值区域引入了一个指数项,以解决ReLU函数存在的一些问题。ELU函数的定义如下:
其中,是一个小的正数,通常取为1。ELU函数在负值区域引入了一个指数项
,使得函数在负值区域呈现出更平滑的曲线,从而缓解了ReLU函数存在的一些问题,如“死亡神经元”问题。
2.优点
- 解决了“死亡神经元”问题:ELU函数在负值区域引入了一个指数项,使得神经元在负区域也有一定的激活,避免了ReLU函数中神经元死亡的问题。
- 零中心性:ELU函数在负值区域也具有一个类似于ReLU函数的零中心性,有助于网络学习更好的特征表示。
- 平滑性:ELU函数是连续可导的,且在负值区域呈现出更平滑的曲线,有利于梯度的计算和优化。
3.缺点
- 计算开销:ELU函数的计算相对于ReLU函数来说稍微复杂一些,因为它涉及到指数运算。在大规模数据和深度网络中,可能会带来一些计算开销。
4.函数图像及其可视化
def elu(x, alpha=1.0):
return np.where(x > 0, x, alpha * (np.exp(x) - 1))
def elu_derivative(x, alpha=1.0):
return np.where(x > 0, 1, alpha * np.exp(x))
# 生成一系列输入值
x_values = np.linspace(-10, 10, 100)
# 计算ELU函数及其导数的值
y_values_elu = elu(x_values)
y_values_derivative = elu_derivative(x_values)
# 可视化ELU函数及其导数
plt.figure(figsize=(10, 6))
plt.plot(x_values, y_values_elu, label='ELU', color='blue')
plt.plot(x_values, y_values_derivative, label='ELU Derivative', color='red', linestyle='--')
plt.title('ELU Function and Its Derivative')
plt.xlabel('Input')
plt.ylabel('Output')
plt.grid(True)
plt.legend()
plt.show()
函数(蓝线)及其导数(红线)图像如下:

2.7 SELU函数
1.函数定义
SELU(Scaled Exponential Linear Unit)函数是一种激活函数,是对ELU函数的扩展和缩放版本。SELU函数的定义如下:
其中,和
是两个常数,通常取为 1.0507 和 1.6733。这些常数是根据自归一化条件推导出来的,使得网络在深度方向上保持稳定分布。
2.优点
- 自归一化:SELU函数在一定条件下能够保持输入的平均和方差不变,从而使得网络在深度方向上自归一化,有助于解决梯度消失和爆炸问题。
- 零中心性:SELU函数在负值区域也具有零中心性,有助于网络学习更好的特征表示。
- 稳定性:SELU函数在负值区域的曲线相比ELU函数更为平滑,有助于网络的训练稳定性。
3.缺点
- 限制:SELU函数的自归一化特性仅在满足一定条件下才能保持,如层之间的线性变换、特定的输入分布等。
4.函数图像及其可视化
def selu(x, alpha=1.6733, scale=1.0507):
return scale * np.where(x > 0, x, alpha * (np.exp(x) - 1))
def selu_derivative(x, alpha=1.6733, scale=1.0507):
return scale * np.where(x > 0, 1, alpha * np.exp(x))
# 生成一系列输入值
x_values = np.linspace(-3, 3, 100)
# 计算SELU函数及其导数的值
y_values_selu = selu(x_values)
y_values_derivative = selu_derivative(x_values)
# 可视化SELU函数及其导数
plt.figure(figsize=(10, 6))
plt.plot(x_values, y_values_selu, label='SELU', color='blue')
plt.plot(x_values, y_values_derivative, label='SELU Derivative', color='red', linestyle='--')
plt.title('SELU Function and Its Derivative')
plt.xlabel('Input')
plt.ylabel('Output')
plt.grid(True)
plt.legend()
plt.show()
函数(蓝线)及其导数(红线)图像如下:

2.8 Swish函数
1.函数定义
Swish函数是由Google提出的一种激活函数,它具有一种非线性的形式,并且在深度学习中表现良好。Swish函数的数学表达式如下:
其中,是 sigmoid 函数,
是一个可学习的参数或者常数。Swish函数在输入较大时接近线性,而在输入较小时接近零。这使得它比一些传统的激活函数更具有优势,因为它可以将正向传播和反向传播的信号都保持在较大的范围内。
2.优点
- 非线性:Swish函数是一种非线性激活函数,可以帮助神经网络学习和表示复杂的非线性关系。
- 平滑性:Swish函数是平滑的,这有助于优化算法在训练神经网络时更容易地寻找最优解。
- 可学习的参数:Swish函数中的参数 �β 可以通过反向传播进行优化,这使得神经网络可以自适应地调整参数。
3.缺点
- 计算成本:Swish函数的计算成本相对较高,因为它涉及到 sigmoid 函数的计算。
- 对比度敏感:Swish函数对比度敏感,可能会受到输入的大小和分布的影响。
4.函数图像及其可视化
def swish(x, beta=1.0):
return x * (1 / (1 + np.exp(-beta * x)))
def swish_derivative(x, beta=1.0):
sigmoid = 1 / (1 + np.exp(-beta * x))
return (1 / (1 + np.exp(-beta * x))) + beta * x * sigmoid * (1 - sigmoid)
# 生成一系列输入值
x_values = np.linspace(-10, 10, 100)
# 计算Swish函数及其导数的值
y_values_swish = swish(x_values)
y_values_derivative = swish_derivative(x_values)
# 可视化Swish函数及其导数
plt.figure(figsize=(10, 6))
plt.plot(x_values, y_values_swish, label='Swish', color='blue')
plt.plot(x_values, y_values_derivative, label='Swish Derivative', color='red', linestyle='--')
plt.title('Swish Function and Its Derivative')
plt.xlabel('Input')
plt.ylabel('Output')
plt.grid(True)
plt.legend()
plt.show()
函数(蓝线)及其导数(红线)图像如下:

2.9 Mish函数
1.函数定义
Mish函数,由Diganta Misra在2019年提出,它是对Swish函数的改进。Mish函数的数学表达式如下:
Mish函数在负值区域呈现出类似于双曲正切函数的形状,而在正值区域则更加线性。它的形状在接近零点时比Swish函数更加平滑,因此在实践中有时候表现更好。
2.优点
- 非线性:Mish函数是一种非线性激活函数,有助于神经网络学习和表示复杂的非线性关系。
- 平滑性:Mish函数在接近零点时更加平滑,这有助于优化算法在训练神经网络时更容易地寻找最优解。
- 简单性:Mish函数的表达式相对简单,只涉及到基本的数学函数,因此计算成本相对较低。
3.缺点
- 计算成本:Mish函数的计算成本相对较高,因为它涉及到tanh函数和指数函数的计算。
- 参数调整:Mish函数中没有可调参数,可能无法适应所有数据和问题的特性。
4.函数图像及其可视化
import numpy as np
import matplotlib.pyplot as plt
def mish(x):
return x * np.tanh(np.log(1 + np.exp(x)))
def mish_derivative(x):
sigmoid = 1 / (1 + np.exp(-x))
return np.tanh(np.log(1 + np.exp(x))) + x * sigmoid * (1 - np.square(np.tanh(np.log(1 + np.exp(x)))))
# 生成一系列输入值
x_values = np.linspace(-10, 10, 100)
# 计算Mish函数及其导数的值
y_values_mish = mish(x_values)
y_values_derivative = mish_derivative(x_values)
# 可视化Mish函数及其导数
plt.figure(figsize=(10, 6))
plt.plot(x_values, y_values_mish, label='Mish', color='blue')
plt.plot(x_values, y_values_derivative, label='Mish Derivative', color='red', linestyle='--')
plt.title('Mish Function and Its Derivative')
plt.xlabel('Input')
plt.ylabel('Output')
plt.grid(True)
plt.legend()
plt.show()
函数(蓝线)及其导数(红线)图像如下:

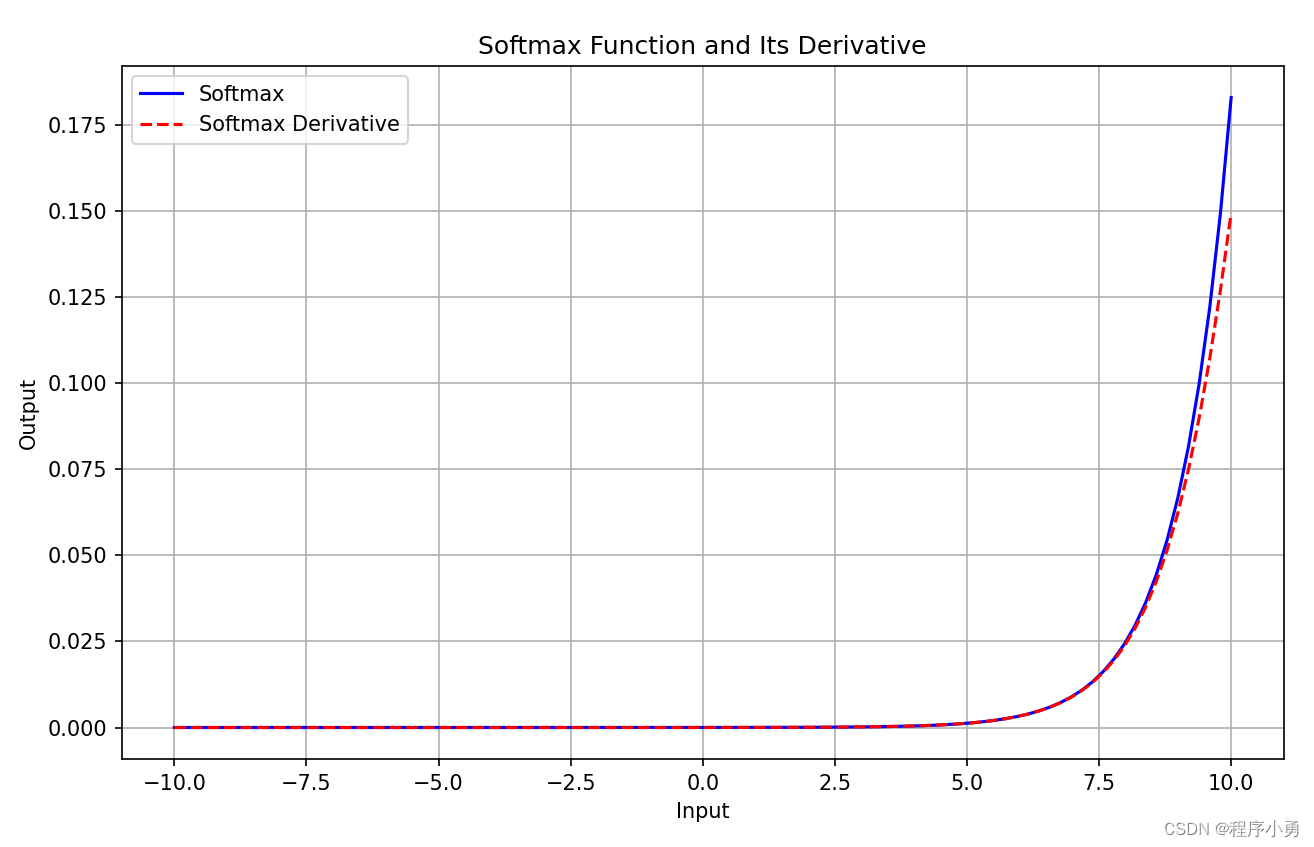
2.10 Softmax函数
1.函数定义
Softmax函数是一种常用的激活函数,通常用于多分类问题中的输出层。Softmax函数将一个N维的实数向量映射到一个概率分布上,使得每个元素的取值范围在0到1之间,并且所有元素的和为1。Softmax函数的数学表达式如下:
其中,是输入向量,
是Softmax函数的第i个输出。
Softmax函数的特点是将输入进行指数化,然后归一化,使得输出概率分布的每个元素表示了对应类别的预测概率。在多分类问题中,通常使用交叉熵损失函数结合Softmax函数进行训练。
2.优点
-
输出概率分布:Softmax函数将输入向量映射到一个概率分布上,使得每个元素的取值范围在0到1之间,并且所有元素的和为1。这种特性使得Softmax函数在多分类问题中特别有用,可以直接输出各个类别的概率。
-
数学简单:Softmax函数的数学表达式相对简单,只涉及到指数运算和归一化操作,计算也比较高效。
-
可导性:Softmax函数是可导的,这意味着可以直接应用于梯度下降等优化算法中,用于训练神经网络。
3.缺点
-
数值不稳定性:Softmax函数在处理数值较大的输入时可能会出现数值不稳定的情况,因为指数函数的值可能会非常大,导致数值溢出。为了解决这个问题,通常需要进行数值稳定性的处理,例如通过减去输入向量中的最大值来避免指数函数的值过大。
-
不适合处理大规模输出:当输出类别很多时,Softmax函数的计算量会增加,导致计算效率降低。特别是在深度学习模型中,如果输出类别数量非常大,Softmax函数可能会成为性能瓶颈。
-
独立性假设:Softmax函数假设各个输出之间相互独立,但在实际问题中可能存在相关性,这会导致Softmax函数的预测结果存在一定的偏差。
4.函数图像及其可视化
import numpy as np
import matplotlib.pyplot as plt
def softmax(z):
exp_z = np.exp(z)
return exp_z / np.sum(exp_z)
def softmax_derivative(z):
softmax_output = softmax(z)
return softmax_output * (1 - softmax_output)
# 生成输入范围
x_values = np.linspace(-10, 10, 100)
# 计算 Softmax 函数及其导数的输出
softmax_output = softmax(x_values)
softmax_derivative_output = softmax_derivative(x_values)
# 可视化 Softmax 函数及其导数
plt.figure(figsize=(10, 6))
plt.plot(x_values, softmax_output, label='Softmax', color='blue')
plt.plot(x_values, softmax_derivative_output, label='Softmax Derivative', color='red', linestyle='--')
plt.title('Softmax Function and Its Derivative')
plt.xlabel('Input')
plt.ylabel('Output')
plt.grid(True)
plt.legend()
plt.show()
函数(蓝线)及其导数(红线)图像如下:
2.11 GELU函数
1.函数定义
GELU(Gaussian Error Linear Unit)最初由Hendrycks和Gimpel在2016年提出,并且在BERT模型中广泛应用。GELU 函数的数学表达式如下:
其中,是标准正态分布的累积分布函数(CDF)。其定义为:
是误差函数。
2.优点
-
非线性性质:GELU 函数是一种非线性激活函数,可以帮助神经网络学习和表示复杂的非线性关系。
-
平滑性:GELU 函数是平滑的,这有助于优化算法在训练神经网络时更容易地寻找最优解。
-
性能表现:GELU 函数在很多自然语言处理任务中表现良好,尤其在BERT等模型中得到广泛应用。
3.缺点
-
计算成本:GELU 函数的计算成本相对较高,因为它涉及到误差函数的计算,这可能导致训练速度较慢。
-
对比度敏感:GELU 函数对比度敏感,可能会受到输入的大小和分布的影响,因此在某些情况下可能不稳定。
-
参数调整:GELU 函数中没有可调参数,可能无法适应所有数据和问题的特性,对模型的泛化能力具有一定挑战性。
4.函数图像及其可视化
def gelu(x):
return 0.5 * x * (1 + erf(x / np.sqrt(2)))
def gelu_derivative(x):
return 0.5 * (1 + erf(x / np.sqrt(2))) + 0.5 * x * np.exp(-0.5 * x**2) / np.sqrt(np.pi)
# 生成一系列输入值
x_values = np.linspace(-5, 5, 100)
# 计算 GELU 函数及其导数的值
y_values_gelu = gelu(x_values)
y_values_derivative = gelu_derivative(x_values)
# 可视化 GELU 函数及其导数
plt.figure(figsize=(10, 6))
plt.plot(x_values, y_values_gelu, label='GELU', color='blue')
plt.plot(x_values, y_values_derivative, label='GELU Derivative', color='red', linestyle='--')
plt.title('GELU Function and Its Derivative')
plt.xlabel('Input')
plt.ylabel('Output')
plt.grid(True)
plt.legend()
plt.show()
函数(蓝线)及其导数(红线)图像如下:

2.12 Maxout函数
1.函数定义
Maxout是一种激活函数,由Goodfellow等人于2013年提出。它不是单个函数,而是一种整流单元(Rectified Linear Unit,ReLU)的扩展,能够学习激活函数的形状。
Maxout单元的数学表达式如下:
其中,、
是权重向量,
、
是偏置,
是输入向量。Maxout函数可以看作是对两个线性函数的最大化,因此在每个区间内都是线性的,但整体上是非线性的。
2.优点
-
非线性性质:Maxout函数是一种非线性激活函数,可以帮助神经网络学习和表示复杂的非线性关系。
-
表达能力:Maxout函数的表达能力比ReLU更强,它可以学习到更复杂的函数形状。
-
稀疏性:与ReLU类似,Maxout函数在某些情况下可以保持输入的稀疏性,因为在输入的某些部分会被置零。
3.缺点
-
参数量:Maxout函数涉及到更多的参数(两倍于ReLU),因此模型的参数量会增加,可能导致过拟合。
-
计算成本:Maxout函数的计算成本相对较高,因为它涉及到更多的权重和偏置。
4.函数图像及其可视化
def maxout(x, w1, b1, w2, b2):
max1 = np.dot(x, w1) + b1
max2 = np.dot(x, w2) + b2
return np.maximum(max1, max2)
def maxout_derivative(x, w1, b1, w2, b2):
max1 = np.dot(x, w1) + b1
max2 = np.dot(x, w2) + b2
return np.where(max1 > max2, w1, w2)
# 生成一系列输入值
x_values = np.linspace(-5, 5, 100)
# 设置权重和偏置
w1 = np.array([1, 1])
b1 = 0
w2 = np.array([-1, 1])
b2 = 0
# 计算 Maxout 函数及其导数的值
y_values_maxout = maxout(x_values[:, np.newaxis], w1[np.newaxis, :], b1, w2[np.newaxis, :], b2)
y_values_derivative = maxout_derivative(x_values[:, np.newaxis], w1[np.newaxis, :], b1, w2[np.newaxis, :], b2)
# 可视化 Maxout 函数及其导数
plt.figure(figsize=(10, 6))
plt.plot(x_values, y_values_maxout, label='Maxout', color='blue')
plt.plot(x_values, y_values_derivative, label='Maxout Derivative', color='red', linestyle='--')
plt.title('Maxout Function and Its Derivative')
plt.xlabel('Input')
plt.ylabel('Output')
plt.grid(True)
plt.legend()
plt.show()函数(蓝线)及其导数(红线)图像如下:

总结
神经网络中的激活函数是引入非线性和提高网络表达能力的重要组成部分。本文详细探讨了激活函数的性质、种类、及其优缺点。通过对Sigmoid、Tanh、ReLU等常见激活函数的深入分析,揭示了它们在神经网络中的关键作用。此外,针对梯度消失和“死亡”ReLU等挑战,给出了有效的解决方案。
综上所述,激活函数对于神经网络的性能和学习能力具有显著影响,选择合适的激活函数对于优化网络训练和提高模型性能至关重要。