目录
1、部署环境
编辑
2、更改节点名称
3、准备环境
4、磁盘分区,并挂载
5. 做主机映射--/etc/hosts/
6. 复制脚本文件
7. 执行脚本完成分区
8. 安装客户端软件
1. 安装解压源包
2. 创建gfs
3. 安装 gfs
4. 开启服务
9、 添加节点到存储信任池中
10、创建卷
1. 规划创建卷
2.创建分布式卷
3.创建条带卷
4. 创建复制卷
5.创建分布式条带卷
6.创建分布式复制卷
7.查看卷列表
11、部署客户端--7-1
1.复制文件并解压
2. 建立元数据
3.安装
4.创建挂载目录
5. 给客户端做主机名映射
6.挂载Gluster文件系统
12、测试Gluster文件系统
1.在5个卷中写入文件
13、查看文件分布
1. 查看分布式文件分布
2.查看条带卷文件分布
3.查看复制卷分布
4.查看分布式条带卷分布
5.查看分布式复制卷分布
14.破坏性测试
1.挂起node2
15.客户端查看破坏结果
1.查看分布式数据
2.查看条带卷数据
3.查看复制卷数据
4.查看分布式条带卷数据
5.查看分布式复制卷数据
16、总结
1.查看GlusterFS卷
2.查看所有卷的信息
3.查看所有卷的状态
4.停止一个卷
5.删除一个卷,注意:删除卷时,需要先停止卷,且信任池中不能有主机处于宕机状态,否则删除不成功
6.设置卷的访问控制
1、部署环境
Node1节点:node1/192.168.91.102 磁盘: /dev/sdb1 挂载点: /data/sdb1
/dev/sdc1 /data/sdc1
/dev/sdd1 /data/sdd1
/dev/sde1 /data/sde1
Node2节点:node2/192.168.91.103 磁盘: /dev/sdb1 挂载点: /data/sdb1
/dev/sdc1 /data/sdc1
/dev/sdd1 /data/sdd1
/dev/sde1 /data/sde1
Node3节点:node3/192.168.91.104 磁盘: /dev/sdb1 挂载点: /data/sdb1
/dev/sdc1 /data/sdc1
/dev/sdd1 /data/sdd1
/dev/sde1 /data/sde1
Node4节点:node4/192.168.91.105 磁盘: /dev/sdb1 挂载点: /data/sdb1
/dev/sdc1 /data/sdc1
/dev/sdd1 /data/sdd1
/dev/sde1 /data/sde1
=====客户端节点:192.168.91.100=====给四个服务器,每台添加4块硬盘
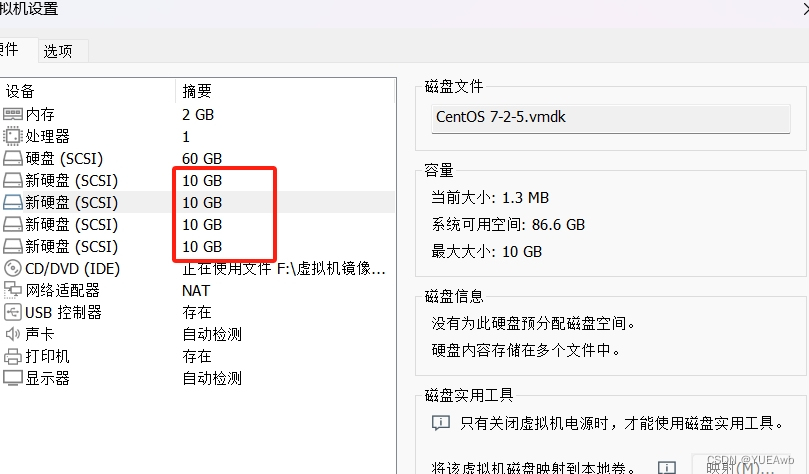
[root@localhost ~]# ls /dev/sd*
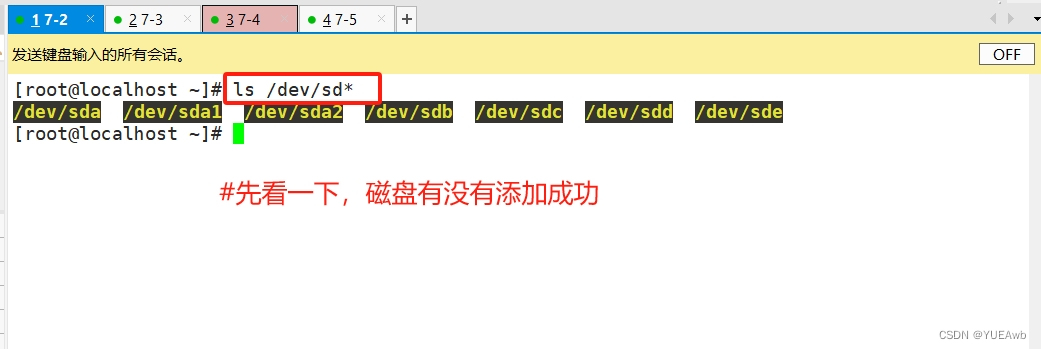
2、更改节点名称
node1(192.168.91.102)
[root@localhost ~] # hostnamectl set-hostname node1
[root@localhost ~] # bashnode2(192.168.91.103)
[root@localhost ~] # hostnamectl set-hostname node2
[root@localhost ~] # bashnode3(192.168.91.104)
[root@localhost ~] # hostnamectl set-hostname node3
[root@localhost ~] # bashnode4(192.168.91.105)
[root@localhost ~] # hostnamectl set-hostname node4
[root@localhost ~] # bash3、准备环境
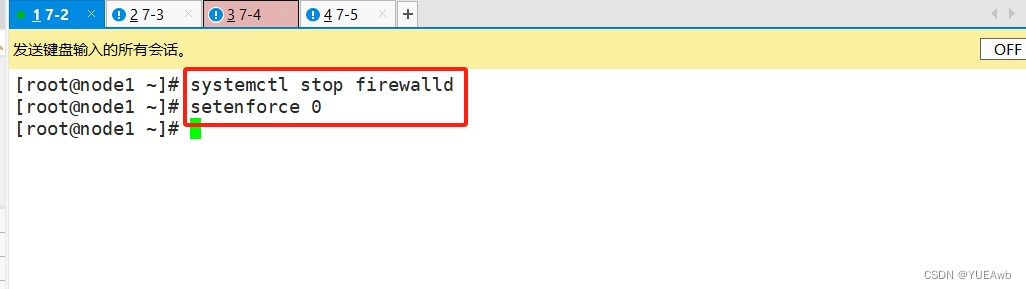
关闭防火墙和selinux
[root@node1 ~]# systemctl stop firewalld
[root@node1 ~]# setenforce 0
4、磁盘分区,并挂载
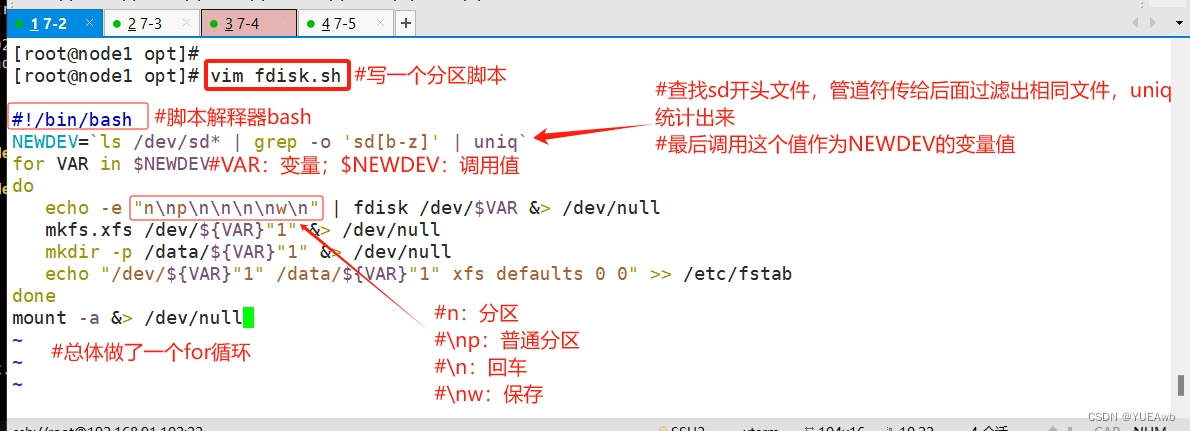
vim /opt/fdisk.sh
#!/bin/bash
NEWDEV=`ls /dev/sd* | grep -o 'sd[b-z]' | uniq`
for VAR in $NEWDEV
do
echo -e "n\np\n\n\n\nw\n" | fdisk /dev/$VAR &> /dev/null
mkfs.xfs /dev/${VAR}"1" &> /dev/null
mkdir -p /data/${VAR}"1" &> /dev/null
echo "/dev/${VAR}"1" /data/${VAR}"1" xfs defaults 0 0" >> /etc/fstab
done
mount -a &> /dev/null
chmod +x /opt/fdisk.sh
5. 做主机映射--/etc/hosts/
echo "192.168.91.102 node1" >> /etc/hosts
echo "192.168.91.103 node2" >> /etc/hosts
echo "192.168.91.104 node3" >> /etc/hosts
echo "192.168.91.105 node4" >> /etc/hosts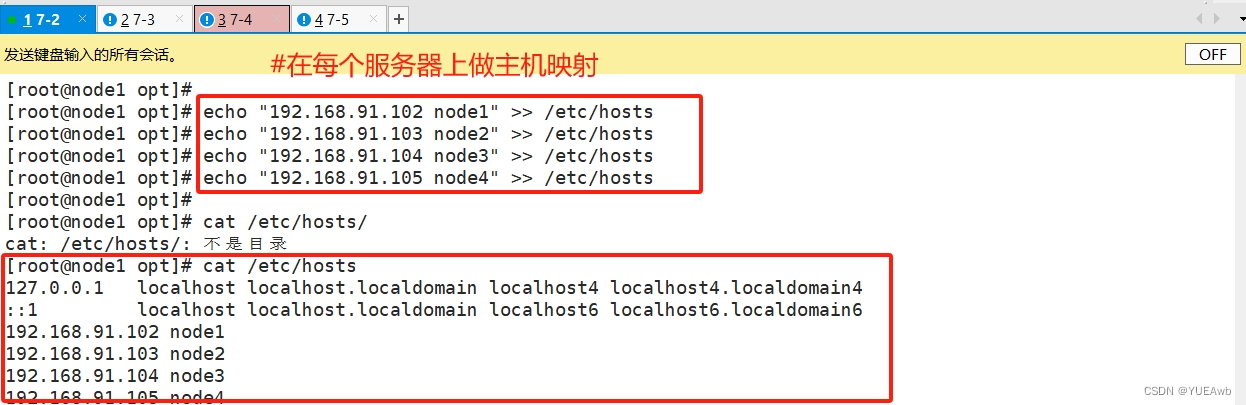
6. 复制脚本文件
[root@node1 opt]# scp fdisk.sh node2:/opt/
[root@node1 opt]# scp fdisk.sh node3:/opt/
[root@node1 opt]# scp fdisk.sh node4:/opt/
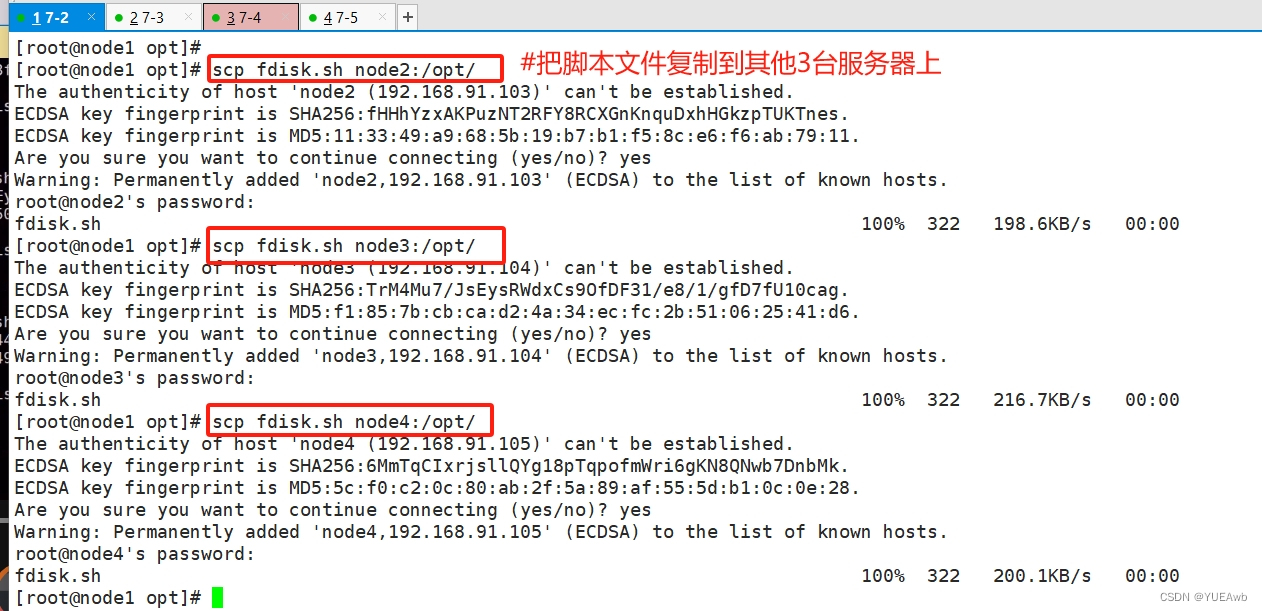
7. 执行脚本完成分区

8. 安装客户端软件
一定要先解压源包,才能成功创建gfs
1. 安装解压源包

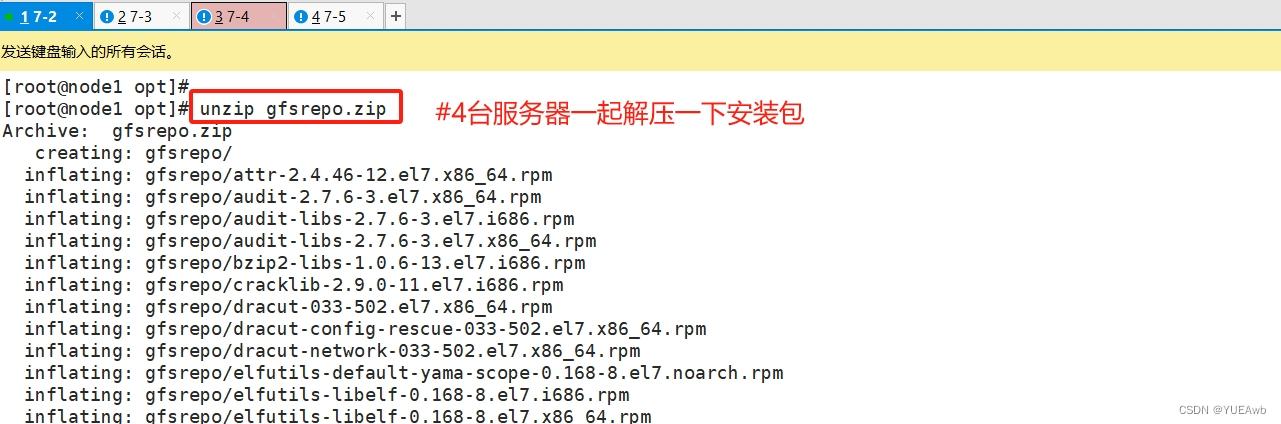
2. 创建gfs
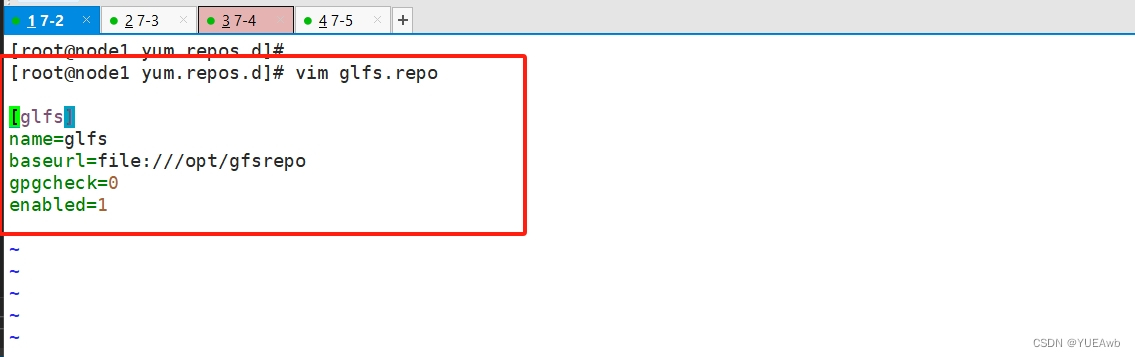
四台node服务器都要创建
cd /etc/yum.repos.d/
mkdir repo.bak
mv *.repo repo.bak
vim glfs.repo
[glfs]
name=glfs
baseurl=file:///opt/gfsrepo
gpgcheck=0
enabled=1

yum clean all && yum makecache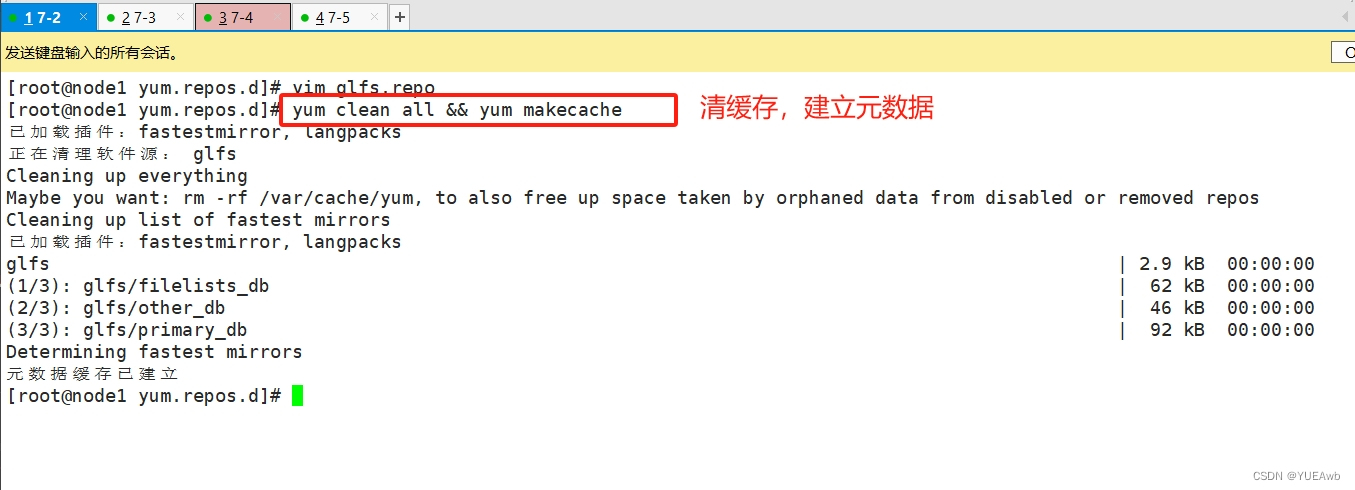
3. 安装 gfs
yum remove glusterfs-api.x86_64 glusterfs-cli.x86_64 glusterfs.x86_64 glusterfs-libs.x86_64 glusterfs-client-xlators.x86_64 glusterfs-fuse.x86_64 -y

yum -y install glusterfs glusterfs-server glusterfs-fuse glusterfs-rdma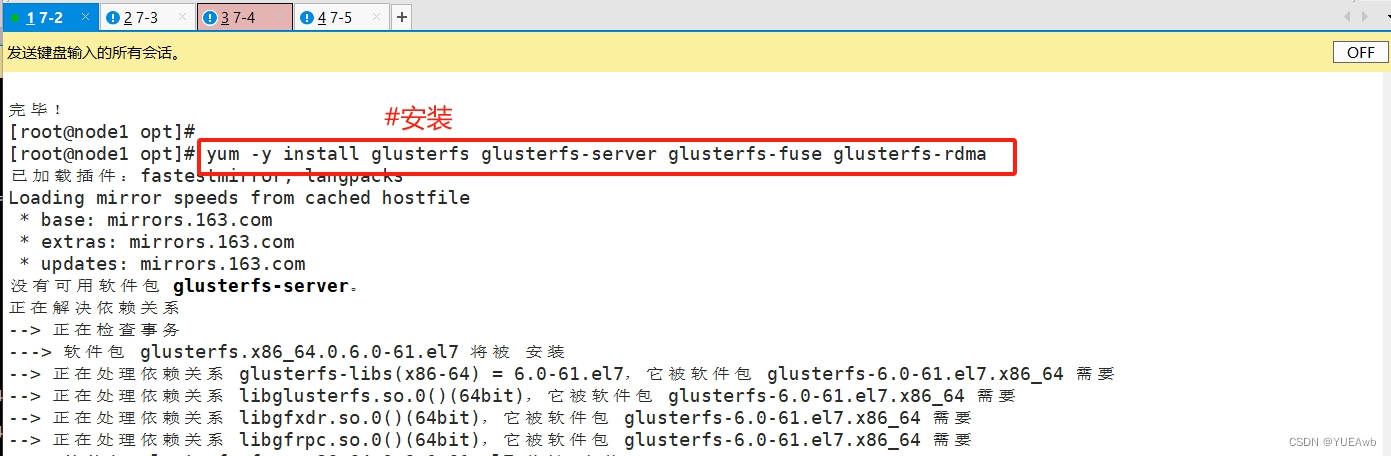
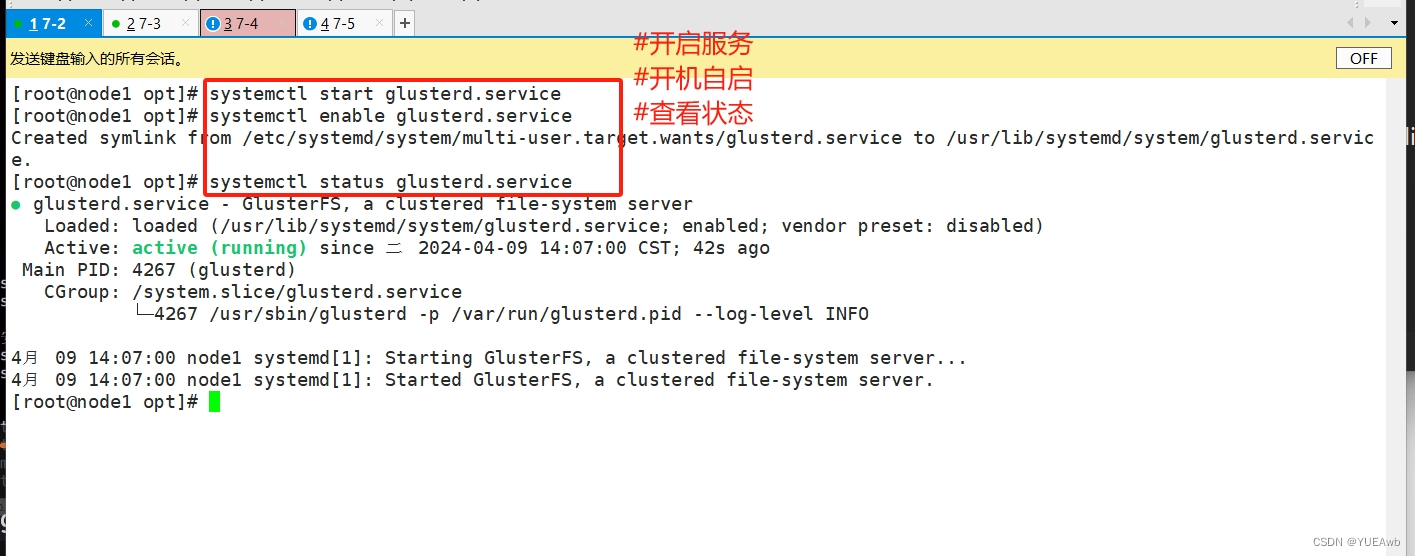
4. 开启服务
systemctl start glusterd.service
systemctl enable glusterd.service
systemctl status glusterd.service
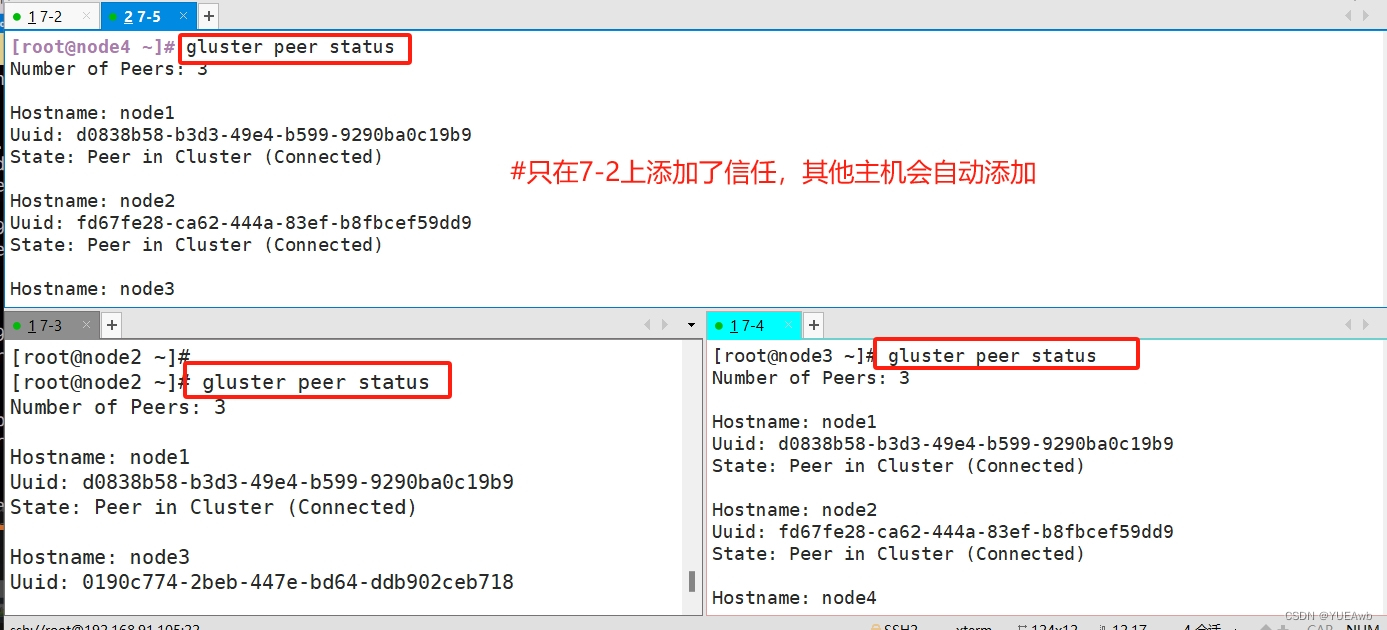
9、 添加节点到存储信任池中
#只要在一台Node节点上添加其它节点即可
gluster peer probe node2
gluster peer probe node3
gluster peer probe node4
gluster peer status
在7-2一台主机上添加信任,其他主机会自动添加
10、创建卷
1. 规划创建卷
============================根据以下规划创建卷=============================
卷名称 卷类型 Brick
fenbushi 分布式卷 node1(/data/sdb1)、node2(/data/sdb1)
tiaodai 条带卷 node1(/data/sdc1)、node2(/data/sdc1)
fuzhi 复制卷 node3(/data/sdb1)、node4(/data/sdb1)
fbs-td 分布式条带卷 node1(/data/sdd1)、node2(/data/sdd1)、node3(/data/sdd1)、node4(/data/sdd1)
fbs-fz 分布式复制卷 node1(/data/sde1)、node2(/data/sde1)、node3(/data/sde1)、node4(/data/sde1)2.创建分布式卷
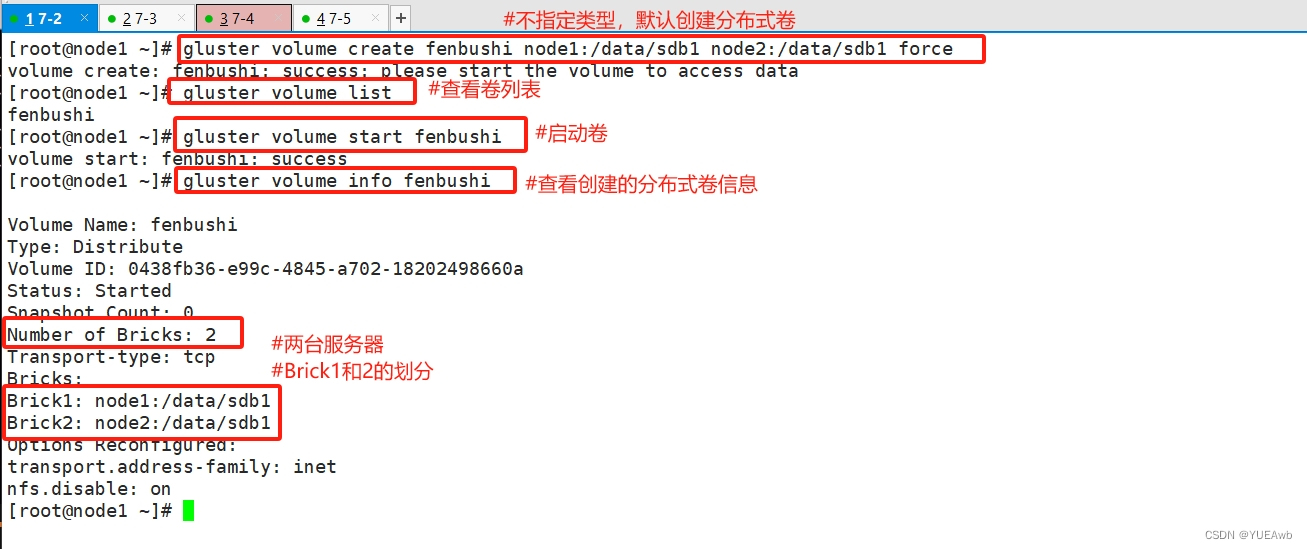
#创建分布式卷,没有指定类型,默认创建的是分布式卷
[root@node1 ~]# gluster volume create fenbushi node1:/data/sdb1 node2:/data/sdb1 force
volume create: fenbushi: success: please start the volume to access data
[root@node1 ~]# gluster volume list
fenbushi
[root@node1 ~]# gluster volume start fenbushi
volume start: fenbushi: success
[root@node1 ~]# gluster volume info fenbushi
Volume Name: fenbushi
Type: Distribute
Volume ID: 0438fb36-e99c-4845-a702-18202498660a
Status: Started
Snapshot Count: 0
Number of Bricks: 2
Transport-type: tcp
Bricks:
Brick1: node1:/data/sdb1
Brick2: node2:/data/sdb1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
[root@node1 ~]#
3.创建条带卷
[root@node1 ~]# gluster volume create tiaodai stripe 2 node1:/data/sdc1 node2:/data/sdc1 force
volume create: tiaodai: success: please start the volume to access data
[root@node1 ~]# gluster volume start tiaodai
volume start: tiaodai: success
[root@node1 ~]# gluster volume info tiaodai
Volume Name: tiaodai
Type: Stripe
Volume ID: f64b6b6a-dadd-427f-8806-6e7dff448b66
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x 2 = 2
Transport-type: tcp
Bricks:
Brick1: node1:/data/sdc1
Brick2: node2:/data/sdc1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
[root@node1 ~]#

4. 创建复制卷
[root@node1 ~]# gluster volume create fuzhi replica 2 node3:/data/sdb1 node4:/data/sdb1 force
volume create: fuzhi: success: please start the volume to access data
[root@node1 ~]# gluster volume start fuzhi
volume start: fuzhi: success
[root@node1 ~]# gluster volume info fuzhi
Volume Name: fuzhi
Type: Replicate
Volume ID: 3cdffb32-a007-41c6-8e19-dbc17878ea12
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x 2 = 2
Transport-type: tcp
Bricks:
Brick1: node3:/data/sdb1
Brick2: node4:/data/sdb1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
[root@node1 ~]#

5.创建分布式条带卷
[root@node1 ~]# gluster volume create fbs-td stripe 2 node1:/data/sdd1 node2:/data/sdd1 node3:/data/sdd1 node4:/data/sdd1 force
volume create: fbs-td: success: please start the volume to access data
[root@node1 ~]# gluster volume start fbs-td
volume start: fbs-td: success
[root@node1 ~]# gluster volume info fbs-td
Volume Name: fbs-td
Type: Distributed-Stripe
Volume ID: b389f9b9-12bf-4ffd-a05a-d4a126a37cb4
Status: Started
Snapshot Count: 0
Number of Bricks: 2 x 2 = 4
Transport-type: tcp
Bricks:
Brick1: node1:/data/sdd1
Brick2: node2:/data/sdd1
Brick3: node3:/data/sdd1
Brick4: node4:/data/sdd1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
[root@node1 ~]#
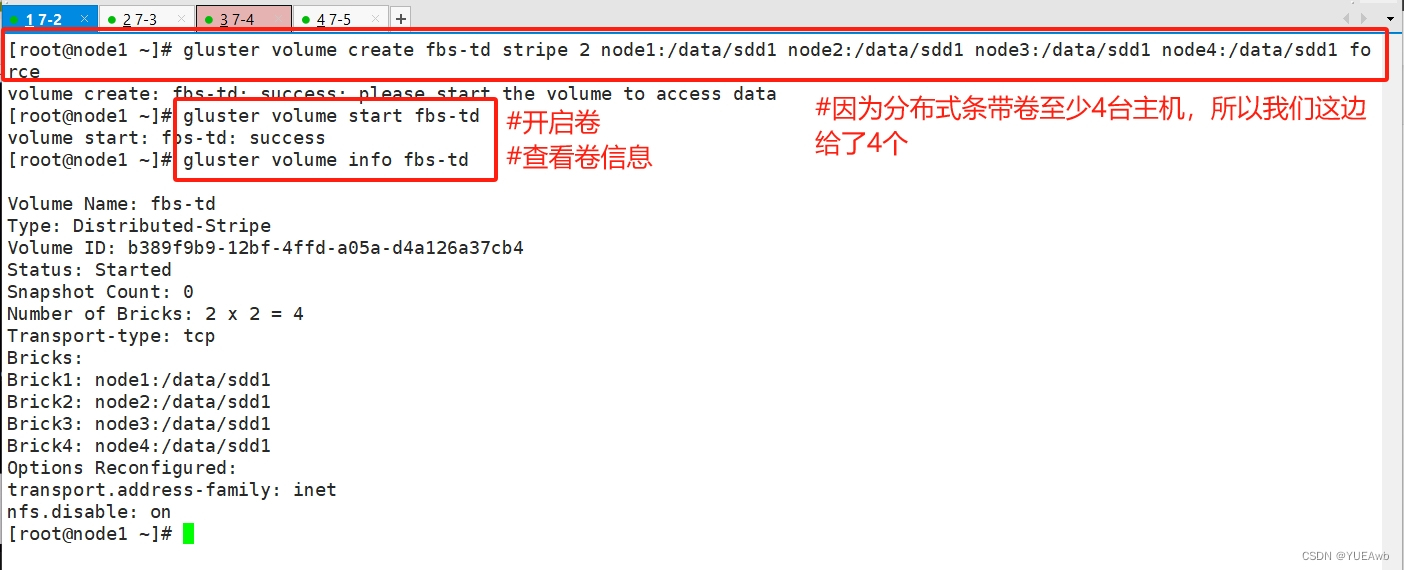
6.创建分布式复制卷
[root@node1 ~]# gluster volume create fbs-fz replica 2 node1:/data/sde1 node2:/data/sde1 node3:/data/sde1 node4:/data/sde1 force
volume create: fbs-fz: success: please start the volume to access data
[root@node1 ~]# gluster volume start fbs-fz
volume start: fbs-fz: success
[root@node1 ~]# gluster volume info fbs-fz
Volume Name: fbs-fz
Type: Distributed-Replicate
Volume ID: f6913316-f886-4f4b-8e53-94feaf448587
Status: Started
Snapshot Count: 0
Number of Bricks: 2 x 2 = 4
Transport-type: tcp
Bricks:
Brick1: node1:/data/sde1
Brick2: node2:/data/sde1
Brick3: node3:/data/sde1
Brick4: node4:/data/sde1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
[root@node1 ~]#

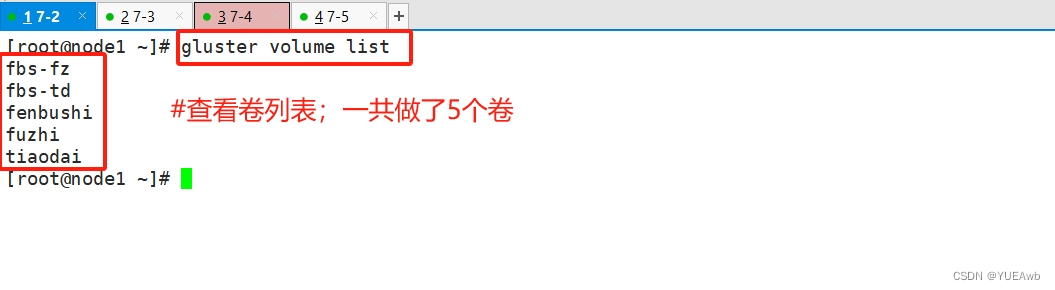
7.查看卷列表
gluster volume list
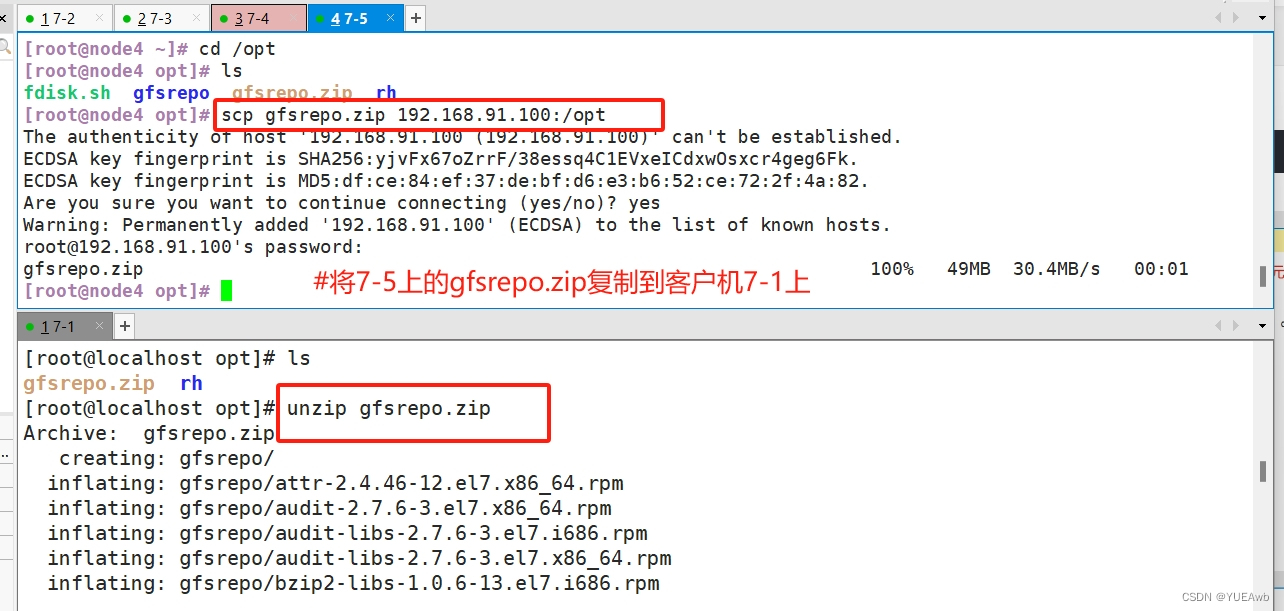
11、部署客户端--7-1
1.复制文件并解压
2. 建立元数据
cd /etc/yum.repos.d/
mkdir repo.bak
mv *.repo repo.bak
vim glfs.repo
[glfs]
name=glfs
baseurl=file:///opt/gfsrepo
gpgcheck=0
enabled=1
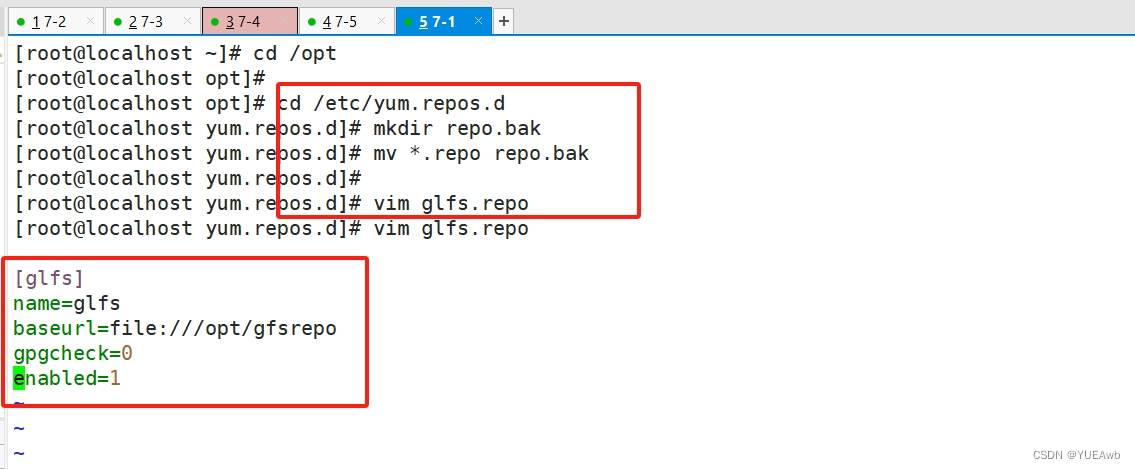
[root@localhost opt]# yum clean all && yum makecache
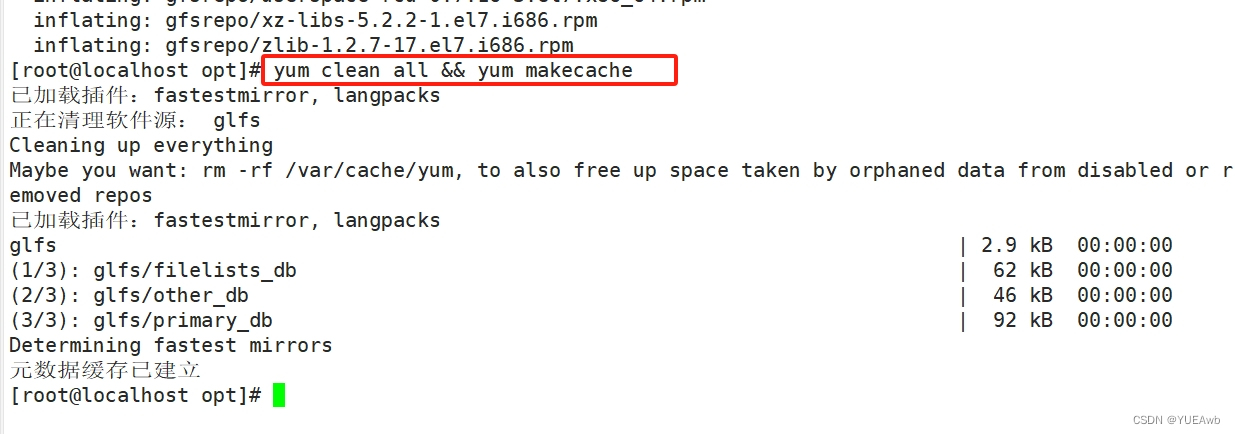
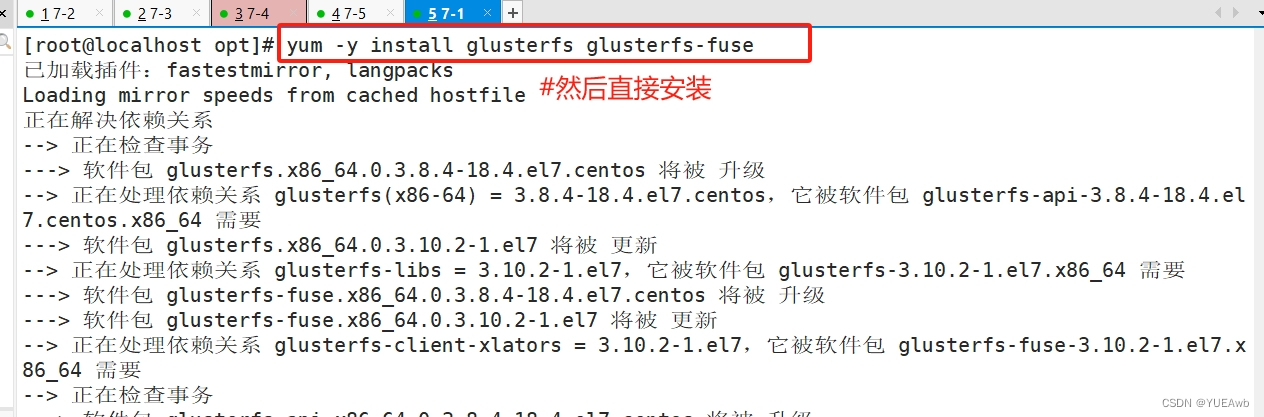
3.安装
yum -y install glusterfs glusterfs-fuse
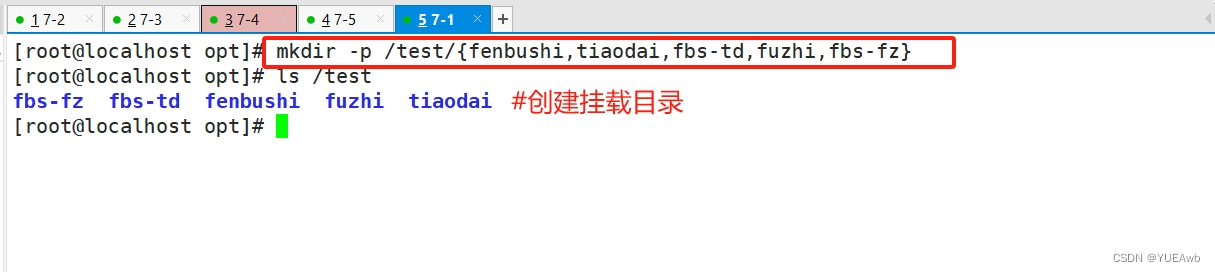
4.创建挂载目录
mkdir -p /test/{fenbushi,tiaodai,fbs-td,fuzhi,fbs-fz}
5. 给客户端做主机名映射
192.168.91.102 node1
192.168.91.103 node2
192.168.91.104 node3
192.168.91.105 node4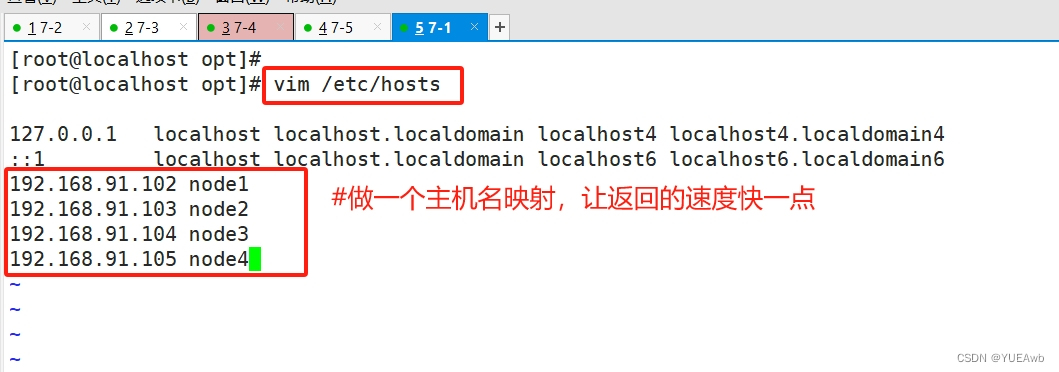
6.挂载Gluster文件系统
#临时挂载
[root@localhost opt]# mount.glusterfs node1:fenbushi /test/fenbushi/
[root@localhost opt]# mount.glusterfs node1:tiaodai /test/tiaodai/
[root@localhost opt]# mount.glusterfs node1:fuzhi /test/fuzhi/
[root@localhost opt]# mount.glusterfs node1:fbs-td /test/fbs-td/
[root@localhost opt]# mount.glusterfs node1:fbs-fz /test/fbs-fz/
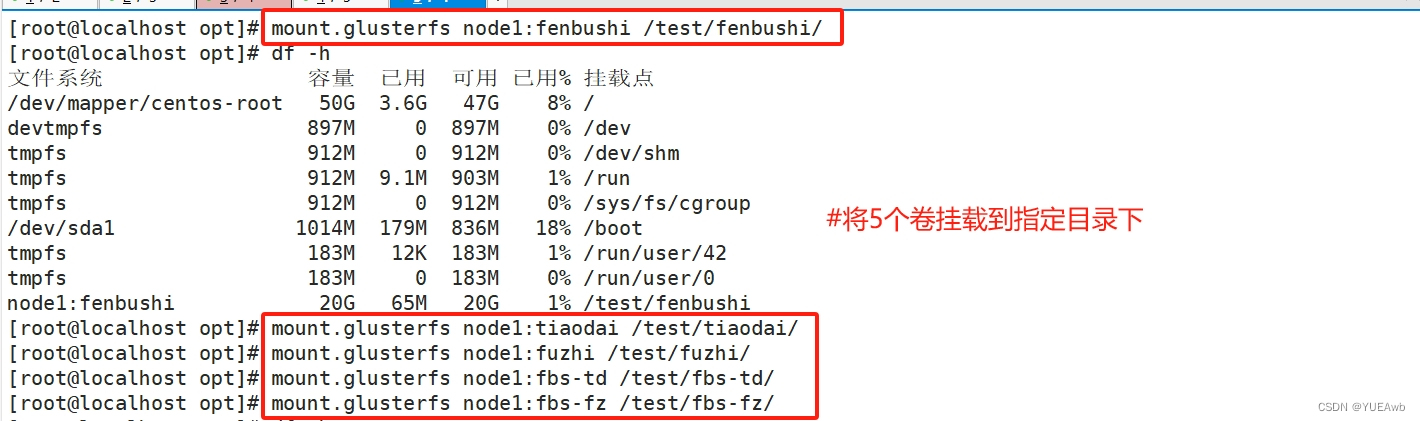
df -h###查看挂载效果
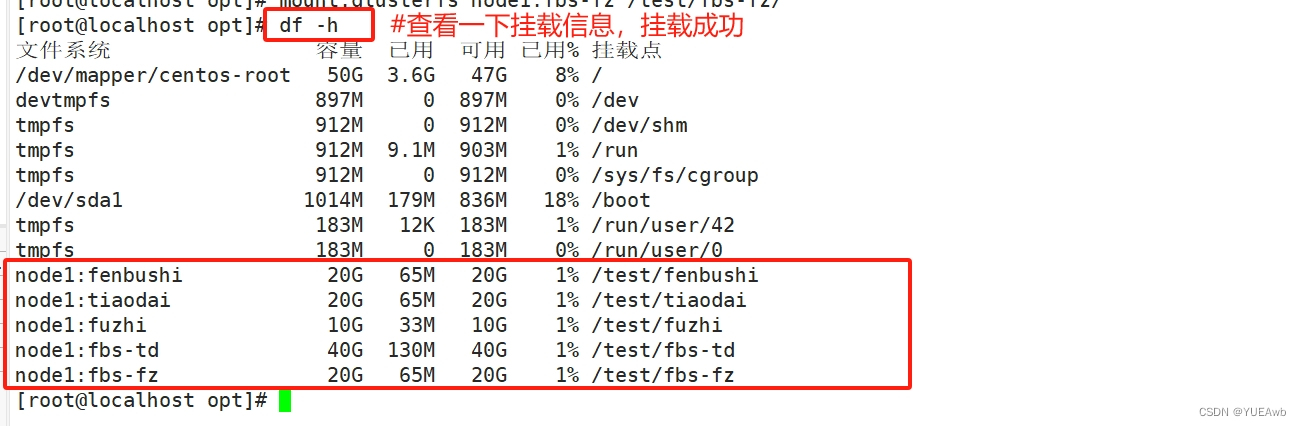
12、测试Gluster文件系统
1.在5个卷中写入文件
cd /opt
dd if=/dev/zero of=/opt/demo1.log bs=1M count=40
dd if=/dev/zero of=/opt/demo2.log bs=1M count=40
dd if=/dev/zero of=/opt/demo3.log bs=1M count=40
dd if=/dev/zero of=/opt/demo4.log bs=1M count=40
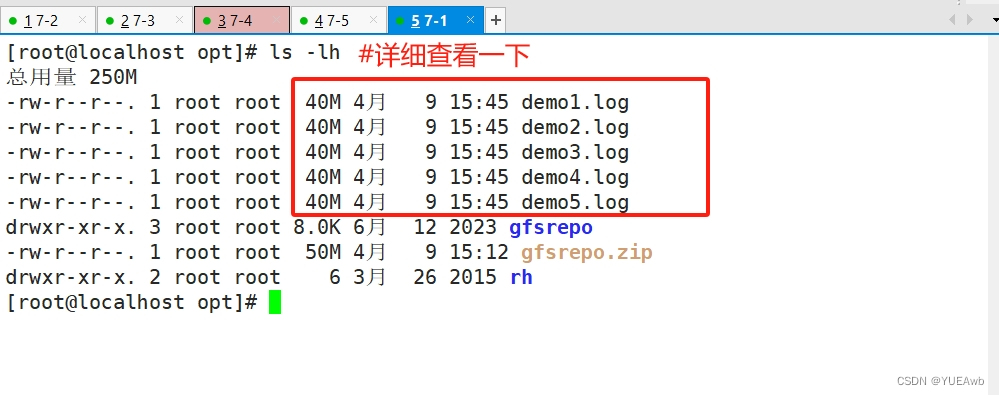
dd if=/dev/zero of=/opt/demo5.log bs=1M count=40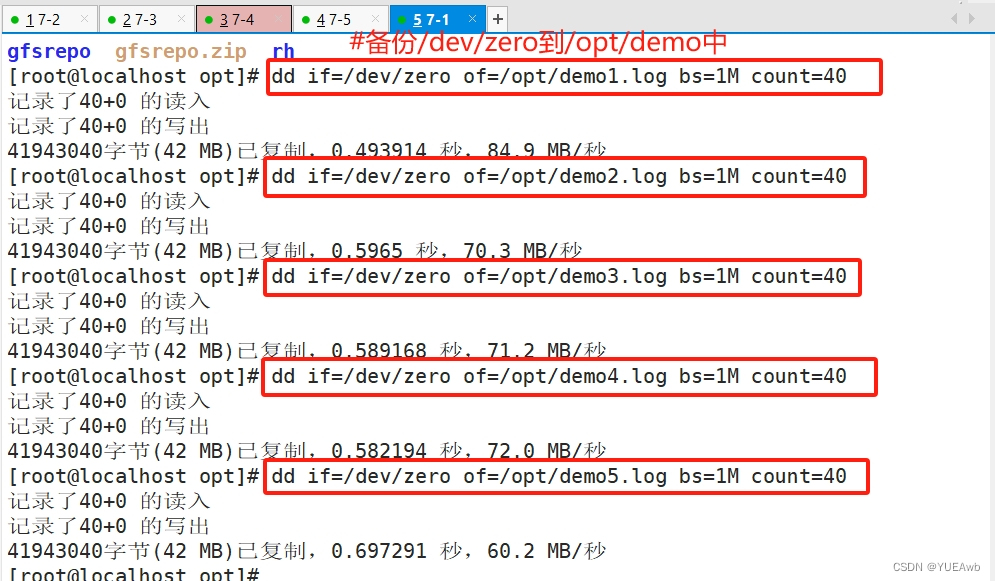
[root@localhost opt]# cp /opt/demo* /test/fenbushi/
[root@localhost opt]# cp /opt/demo* /test/tiaodai/
[root@localhost opt]# cp /opt/demo* /test/fuzhi/
[root@localhost opt]# cp /opt/demo* /test/fbs-td/
[root@localhost opt]# cp /opt/demo* /test/fbs-fz/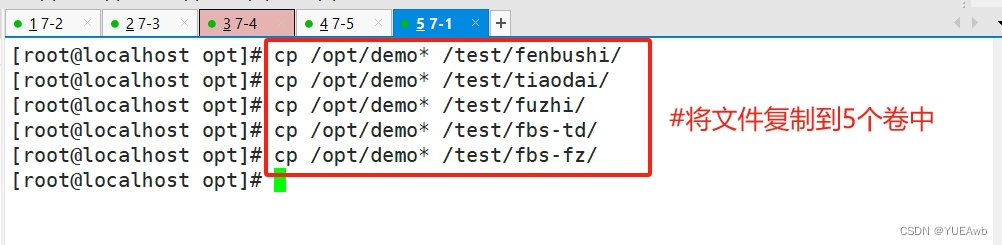
13、查看文件分布
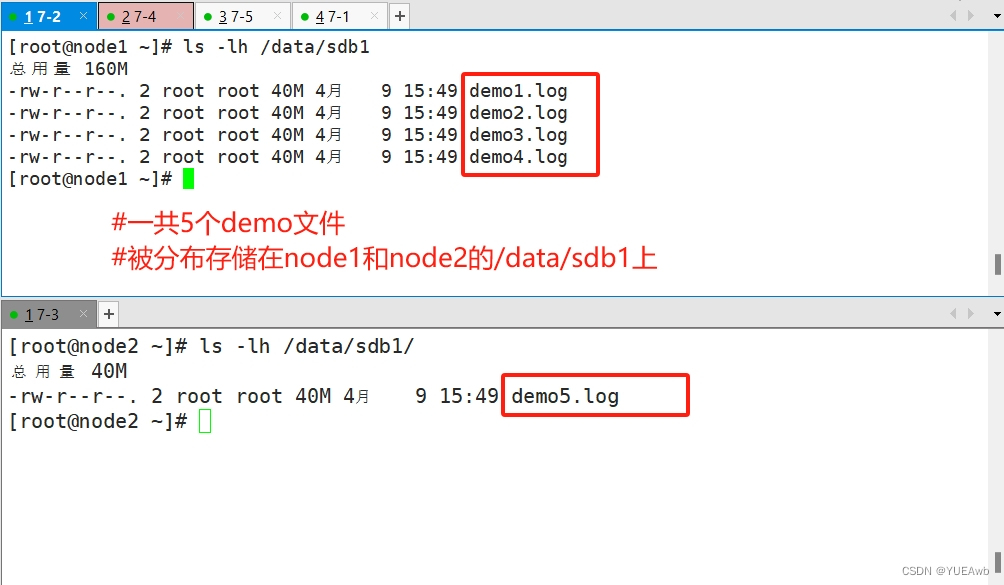
1. 查看分布式文件分布
没有数据分片
1. 因为我们之前做分布式卷的时候,指定就是node1和node2的sdb1磁盘
2. 所以我们查看文件分布的时候,要对应之前创建卷的时候的分布
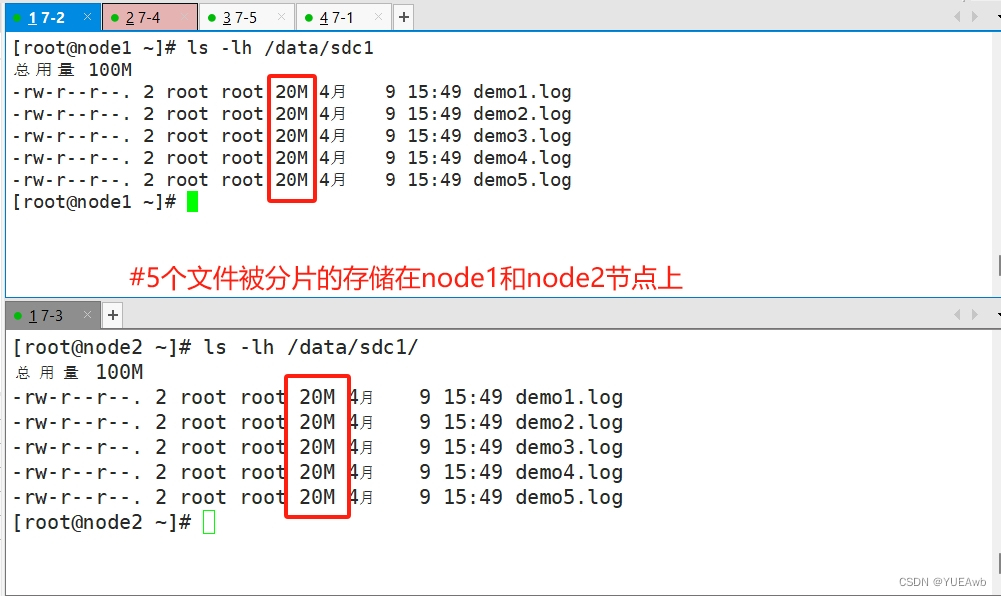
2.查看条带卷文件分布
数据被分片
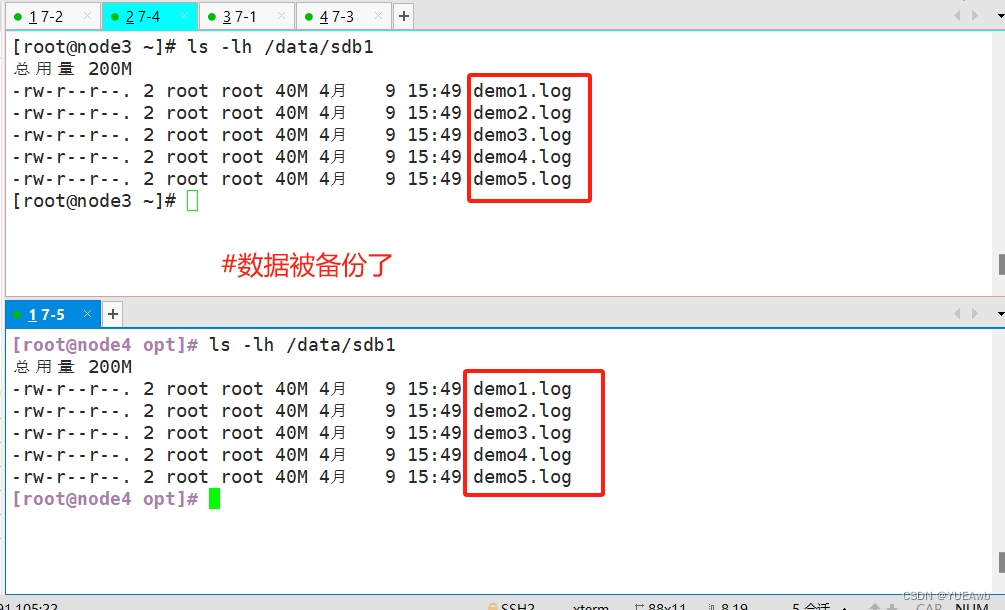
3.查看复制卷分布
数据备份了
4.查看分布式条带卷分布
数据被分布式存储;数据被分片

5.查看分布式复制卷分布
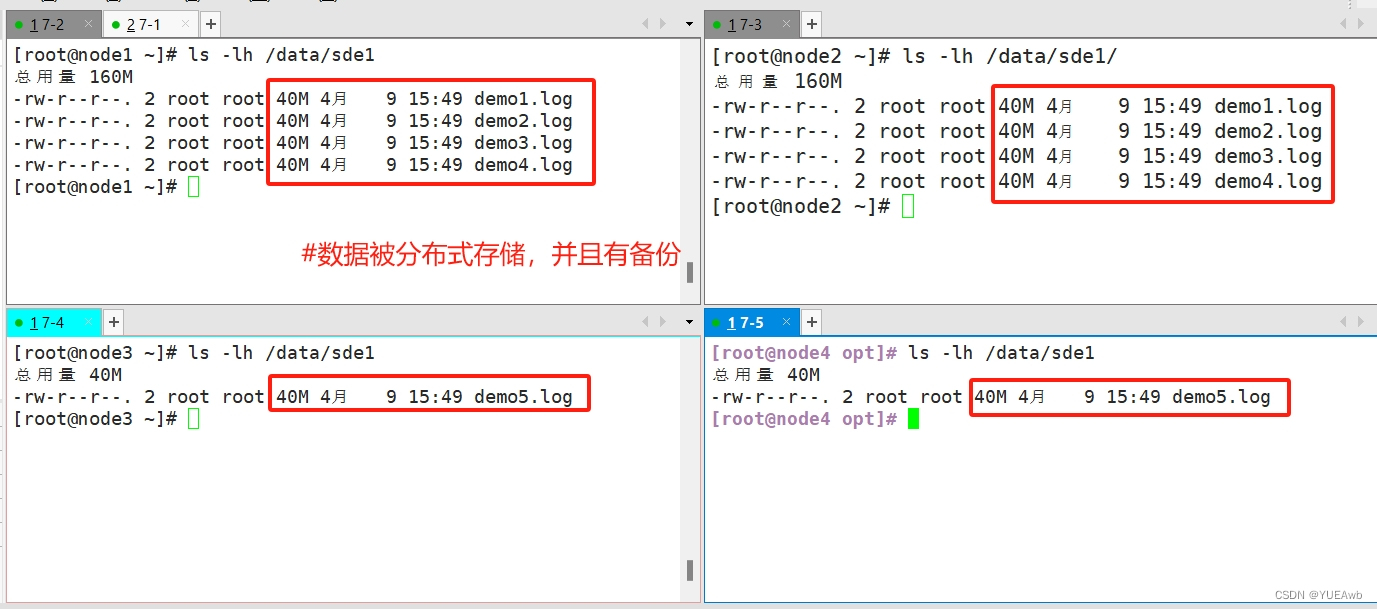
14.破坏性测试
1.挂起node2
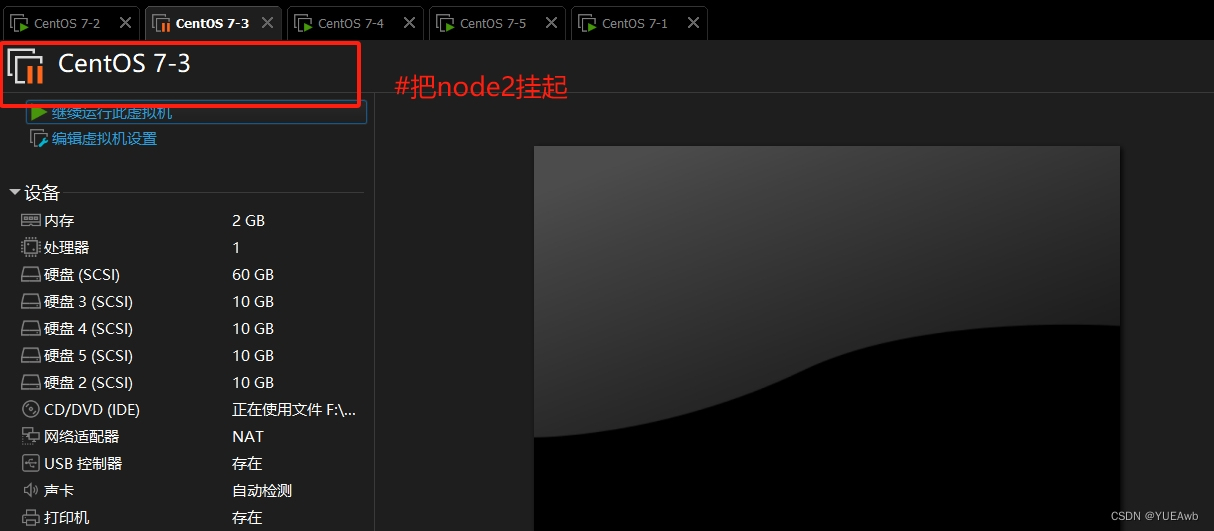
15.客户端查看破坏结果
1.查看分布式数据

2.查看条带卷数据

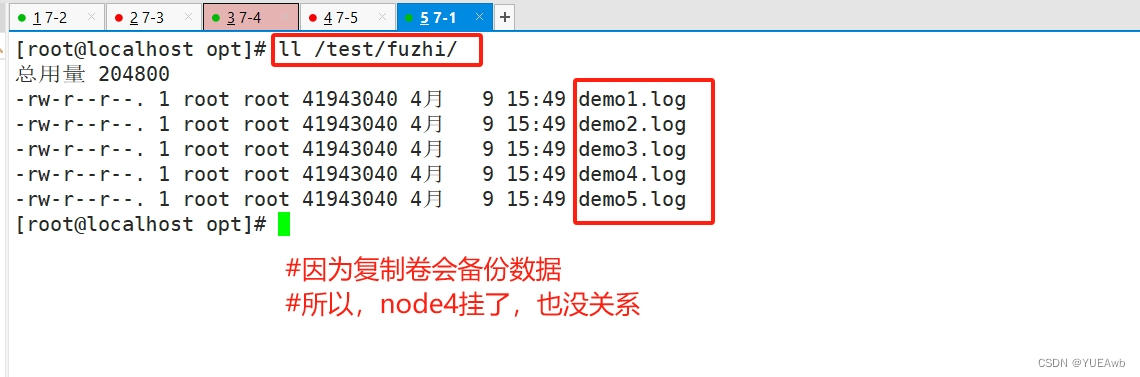
3.查看复制卷数据
因为我们把复制卷坐在了node3和node4上
所以,我们把node4挂起
4.查看分布式条带卷数据

5.查看分布式复制卷数据
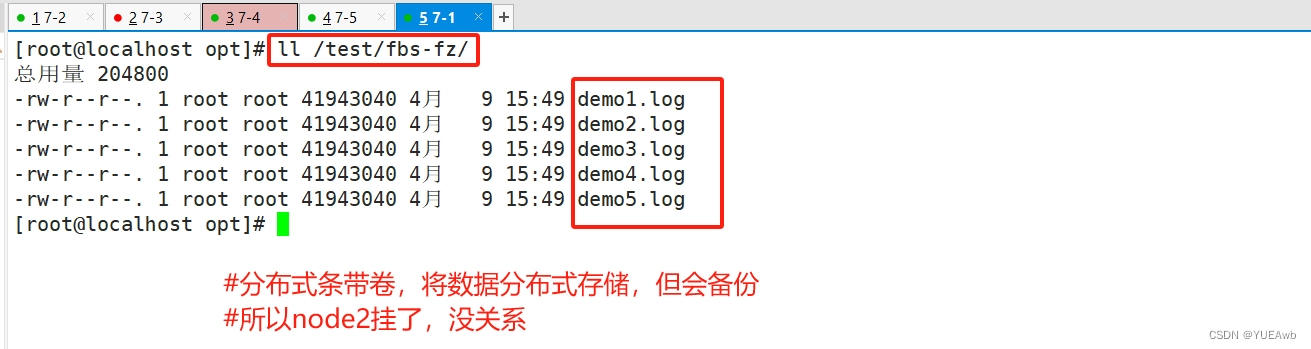
16、总结
##### 上述实验测试,凡是带复制数据,相比而言,数据比较安全 #####
#扩展其他的维护命令:
1.查看GlusterFS卷
gluster volume list
2.查看所有卷的信息
gluster volume info
3.查看所有卷的状态
gluster volume status
4.停止一个卷
gluster volume stop dis-stripe
5.删除一个卷,注意:删除卷时,需要先停止卷,且信任池中不能有主机处于宕机状态,否则删除不成功
gluster volume delete dis-stripe
6.设置卷的访问控制
#仅拒绝
gluster volume set dis-rep auth.deny 192.168.80.100
#仅允许
gluster volume set dis-rep auth.allow 192.168.80.* #设置192.168.80.0网段的所有IP地址都能访问dis-rep卷(分布式复制卷)