目录
一、类型转换
1、显式类型转换
2、隐式类型转换
二、算术转换
三、总结
每个编译器都会对表达式做两件事情,一是判断表达式中操作符的优先级和结合性,二是判断表达式中的操作数类型是否一致,如果不一致则需要进行类型转换。第一点在我前面的文章中已经讲解过了,这篇就特意来讲解一下第二点类型转换和算术转换。看看编译器是如何进行操作的。
一、类型转换
首先我们先来学习C语言中的类型转换,为什么要进行类型转换呢?因为C的整型算术运算总是至少以缺省整型类型的精度来进行的。编译器为了实现这个精度,所以会将表达式中操作数小于整型数据类型字节大小的数据转换为普通整型再进行运算,这种方法称为整型提升。如果有时候我们知道表达式中的数据需要进行转换,那我们就可以显示转换,如果有时候我们没有对数据进行显示转换,那么编译器就会隐式的帮我们转换。
所以,类型转换分为两种:显式类型转换和隐式类型转换。
显式类型转换:我们自己使用强制类型转换操作符进行数据类型转换。
隐式类型转换:编译器默认的帮我们转换。
那我们现在再来了解一个概念,编译器为什么要提升精度呢?这个就要从计算机层面进行分析,这是我从网上搜到的资料。
| 表达式的整型运算要在CPU的相应运算器内执行,也就是在CPU内整型运算器(ALU)。 ALU的操作数的字节长度一般就是int的字节长度(4个字节),同时也是CPU的通用寄存器的长度。 因此,即使两个char类型的相加,在CPU执行时实际上也要先转换为CPU内整型操作数的标准长度。 通用CPU(general-purpose CPU)是难以直接实现两个8比特字节直接相加运算(虽然机器指令中可能有这种字节相加指令)。所以,表达式中各种长度可能小于int长度的整型值,都必须先转换为int或unsigned int ,然后才能送入CPU去执行运算。 |
了解这些之后,我们就分别来学习一下两种方式的类型转换。
1、显式类型转换
int main()
{
//显式类型转换
float a = 10.55f;
float b = 13.14f;
float c = (int)a + (int)b;
printf("%f\n",c);
return 0;
}
大家看代码执行的结果,为什么两个浮点数相加之后,并且我用浮点数打印结果,却结果是不对的,应该打印正确的结果为23.690000。这是因为我对数据类型进行了显式转换的处理。
起到作用的代码主要是这一行:float c = (int)a + (int)b;首先变量a和变量b是浮点型存储在内存中的,然后我从内存中取出这两个变量的时候,就对他们进行了处理。处理的方式就是(int)a,意思就是把a的值取出来强制转换为int的数据类型,(int)c也是同样的处理,这样操作之后 (int)a + (int)b的结果就为10+13=23。最后再把23赋值给变量c,变量c在用浮点数的形式存储在内存中。所以最后打印出来的是23.000000。
看完这段代码是不是对显式类型转换有了一定的了解。这里提一个小小的建议,在以后写代码的时候,如果你知道自己需要使用什么样的数据类型,就提前定义好数据类型,尽量少在表达式中使用显式类型转换。这样可能会给你的代码带来潜在的危害。C语言标准有这个操作,说明也有它的好处存在,所以大家根据需要决定使用。
2、隐式类型转换
隐式这词见名思意就知道是我们不显式的写类型转换,让编译器根据代码的实际情况,判断要不要进行数据转换。编译器隐式转换的主要方法就是整型提升。
编译器是如何进行整型提升的呢?整形提升是按照变量的数据类型的符号位来提升的。下面给大家画图演示一下。

不管是short类型还是char类型,在表达式中进行运算的时候编译器都会按照图片中的方法进行整型提升。以方便CPU进行计算。
我们再来看一个例子:
char c = -1;
printf("%d\n",sizeof(c));
printf("%d\n", sizeof(+c));
printf("%d\n", sizeof(-c));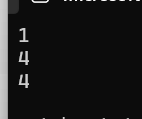
为什么同样用sizeof操作符求变量c的字节大小的时候,结果会不一样呢?这就是因为编译器在运行代码的时候,进行表达运算的时候,表达式中的数据类型有小于int字节大小的数据都会被隐式的整型提升操作。sizeof(+c)、sizeof(-c)中的c都做了表达式运算,所以被整型提升了,最后sizeof求的是int类型的字节数。
总结:显式类型转换就是可以随便转换我们想要的数据类型。而这里的隐式转换只是在表达式中,操作数的数据类型有小于int类型的数据转换为int大小的数据,也就是整型提升。这种只是隐式转换的一种形式,还有另外一种形式。
二、算术转换
这里的算术转换其实就是上面所说的隐式转换的第二种形式。这里的算术转换的都是大于等于int类型的数据。算术转换就是在一个表达式中,有两个不同数据类型的操作数,那么编译器就会隐式的转换为一种数据类型,然后进行运算。那编译器是如何判断将两种不同的数据类型转换成一个呢?那请看下面。
long double
double
float
unsigned long int
long int
unsigned int
int编译器在隐式转换类型的依据就是把精度低的数据类型转换成精度高的数据类型。上面图片就是各种数据类型的精度排行,从下往上就是代表精度从低到高。
int a = 20;
float b = 5.23f;
int c = a + b;上面的代码中,有两个不同的数据类型变量,在进行 int c = a + b; 表达式运算的时候,会有一个隐式转换的过程。因为int 类型比 float类型的精度低,所以编译器会先把变量a隐式转换为float类型的数据,然后再把两个float类型的a和b进行相加。
注意:虽然编译器会帮我们隐式转换数据类型,提高数据类型精度。但我们还是要合理使用它。比如下面的代码就会带来潜在的问题。

本来我们想要把变量f的值给变量num,但是这里会有一个隐式转换,会把float类型隐式转换为int类型,这样就会导致数据的精度丢失。所以我们要合理的使用它,这种潜在的问题在调试bug的时候不容易找出来。
三、总结
这节主要讲了类型转换的操作,类型转换主要分为显式类型转换和隐式类型转换。隐式类型转换又分为整型提升和算术转换两个操作。整型提升的用途主要是在表达式中,有数据类型小于int类型大小的,编译器就会隐式的把小于int类型的数据转换为int类型的数据。算术转换的用途就是在表达式中,操作数的数据类型都是大于等于int 类型,并且数据类型不一致,这个时候编译器就会隐式算术转换。两种隐式转换都有一定的潜在问题,大家都要合理使用。
谢谢大家~~