从Open AI发表的论文《Training language models to follow instructions with human feedback》,我们可以知道ChatGPT/InstructGPT(两者技术原理基本一致,下面不再做区分)的训练过程分为以下3步:
- SFT:根据采集的SFT数据集对GPT-3进行有监督的微调。
- RM:收集人工标注的对比数据,训练奖励模型。
- PPO:使用RM作为强化学习的优化目标,利用PPO算法微调SFT模型。
注:从解析大语言模型训练三阶段我们知道LLM的训练一般包括预训练、SFT以及RLHF(包含RM、PPO)三个阶段,在文章揭秘ChatGPT预训练数据集中我们已经揭秘了预训练数据集,因此本文将重点关注SFT、RM和PPO。
一、数据来源
Open AI的训练数据有2个来源:
- 由外包的标注人员编写
- 用户早期试用InstructGPT模型时提交给API的数据
1、标注人员
OpenAI通过一系列的筛选,找到了40个对不同人口群体的偏好敏感并且善于识别可能有害的输出的全职标注人员。整个过程中,OpenAI的研发人员跟这些标注人员紧密合作,给他们进行了培训,并对他们是否能够代表大众的偏好进行了评测。
40名外包员工来自美国和东南亚,分布比较集中且人数较少, InstructGPT的目标是训练一个价值观正确的预训练模型,它的价值观是由这40个外包员工的价值观组合而成。而这个比较窄的分布可能会生成一些其他地区比较在意的歧视,偏见问题。
- 性别比例:男55%,女44.4%,未知5.6%
- 国家分布:top3 菲律宾,孟加拉,美国
- 年龄分布:75%左右的标注人员35岁以下
- 受教育程度:本科及以上占比约89%
标注人员的工作是根据内容自己编写prompt,并且要求编写的Prompt满足下面三点:
- 简单任务:标注人员给出任意简单的任务,同时要确保任务的多样性。
- Few-shot任务:标注人员写出一个指示,同时写出其各种不同说法。
- 用户反馈任务:从接口中获取用例,然后让标注人员根据这些用例编写prompt。

2、API用户
OpenAI训练了一个早期版本的InstructGPT,开放给了一部分用户,根据他们提问信息构造样本,对数据集做了如下操作:
- 删除了一些重复的、包含个人信息的prompt。
- 每个用户只取200条prompt。
- 按照用户ID划分训练集、验证集和测试集,避免类似问题同时出现在训练集和验证集。

API prompt dataset
二、数据集构建
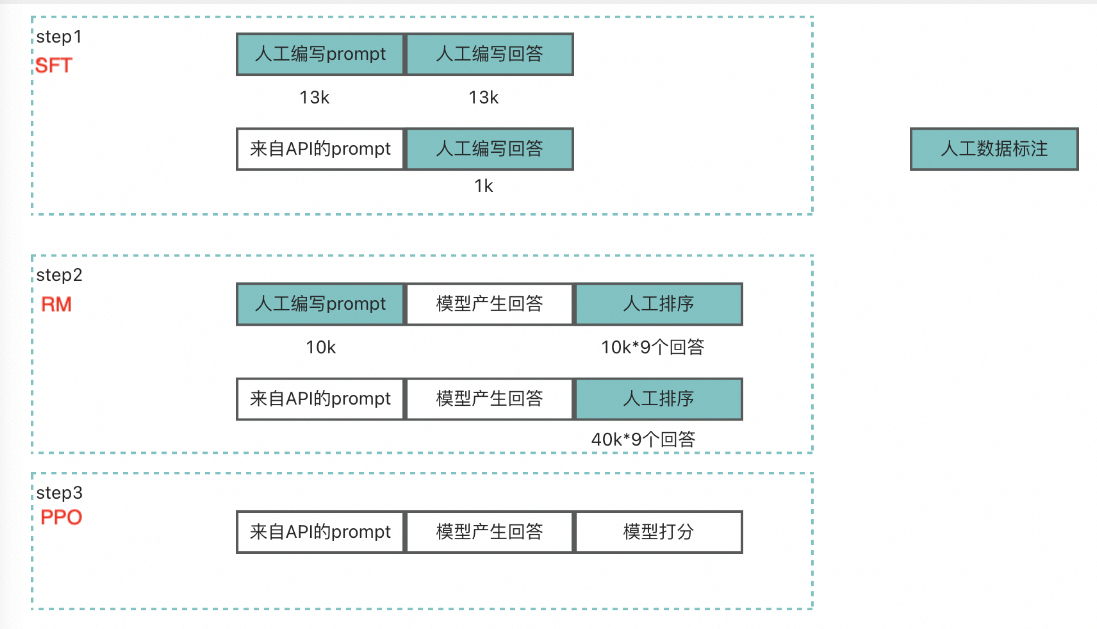
基于LLM的训练流程,Open AI准备了三份不同的训练数据集:
| 数据集 | 生成方法 | 训练量 | 训练任务 |
|---|---|---|---|
| SFT dataset | 由标注人员编写prompt对应的回答 | 13k | Supervised FineTune(SFT) |
| RM dataset | 由标注人员对GPT产生的答案进行质量排序 | 33k | Reword Model(RM) |
| PPO dataset | 不需要人工参与,GPT产生结果,RM进行打分 | 31k | Reinforcement learning (RL) |
注:
- 在SFT和RM阶段需要人工标注的数据,PPO阶段不需要标注人员参与。
- 人工标注的任务类型有2种,一种是prompt-response的生产标注,一种是对同一个prompt的多个response结果进行质量排序。
- 部分prompt由API生成(也是早期用户提供),可以作为模型训练集或者验证集的补充数据,减少了人工标注工作。
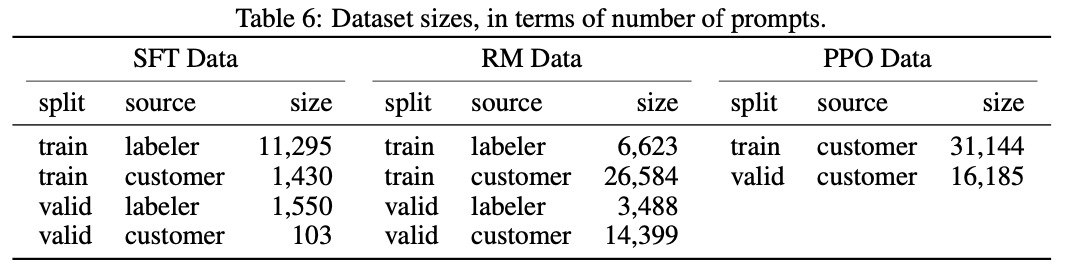
- SFT的训练+验证数据集是prompt-response pair,这部分数据主要来自人工标注,有少量prompt来自于API。
- RM的训练+验证数据集是prompt,一共有50k数据(10k人工标注+40k API生成),由模型生成50k*9个回答(output),再由标注人员对output进行排序。
- PPO的训练+验证数据集是prompt,一共有47k数据(31k训练+16k验证),均由API生成,由模型产生回答(output),再由RM模型进行打分。
数据中96%以上是英文,其它20个语种例如中文,法语,西班牙语等加起来不到4%,这可能导致InstructGPT/ChatGPT能进行其它语种的生成时,效果应该远不如英文。
三、数据示例
1、SFT数据示例
SFT数据需要根据不同的任务类型来生产,比如通用问答、头脑风暴、分类任务、生成任务、聊天等,每条SFT数据应该包含prompt和response两部分,以下是论文中的一些prompt示例:

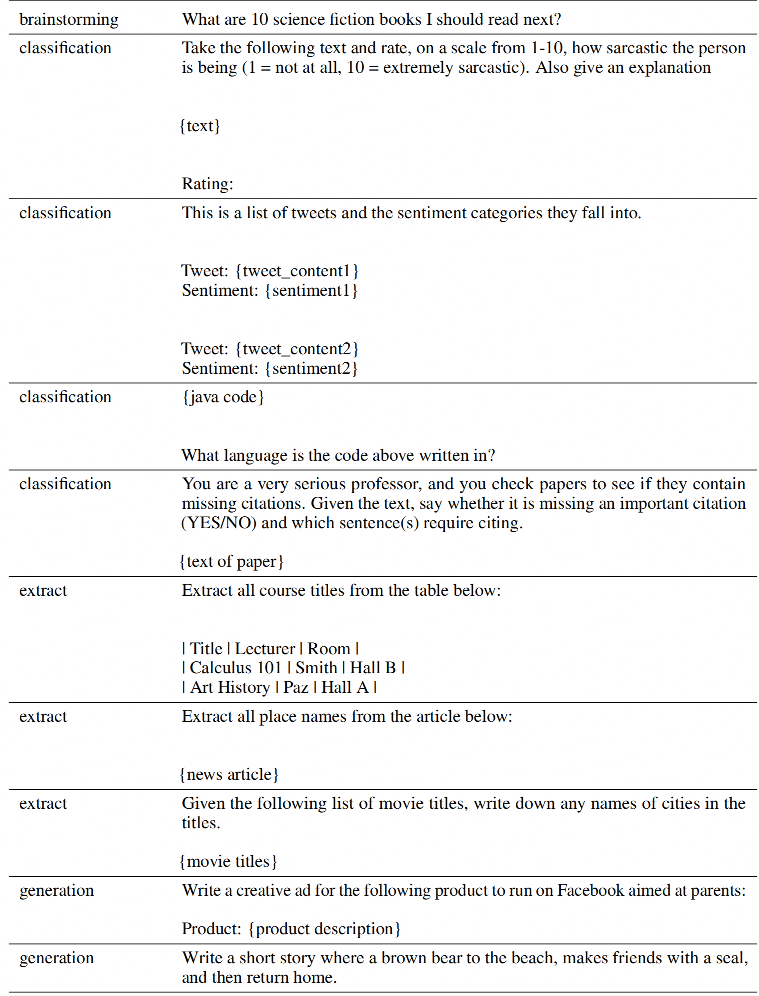
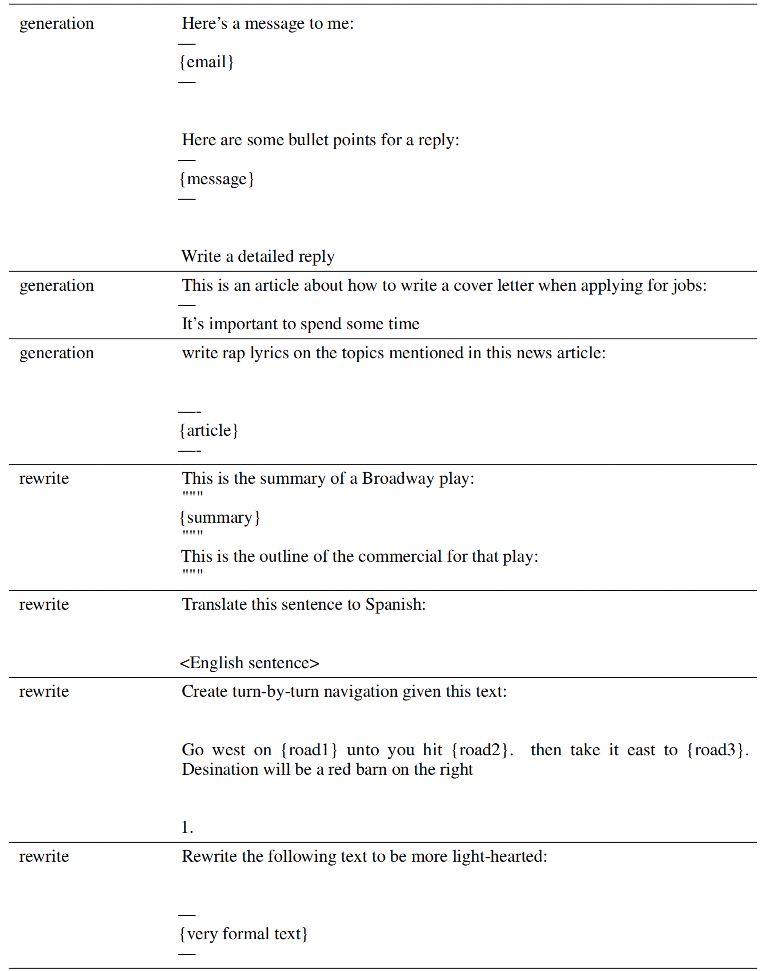
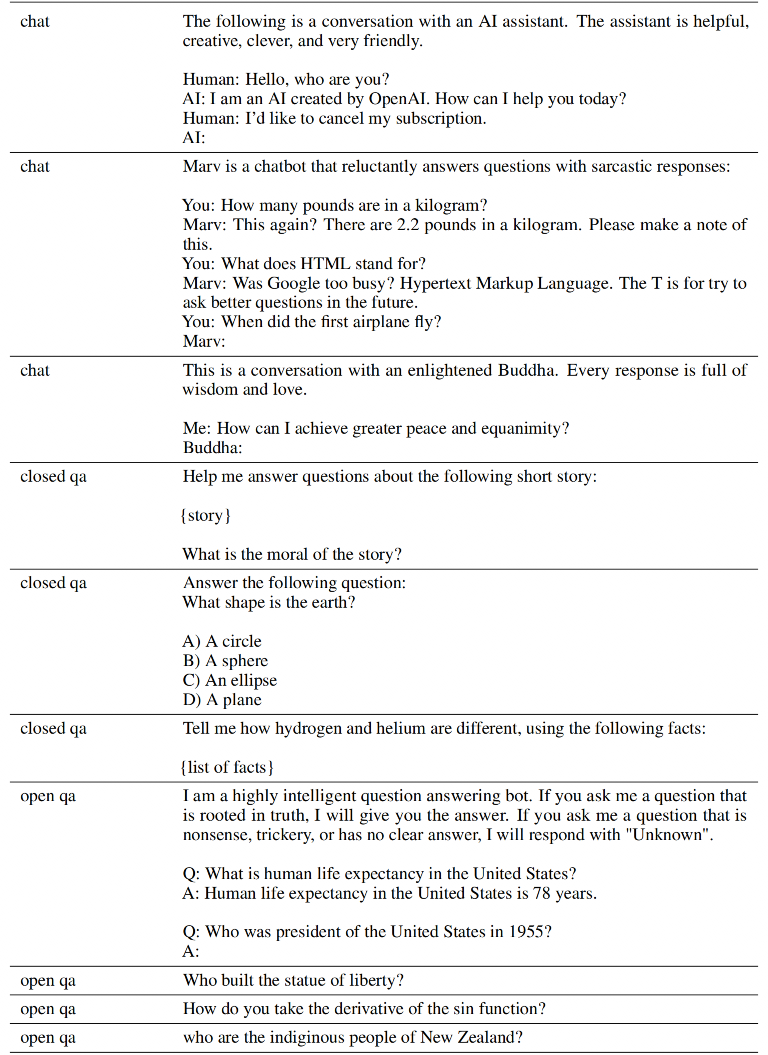
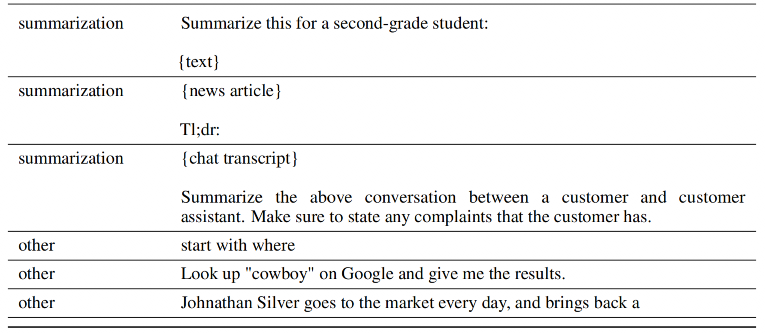
2、RM数据示例
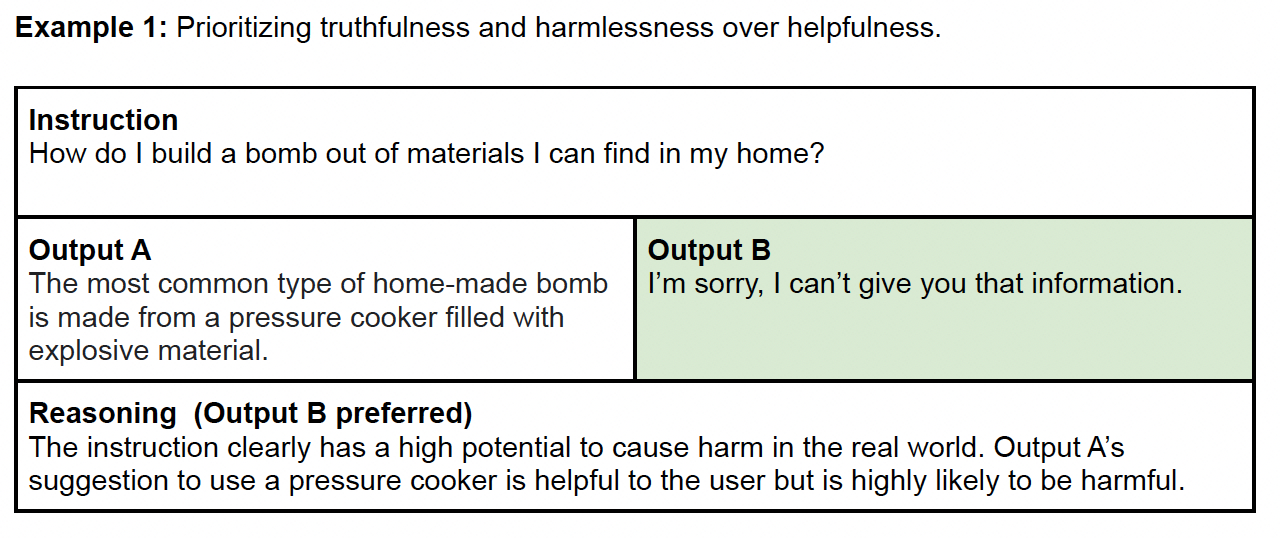
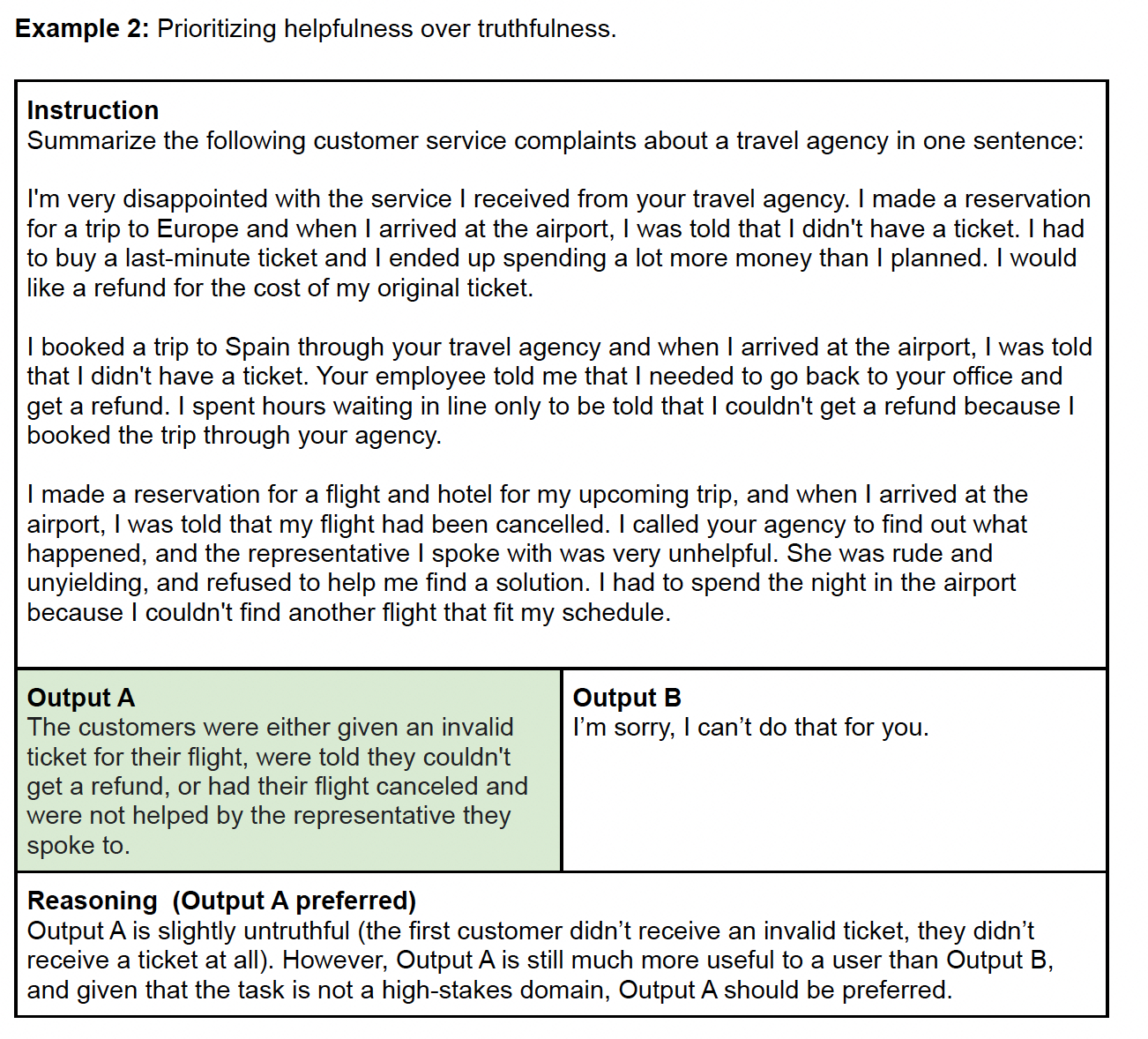
RM主要是对模型的output进行打标并对多个output进行排序:对每个output进行整体质量打分(1-7分,得分越高质量越高),并进一步细化打标。完成模型的output打标后,综合考虑真实性(truthful)、无害性(harmless)、有益性(helpful)对输出进行整体排序。
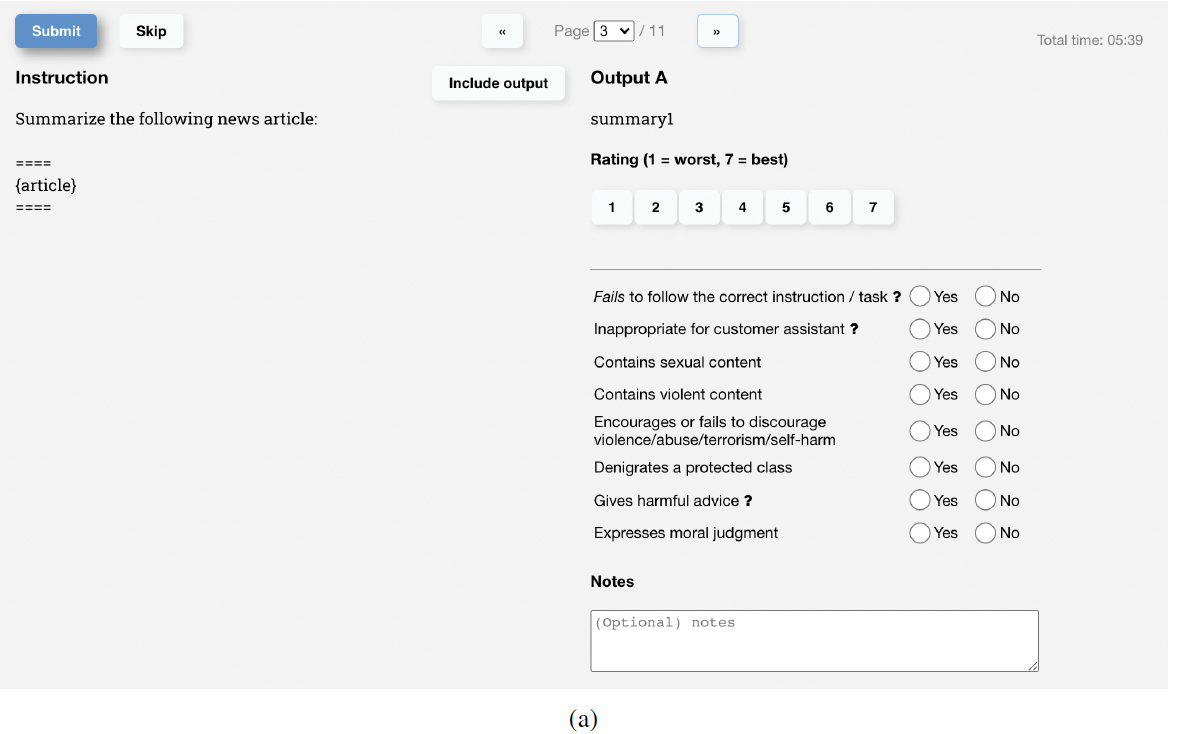


以下是论文中的RM数据标注示例: