在人工智能领域,尤其是自然语言处理(NLP)的子领域——问答系统(QA)中,知识的获取和利用一直是推动技术进步的核心问题。近年来,大语言模型(LLMs)在各种任务中展现出了惊人的能力,但它们在处理知识密集型任务时仍然存在局限性。为了解决这一问题,研究者们提出了多种知识增强方法,如检索增强生成(Retrieval-Augmented-Generation, RAG)和生成增强生成(Generation-Augmented-Generation, GAG)。然而,这些方法不仅依赖外部资源,而且需要将显式文档整合到上下文中,导致更长的上下文和更多的资源消耗。
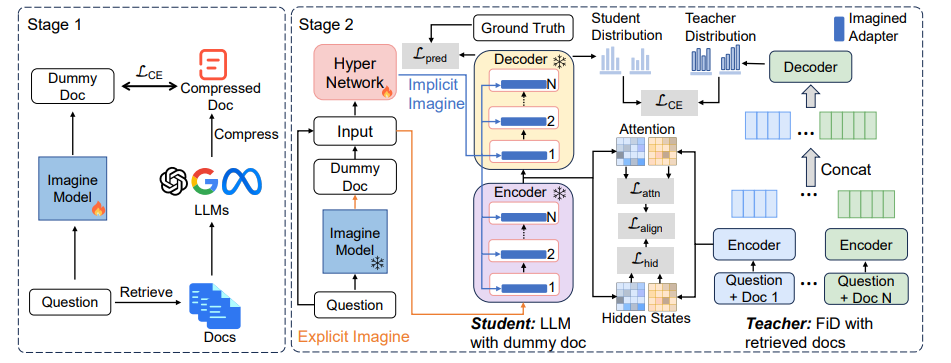
最新的研究表明,LLMs内部已经建模了丰富的知识,只是这些知识没有被有效地触发或激活。受此启发,研究者提出了一种新的知识增强框架——想象增强生成(Imagination-Augmented-Generation, IAG),它模拟人类在回答问题时,仅通过想象来弥补知识缺陷的能力,而不依赖外部资源。在IAG的指导下,研究者提出了一种问答方法——想象丰富上下文的方法(IMcQA),通过两个模块获得更丰富的上下文:通过生成短虚拟文档的显式想象和通过HyperNetwork生成适配器权重的隐式想象。实验结果表明,IMcQA在开放域和闭卷设置中,以及在分布内性能和分布外泛化中都展现出显著优势。
分享几个网站
GPT-3.5研究测试:
https://hujiaoai.cn
GPT-4研究测试:
https://higpt4.cn
Claude-3研究测试(全面吊打GPT-4):
https://hiclaude3.com
论文标题:
Imagination Augmented Generation: Learning to Imagine Richer Context for Question Answering over Large Language Models
论文链接:
https://arxiv.org/pdf/2403.15268.pdf
知识增强方法的发展回顾
1. RAG与GAG方法简介
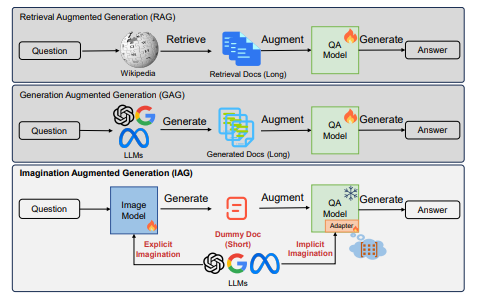
Retrieval-Augmented-Generation (RAG) 和 Generation-Augmented-Generation (GAG) 是两种旨在增强大语言模型(LLMs)在问答任务中所需知识的方法。
RAG 方法通过检索外部资源(如辅助工具和领域文档)中的相关文档,并将这些文档与问题一起输入到 LLMs 中。例如,FiD 方法就是一种典型的 RAG 方法,它需要处理大量的检索文档,随着文档数量的增加,计算资源和推理时间也随之增长。
相比之下,GAG 方法则利用像 InstructGPT 这样的 LLMs 生成相关文档,避免了对外部资源的依赖,但仍需要额外的财务成本(如 API 调用)并且同样需要大量的计算资源和时间。
2. 现有方法的局限性
尽管 RAG 和 GAG 方法在多个任务上展示了强大的性能,但它们都存在一些局限性。
-
首先,RAG 方法不仅需要预设的外部资源,而且还需要更多的计算资源和更长的处理时间。
-
此外,RAG 和 GAG 方法都使用了更多的显式外部资源(象征性文档),而获取的内容质量显著影响下游任务。例如,文档中的噪声会对性能产生负面影响。
因此,迫切需要探索新的知识增强方法。
提出IAG框架的动机与概念
1. IAG框架的定义与目标
Imagination-Augmented-Generation (IAG) 是一种新的知识增强框架,旨在模拟人类在问答任务中仅通过想象来弥补知识缺陷的能力,而不依赖外部资源。IAG 框架的目标是充分利用 LLMs 内在的知识,通过两个主要模块——显式想象和隐式想象——来激活 LLMs 中的各种潜在知识建模,并获取更丰富的上下文。
2. 与RAG和GAG的对比
与 RAG 和 GAG 相比,IAG 框架不依赖外部资源,而是完全利用 LLMs 的内在知识。IAG 通过显式想象模块生成一个简短的虚拟文档,并通过隐式想象模块使用 HyperNetwork 生成适配器权重,从而激活 LLMs 的任务处理能力。这种方法不仅避免了对外部资源的依赖,而且在提取和激活内部知识方面更为高效。实验结果表明,IAG 在开放域和闭卷设置中都展现出显著优势,无论是在分布内性能还是分布外泛化方面。
IMcQA方法详解
1. 显式想象与长文本压缩
IMcQA方法的显式想象模块首先使用符号蒸馏来获取压缩的上下文,然后指导大语言模型(LLMs)生成一个简短且有用的虚拟文档。这个过程使得LLMs能够构想与问题知识需求紧密相连的压缩知识。在这个模块中,通过预训练Imagine Model来激活LLMs的长文本建模能力,使得处理短文本的QA模型也能像处理长文本的QA模型一样具有丰富的上下文理解能力。
2. 隐式想象与HyperNetwork的应用
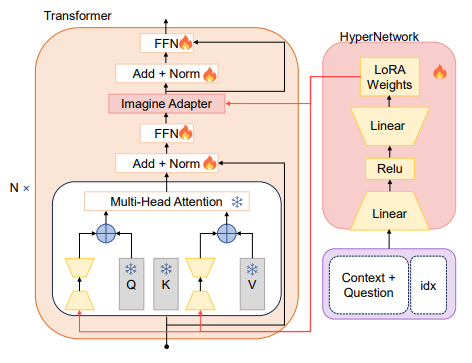
隐式想象模块利用提出的HyperNetwork来生成LoRA权重,以激活LLMs的任务处理能力。与LoRA存储任务知识和能力的模块不同,HyperNetwork学习为每个问题想象隐藏的知识。HyperNetwork的架构详细描述在Figure 3中,它接受连接的特征向量和位置嵌入作为输入,并生成LoRA适配器的权重。这类似于在提示中重复问题,并加入特定的主题线索来刺激模型回忆相关问题,但我们生成的是模型参数。
3. 训练过程中的长文本蒸馏
在知识蒸馏的框架下,考虑长文本蒸馏(LCD) 作为主要指导学生模型的上下文化知识。具体来说,教师模型FiD利用较长的上下文输入并理论上包含更多信息(更丰富的上下文),将激活更具体的内部知识并作为监督模型。教师模型帮助学生模型T5(具有与教师相同大小的模型)利用短文本输入,以激活更丰富的特征表示和知识。学生模型在每个小批量zr = (xr, yr)上的优化目标是最小化教师和学生模型之间隐藏状态的余弦距离和注意力矩阵的均方误差。
实验设置与评估指标
1. 数据集介绍
研究者们在三个公开的问答数据集上评估提出的方法:NaturalQuestions (NQ)、WebQuestions (WQ) 和 TriviaQA (TQA)。为了评估模型性能,研究者们使用精确匹配(EM)分数来评估预测答案。
2. 基线方法与对比
研究者考虑了中等大小的语言模型(< 1B)和大语言模型(LLM)(≥ 3B)。选择T5作为中等大小语言模型的骨干。研究者将提出的IMcQA与几种知识增强方法进行比较,包括RAG模型如DPR、RAG和FiD,以及GAG模型GENREAD和参数高效微调方法LoRA。
对于LLMs的零样本设置(≥ 3B),研究者使用Llama2-7B和Llama2-13B作为基础模型。在四种不同的设置下进行评估:无检索、有检索、使用LoRA和使用提出的IMcQA。
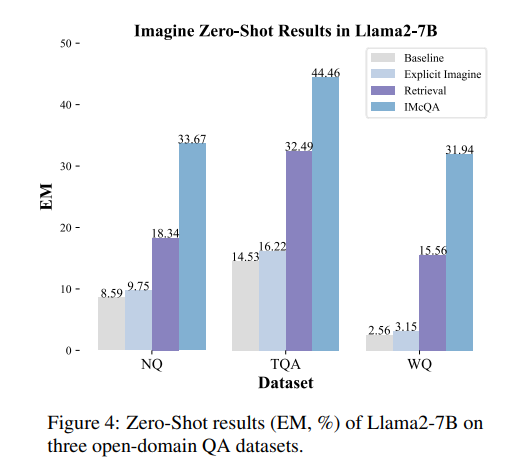
在预训练阶段,使用T5-large初始化的Imagine Model使用生成的问题压缩对。在第二阶段,教师模型使用不同大小的FiD阅读器在目标数据集的训练分割上进行微调。学生模型冻结了骨干网络,仅更新HyperNetwork、前馈神经网络(FFN)和归一化层。
主要实验结果与分析
1. IMcQA的性能表现
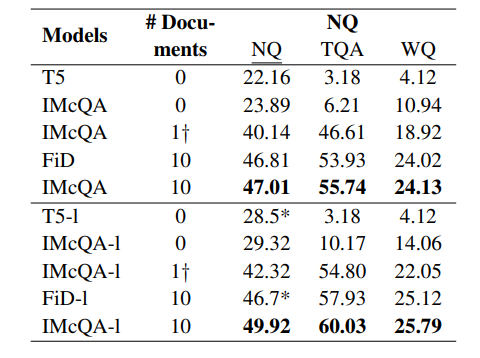
IMcQA方法在三个开放域问答数据集上的实验结果表明,该方法能够有效地激活LLMs内部的相关知识,从而在开放域和闭卷设置下都展现出显著的优势。具体来说,在闭卷设置中,IMcQA相比基线方法平均提高了2%的准确率,这表明IMcQA能够通过想象来更有效地利用内部知识。在开放域设置中,尽管IMcQA只处理一个短的虚构文档,但其性能仍然与处理10个文档的RAG和GAG方法相当或更好,这进一步证明了IMcQA通过想象压缩文本来平衡效率和开销。
2. 开放域与闭卷设置下的表现
在开放域和闭卷设置下,IMcQA展现出了卓越的性能。在闭卷设置中,IMcQA通过激活LLMs内部的知识,达到了优于传统闭卷模型的性能。在开放域设置中,IMcQA利用单个想象的文档就能达到或超过处理多个文档的传统方法,这一结果凸显了IMcQA在提高问答性能方面的有效性。
3. 超出分布(OOD)性能分析
IMcQA在超出分布(OOD)的泛化能力上也展现出了优异的性能。通过在NQ数据集上训练并在其他两个数据集上测试,IMcQA在使用单个想象文档时与使用10个检索文档的FiD方法性能相近,且在使用10个检索文档时,IMcQA的性能普遍优于FiD方法。这表明IMcQA通过HyperNetwork生成的LoRA适配器权重,能够根据问题激活和访问内部知识,从而在OOD场景下展现出更好的性能。
零样本设置下的实验结果
1. Llama2模型的性能提升
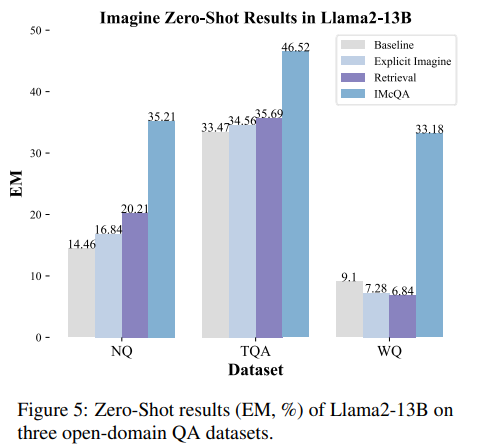
在零样本设置下,Llama2模型通过自主想象知识,展现出了性能的显著提升。尽管通过显式想象的上下文能够使平均准确率提高1%,但这种提升不如通过检索10个文档所实现的显著。IMcQA通过两种主要的想象过程,分别在NQ、TQA和WQ数据集上将EM提高了+15.33%、+11.97%和+16.38%。这表明即使在零样本设置下,IMcQA方法仍能为LLMs带来实质性的性能提升。
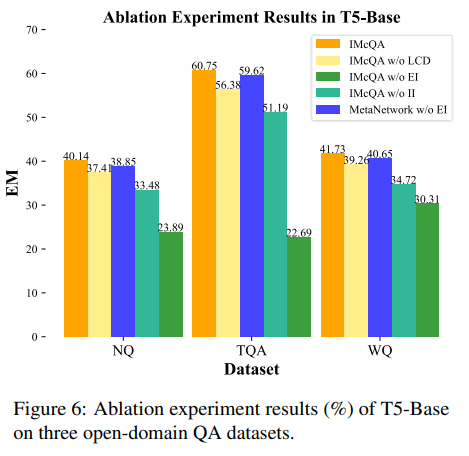
2. 显式与隐式想象的作用分析
通过对IMcQA中显式想象(EI)和隐式想象(II)的分析,发现这两种想象过程对于激活LLMs内部知识至关重要。长文本蒸馏(LCD)和EI在HyperNetwork中的应用对总体结果有边际贡献,这验证了更广泛的上下文倾向于优化性能,尽管收益有限。
训练成本与推理速度分析
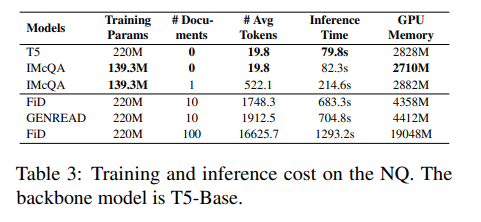
在评估IMcQA方法的有效性的同时,训练成本和推理速度也是重要的考量因素。根据实验结果,IMcQA在训练和推理阶段都展现出了一定的优势。
具体来说,IMcQA通过共享的HyperNetwork生成LoRA适配器权重,从而减少了参数更新的需求。尽管由于知识蒸馏的限制,训练过程中并没有显著的速度优势,但在推理阶段,IMcQA的设计极为轻量级,显著降低了处理令牌的数量,同时在性能上要么超过了其他方法,要么与之相差无几。这表明IMcQA在效率和计算需求之间取得了良好的平衡。
此外,与GAG方法相比,IMcQA不需要额外的财务成本(例如API调用),并且由于模型尺寸的减小,生成速度更快。在NQ数据集上,使用T5-Base作为基础模型,在单个RTX 3090 GPU上进行的实验表明,标准批量大小为8的训练和批量大小为1的推理,IMcQA在5000步训练时间和GPU时间上的推理速度都有所提升。
总的来说,IMcQA方法在训练成本和推理速度上都显示出了其优势,尤其是在推理阶段的轻量级设计,使其在保持竞争力的性能的同时,大幅减少了资源消耗。
总结与未来工作方向
IAG与IMcQA方法的贡献
本研究提出了一种新颖的知识增强框架——想象增强生成(IAG),以及一个基于此框架的问题回答方法——IMcQA。IAG框架模拟人类在回答问题时补偿知识缺陷的能力,仅通过想象而不依赖外部资源。
IMcQA方法通过显式想象和隐式想象两个主要模块,有效激活并利用LLMs内在的知识,获得更丰富的上下文。实验结果表明,IMcQA在开放域和闭卷设置中都显示出显著优势,无论是在分布内性能还是在分布外泛化方面。
面临的挑战与未来研究方向
尽管IMcQA在问题回答任务中取得了显著成就,但仍存在一些限制和挑战。
-
首先,目前的方法专门针对QA任务,其在其他知识密集型任务(如事实核查或对话系统)中的有效性尚未得到验证。
-
其次,本研究仅考虑了想象文本和隐藏表示,未来工作需要探索包括想象图像在内的多模态信息对性能的影响。
-
此外,目前的方法依赖于LLMs在预训练阶段学到的知识,这可能限制了模型快速适应新信息的能力。IAG中的内部知识激活可能导致模型决策过程不够透明,使得生成答案的逻辑难以解释。
因此,未来需要继续探索适应性知识增强方法,以进一步优化结果。
综上所述,未来的研究方向将包括将IAG应用于更多NLP任务,探索多模态知识增强生成,并改进方法以适应新信息,同时提高模型决策过程的透明度。