这章写点Groq干货,理性的分析。
首先是Articical Analysis的关于Mixtral8*7B的吞吐比较
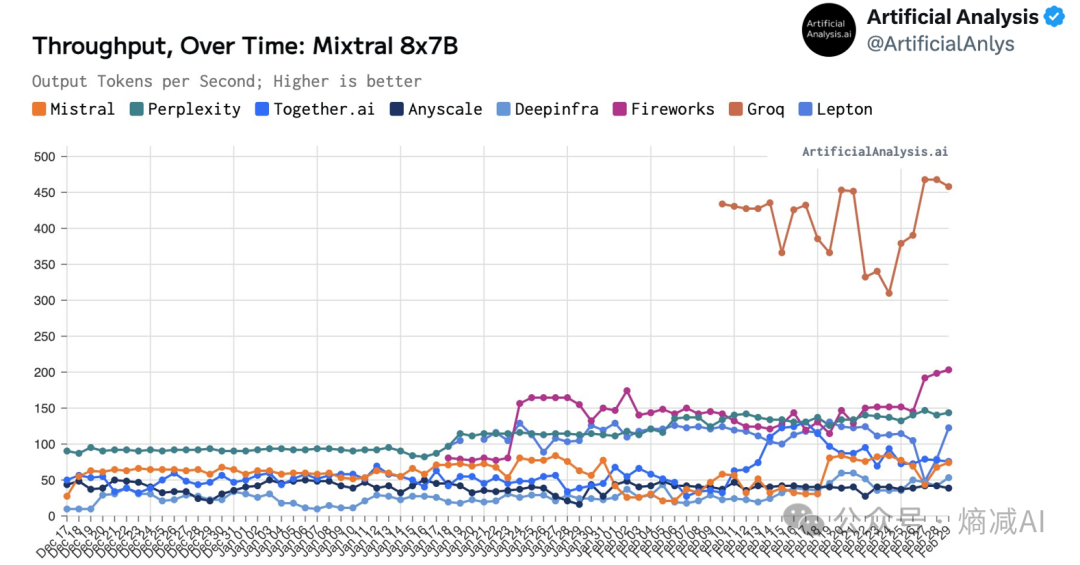
上图是有Mixtral 8*7BPaaS服务的AI服务商,Mistral自己居然排倒数第三

,Groq是真的遥遥领先啊。
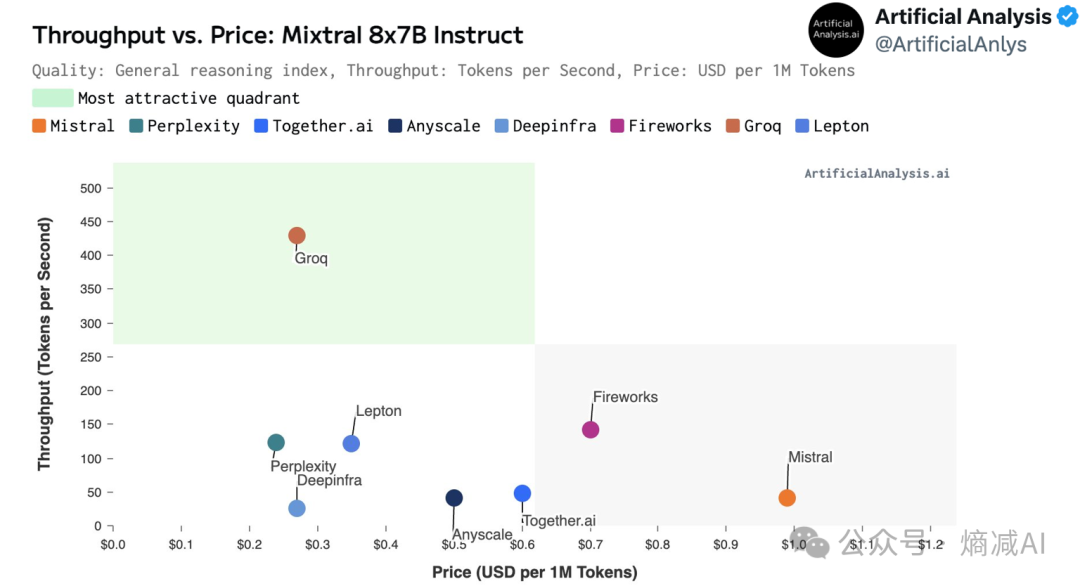
另外这个图是比较每100万tokens的cost,无论是推理速度还是cost,Groq都是遥遥领先的,而下面这些服务,比如perplexity,Mistral这些网站,他们的服务肯定都是构建在Nvidia的硬件上的,那为什么Groq能领先Nvidia这么多?
硬件的数据在这篇文章里,其实看一下,它的纸面数据并不怎么好
怎么看待Groq (qq.com)

实际上LLM在推理时和训练时的方式是完全不同的,推理就是一个前向计算的过程,也没有反向传播,推理其实也分为两个阶