分享一下基于transformer的时间序列预测模型python代码,给大家,记得点赞哦
#!/usr/bin/env python
# coding: 帅帅的笔者
import torch
import torch.nn as nn
import numpy as np
import pandas as pd
import time
import math
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
# Set random seeds for reproducibility
torch.manual_seed(0)
np.random.seed(0)
# Hyperparameters
input_window = 10
output_window = 1
batch_size = 250
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
epochs = 100
lr = 0.00005
# Load data
df = pd.read_csv("data1.csv", parse_dates=["value"], index_col=[0], encoding='gbk')
data = np.array(df['value']).reshape(-1, 1)
# Normalize data
scaler = MinMaxScaler(feature_range=(-1, 1))
data_normalized = scaler.fit_transform(data)
# Split the data into train and validation sets
train_ratio = 0.828
train_size = int(len(data) * train_ratio)
val_size = len(data) - train_size
train_data_normalized = data_normalized[:train_size]
val_data_normalized = data_normalized[train_size:]
# Define the Transformer model
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
return x + self.pe[:x.size(0), :]
class TransAm(nn.Module):
def __init__(self, feature_size=250, num_layers=1, dropout=0.1):
super(TransAm, self).__init__()
self.model_type = 'Transformer'
self.src_mask = None
self.pos_encoder = PositionalEncoding(feature_size)
self.encoder_layer = nn.TransformerEncoderLayer(d_model=feature_size, nhead=10, dropout=dropout)
self.transformer_encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=num_layers)
self.decoder = nn.Linear(feature_size, 1)
self.init_weights()
def init_weights(self):
initrange = 0.1
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform_(-initrange, initrange)
def forward(self, src):
if self.src_mask is None or self.src_mask.size(0) != len(src):
device = src.device
mask = self._generate_square_subsequent_mask(len(src)).to(device)
self.src_mask = mask
src = self.pos_encoder(src)
output = self.transformer_encoder(src, self.src_mask)
output = self.decoder(output)
return output
def _generate_square_subsequent_mask(self, sz):
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
# Create the dataset for the model
def create_inout_sequences(data, input_window, output_window):
inout_seq = []
length = len(data)
for i in range(length - input_window - output_window):
train_seq = data[i:i+input_window]
train_label = data[i+input_window:i+input_window+output_window]
inout_seq.append((train_seq, train_label))
return inout_seq
train_data = create_inout_sequences(train_data_normalized, input_window, output_window)
val_data = create_inout_sequences(val_data_normalized, input_window, output_window)
# Train the model
model = TransAm().to(device)
criterion = nn.MSELoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.95)
def train(train_data):
model.train()
total_loss = 0.
for i in range(0, len(train_data) - 1, batch_size):
data, targets = torch.stack([torch.tensor(item[0], dtype=torch.float32) for item in train_data[i:i+batch_size]]).to(device), torch.stack([torch.tensor(item[1], dtype=torch.float32) for item in train_data[i:i+batch_size]]).to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, targets)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)
optimizer.step()
total_loss += loss.item()
return total_loss / len(train_data)
def validate(val_data):
model.eval()
total_loss = 0.
with torch.no_grad():
for i in range(0, len(val_data) - 1, batch_size):
data, targets = torch.stack([torch.tensor(item[0], dtype=torch.float32) for item in val_data[i:i+batch_size]]).to(device), torch.stack([torch.tensor(item[1], dtype=torch.float32) for item in val_data[i:i+batch_size]]).to(device)
output = model(data)
loss = criterion(output, targets)
total_loss += loss.item()
return total_loss / len(val_data)
best_val_loss = float("inf")
best_model = None
for epoch in range(1, epochs + 1):
epoch_start_time = time.time()
train_loss = train(train_data)
val_loss = validate(val_data)
scheduler.step()
if val_loss < best_val_loss:
best_val_loss = val_loss
best_model = model
# Predict and denormalize the data
def predict(model, dataset):
model.eval()
predictions = []
actuals = []
with torch.no_grad():
for i in range(len(dataset)):
data, target = dataset[i]
data = torch.tensor(data, dtype=torch.float32).to(device)
output = model(data.unsqueeze(0))
prediction = output.squeeze().cpu().numpy()
predictions.append(prediction)
actuals.append(target)
return np.array(predictions), np.array(actuals)
predictions, actuals = predict(best_model, val_data)
print("Predictions shape:", predictions.shape)
print("Actuals shape:", actuals.shape)
predictions_denorm = scaler.inverse_transform(predictions)
actuals_denorm = scaler.inverse_transform(actuals.flatten().reshape(-1, 1))
# Plot the results
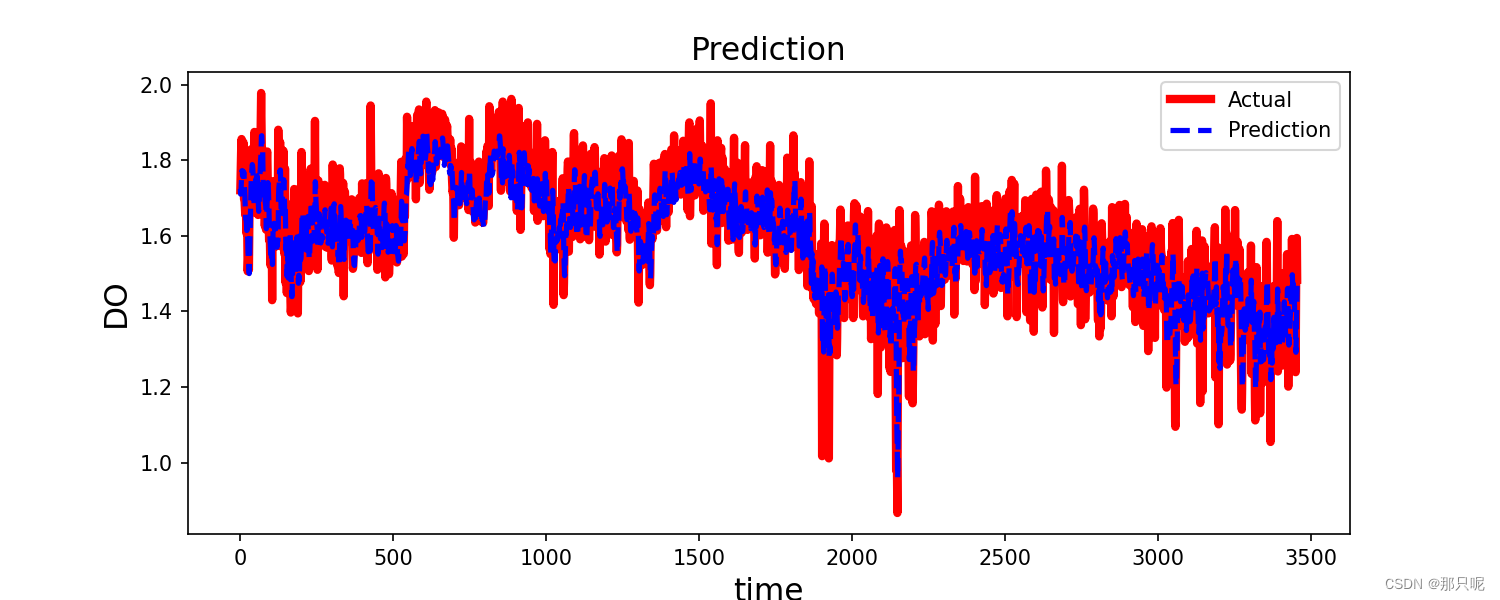
plt.plot(predictions_denorm, label='Predictions')
plt.plot(actuals_denorm, label='Actuals')
plt.legend(['Predictions', 'Actuals'])
plt.xlabel('Timestep')
plt.ylabel('High')
plt.legend()
plt.show()
更多时间序列预测代码:时间序列预测算法全集合--深度学习