概述
Champ是阿里巴巴集团、南京大学和复旦大学的研究团队共同提出了一种创新的人体动画生成技术,Champ能够在仅有一段原始视频和一张静态图片的情况下,激活图片中的人物,使其按照视频中的动作进行动态表现,极大地促进了虚拟主播和其他虚拟角色生成技术的发展。
Champ技术的核心在于其独特的工作流程。首先,该方法利用SMPL(Skinned Multi-Person Linear Model)模型来生成渲染深度图、法线贴图和语义贴图。这些图像为后续的处理步骤提供了详尽的三维形状信息,是构建真实感动画的关键。接着,Champ结合了基于骨架的动作指导,为模型注入精确的动作属性,确保生成的动画既准确又具有丰富的细节。
通过这种方法,Champ能够捕捉并再现人物的细微动作和表情,使得生成的动画既自然又逼真。这不仅为虚拟内容创作者提供了一个强大的工具,也为虚拟现实、游戏开发和电影制作等领域带来了新的可能性。
项目主页:https://fudan-generative-vision.github.io/champ/
论文地址:https://arxiv.org/pdf/2403.14781.pdf
Github地址:https://github.com/fudan-generative-vision/champ
企鹅交流群:787501969
简介
Champ是一种基于SMPL模型的先进技术,旨在精确捕捉视频中人体的几何形状和动作特征。通过统一身体形状和姿势的表示方法,Champ能够从源视频中提取复杂的3D人体信息。
该技术通过整合渲染深度图像、法线图和语义图等多维度数据,这些数据都是从SMPL模型序列中获得的。同时,Champ还利用了基于骨骼结构的运动信息来引导模型,这为潜在扩散模型提供了更为丰富的条件,使得模型能够全面地理解和再现3D形状及详细的姿势属性。
Champ的一个显著特点是其多层运动融合模块,该模块结合了自注意机制,能够在空间域中有效地整合形状和运动的信息。自注意机制使得模型能够自动识别并关注对结果影响最大的特征,从而在处理过程中提高对关键信息的捕捉能力。
此外,Champ通过将3D人体参数模型作为运动引导,实现了在参考图像和源视频运动之间进行精确的参数形状对齐。这一过程允许模型根据参考图像调整人体姿势,同时保持源视频中的运动特征,确保生成的动画既准确又自然。

生成扩散模型的最新进展为图像动画领域带来了显著的推动力,特别是在人类图像动画的生成方面。这一领域主要采用基于生成对抗网络(GAN)和扩散模型的方法。GAN方法通过变形函数对输入的动作进行空间变换,以生成连续的视频帧。但GAN在动作转移方面面临挑战,尤其是在人物身份和场景动态发生较大变化的情况下。
与之相对的扩散模型方法,通过结合参考图像和动态条件直接生成人类动画视频。最新的扩散模型结合了数据驱动策略和CLIP编码的视觉特征,通过时间对齐模块解决了GAN方法中的泛化问题。
本研究进一步优化了形状对齐和姿势引导机制,提出了一种基于SMPL模型的人体图像动画生成方法。SMPL模型作为一种3D参数化人体模型,能够统一表示身体形状和姿势变化,提供丰富的人体几何特征,如表面变形、空间关系和轮廓等。利用SMPL模型的参数化特性,可以建立重建的SMPL与源视频中提取的SMPL运动序列之间的几何对应关系,从而调整参数化SMPL运动序列,优化潜在扩散模型中的运动和几何形状条件。
该方法包含三个关键步骤:
- 将SMPL模型的序列投影到图像空间,生成深度图、法线图和语义图,以捕捉人体的3D信息。
- 引入基于骨架的运动指导,以提高动画生成的精度。
- 通过特征编码和自注意力机制融合深度、法线、语义和骨架图,进一步提升模型的生成能力。
实验结果显示,该方法在TikTok和UBC时尚视频数据集上取得了优异的表现,并在真实场景数据集上展现了强大的泛化能力。这表明,基于SMPL模型的人体图像动画生成方法能够有效地捕捉和再现复杂的人体动作和形状变化,为图像动画领域提供了一种新的解决方案。
算法框架
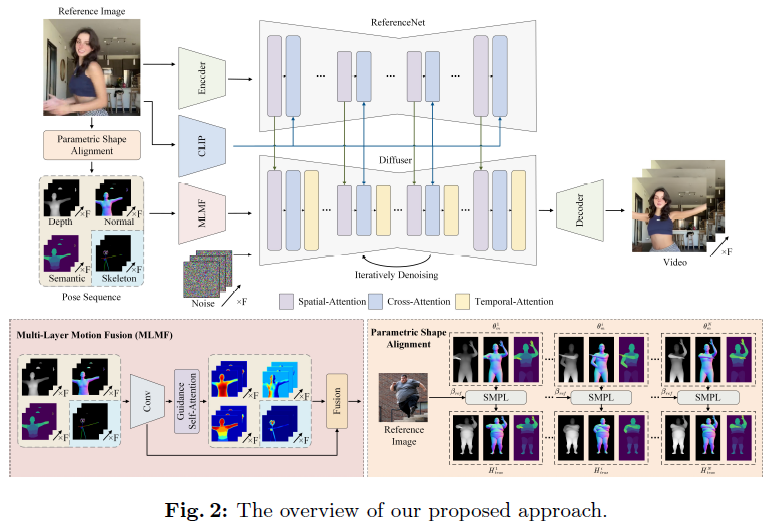
Champ是一种先进的人体图像动画合成技术,它能够根据给定的人物图像和参考视频中的动作序列,生成一个时间连贯且视觉可控的视频。这一过程的核心在于利用SMPL模型来提取和复制人体动作,从而创造出逼真的动画效果。
在实现过程中,Champ首先使用SMPL模型对源视频中的人体姿势和形状进行分析和提取。SMPL模型是一种基于物理的模型,它通过一组参数来描述人体的三维形状和姿势。这种模型能够精确捕捉人体的细节,包括关节的位置、身体的姿态以及肌肉的形态等。
提取出的姿势和形状信息随后被用于生成多个包含姿势和形状细节的输出。这些输出不仅提供了丰富的人体几何信息,而且为后续的动画生成过程提供了基础。接着,Champ在潜在扩散模型框架中利用这些输出为人物图像动画提供多层次的姿势和形状指导。
潜在扩散模型是一种生成模型,它通过模拟数据的扩散过程来生成新的数据样本。在Champ中,这个模型利用从SMPL模型中提取的姿势和形状信息,以及深度、法线和语义地图等辅助信息,来生成与参考视频动作相匹配的动画帧。
潜在扩散模型(LDM)。它将扩散和去噪两个随机过程结合到潜在空间中。首先,使用变分自编码器(VAE)将输入图像编码为低维特征空间。然后,将输入图像转换为潜在表示,应用方差保持马尔可夫过程对其进行扩散,生成多样化的噪声潜在表示。去噪过程涉及从z_t到z_t-1的每个时间步长t的噪声预测。最后,使用冻结的解码器将去噪后的z_0解码回图像空间。
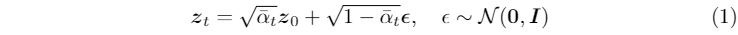
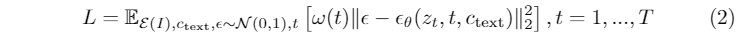
SMPL****模型是计算机图形学和计算机视觉领域中常用的人体建模和动画方法。该模型结合了参数化形状空间和姿势空间,能够生成多样化的人体形状和姿势。模型的参数包括姿势和形状,通过输入这些参数,可以生成一个包含6890个顶点的3D网格表示。模型还可以使用顶点权重来进行人体部位分割。
Multi-Layer运动条件
**SMPL引导条件。**给定一个参考人体图像I ref和一个参考运动视频帧序列I 1:N,利用4D-Humans分别获得3D人体参数化SMPL模型H ref和H m1:N。为了从像素空间中提取全面的视觉信息,渲染SMPL网格以获得二维表示。这包括编码深度图,其中包含从每个像素到相机的距离信息,对重建场景的3D结构至关重要。对法线映射进行编码,描述了图像中每个点的表面方向,可以捕获关于人体表面的详细信息。此外,语义分割图为图像中的每个像素提供了类信息,从而能够准确处理人体不同组件之间的交互。
**参数化形状对齐。**作为人体视频生成的关键,通过驱动运动序列来生成参考人体图像的动画仍然具有挑战性。利用参数化的人体模型,可以很容易地对齐参考人体和运动序列之间的形状和姿态。给定在参考图像I ref上拟合的SMPL模型H ref和来自N帧驱动视频I 1:N的SMPL序列H m1:N,我们的目标是将H ref的形状β ref与H m1:N的姿态序列θ m1:N对齐。对齐后的SMPL模型可表示为:
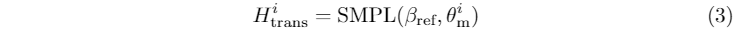
从H trans 1:N中渲染的相应条件来指导图像I ref上的视频生成,产生像素级对齐的人体形状,并增强生成的动画视频中的人体外观映射过程。
Multi-Layer运动引导
通过参数形状对齐,完成了基于参考图像重建的参数化SMPL模型与源视频SMPL模型序列之间的形状级对齐。然后,从对齐的SMPL模型序列中绘制深度图、法线图和语义图。此外,引入骨骼作为辅助输入,以增强复杂动作的表示,如面部表情和手指运动。如图3所示,利用潜在特征嵌入和下面将要介绍的自注意力机制,我们可以对人体形状和姿态的多层嵌入进行空间加权,从而生成多层语义融合作为运动指导。
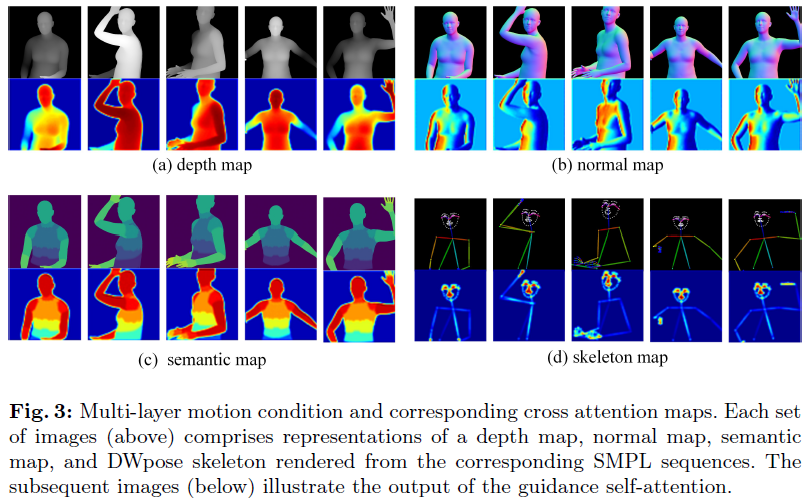
**Self-Attention指导。**本文提出了一种制导编码器,用于编码多级制导。通过这种方法,实现了从引导中提取信息的同时,微调一个预训练的去噪U-Net。编码器由一系列轻量级网络组成。我们为每个指导条件分配一个指导网络F i来编码其特征。对于每个引导网络,首先通过一组卷积层提取引导条件的特征;考虑到存在多级引导条件,涉及人体不同特征,在卷积层之后添加自注意力模块。该模块便于精确捕获每一层引导条件对应的语义信息。特别是,图3说明了训练后深度、正常、语义和骨架特征嵌入的自注意力图。分析结果显示出不同的模式:深度条件主要关注人体的几何轮廓;正常状态强调人体的方向性;语义条件优先考虑身体不同部位的语义信息;骨骼注意力提供了面部和手部的详细约束。
**多层运动融合。**为了保持预训练去噪U-Net模型的完整性,我们选择应用零卷积来提取每个引导条件的特征。引导编码器将所有引导条件中的特征嵌入通过求和进行聚合,从而得到最终的引导特征y。该操作在数学上可以表示为:
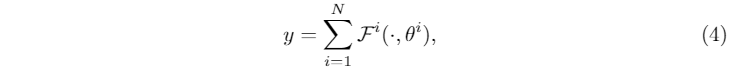
其中N为纳入制导条件的总数。随后,将引导特征与噪声潜表示相结合,然后将其送入去噪融合模块。
神经网络
**网络结构。**提出了一种视频扩散模型,融合了来自3D人体参数模型的运动指导。我们采用SMPL模型从运动数据中提取连续的SMPL姿态序列。本文提出一种运动嵌入模块,将多层引导纳入模型中。运动引导的多个潜在嵌入通过自注意力机制单独细化,然后使用多层运动融合模块将其融合在一起。此外,我们使用一个VAE编码器和一个剪辑图像编码器对参考图像进行编码。为了确保视频的一致性,我们利用了两个关键模块:ReferenceNet和时间对齐模块。VAE嵌入被输入到参考网络中,该网络负责保持生成的视频和参考图像中的字符和背景之间的一致性。采用了一种运动对齐策略,利用一系列运动模块在各帧之间应用时间注意力。该过程旨在减轻参考图像和运动指导之间的任何差异,从而增强生成视频内容的整体连贯性。
**训练。**训练过程包括两个不同的阶段。在初始阶段,仅在图像上进行训练,而不包括模型中的运动模块。将VAE编码器和解码器以及剪辑图像编码器的权重冻结在冻结状态,同时允许指导编码器、去噪U-Net和参考编码器在训练期间进行更新。在初始化阶段,从一段人类视频中随机选择一帧作为参考,并从同一段视频中选择另一幅图像作为目标图像。然后将从目标图像中提取的多层引导输入到引导网络中。该阶段的主要目标是利用特定目标图像的多级引导生成高质量的动画图像。
在第二个训练阶段,加入运动模块以增强模型的时间连贯性和流动性。该模块使用AnimateDiff中预先存在的权重进行初始化。提取包含24帧的视频片段作为输入数据。在运动模块训练过程中,保持初始阶段训练的引导编码器、去噪U-Net和参考编码器不变。
**推理。**在推理过程中,通过对齐从野生视频中提取的运动序列或合成的运动序列,在特定的参考图像上执行动画。通过参数化形状对齐,将运动序列与参考图像重建的SMPL模型进行像素级对齐,为动画生成提供依据。为了适应包含24帧的视频片段的输入,采用时间聚合技术将多个片段连接起来。这种聚合方法旨在产生长时间的视频输出。
实验
实现细节
**数据集。**我们构建了一个数据集,包括来自著名在线库的大约5000个高保真真实的人体视频,共包括100万帧。数据集被分割为:Bilibili(2540个视频),快手(920个视频),Tiktok & Youtube(1438个视频),小红书(430个视频)。这些视频以不同年龄、种族和性别的人为特征,以全身、半身和特写镜头的方式描绘,并以室内和室外的不同背景为背景。
**实现。**使用8个NVIDIA A100 GPU进行训练,分为两个阶段,第一阶段处理单个视频帧,第二阶段处理时间序列,使用学习率为1e-5的训练方法。
结果
**基线。**与MRAA、DisCo、MagicAnimate、Animate Anyone等方法进行了全面比较。在所有定性比较实验中,我们采用了MooreThreads和MagicAnimate的开源实现。
**评价指标。**单帧图像质量评价包括L1误差、结构相似度(SSIM)、学习感知图像块相似度(LPIPS)和峰值信噪比(PSNR)等指标。视频保真度通过Frechet Inception距离与Fr échet视频距离(FIDFVD)和Fr échet视频距离(FVD)来评估。
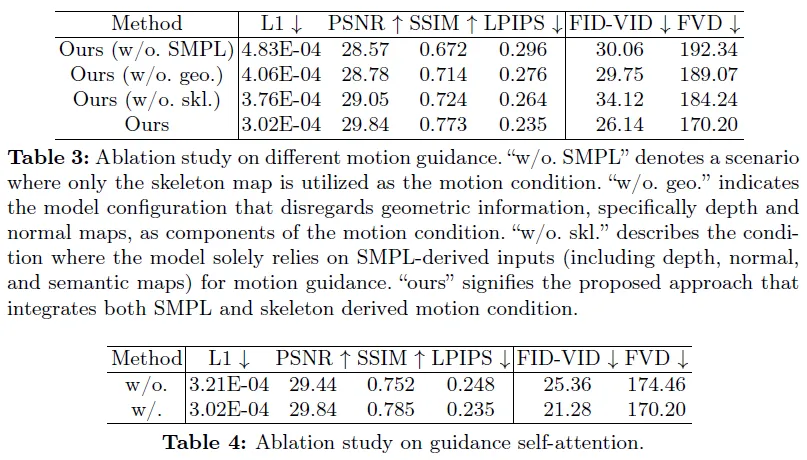
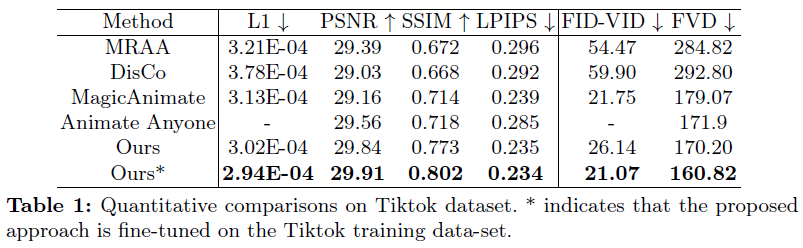
**对TikTok数据集的评估。**Champ无论是原始的还是微调的形式,在大多数指标上都表现出卓越的性能,特别是突出了其在实现较低的L1损失、较高的PSNR和SSIM值,以及减少LPIPS、FID-VID和FVD分数方面的有效性。

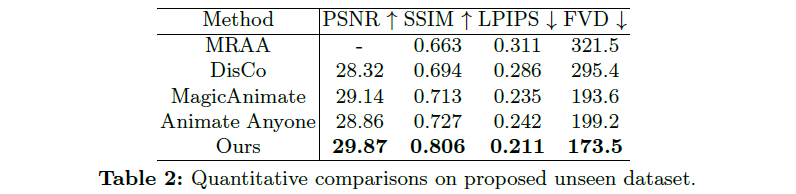
**对未见过数据集的评估。**通过定性评估,以及的统计比较,共同说明了Champ在泛化到未见过的域方面的有效性。

**交叉ID动画。**Champ与最先进的跨实体动画基线方法进行了比较分析,特别是通过来自不同视频的运动序列制作参考图像的任务。

**消融分析
**
实验结果表明,引入SMPL模型和骨架模型可以显著提高图像质量和保持形状对齐和运动引导,引入姿态引导自注意力机制可以提高转移的一致性和真实性。同时,该方法具有高效性,能够在较短的时间内完成转移。