1,原理
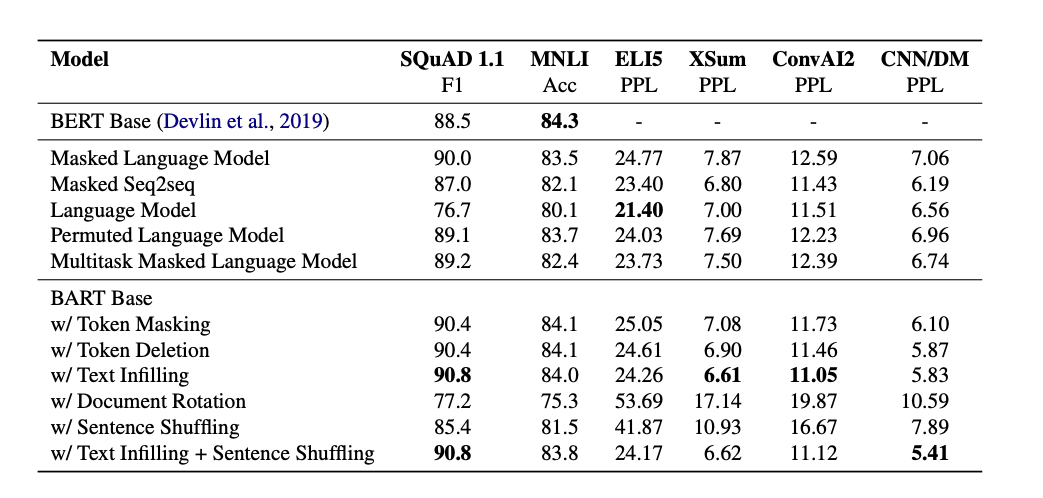
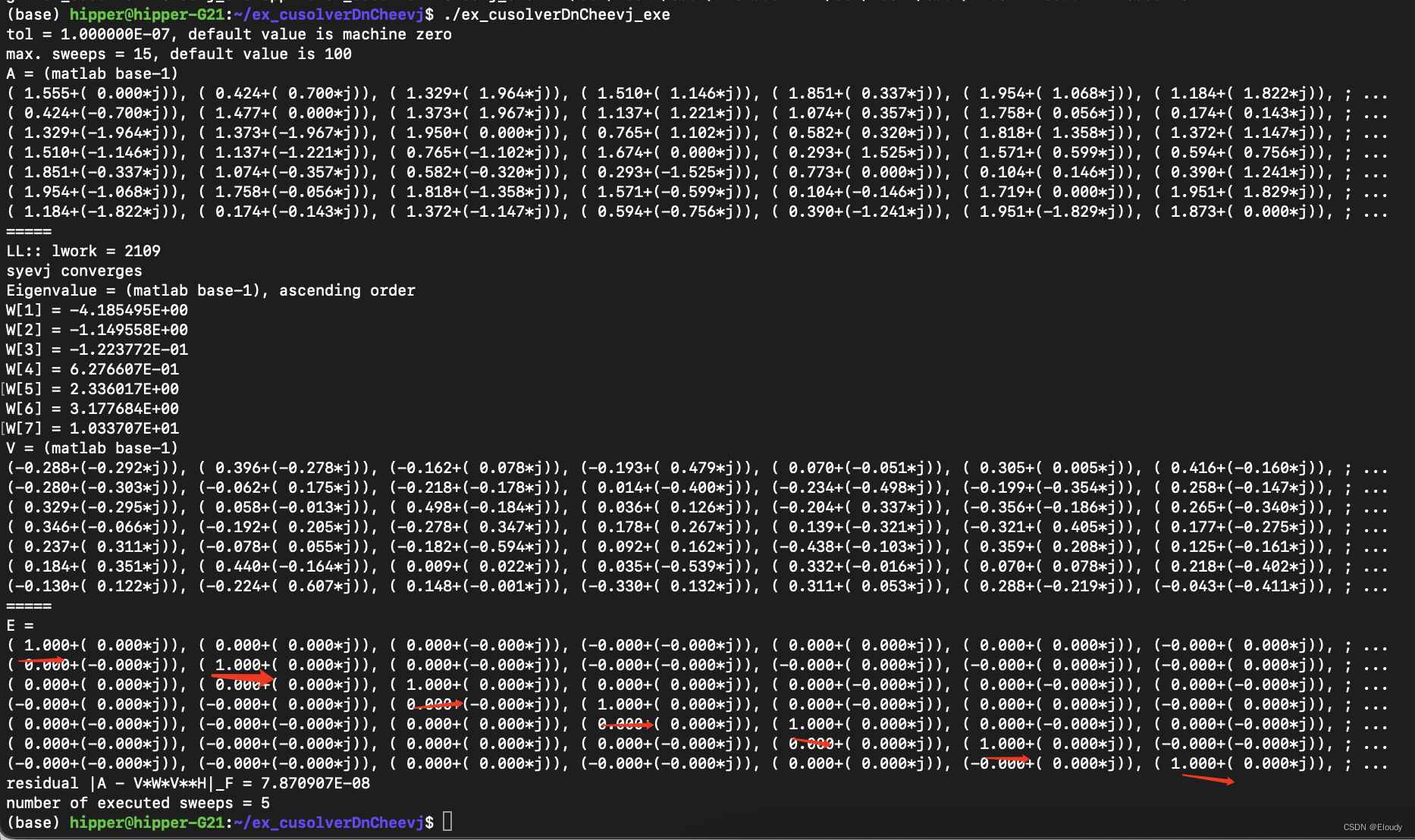
计算Hermitian 矩阵的特征值,使用Jacobi 旋转法,每次调整两个对称元素为0,通过迭代,使得非对角线上的值总体越来越趋近于0.
示例扩展了 nv 的 cusolverDsyevj 的示例
由于特征向量是正交的,故V*V^c = E,以此作为正确性的验证准则
2,源码
ex_cusolverDnCheevj_exe.cpp
#include <cstdio>
#include <cstdlib>
#include <vector>
#include <cuda_runtime.h>
#include <cusolverDn.h>
#include <cuComplex.h>
#include "cusolver_utils.h"
void print_complex_matrix(cuComplex* A, int m, int n, int lda)
{
for(int i=0; i<(m<12? m:12); i++){
for(int j=0; j<(n<12? n:12); j++){
printf("(%6.3f+(", A[i + j*lda].x);
printf("%6.3f*j)), ", A[i + j*lda].y);
}
printf("; ...\n");
}
}
void init_Hermitian_matrix(cuComplex *A, int m, int n ,int lda, int seed)
{
srand(seed);
for(int i=0; i<lda; i++){
for(int j=0; j<m; j++){
if(i<=j){
A[i + j*lda].x = (rand()%2000)/1000.0f;
A[i + j*lda].y = (rand()%2000)/1000.0f;
if(i==j)
A[i + j*lda].y = 0.0f;
}else{
A[i + j*lda].x = A[j + i*lda].x;
A[i + j*lda].y = -A[j + i*lda].y;
}
}
}
}
void complex_gemm_NT(cuComplex *A, int lda, cuComplex *B, int ldb, cuComplex *C, int ldc, int M, int N, int K)
{
cuComplex zero_c;
zero_c.x = 0.0f;
zero_c.y = 0.0f;
for(int i=0; i<M; i++){
for(int j=0; j<N; j++){
cuComplex sigma = zero_c;
for(int k=0; k<K; k++){
sigma = cuCaddf(sigma, cuCmulf(A[i + k*lda], cuConjf(B[j+ k*ldb])));
}
C[i + j*ldc] = sigma;
}
}
}
int main(int argc, char *argv[]) {
cusolverDnHandle_t cusolverH = NULL;
cudaStream_t stream = NULL;
syevjInfo_t syevj_params = NULL;
const int m = 7;
const int lda = m;
cuComplex *A = nullptr;
A = (cuComplex*)malloc(lda*m*sizeof(cuComplex));
cuComplex *V = nullptr;
V = (cuComplex*)malloc(lda*m*sizeof(cuComplex));
float *W = nullptr;
W = (float*)malloc(m*sizeof(float));
init_Hermitian_matrix(A, m, m, lda, 2024);
cuComplex *d_A = nullptr;
float *d_W = nullptr;
int *devInfo = nullptr;
cuComplex *d_work = nullptr;
int lwork = 0;
int info_gpu = 0;
/* configuration of syevj */
const double tol = 1.e-7;
const int max_sweeps = 15;
const cusolverEigMode_t jobz = CUSOLVER_EIG_MODE_VECTOR; // compute eigenvectors.
//const cublasFillMode_t uplo = CUBLAS_FILL_MODE_LOWER;
const cublasFillMode_t uplo = CUBLAS_FILL_MODE_UPPER;
/* numerical results of syevj */
double residual = 0;
int executed_sweeps = 0;
printf("tol = %E, default value is machine zero \n", tol);
printf("max. sweeps = %d, default value is 100\n", max_sweeps);
printf("A = (matlab base-1)\n");
//print_matrix(m, m, A, lda);
print_complex_matrix(A, m, m, lda);
printf("=====\n");
/* step 1: create cusolver handle, bind a stream */
CUSOLVER_CHECK(cusolverDnCreate(&cusolverH));
CUDA_CHECK(cudaStreamCreateWithFlags(&stream, cudaStreamNonBlocking));
CUSOLVER_CHECK(cusolverDnSetStream(cusolverH, stream));
/* step 2: configuration of syevj */
CUSOLVER_CHECK(cusolverDnCreateSyevjInfo(&syevj_params));
/* default value of tolerance is machine zero */
CUSOLVER_CHECK(cusolverDnXsyevjSetTolerance(syevj_params, tol));
/* default value of max. sweeps is 100 */
CUSOLVER_CHECK(cusolverDnXsyevjSetMaxSweeps(syevj_params, max_sweeps));
/* step 3: copy A to device */
CUDA_CHECK(cudaMalloc(reinterpret_cast<void **>(&d_A), sizeof(cuComplex) * lda * m));
CUDA_CHECK(cudaMalloc(reinterpret_cast<void **>(&d_W), sizeof(float) * m));
CUDA_CHECK(cudaMalloc(reinterpret_cast<void **>(&devInfo), sizeof(int)));
CUDA_CHECK(cudaMemcpyAsync(d_A, A, sizeof(cuComplex) * lda * m, cudaMemcpyHostToDevice, stream));
/* step 4: query working space of syevj */
CUSOLVER_CHECK(cusolverDnCheevj_bufferSize(cusolverH, jobz, uplo, m, d_A, lda, d_W, &lwork, syevj_params));
printf("LL:: lwork = %d\n", lwork);
CUDA_CHECK(cudaMalloc(reinterpret_cast<void **>(&d_work), sizeof(cuComplex) * lwork));
/* step 5: compute eigen-pair */
CUSOLVER_CHECK(cusolverDnCheevj(cusolverH, jobz, uplo, m, d_A, lda, d_W, d_work, lwork, devInfo,
syevj_params));
CUDA_CHECK(cudaMemcpyAsync(V, d_A, sizeof(cuComplex) * lda * m, cudaMemcpyDeviceToHost, stream));
CUDA_CHECK(cudaMemcpyAsync(W, d_W, sizeof(float) * m, cudaMemcpyDeviceToHost, stream));
CUDA_CHECK(cudaMemcpyAsync(&info_gpu, devInfo, sizeof(int), cudaMemcpyDeviceToHost, stream));
CUDA_CHECK(cudaStreamSynchronize(stream));
if (0 == info_gpu) {
printf("syevj converges \n");
} else if (0 > info_gpu) {
printf("%d-th parameter is wrong \n", -info_gpu);
exit(1);
} else {
printf("WARNING: info = %d : syevj does not converge \n", info_gpu);
}
printf("Eigenvalue = (matlab base-1), ascending order\n");
for (int i = 0; i < m; i++) {
printf("W[%d] = %E\n", i + 1, W[i]);
}
#if 1
printf("V = (matlab base-1)\n");
print_complex_matrix(V, m, m, lda);
printf("=====\n");
#endif
cuComplex *E = nullptr;
E = (cuComplex*)malloc(m*m*sizeof(cuComplex));
//void complex_gemm_NT(cuComplex *A, int lda, cuComplex *B, int ldb, cuComplex *C, int ldc, int M, int N, int K)
complex_gemm_NT(V, lda, V, lda, E, m, m, m, m);
printf("E =\n");
print_complex_matrix(E, m, m, m);
CUSOLVER_CHECK(cusolverDnXsyevjGetSweeps(cusolverH, syevj_params, &executed_sweeps));
CUSOLVER_CHECK(cusolverDnXsyevjGetResidual(cusolverH, syevj_params, &residual));
printf("residual |A - V*W*V**H|_F = %E \n", residual);
printf("number of executed sweeps = %d \n", executed_sweeps);
/* free resources */
CUDA_CHECK(cudaFree(d_A));
CUDA_CHECK(cudaFree(d_W));
CUDA_CHECK(cudaFree(devInfo));
CUDA_CHECK(cudaFree(d_work));
CUSOLVER_CHECK(cusolverDnDestroySyevjInfo(syevj_params));
CUSOLVER_CHECK(cusolverDnDestroy(cusolverH));
CUDA_CHECK(cudaStreamDestroy(stream));
CUDA_CHECK(cudaDeviceReset());
return EXIT_SUCCESS;
}
cusolver_utils.h :
/*
* Copyright (c) 2019, NVIDIA CORPORATION. All rights reserved.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions
* are met:
* * Redistributions of source code must retain the above copyright
* notice, this list of conditions and the following disclaimer.
* * Redistributions in binary form must reproduce the above copyright
* notice, this list of conditions and the following disclaimer in the
* documentation and/or other materials provided with the distribution.
* * Neither the name of NVIDIA CORPORATION nor the names of its
* contributors may be used to endorse or promote products derived
* from this software without specific prior written permission.
*
* THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS ``AS IS'' AND ANY
* EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
* IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
* PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR
* CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,
* EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
* PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR
* PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY
* OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
* (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
* OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
*/
#pragma once
#include <cmath>
#include <functional>
#include <iostream>
#include <random>
#include <stdexcept>
#include <string>
#include <cuComplex.h>
#include <cuda_runtime_api.h>
#include <cublas_api.h>
#include <cusolverDn.h>
#include <library_types.h>
// CUDA API error checking
#define CUDA_CHECK(err) \
do { \
cudaError_t err_ = (err); \
if (err_ != cudaSuccess) { \
printf("CUDA error %d at %s:%d\n", err_, __FILE__, __LINE__); \
throw std::runtime_error("CUDA error"); \
} \
} while (0)
// cusolver API error checking
#define CUSOLVER_CHECK(err) \
do { \
cusolverStatus_t err_ = (err); \
if (err_ != CUSOLVER_STATUS_SUCCESS) { \
printf("cusolver error %d at %s:%d\n", err_, __FILE__, __LINE__); \
throw std::runtime_error("cusolver error"); \
} \
} while (0)
// cublas API error checking
#define CUBLAS_CHECK(err) \
do { \
cublasStatus_t err_ = (err); \
if (err_ != CUBLAS_STATUS_SUCCESS) { \
printf("cublas error %d at %s:%d\n", err_, __FILE__, __LINE__); \
throw std::runtime_error("cublas error"); \
} \
} while (0)
// cublas API error checking
#define CUSPARSE_CHECK(err) \
do { \
cusparseStatus_t err_ = (err); \
if (err_ != CUSPARSE_STATUS_SUCCESS) { \
printf("cusparse error %d at %s:%d\n", err_, __FILE__, __LINE__); \
throw std::runtime_error("cusparse error"); \
} \
} while (0)
// memory alignment
#define ALIGN_TO(A, B) (((A + B - 1) / B) * B)
// device memory pitch alignment
static const size_t device_alignment = 32;
// type traits
template <typename T> struct traits;
template <> struct traits<float> {
// scalar type
typedef float T;
typedef T S;
static constexpr T zero = 0.f;
static constexpr cudaDataType cuda_data_type = CUDA_R_32F;
#if CUDART_VERSION >= 11000
static constexpr cusolverPrecType_t cusolver_precision_type = CUSOLVER_R_32F;
#endif
inline static S abs(T val) { return fabs(val); }
template <typename RNG> inline static T rand(RNG &gen) { return (S)gen(); }
inline static T add(T a, T b) { return a + b; }
inline static T mul(T v, double f) { return v * f; }
};
template <> struct traits<double> {
// scalar type
typedef double T;
typedef T S;
static constexpr T zero = 0.;
static constexpr cudaDataType cuda_data_type = CUDA_R_64F;
#if CUDART_VERSION >= 11000
static constexpr cusolverPrecType_t cusolver_precision_type = CUSOLVER_R_64F;
#endif
inline static S abs(T val) { return fabs(val); }
template <typename RNG> inline static T rand(RNG &gen) { return (S)gen(); }
inline static T add(T a, T b) { return a + b; }
inline static T mul(T v, double f) { return v * f; }
};
template <> struct traits<cuFloatComplex> {
// scalar type
typedef float S;
typedef cuFloatComplex T;
static constexpr T zero = {0.f, 0.f};
static constexpr cudaDataType cuda_data_type = CUDA_C_32F;
#if CUDART_VERSION >= 11000
static constexpr cusolverPrecType_t cusolver_precision_type = CUSOLVER_C_32F;
#endif
inline static S abs(T val) { return cuCabsf(val); }
template <typename RNG> inline static T rand(RNG &gen) {
return make_cuFloatComplex((S)gen(), (S)gen());
}
inline static T add(T a, T b) { return cuCaddf(a, b); }
inline static T add(T a, S b) { return cuCaddf(a, make_cuFloatComplex(b, 0.f)); }
inline static T mul(T v, double f) { return make_cuFloatComplex(v.x * f, v.y * f); }
};
template <> struct traits<cuDoubleComplex> {
// scalar type
typedef double S;
typedef cuDoubleComplex T;
static constexpr T zero = {0., 0.};
static constexpr cudaDataType cuda_data_type = CUDA_C_64F;
#if CUDART_VERSION >= 11000
static constexpr cusolverPrecType_t cusolver_precision_type = CUSOLVER_C_64F;
#endif
inline static S abs(T val) { return cuCabs(val); }
template <typename RNG> inline static T rand(RNG &gen) {
return make_cuDoubleComplex((S)gen(), (S)gen());
}
inline static T add(T a, T b) { return cuCadd(a, b); }
inline static T add(T a, S b) { return cuCadd(a, make_cuDoubleComplex(b, 0.)); }
inline static T mul(T v, double f) { return make_cuDoubleComplex(v.x * f, v.y * f); }
};
template <typename T> void print_matrix(const int &m, const int &n, const T *A, const int &lda);
template <> void print_matrix(const int &m, const int &n, const float *A, const int &lda) {
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
std::printf("%0.2f ", A[j * lda + i]);
}
std::printf("\n");
}
}
template <> void print_matrix(const int &m, const int &n, const double *A, const int &lda) {
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
std::printf("%0.2f ", A[j * lda + i]);
}
std::printf("\n");
}
}
template <> void print_matrix(const int &m, const int &n, const cuComplex *A, const int &lda) {
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
std::printf("%0.2f + %0.2fj ", A[j * lda + i].x, A[j * lda + i].y);
}
std::printf("\n");
}
}
template <>
void print_matrix(const int &m, const int &n, const cuDoubleComplex *A, const int &lda) {
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
std::printf("%0.2f + %0.2fj ", A[j * lda + i].x, A[j * lda + i].y);
}
std::printf("\n");
}
}
template <typename T>
void generate_random_matrix(cusolver_int_t m, cusolver_int_t n, T **A, int *lda) {
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_real_distribution<typename traits<T>::S> dis(-1.0, 1.0);
auto rand_gen = std::bind(dis, gen);
*lda = n;
size_t matrix_mem_size = static_cast<size_t>(*lda * m * sizeof(T));
// suppress gcc 7 size warning
if (matrix_mem_size <= PTRDIFF_MAX)
*A = (T *)malloc(matrix_mem_size);
else
throw std::runtime_error("Memory allocation size is too large");
if (*A == NULL)
throw std::runtime_error("Unable to allocate host matrix");
// random matrix and accumulate row sums
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
T *A_row = (*A) + *lda * i;
A_row[j] = traits<T>::rand(rand_gen);
}
}
}
// Makes matrix A of size mxn and leading dimension lda diagonal dominant
template <typename T>
void make_diag_dominant_matrix(cusolver_int_t m, cusolver_int_t n, T *A, int lda) {
for (int i = 0; i < std::min(m, n); ++i) {
T *A_row = A + lda * i;
auto row_sum = traits<typename traits<T>::S>::zero;
for (int j = 0; j < n; ++j) {
row_sum += traits<T>::abs(A_row[j]);
}
A_row[i] = traits<T>::add(A_row[i], row_sum);
}
}
// Returns cudaDataType value as defined in library_types.h for the string containing type name
cudaDataType get_cuda_library_type(std::string type_string) {
if (type_string.compare("CUDA_R_16F") == 0)
return CUDA_R_16F;
else if (type_string.compare("CUDA_C_16F") == 0)
return CUDA_C_16F;
else if (type_string.compare("CUDA_R_32F") == 0)
return CUDA_R_32F;
else if (type_string.compare("CUDA_C_32F") == 0)
return CUDA_C_32F;
else if (type_string.compare("CUDA_R_64F") == 0)
return CUDA_R_64F;
else if (type_string.compare("CUDA_C_64F") == 0)
return CUDA_C_64F;
else if (type_string.compare("CUDA_R_8I") == 0)
return CUDA_R_8I;
else if (type_string.compare("CUDA_C_8I") == 0)
return CUDA_C_8I;
else if (type_string.compare("CUDA_R_8U") == 0)
return CUDA_R_8U;
else if (type_string.compare("CUDA_C_8U") == 0)
return CUDA_C_8U;
else if (type_string.compare("CUDA_R_32I") == 0)
return CUDA_R_32I;
else if (type_string.compare("CUDA_C_32I") == 0)
return CUDA_C_32I;
else if (type_string.compare("CUDA_R_32U") == 0)
return CUDA_R_32U;
else if (type_string.compare("CUDA_C_32U") == 0)
return CUDA_C_32U;
else
throw std::runtime_error("Unknown CUDA datatype");
}
// Returns cusolverIRSRefinement_t value as defined in cusolver_common.h for the string containing
// solver name
cusolverIRSRefinement_t get_cusolver_refinement_solver(std::string solver_string) {
if (solver_string.compare("CUSOLVER_IRS_REFINE_NONE") == 0)
return CUSOLVER_IRS_REFINE_NONE;
else if (solver_string.compare("CUSOLVER_IRS_REFINE_CLASSICAL") == 0)
return CUSOLVER_IRS_REFINE_CLASSICAL;
else if (solver_string.compare("CUSOLVER_IRS_REFINE_GMRES") == 0)
return CUSOLVER_IRS_REFINE_GMRES;
else if (solver_string.compare("CUSOLVER_IRS_REFINE_CLASSICAL_GMRES") == 0)
return CUSOLVER_IRS_REFINE_CLASSICAL_GMRES;
else if (solver_string.compare("CUSOLVER_IRS_REFINE_GMRES_GMRES") == 0)
return CUSOLVER_IRS_REFINE_GMRES_GMRES;
else
printf("Unknown solver parameter: \"%s\"\n", solver_string.c_str());
return CUSOLVER_IRS_REFINE_NOT_SET;
}
Makefile:
EXE = hello_DnDsyevj ex_cusolverDnCheevj_exe
all: $(EXE)
INC :=-I /usr/local/cuda/include
LD_FLAGS := -L /usr/local/cuda/lib64 -lcudart -lcusolver
%: %.cpp
g++ $< -o $@ $(INC) $(LD_FLAGS)
.PHONY: clean
clean:
rm -rf $(EXE)
3,运行
make
4,参考
CUDALibrarySamples/cuSOLVER/syevj/cusolver_syevj_example.cu at master · NVIDIA/CUDALibrarySamples · GitHub