目录
Set(集合)
集合内置方法完整列表
根据字符串的表达式计算结果
编辑
条件控制:
if – elif – else
match...case
循环语句:
while循环
for循环
在同一行中有多个赋值操作(先计算,再赋值):
end 关键字
Python 推导式
列表推导式:
元组推导式(生成器表达式)
字典推导式
集合推导式:
函数
参数
匿名函数,lambda表达式
字典:
字典的创建:
遍历:
输出
format后跟着格式标识符可以更好的格式化:
try-finally 语句
类
super()函数
类属性与方法
类的私有属性
类的私有方法
类的专有方法:
global 和 nonlocal关键字
本篇博客所有内容均来自于:
Python3 教程 | 菜鸟教程
Set(集合)
Python 中的集合(Set)是一种无序、可变的数据类型,用于存储唯一的元素。集合中的元素不会重复,并且可以进行交集、并集、差集等常见的集合操作。
在 Python 中,集合使用大括号 {} 表示,元素之间用逗号 , 分隔。另外,也可以使用 set() 函数创建集合。
注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
集合内置方法完整列表
| 方法 | 描述 |
|---|---|
| add() | 为集合添加元素 |
| clear() | 移除集合中的所有元素 |
| copy() | 拷贝一个集合 |
| difference() | 返回多个集合的差集 |
| difference_update() | 移除集合中的元素,该元素在指定的集合也存在。 |
| discard() | 删除集合中指定的元素 |
| intersection() | 返回集合的交集 |
| intersection_update() | 返回集合的交集。 |
| isdisjoint() | 判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。 |
| issubset() | 判断指定集合是否为该方法参数集合的子集。 |
| issuperset() | 判断该方法的参数集合是否为指定集合的子集 |
| pop() | 随机移除元素 |
| remove() | 移除指定元素 |
| symmetric_difference() | 返回两个集合中不重复的元素集合。 |
| symmetric_difference_update() | 移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。 |
| union() | 返回两个集合的并集 |
| update() | 给集合添加元素 |
| len() | 计算集合元素个数 |
根据字符串的表达式计算结果
eval(str): 用来计算在字符串中的有效Python表达式,并返回一个对象。

条件控制:
if – elif – else
1、Python 中用 elif 代替了 else if,所以if语句的关键字为:if – elif – else。
match...case
2、在 Python 中没有 switch...case 语句,但在 Python3.10 版本添加了 match...case,功能也类似。
match...case 语法结构
match expression:
case pattern1:
# 处理pattern1的逻辑
case pattern2 if condition:
# 处理pattern2并且满足condition的逻辑
case _:
# 处理其他情况的逻辑
case _: 类似于 C 和 Java 中的 default:,当其他 case 都无法匹配时,匹配这条,保证永远会匹配成功。
参数说明:
match语句后跟一个表达式,然后使用case语句来定义不同的模式。case后跟一个模式,可以是具体值、变量、通配符等。- 可以使用
if关键字在case中添加条件。 _通常用作通配符,匹配任何值。
循环语句:
while循环
while 循环使用 else 语句,如果 while 后面的条件语句为 false 时,则执行 else 的语句块。
语法格式如下:
while <expr>:
<statement(s)>
else:
<additional_statement(s)>for循环
for循环的一般格式如下:
for <variable> in <sequence>:
<statements>
else:
<statements>当循环执行完毕(即遍历完 iterable 中的所有元素)后,会执行 else 子句中的代码,如果在循环过程中遇到了 break 语句,则会中断循环,此时不会执行 else 子句。
在同一行中有多个赋值操作(先计算,再赋值):
例如:
a, b = 0, 1
a, b = b, a+b其中代码 a, b = b, a+b 的计算方式为先计算右边表达式,然后同时赋值给左边,等价于:
n=b
m=a+b
a=n
b=mend 关键字
关键字end可以用于将结果输出到同一行,或者在输出的末尾添加不同的字符:
print(b, end=',')Python 推导式
Python 支持各种数据结构的推导式:
- 列表(list)推导式
- 元组(tuple)推导式
- 字典(dict)推导式
- 集合(set)推导式
列表推导式:
[表达式 for 变量 in 列表]
[out_exp_res for out_exp in input_list]
或者
[表达式 for 变量 in 列表 if 条件]
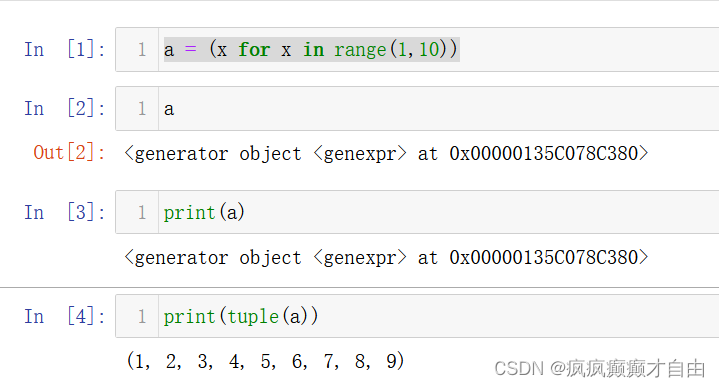
[out_exp_res for out_exp in input_list if condition]元组推导式(生成器表达式)
(expression for item in Sequence )
或
(expression for item in Sequence if conditional )元组推导式和列表推导式的用法也完全相同,只是元组推导式是用 () 圆括号将各部分括起来,而列表推导式用的是中括号 [],另外元组推导式返回的结果是一个生成器对象。
字典推导式
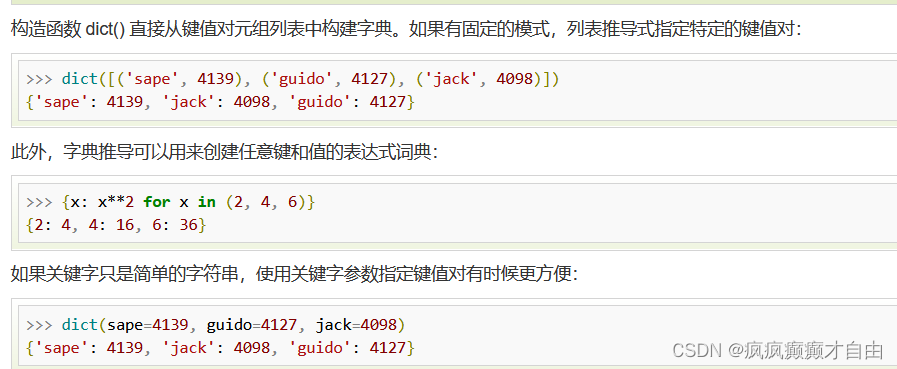
{ key_expr: value_expr for value in collection }
或
{ key_expr: value_expr for value in collection if condition }集合推导式:
{ expression for item in Sequence }
或
{ expression for item in Sequence if conditional }函数的参数传递:
在 python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象。
python 函数的参数传递:
-
不可变类型:类似 C++ 的值传递,如整数、字符串、元组。如 fun(a),传递的只是 a 的值,没有影响 a 对象本身。如果在 fun(a) 内部修改 a 的值,则是新生成一个 a 的对象。
-
可变类型:类似 C++ 的引用传递,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后 fun 外部的 la 也会受影响。
python 中一切都是对象,严格意义我们不能说值传递还是引用传递,我们应该说传不可变对象和传可变对象。
函数
参数
以下是调用函数时可使用的正式参数类型:
- 必需参数
- 关键字参数
- 默认参数
- 不定长参数
不定长参数
你可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数。
- 加了星号 * 的参数会以元组(tuple)的形式导入,存放所有未命名的变量参数。如果在函数调用时没有指定参数,它就是一个空元组。我们也可以不向函数传递未命名的变量。
- 加了两个星号 ** 的参数会以字典的形式导入。
- 如果单独出现星号 *,则星号 * 后的参数必须用关键字传入
匿名函数,lambda表达式
Python 使用 lambda 来创建匿名函数。
所谓匿名,意即不再使用 def 语句这样标准的形式定义一个函数。
- lambda 只是一个表达式,函数体比 def 简单很多。
- lambda 的主体是一个表达式,而不是一个代码块。仅仅能在 lambda 表达式中封装有限的逻辑进去。
- lambda 函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数。
- 虽然 lambda 函数看起来只能写一行,却不等同于 C 或 C++ 的内联函数,内联函数的目的是调用小函数时不占用栈内存从而减少函数调用的开销,提高代码的执行速度。
语法
lambda 函数的语法只包含一个语句,如下:
lambda [arg1 [,arg2,.....argn]]:expression例如:
#!/usr/bin/python3
# 可写函数说明
sum = lambda arg1, arg2: arg1 + arg2
# 调用sum函数
print ("相加后的值为 : ", sum( 10, 20 ))
print ("相加后的值为 : ", sum( 20, 20 ))lambda 函数通常与内置函数如 map()、filter() 和 reduce() 一起使用,以便在集合上执行操作。
numbers = [1, 2, 3, 4, 5]
squared = list(map(lambda x: x**2, numbers))
print(squared) # 输出: [1, 4, 9, 16, 25]原文链接:Python3 函数 | 菜鸟教程
字典:
字典的创建:
一对大括号创建一个空的字典:{}。
遍历:
在字典中遍历时,关键字和对应的值可以使用 items() 方法同时解读出来:
knights = {'gallahad': 'the pure', 'robin': 'the brave'}
for k, v in knights.items():
print(k, v)同时遍历两个或更多的序列,可以使用 zip() 组合:
遍历两个序列:
questions = ['name', 'quest', 'favorite color']
answers = ['lancelot', 'the holy grail', 'blue']
for q, a in zip(questions, answers):
print('What is your {0}? It is {1}.'.format(q, a))遍历三个序列:
questions = ['name', 'quest', 'favorite color']
answers = ['lancelot', 'the holy grail', 'blue']
add = [1, 2 , 3]
for q, a, t in zip(questions, answers, add):
print('What is your {0}? It is {1}. {2}'.format(q, a, t))输出
- str(): 函数返回一个用户易读的表达形式。
- repr(): 产生一个解释器易读的表达形式。
-
字符串对象的 rjust() 方法, 它可以将字符串靠右, 并在左边填充空格。还有类似的方法, 如 ljust() 和 center()。 这些方法并不会写任何东西, 它们仅仅返回新的字符串。另一个方法 zfill(), 它会在数字的左边填充 0,
-
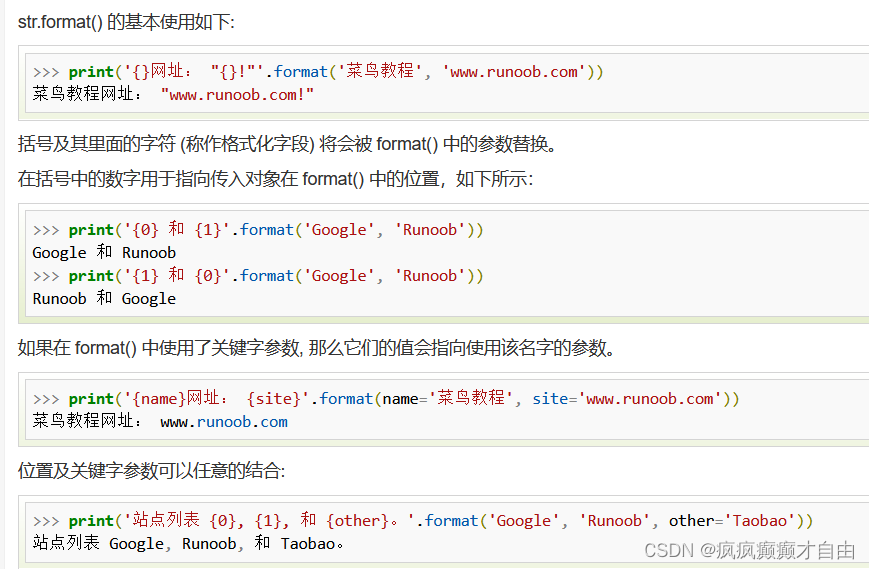
str.format() 的基本使用如下:
1. 括号及其里面的字符 (称作格式化字段) 将会被 format() 中的参数替换。
2. 在括号中的数字用于指向传入对象在 format() 中的位置;3. 如果在 format() 中使用了关键字参数, 那么它们的值会指向使用该名字的参数。
4. 位置及关键字参数可以任意的结合。
format后跟着格式标识符可以更好的格式化:
1)可选项 : 和格式标识符可以跟着字段名。 这就允许对值进行更好的格式化。
import math
print('常量 PI 的值近似为 {0:.3f}。'.format(math.pi))或者:
import math
print('常量 PI 的值近似为 {:.3f}。'.format(math.pi))2)在 : 后传入一个整数, 可以保证该域至少有这么多的宽度。 用于美化表格时很有用。

try-finally 语句

类
super()函数
super() 函数是用于调用父类(超类)的一个方法。
以下是 super() 方法的语法:
super(type[, object-or-type])参数
- type -- 类。
- object-or-type -- 类,一般是 self
Python3.x 和 Python2.x 的一个区别是: Python 3 可以使用直接使用 super().xxx 代替 super(Class, self).xxx :
实例:
FooChild 是子类,FooParent是基类(父类)
super(FooChild,self) 首先找到 FooChild 的父类(就是类 FooParent),然后把类 FooChild 的对象转换为类 FooParent 的对象;
#!/usr/bin/python
# -*- coding: UTF-8 -*-
class FooParent(object):
def __init__(self):
self.parent = 'I\'m the parent.'
print ('Parent')
def bar(self,message):
print ("%s from Parent" % message)
class FooChild(FooParent):
def __init__(self):
# super(FooChild,self) 首先找到 FooChild 的父类(就是类 FooParent),然后把类 FooChild 的对象转换为类 FooParent 的对象
super(FooChild,self).__init__()
print ('Child')
def bar(self,message):
super(FooChild, self).bar(message)
print ('Child bar fuction')
print (self.parent)
if __name__ == '__main__':
fooChild = FooChild()
fooChild.bar('HelloWorld')执行结果:
Parent Child HelloWorld from Parent Child bar fuction I'm the parent.
类属性与方法
类的私有属性
__private_attrs:两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs。
类的私有方法
__private_method:两个下划线开头,声明该方法为私有方法,只能在类的内部调用 ,不能在类的外部调用。self.__private_methods。
类的专有方法:
- __init__ : 构造函数,在生成对象时调用
- __del__ : 析构函数,释放对象时使用
- __repr__ : 打印,转换
- __setitem__ : 按照索引赋值
- __getitem__: 按照索引获取值
- __len__: 获得长度
- __cmp__: 比较运算
- __call__: 函数调用
- __add__: 加运算
- __sub__: 减运算
- __mul__: 乘运算
- __truediv__: 除运算
- __mod__: 求余运算
- __pow__: 乘方
global 和 nonlocal关键字
global修改全局变量
#!/usr/bin/python3
num = 1
def fun1():
global num # 需要使用 global 关键字声明
print(num)
num = 123
print(num)
fun1()
print(num)如果要修改嵌套作用域(enclosing 作用域,外层非全局作用域)中的变量则需要 nonlocal 关键字了。
#!/usr/bin/python3
def outer():
num = 10
def inner():
nonlocal num # nonlocal关键字声明
num = 100
print(num)
inner()
print(num)
outer()map() 函数
map() 函数的基本语法:
map(function, iterable)参数解释如下:
function:一个函数或方法
iterable:一个或多个序列(可迭代对象)
map() 函数的作用是:对序列 iterable 中每一个元素调用 function 函数,返回一个map对象实例。这个map对象本质上来讲是一个迭代器。
面向对象:
1.自定义类的比较:
- 默认情况下,一个自定义类的__eq__方法,功能是判断两个对象的id是否相同。
- 默认情况下,一个自定义类的两个对象a和b,a == b 和ais b 的含义一样,都是“a和b是否指向相同的地方”。同理,a != b 和 not a is b 含义相同。
- 默认情况下,自定义类的对象不能比较大小,因其__lt__、__gt__、__le__、__ge__方法都被设置成了None。
2.静态属性和静态方法:


3. 可哈希:
- 自定义类的对象,默认情况下哈希值是根据对象id进行计算。所以两个对象,只要a is b不成立,a和b的哈希值就不同,就可以同时存在于一个集合内,或作为同一字典的不同元素的键。
- 可以重写自定义类的__hash__()方法,使得对象的哈希值和对象的值相关,而不是id相关,这样值相同的对象,就不能处于同一个集合中,也不能作为同一字典不同元素的键。
- a==b等价于a.__eq__(b)。自定义类的默认__eq__函数是判断两个对象的id是否相同。自定义类的默认__hash__函数是根据对象id算哈希值的。
- 如果为自定义的类重写了__eq__(self,other)成员函数,则其__hash__成员函数会被自动设置为None。这种情况下,该类就变成不可哈希的。
- 一个自定义类,只有在重写了__eq__方法却没有重写__hash__方法的情况下,才是不可哈希的。