深度Q网络
- 1、引言
- 2、深度Q网络
- 2.1 定义
- 2.2 原理
- 2.3 实现方式
- 2.4 算法公式
- 2.5 代码示例
- 3、总结
1、引言
小屌丝:鱼哥, 马上清明小长假了, 你这准备去哪里玩啊?
小鱼:哪也不去,在家待着
小屌丝:在家? 待着? 干啥啊?
小鱼:啥也不干,床上躺着
小屌丝:床上… 躺着… 做啥啊?
小鱼:啥也不做,睡觉
小屌丝:睡觉?? 这大白天的,确定睡觉?
小鱼:我擦… 你这wc~
小屌丝:我很正经的好不好。
小鱼:… 我有点事,待会说
小屌丝: 待会,没时间了哦
小鱼:那就在多几个待会的
小屌丝:这火急火燎的, 肯定"有事"。

2、深度Q网络
2.1 定义
深度Q网络(DQN)是一种结合了深度学习和Q-learning的强化学习算法。它通过深度神经网络逼近值函数,并利用经验回放和目标网络等技术,使得Q-learning能够在高维连续状态空间中稳定学习。
2.2 原理
DQN的核心原理是利用深度神经网络来估计Q值函数。
在每个时刻,DQN根据当前状态s和所有可能的动作a计算出一组Q值,然后选择Q值最大的动作执行。
执行动作后,环境会给出新的状态s’和奖励r,DQN将这些信息存储到经验回放缓存中。
在训练过程中,DQN从经验回放缓存中随机采样一批历史数据,利用这些数据进行梯度下降更新神经网络参数。
此外,DQN还引入了目标网络来稳定学习过程,即每隔一定步数将当前网络参数复制给目标网络,用于计算目标Q值。
2.3 实现方式
实现DQN主要包括以下步骤:
- 初始化深度神经网络(Q网络)和目标网络(目标Q网络)。
- 初始化经验回放缓存。
- 对于每个训练回合:
- 初始化状态s。
- 对于每个时间步t:
- 使用ε-贪婪策略选择动作a。
- 执行动作a,观察奖励r和新状态s’。
- 将经验(s, a, r, s’)存储到经验回放缓存中。
- 从经验回放缓存中采样一批数据,计算损失函数并更新Q网络参数。
- 每隔一定步数更新目标网络参数。
- 重复上述步骤直至满足终止条件。
2.4 算法公式
DQN的损失函数通常采用均方误差(MSE)形式,即:
L ( θ ) = 1 / N ∗ Σ [ ( r + γ ∗ m a x a ′ Q ( s ′ , a ′ ; θ − ) − Q ( s , a ; θ ) ) 2 ] L(θ) = 1/N * Σ[(r + γ * max_a' Q(s', a'; θ⁻) - Q(s, a; θ))^2] L(θ)=1/N∗Σ[(r+γ∗maxa′Q(s′,a′;θ−)−Q(s,a;θ))2]
其中,
- θ θ θ是 Q Q Q网络参数,
- θ − θ⁻ θ−是目标网络参数,
- N N N是采样数据批量大小,
- γ γ γ是折扣因子,
- r r r是奖励,
- s s s和 a a a分别是当前状态和动作,
- s ′ s' s′是下一状态,
- a ′ a' a′是下一状态的所有可能动作。
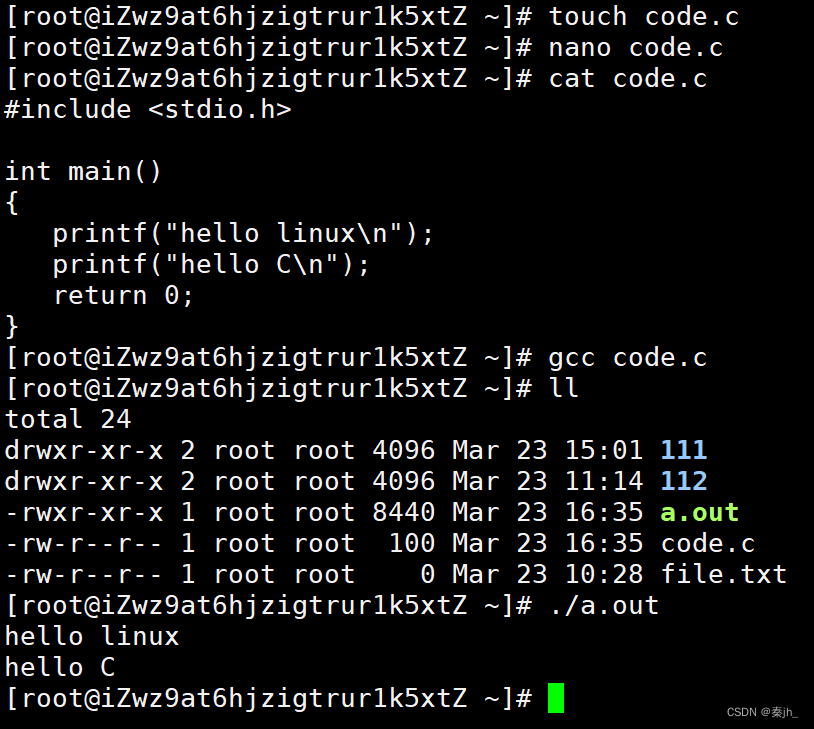
2.5 代码示例
# -*- coding:utf-8 -*-
# @Time : 2024-04-01
# @Author : Carl_DJ
'''
实现功能:
使用PyTorch框架的简单DQN(Deep Q-Network)实现示例
'''
import gym
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import random
from collections import deque
# 创建一个简单的神经网络,作为Q网络
class DQN(nn.Module):
def __init__(self, input_dim, output_dim):
super(DQN, self).__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, 128),
nn.ReLU(),
nn.Linear(128, output_dim)
)
def forward(self, x):
return self.net(x)
# 经验回放
class ReplayBuffer:
def __init__(self, capacity):
self.buffer = deque(maxlen=capacity)
def push(self, state, action, reward, next_state, done):
self.buffer.append((state, action, reward, next_state, done))
def sample(self, batch_size):
state, action, reward, next_state, done = zip(*random.sample(self.buffer, batch_size))
return np.array(state), action, reward, np.array(next_state), done
def __len__(self):
return len(self.buffer)
# DQN算法实现
class DQNAgent:
def __init__(self, input_dim, output_dim):
self.model = DQN(input_dim, output_dim)
self.target_model = DQN(input_dim, output_dim)
self.target_model.load_state_dict(self.model.state_dict())
self.optimizer = optim.Adam(self.model.parameters())
self.buffer = ReplayBuffer(10000)
self.steps_done = 0
self.epsilon_start = 1.0
self.epsilon_final = 0.01
self.epsilon_decay = 500
self.batch_size = 32
def act(self, state):
epsilon = self.epsilon_final + (self.epsilon_start - self.epsilon_final) * \
np.exp(-1. * self.steps_done / self.epsilon_decay)
self.steps_done += 1
if random.random() > epsilon:
state = torch.FloatTensor(state).unsqueeze(0)
q_value = self.model(state)
action = q_value.max(1)[1].item()
else:
action = random.randrange(2)
return action
def update(self):
if len(self.buffer) < self.batch_size:
return
state, action, reward, next_state, done = self.buffer.sample(self.batch_size)
state = torch.FloatTensor(state)
next_state = torch.FloatTensor(next_state)
action = torch.LongTensor(action)
reward = torch.FloatTensor(reward)
done = torch.FloatTensor(done)
q_values = self.model(state)
next_q_values = self.target_model(next_state)
q_value = q_values.gather(1, action.unsqueeze(1)).squeeze(1)
next_q_value = next_q_values.max(1)[0]
expected_q_value = reward + 0.99 * next_q_value * (1 - done)
loss = (q_value - expected_q_value.data).pow(2).mean()
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
def update_target(self):
self.target_model.load_state_dict(self.model.state_dict())
# 训练环境设置
env = gym.make('CartPole-v1')
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
agent = DQNAgent(state_dim, action_dim)
# 训练循环
episodes = 100
for episode in range(episodes):
state = env.reset()
total_reward = 0
done = False
while not done:
action = agent.act(state)
next_state, reward, done, _ = env.step(action)
agent.buffer.push(state, action, reward, next_state, done)
state = next_state
total_reward += reward
agent.update()
agent.update_target()
print('Episode: {}, Total reward: {}'.format(episode, total_reward))
解析:
- 首先定义了一个简单的神经网络DQN,
- 然后定义了ReplayBuffer用于经验回放,
- 接着定义了DQNAgent类封装了DQN的决策、学习和目标网络更新逻辑。
- 最后,通过创建一个gym环境(这里使用的是CartPole-v1)并在该环境中运行DQNAgent来进行训练。

3、总结
深度Q网络(DQN)通过将深度学习与强化学习相结合,解决了传统Q-learning在高维连续状态空间中的维度灾难问题。
DQN利用深度神经网络的强大表征能力来估计Q值函数,并通过经验回放和目标网络等技术来稳定学习过程。
我是小鱼:
- CSDN 博客专家;
- 阿里云 专家博主;
- 51CTO博客专家;
- 企业认证金牌面试官;
- 多个名企认证&特邀讲师等;
- 名企签约职场面试培训、职场规划师;
- 多个国内主流技术社区的认证专家博主;
- 多款主流产品(阿里云等)测评一、二等奖获得者;
关注小鱼,学习【机器学习】&【深度学习】领域的知识。