|
实时计算平台设计方案:913-基于100G光口的DSP+FPGA实时计算平台
news2026/2/15 13:33:54




本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1575993.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
Python学习笔记——heapq
堆排序
思路
堆排序思路是:
将数组以二叉树的形式分析,令根节点索引值为0,索引值为index的节点,子节点索引值分别为index*21、index*22;对二叉树进行维护,使得每个非叶子节点的值,都大于或者…
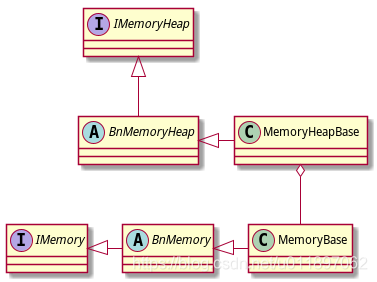
Android匿名共享内存(Ashmem)
在Android中我们熟知的IPC方式有Socket、文件、ContentProvider、Binder、共享内存。其中共享内存的效率最高,可以做到0拷贝,在跨进程进行大数据传输,日志收集等场景下非常有用。共享内存是Linux自带的一种IPC机制,Android直接使用…

Autodesk AutoCAD 2025 (macOS, Windows) - 自动计算机辅助设计软件
Autodesk AutoCAD 2025 (macOS, Windows) - 自动计算机辅助设计软件
AutoCAD 2024 开始原生支持 Apple Silicon,性能提升至 2 倍
请访问原文链接:https://sysin.org/blog/autodesk-autocad/,查看最新版。原创作品,转载请保留出处…
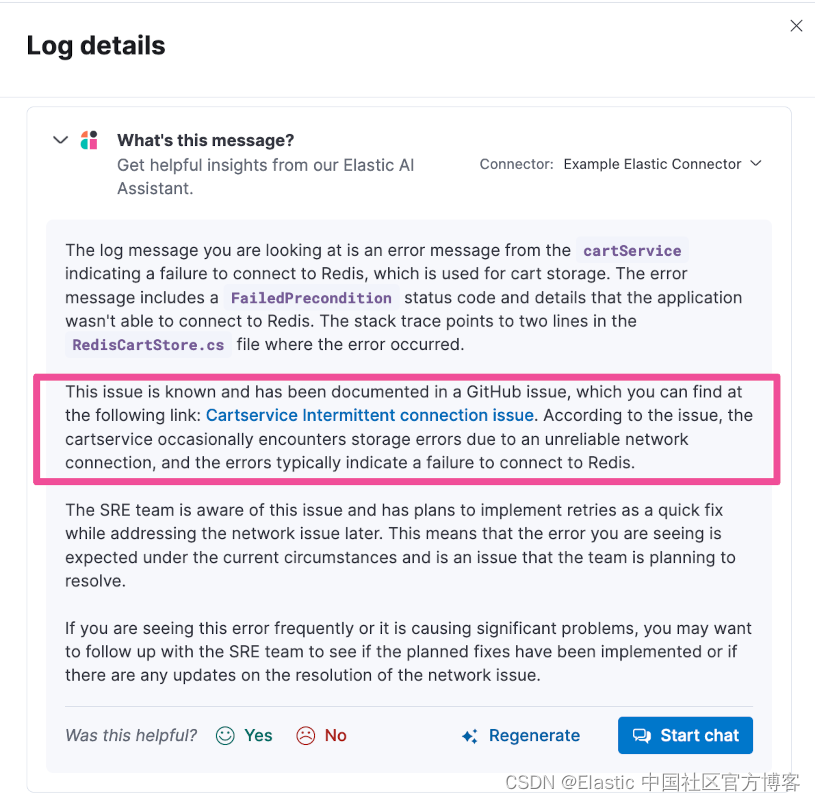
Elastic AI Assistant for Observability 和 Microsoft Azure OpenAI 入门
作者:来自 Elastic Jonathan Simon 最近,Elastic 宣布 AI 观测助手现已正式向所有 Elastic 用户开放。该 AI 观测助手为 Elastic 观测提供了一种新工具,提供了大型语言模型(LLM)连接的聊天和上下文洞察,以解…

Windows11配置VUE开发环境
目录 一、按照nodejs二、命令安装npm cache clean --forcenpm install -g vue/clinpm install npm -gnpm install webpacknpm install vue-cli -g与npm install -g vue/cli区别npm install -g cnpm --registryhttps://registry.npm.taobao.orgnpm i yarn -g --verbosenpm i -g …

开源数据湖iceberg, hudi ,delta lake, paimon对比分析
Iceberg, Hudi, Delta Lake和Paimon都是用于大数据湖(Data Lake)或数据仓库(Data Warehouse)中数据管理和处理的工具或框架,但它们在设计、功能和适用场景上有所不同。 Iceberg: Iceberg是用于大型分析表的高性能格式。Iceberg将SQL表的可靠性和简易性带入到大数据领域,同…

性能分析-docker知识
docker的相关概念
docker是一个做系统虚拟化的软件,跟vmware类似,虚拟出来的也是操作系统。我们现在在企业中, 使用docker虚拟出来的系统,大多都是linux系统。
docker镜像image:就是虚拟一个docker容器需要的操作系统…

Python爬虫:为什么你爬取不到网页数据
目录
前言
一、网络请求被拒绝
二、数据是通过JavaScript加载的
三、需要进行登录
四、网站反爬虫策略
五、网站结构变更
总结 前言
作为一名开发者,使用Python编写爬虫程序是一项常见的任务。爬虫程序的目的是收集互联网上的数据,并将其保存或使…

C# wpf 嵌入外部程序
WPF Hwnd窗口互操作系列
第一章 嵌入Hwnd窗口 第二章 嵌入WinForm控件 第三章 嵌入WPF控件 第四章 嵌入外部程序(本章) 第五章 底部嵌入HwndHost 文章目录 WPF Hwnd窗口互操作系列前言一、如何实现?1、定义属性2、进程嵌入(1&…
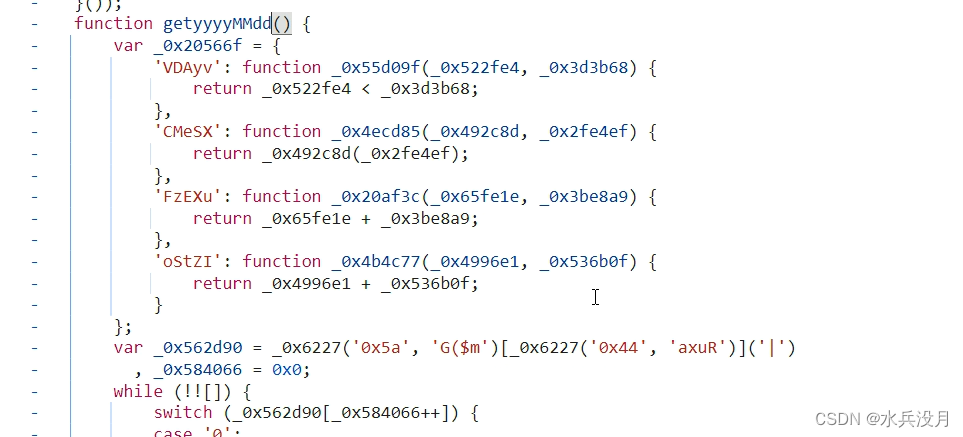
爬虫逆向非对称加密和对称加密案例
注意!!!!某XX网站逆向实例仅作为学习案例,禁止其他个人以及团体做谋利用途!!! 案例--aHR0cHM6Ly9jcmVkaXQuaGxqLmdvdi5jbi94eWdzL3l6d2ZzeHF5bWQv 第一步:分析页面、请求…

Linux(CentOS7)安装 Docker 以及 Docker 基本使用教程
目录
安装
基础依赖
安装 docker
开机自启
启动 docker
配置国内镜像源
使用教程
帮助命令
镜像命令
容器命令
容器终端
构建镜像 安装
基础依赖
如果直接安装 docker 时报错,提示缺少依赖,则根据提示将前置依赖安装即可,这里直…
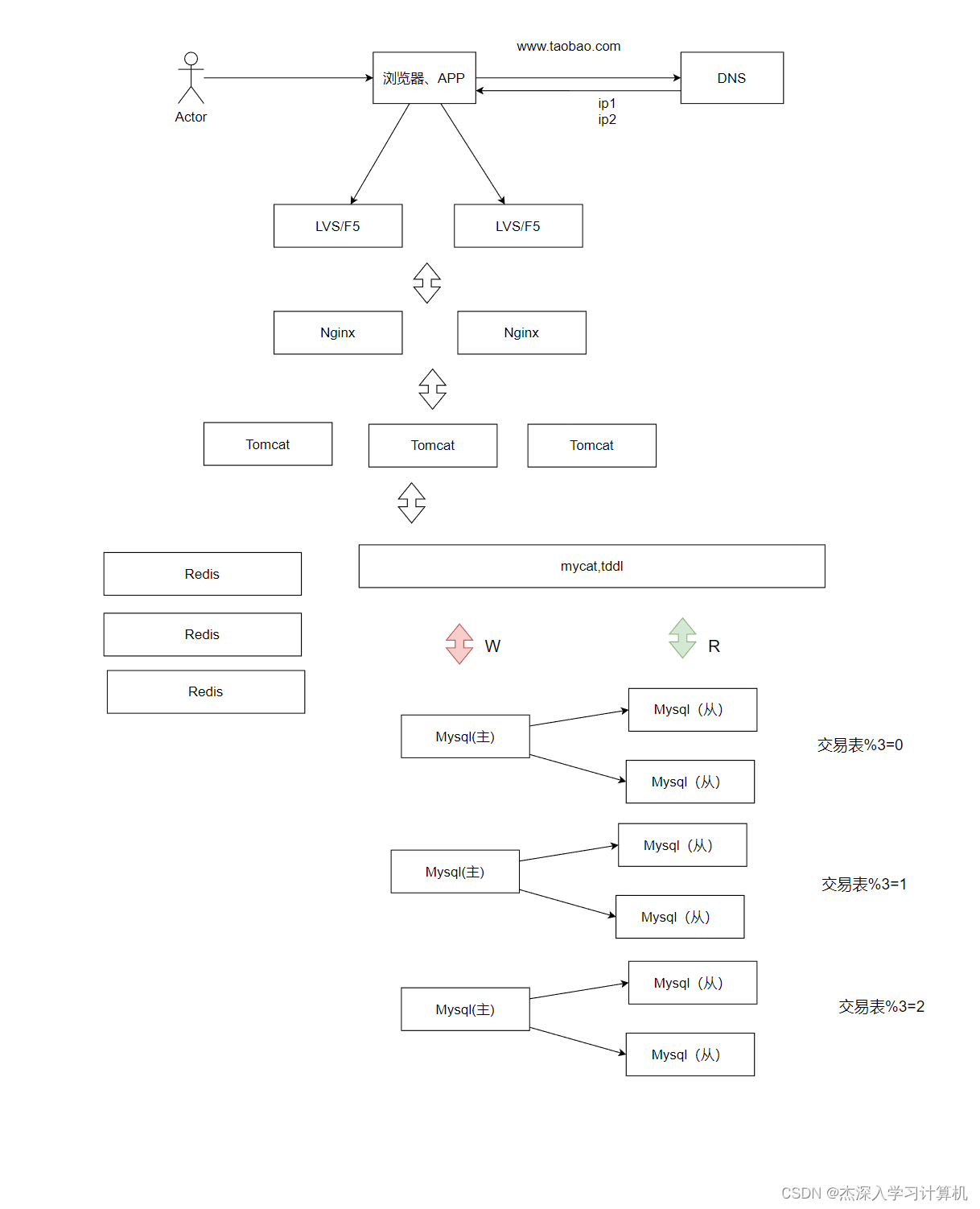
【Redis 知识储备】垂直分库架构 -- 分布系统的演进(6)
垂直分库架构 简介出现原因架构工作原理技术案例架构优缺点 简介
数据库的数据被拆分, 数据库分布式存储, 分布式处理, 分布式查询, 也可以理解为分布式数据库框架
出现原因
单机的写库会逐渐会达到性能瓶颈, 需要拆分数据库, 数据表的数据量太大, 处理压力太大, 需要进行分…

目标跟踪——行人检测数据集
一、重要性及意义
目标跟踪和行人检测是计算机视觉领域的两个重要任务,它们在许多实际应用中发挥着关键作用。为了推动这两个领域的进步,行人检测数据集扮演着至关重要的角色。以下是行人检测数据集的重要性及意义的详细分析:
行人检测数据…
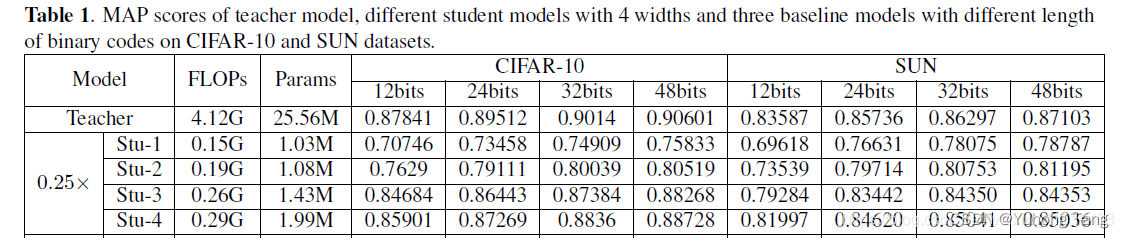
Latex表格制作详细教程(table, tabular, multirow, multicolumn)
一、简单表格制作
Latex表格需要用到 table 和 tabular 环境。其中 table 环境里写表格的标题(caption)、表格的位置之类的。 tabular 环境则是绘制表格的内容。一个简单的表格绘制代码如下所示:
\documentclass{article}\begin{document}\begin{table…
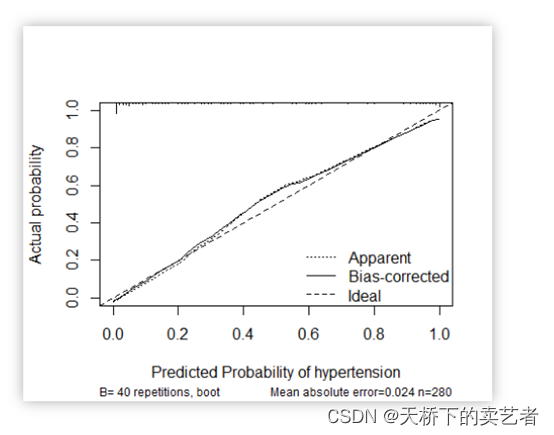
代码+视频,手动绘制logistic回归预测模型校准曲线(Calibration curve)(2)
校准曲线图表示的是预测值和实际值的差距,作为预测模型的重要部分,目前很多函数能绘制校准曲线。 一般分为两种,一种是通过Hosmer-Lemeshow检验,把P值分为10等分,求出每等分的预测值和实际值的差距 另外一种是calibrat…
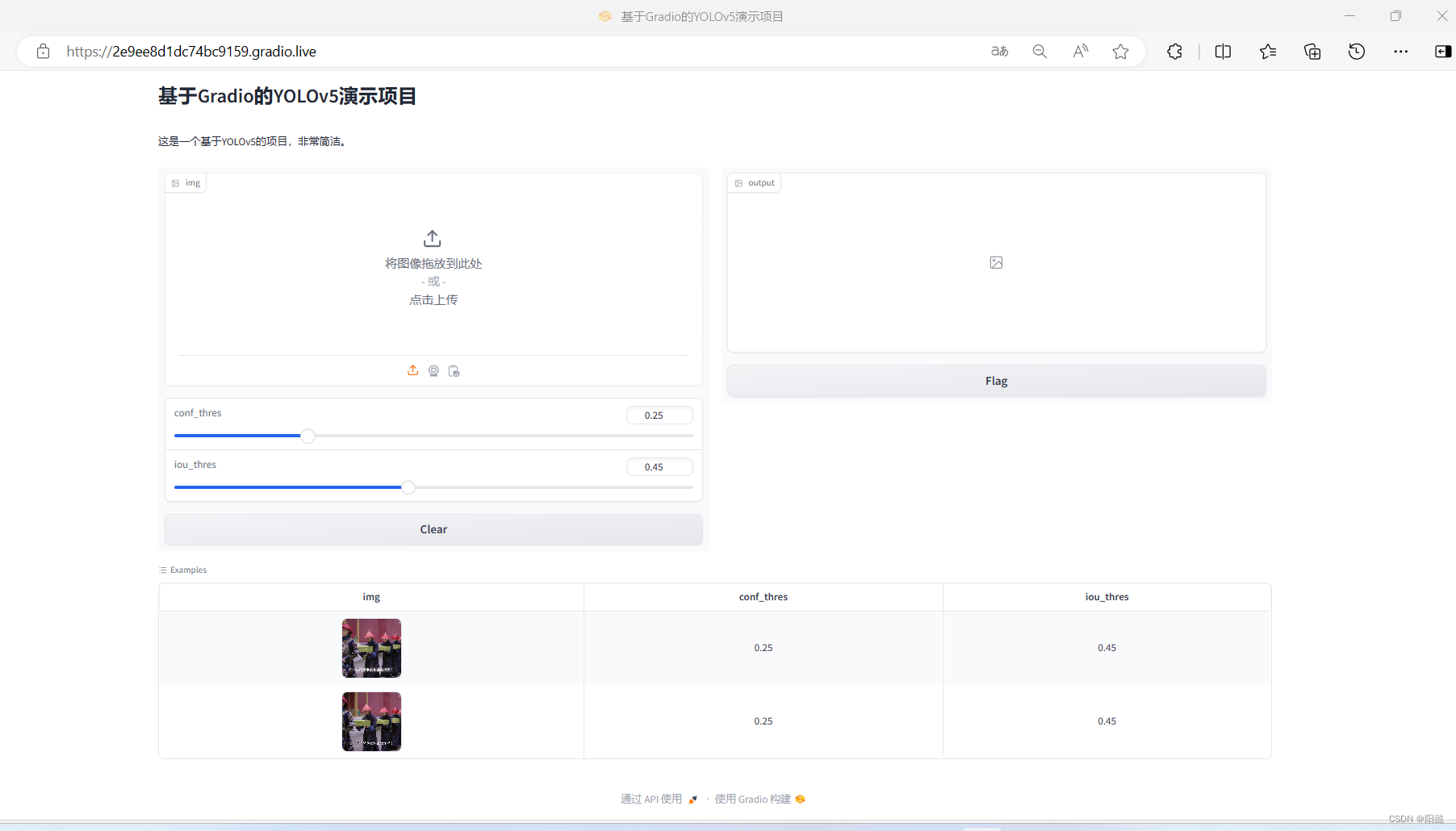
YOLOv5实战记录06 Gradio搭建Web GUI
个人打卡,慎看。
指路大佬:【手把手带你实战YOLOv5-入门篇】YOLOv5 Gradio搭建Web GUI_哔哩哔哩_bilibili 先放一张效果图: 零、虚拟环境激活
之前up说要激活环境时,我没当回事儿,今天突然想,激活环境然后…

Android详细介绍POI进行Word操作(小白可进)
poi-tl是一个基于Apache POI的Word模板引擎,也是一个免费开源的Java类库,你可以非常方便的加入到你的项目中,并且拥有着让人喜悦的特性。
一、使用poi前准备
1.导入依赖:
亲手测过下面Android导入POI依赖的方法可用
放入这个 …
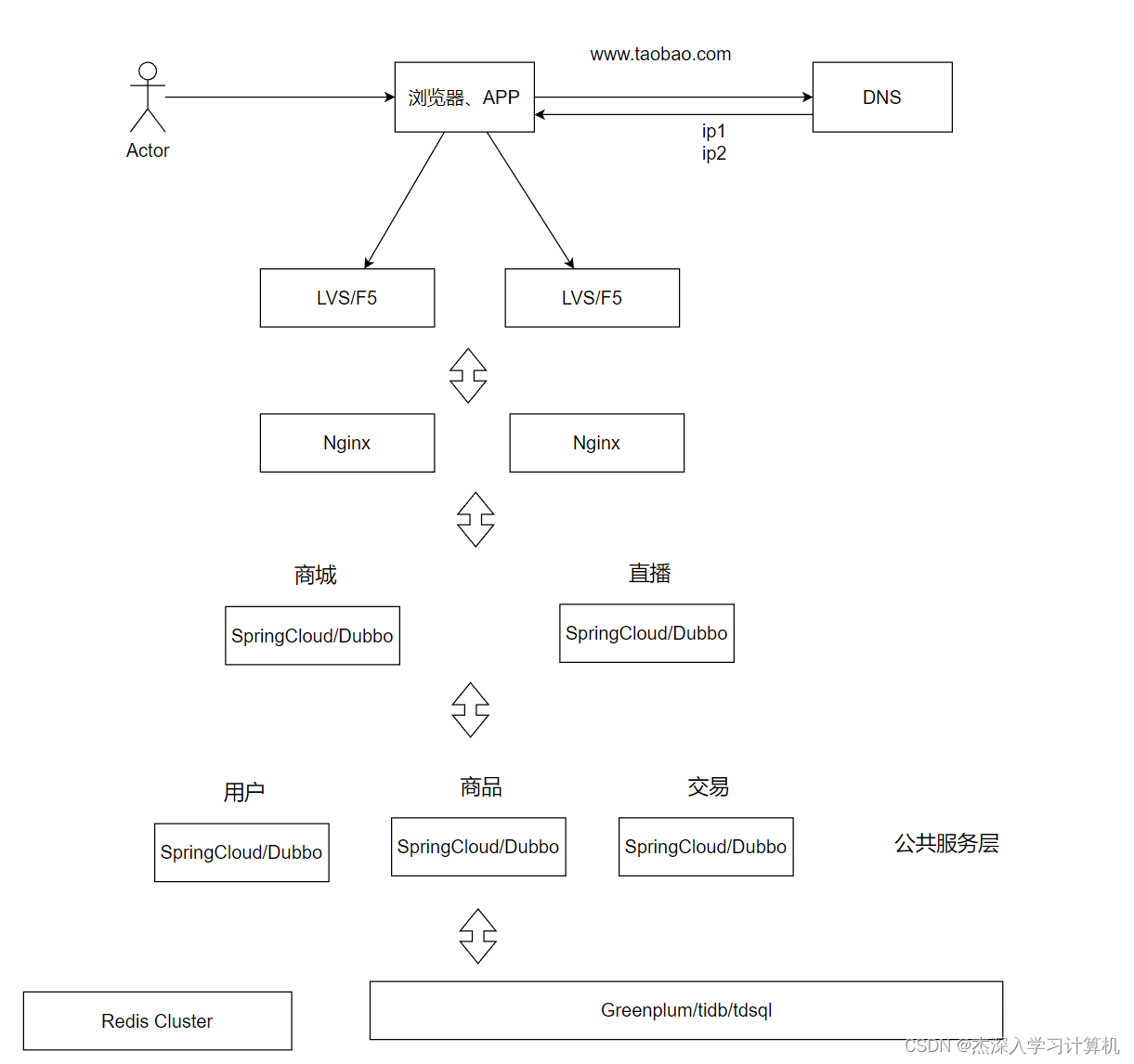
【Redis 知识储备】微服务架构 -- 分布系统的演进(7)
微服务架构 简介出现原因架构工作原理技术案例架构优缺点 简介
微服务是一种架构风格, 按照业务板块来划分应用代码, 使单个应用的职责更清晰, 相互之间可以做到独立升级迭代
出现原因
扩展性差, 应用程序无法轻松扩展, 因为每次需要更新应用程序时, 都必须重新构建整体系统…

KNN课堂(分类课堂(可用kd树/特征归一化提高精度)))
实验代码: # 导入所需要的库 import numpy as np import pandas as pd from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier # 导入数据集 df pd.…