1. 简介
由于 AI 神经网络涉及多种参数,需要频繁修改各种超参数,比如:learning rate,batchsize,filter numbers,alpha 等等,每个参数都有可能影响到模型最终的准确率,所以比较这些参数之间的差异,并且进行记录和保存,是 AI 算法优化必需的流程。
本文将介绍 python 的一个库:mlflow,可以使 AI 实验的效率更高,提供一种更方便的比较方法。
2. mlflow
mlflow 作为机器学习生命周期的管理包,提供了完整的 AI 开发部署工作流程以及可视化管理:
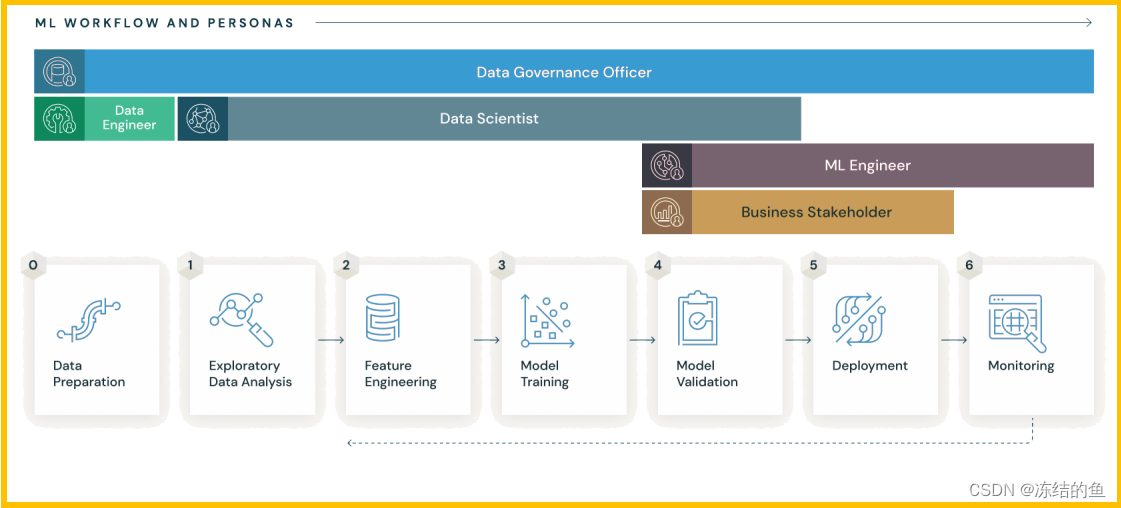
mlflow 模块一共包含 5 个基本组件:
- MLflow Tracking:用于记录机器学习所使用的参数,软件版本,模型测试环境等。
- MLflow Models:一种模型格式,可以方便部署在各个平台上,并且计算其推理时间。比如:Docker,Apache Spark, Databricks, Azure ML 和 AWS SageMaker。
- MLflow Model Registry:中心化的模型商店,包含一系列 API 和 UI。
- MLflow Projects:标准化的格式,用于打包可重用的代码,可以运行在不同参数下。
- MLflow Recipes:开发高质量模型的预定义模板,包括分类和回归。
2.1. 代码集成
Mlflow 提供了两种方法集成,一种是直接调用 mlflow.autolog(),它支持非常多的主流机器学习框架,比如 scikit-learn, Keras, Pytorch。
如果 autolog 不支持,则可以使用下表中方法,手动进行记录:
| 名称 | 目的 | 函数调用 |
|---|---|---|
| Parameters | 常量(比如, 配置参数) | mlflow.log_param,mlflow.log_params |
| Metrics | 运行中更新的值(比如,精度) | mlflow.log_metric |
| Artifacts | 运行中产生的文件(比如,模型权重) | mlflow.log_artifacts,mlflow.log_image,mlflow.log_text |
2.2. Autolog 和结果展示
Autolog 方法比较简单,以 keras 为例,只需要在训练脚本最前面调用以下代码即可 :
import mlflow
mlflow.tensorflow.autolog()
在本次实验中,我运行了两次 train.py, 然后将 batch size 从 256 修改为 128 再次运行了一次 train.py。
运行完成后,mlflow 会自动生成 mlruns 文件夹,并保存每次的训练参数和结果,默认情况下,保存的模型是最后一次迭代的模型。
图2. Mlflow 自动生成的文件夹和文件
然后,在 python 执行终端中,进入包含有 mlruns 的目录中,输入 mlflow ui,即可通过本地浏览器打开 web 界面(默认 http://127.0.0.1:5000):
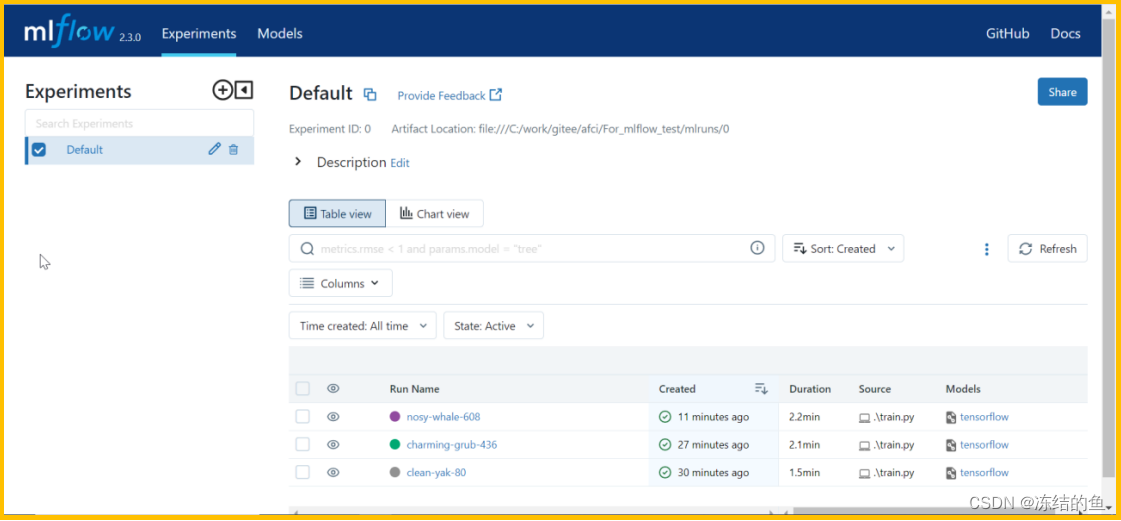
上图 3,记录了三次实验,创建时间,持续时间,并且可以添加其他的实验参数或指标,并支持排序,比如 batch size, epoch, acc, loss 等。
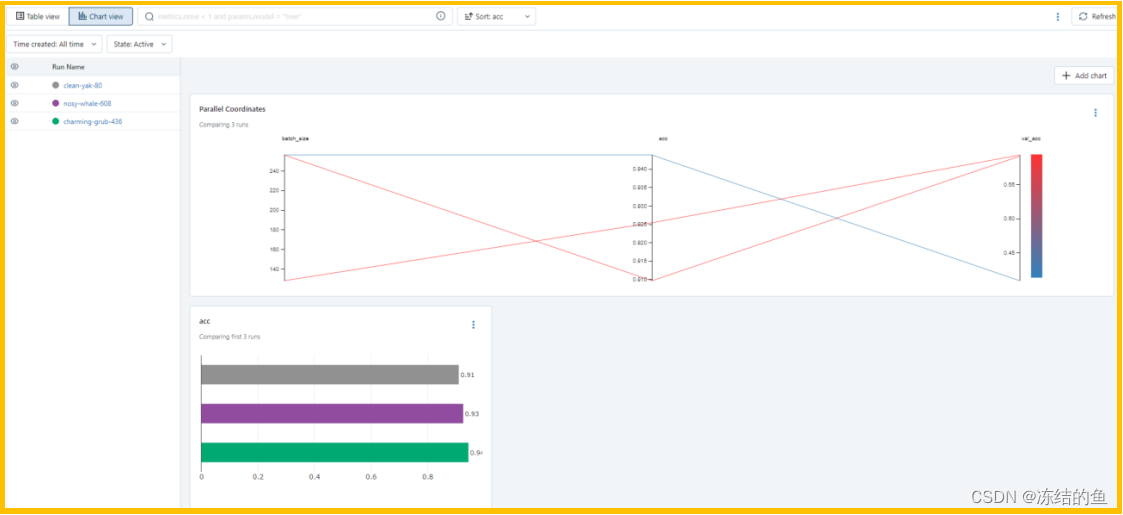
图4. Mlflow chart view 主界面
上图 4,记录了三次实验的图形比较结果,比如修改了 batch size 后准确率变化了多少,验证集准确率变化了多少等,这些交叉对比参数可以手动修改。
自动记录的参数包括以下 24 个:
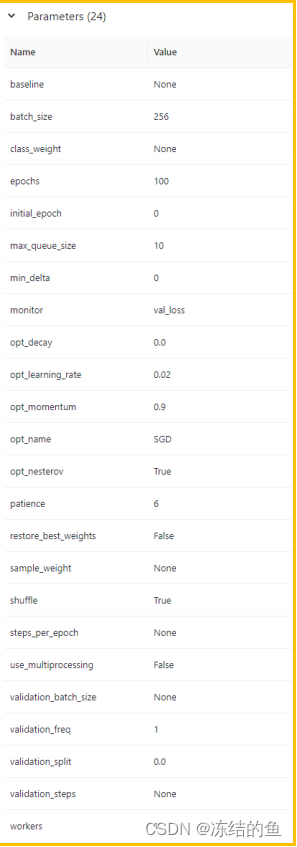
图5. 自动记录的参数
自动记录的指标包括以下 6 个:
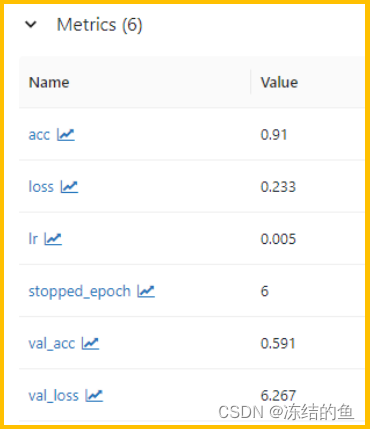
图6. 自动记录的指标
2.3. 选择性记录
Autolog 非常方便,但是有一个问题,自动记录的模型和指标是最后一次迭代的模型,在某些训练脚本中,可能需要保存验证结果最好的一个模型,如果需要达到这个目的,那么需要使用 2.1 中的方法进行记录。

图7. 记录参数
比如,图 7 中,尝试记录一些参数,也可以记录一些超参数,作为模型选择的对比。
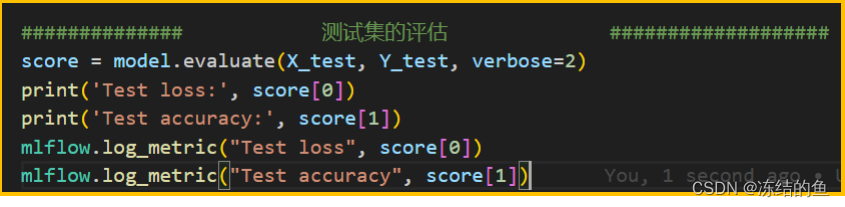
图8. 记录指标
或者,如图 8 中,可以记录测试集的结果,作为新的评估指标。
3. 测试结果
以 AFCI 为例,实践中可能会遇到这样的问题:电流数据的采样率如何设置,分帧长度如何设置,是否需要使用 FFT 等。
这些超参数的设置都很难解释,他严重依赖于具体的数据,实践中可以以测试结果为准。
下面将介绍使用采集到的原始数据进行测试,原始 ADC 采集数据使用了 400KHz 采样率,那么通过降采样很容易得到 200KHz 采样率的数据。同时将分别测试 FFT 和不使用 FFT,帧长设置分别为 512,1024,2048,4096。
同时,记录以下信息:
#记录数据类型,采样率,帧长等信息
mlflow.log_params({"data_type":data_type, \
"sample_rate":sample_rate, "points":points, \
"feature_path":str(feature_path), "data_list":DATA_LIST})
#评估模型的 Precision, Recall, F1-score
Y_pred = model.predict(X_test)
Y_pred = np.argmax(Y_pred, axis=1)
Y_test = np.argmax(Y_test, axis=1)
print(classification_report(Y_test, Y_pred))
#记录精准率,召回率,F1 分数
mlflow.log_metric("Recall", recall_score(Y_test, Y_pred))
mlflow.log_metric("Precision", precision_score(Y_test, Y_pred))
mlflow.log_metric("f1_score", f1_score(Y_test, Y_pred))
#使用 mlflow 记录模型
mlflow.log_artifact(output_path/(model.name +'.h5'))
3.1. FFT 预处理对结果的影响
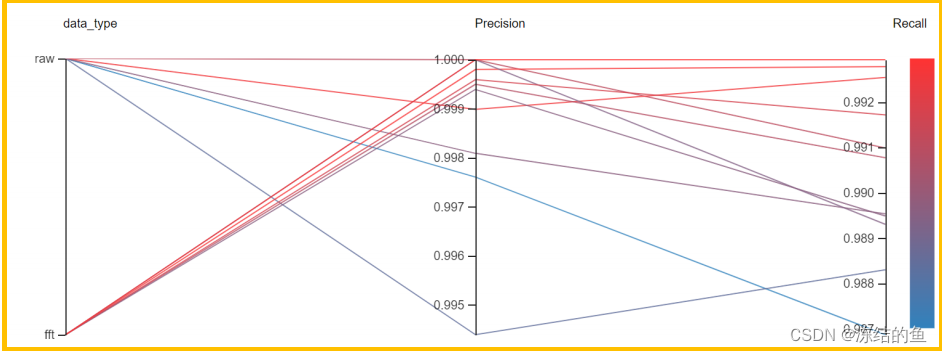
图9. 数据类型和指标的关系
从上图可以看到,使用 FFT 预处理后的结果,相对原始数据要更稳定,更好一点。使用ADC 原始数据也可以达到很好的效果,但参数的选择方面需要更加小心。
3.2. 帧长对结果的影响
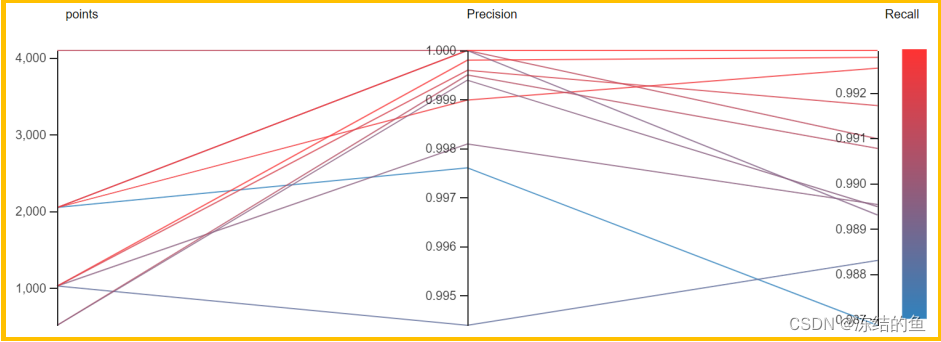
图10. 帧长和指标的关系
从图 10 可以看到,2048 的长度反而达到了最好的 Precison 和 Recall,2048 相比 4096可以节省不少 Ram,是一个比较合适的参数。这里 4096 相对的测试样例比较少,可能需要进一步确认。
3.3. 采样率对结果的影响
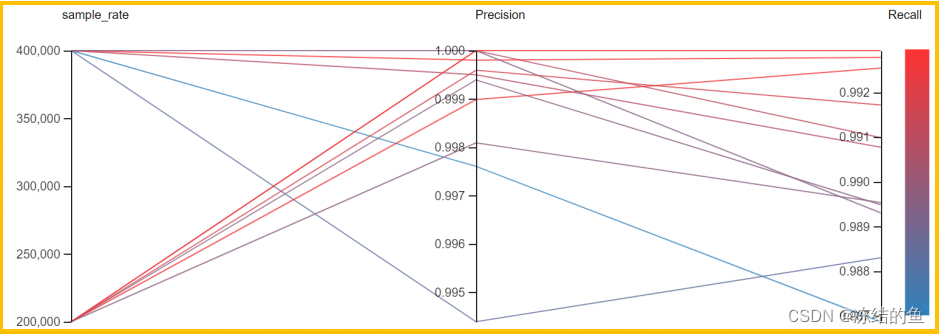
图11. 采样率和指标的关系
从图 11 中可以看到 200KHz 采样率比 400KHz 更稳定,更容易达到更高的评分。
4. 总结
从上面的分析,可以得到以下基本的信息:
- 超参数的选择不是一件容易的事情,需要大量的实验以得到稳定可靠的结论。
- 模型实验对数据的质量要求很高,稳定可靠的数据才能得到可靠的结论,否则实际部署会存在较大差异。
- 从文中图中可以看到,不一定采样率越高越好,帧长越长越好,相反,较低的采样率和帧长可以大大节省 Flash 和 Ram 的空间,以及减少推断时间。
目前测试进行的实验次数仍然较少,可能得到的结论不一定非常准确,本文中的实验全部使用了相同的数据集和相同的网络模型,以减少评估参数。客户可以根据实际需要,使用更多的模型,更多的测试参数进行实验。
文档中所用到的工具及版本
Mlflow 2.3.0
本文档参考ST官方的《【应用笔记】LAT1339+AFCI应用笔记三、使用mlflow管理模型》文档。
参考下载地址:https://download.csdn.net/download/u014319604/89083052