1 处理模型【Processing Model】
DBMS 的处理模型【Processing Model】定义了系统如何执行【execute】查询计划【Query Plan】。
- 针对不同的工作负载进行不同的权衡。
方法1:迭代器模型【Iterator Model】
方法2:物化模型【Materialization Model】
方法3:矢量化/批处理模型【Vectorized / Batch Model】
1.1 迭代器模型
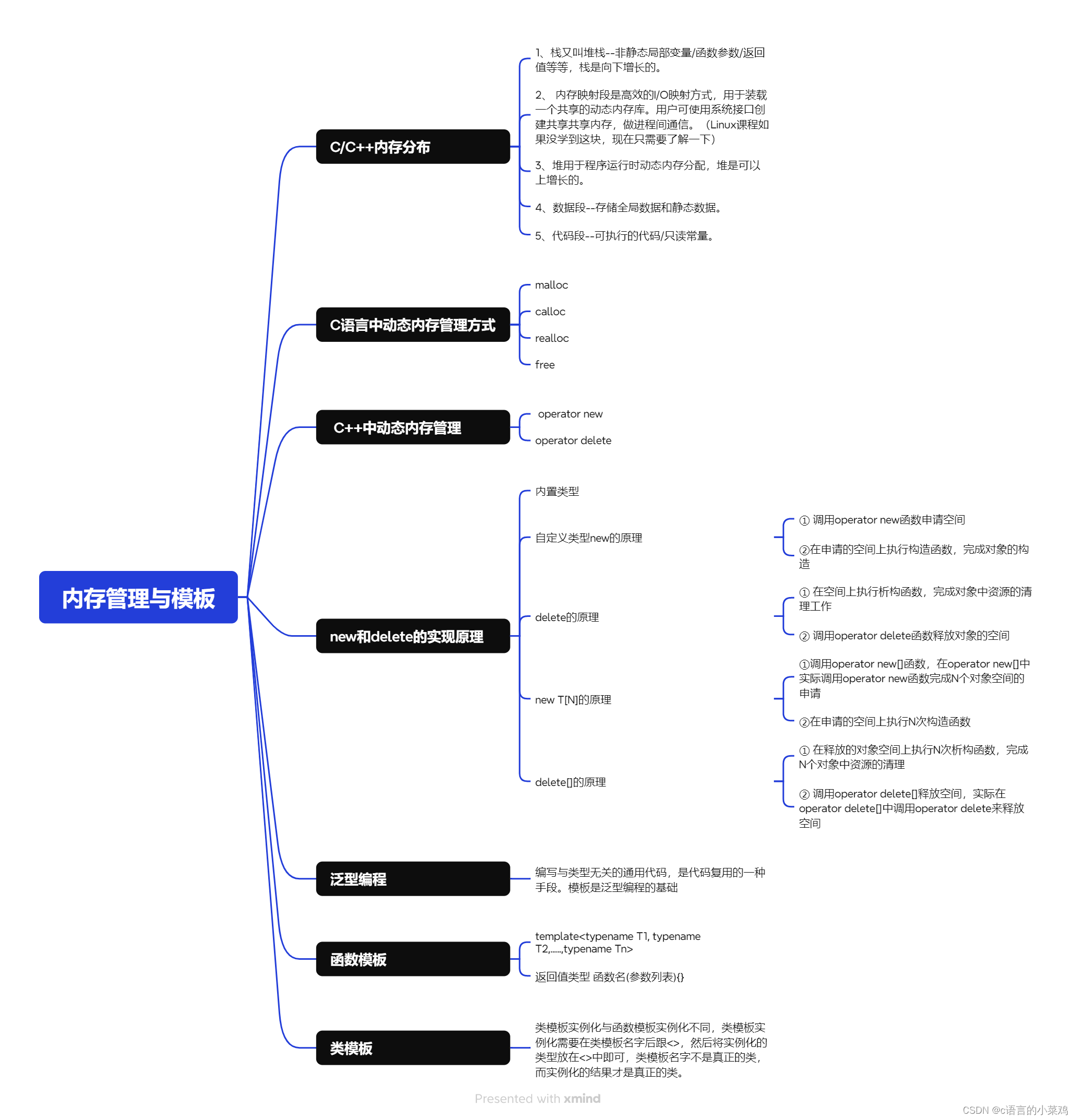
迭代器是最简单的模型。他是一种自顶向下的方法。
每个查询计划【Query Plan】的(物理)操作符【Operator】都实现一个 Next() 函数。
- 在每次调用时,操作符返回单个元组(需要注意的是,这个元组可以是关于列的一个子集,也可以是 Record ID),如果没有更多元组,则返回 eof 标记。
- 操作符实现一个循环,即查询计划树中的父操作符在在其子节点的操作符上调用 Next() 来检索其输出元组,然后处理它们。
每个操作符的实现还具有 Open() 和 Close() 函数,它们类似于构造函数和析构函数,但这是用于操作符的罢了。
迭代器模型也称为火山模型【Volcano Model】或管道模型【Pipeline Model】。
如今大多数 DBMS 都使用这种方法,,它使得元组流水线【pipeling】成为可能。
许多运算符必须阻塞,直到他们的子操作符发出所有元组,赭红操作符也被称为 Pipeline Breaker:
- 连接【Joins】,
- 子查询【Subqueries】
- 排序【Order By】
使用这种方法可以轻松进行输出控制。比如我们在查询【Query】中添加 LIMIT 10 子句,那么点那个我们的根操作符在迭代了 10 次后就可以停止了,我们不需要再继续调用 Next 了。
迭代器的约束是:我们一次只能处理一个元组,我们通过 Next 获取一个元组,然后可能会去做一些成本很高的操作,如果我们可以批量处理,那么就可以摊销很多的成本。
1.2 物化模型
物化模式是一种自底向上的方法。当父操作符调用子操作符时,他总是生成他可以生成的所有结果,然后上推给它的父擦作符。
每个操作符一次处理所有输入,然后一次发出所有输出。
- 操作符将其输出“物化”为单个结果。
- DBMS 可以下推提示【push down hints】(例如 LIMIT)以避免扫描太多元组。
- 可以发送物化后的行或者单个行。
输出可以是整个元组 (NSM) 或列的子集 (DSM)。

在该模型下,我们经常会用到内链【inline】,比如图中的 S 表假设有亿万数据,我们将所有元组加载到内存,然后一次返回给父操作符,这种方法太愚蠢了,因此我们会将某些操作符进行内联。
物化模型更适合 OLTP 工作负载,因为查询一次仅访问少量元组。
- 更低的执行/协调开销。
- 更少的函数调用/操作符调用
但是不适合具有大量中间结果的 OLAP 查询。
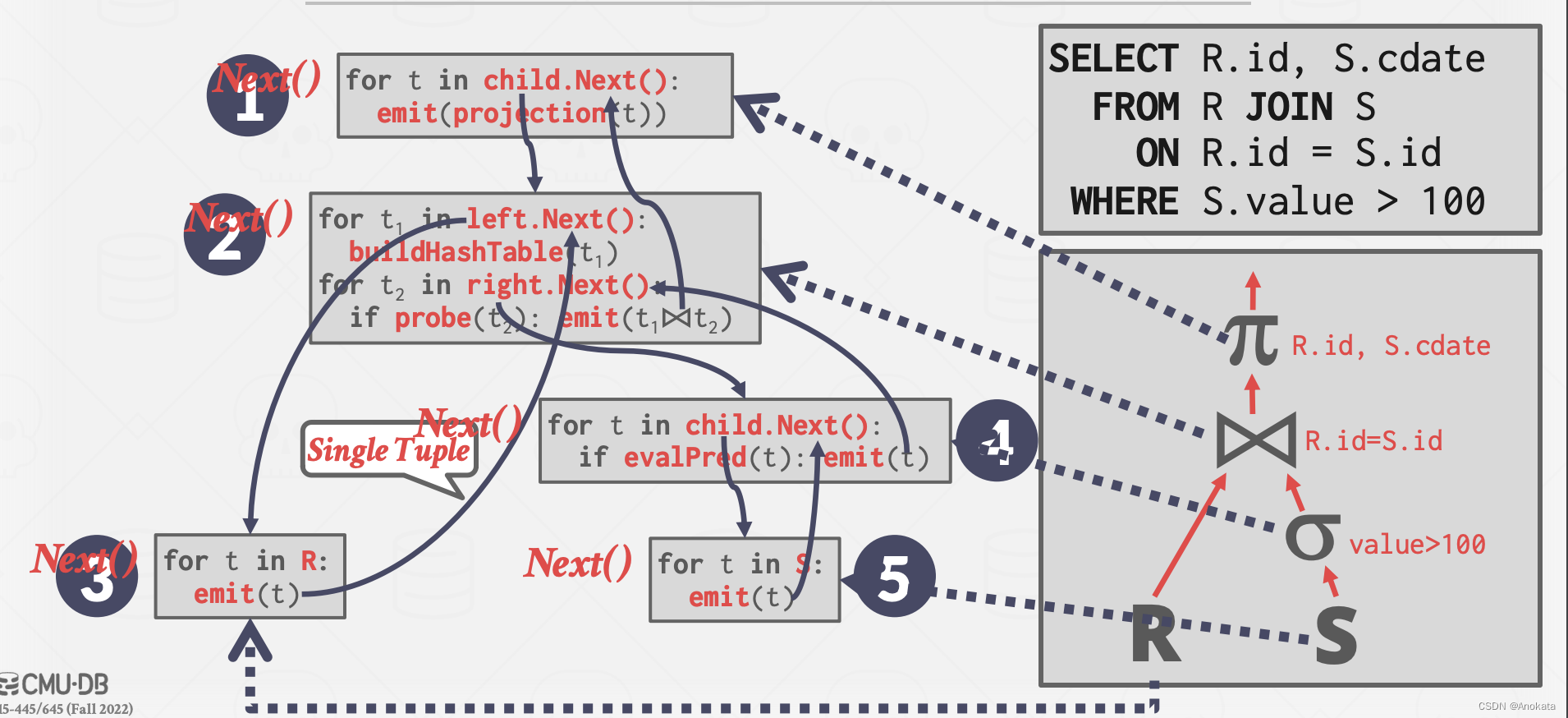
1.3 矢量模型
矢量模型就像迭代器模型一样,每个运算符都实现一个 Next() 函数,但是每个操作符发出一批元组而不是单个元组。
- 每个运算符在内部作循环中,一次处理多个元组来加快速度(由于我们一次可以看到所有的数据,我们可以做一些矢量化操作,比如SIMD)
- 批次的大小可能因硬件或查询属性而异
矢量化模型非常适合 OLAP 查询,因为它大大减少了每个操作符的调用次数,并使得操最符更轻松地使用矢量化 (SIMD) 指令来处理批量元组。
1.4 PLAN PROCESSING DIRECTION
方法1:自上而下:
- 从根开始,从其子节点“提取”数据。
- 元组总是通过函数调用传递。
方法2:自下而上
- 从叶节点开始,将数据推送到其父节点。
- 允许对管道中的缓存/寄存器进行更严格的控制。
- 更适合动态查询重新优化。
但是,大多数系统都是自顶而下的。
2 访问方法【Access Method】
访问方法是 DBMS 访问存储在表中的数据的方式,它在关系代数中未定义。
三种基本的访问方法:
- 顺序扫描【Sequential Scan】
- 索引扫描【 Index Scan】(许多变体)。
- 多索引扫描【Multi-Index Scan】
2.1 顺序扫描【Sequential Scan】
对于表中的每一页【Page】:
- 从缓冲池中检索它
- 迭代每个元组并检查是否需要包含它

DBMS 维护一个内部游标,用于跟踪它检查过的最后一个页【Page】/槽【SLot】。、
这几乎总是 DBMS 在执行查询时可以做的最糟糕的事情,但它有时候可能是唯一可用的选择(比如当我们没有任何索引时)。
顺序扫描的优化:
- 预取【Prefetching】
- 缓冲池绕过【Buffer Pool Bypass】
- 并行化【Parallelization】
- 堆聚簇【Heap Clustering】
- 延迟物化【 Late Materialization】
- 数据跳过【Data Skipping】
数据跳过
方法1:近似查询【Approximate Queries】(有损)
- 对整个表的采样子集执行查询以产生近似结果。
- 示例:BlinkDB、Redshift、ComputeDB、XDB、Oracle、Snowflake、Google BigQuery、DataBricks
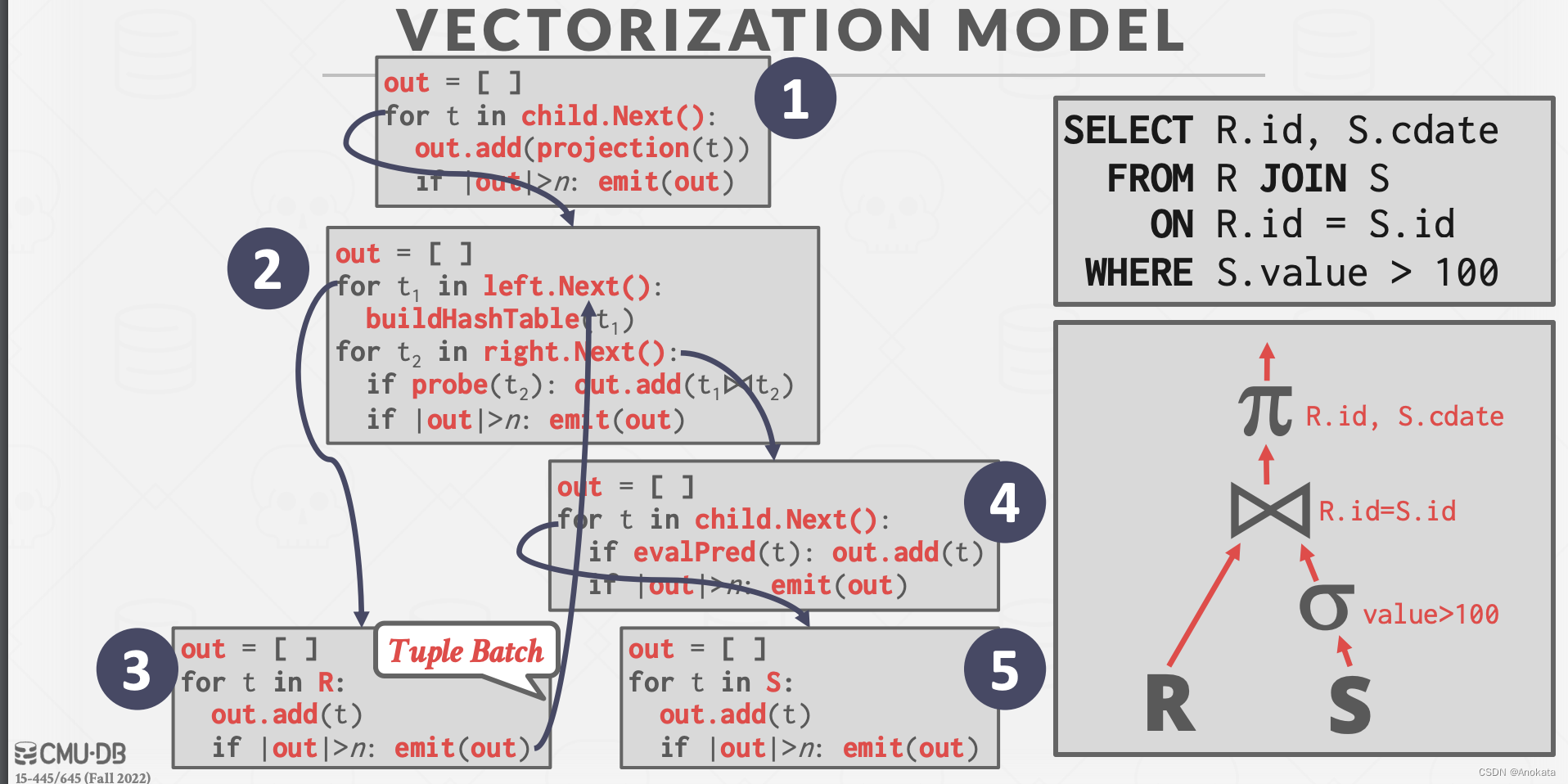
方法2:区域地图【Zone Map】(无损)
- 预先计算每页的列式聚合【Aggregation】,DBMS 首先检查区域地图【Zone Map】来决定是否要访问该页【Page】。
- 需要在页面大小与过滤器效能之间进行权衡,因为页面越大,数据也就越多,如果在一个有百万数据的大页上,我们根据区域地图算出需要访问该页,但是该页中可能只有一条数据满足查询条件,但是我们不得不扫描完整的页。
- 示例:Oracle、Vertica、SingleStore、Netezza、Snowflake、Google BigQuery
2.2 索引扫描【 Index Scan】
DBMS 选择一个索引来查找查询【Query】所需的元组。
使用哪个索引取决于(所有这些都是后面章节里会讲,大概是第12讲):
- 索引包含哪些属性【attribute】
- 查询【Query】引用哪些属性【attribute】
- 属性【attribute】的值域
- 谓词组合【Predicate composition】
- 索引是否有唯一键或非唯一键
假设我们有一个包含 100 个元组和两个索引的表:
→ 索引1:age
→ 索引2:dept
SELECT * FROM students
WHERE age < 30
AND dept = 'CS'
AND country = 'CHINA'
场景1:30岁以下的有99人,但是CS部门只有2人。
在该场景下,我们希望可以选择 dept 索引,因为他的选择性更好,可以顾虑更多的数据
场景1:30岁以下的有 2人,但是CS部门有99人。
在该场景下,我们希望可以选择 age 索引,因为他的选择性更好,可以顾虑更多的数据
2.3 多索引扫描【Multi-Index Scan】
如果 DBMS 可以在一个查询【Query】中使用多个索引:
- 使用每个匹配的索引计算 Record ID 的集合。
- 根据查询【Query】的谓词,来组合这些集合(并集与交集)
- 检索记录并应用剩余的谓词
实现的数据库:
- DB2 多索引扫描
- PostgreSQL 位图扫描
- MySQL 索引合并
SELECT * FROM students
WHERE age < 30
AND dept = 'CS'
AND country = 'CHINA'
继续复用前面的 age 和 dep 的例子:
- 我们可以使用第一个检索 idx_age 来匹配满足 age < 30 的 Record ID
- 然后使用第二个检索 idx_dep 来匹配满足 dept = 'CS' 的 Record ID,
- 取它们 的交集
- 检索记录,并检查 country = 'CHINA'

可以使用位图【Bitmap】或哈希表【Hash Table】有效地完成集合交集。
3 修改查询【Modification Query】
修改数据库的操作符(INSERT、UPDATE、DELETE)需要负责修改目标表【table】及其索引【index】,约束检查可以立即在操作符内部发生,也可以推迟到稍后的查询【Query】/事务【Transction】中。
这些运算符的输出可以是 Record ID 或元组数据(即 RETURNING)。
UPDATE/DELETE:
- 子操作符传递目标元组的 Record ID
- 必须追踪每一个先前看到过的元组(下面例子里会讲,这也是万圣节问题的解决方案)。
INSERT:
- 选择1 :在操作符内部物化元组
- 选择2:操作符插入从子操作符传入【Pass In】的任何元组。
例子:
1️⃣ 假设我们有一张perople表,表中记录了薪水

2️⃣ 现在我想对所有薪水小于 1100 的人作一次 100 元的薪水普调,那么现在我的更新操作符会调用它的子操作符的 Next 方法,该子操作符执行一个索引扫描,以超出所有薪水小于 1100 的工人

3️⃣ 在索引扫描中,我们跟随游标遍历数据,并将满足条件的元组返回给父操作符

4️⃣ 然后父操作符将它从索引内删除,然后插入一条更新后的索引

5️⃣ 然后索引游标继续滑动,但是我们会查到刚才插入的那条数据
这就是著名的万圣节问题【HALLOWEEN PROBLEM】,即:更新操作更改元组的物理位置,导致扫描操作符多次访问该元组的异常。
- 可能发生在聚簇表或索引扫描上。
IBM 研究人员于 1976 年万圣节在 System R 上工作时首次发现。
解决方案:跟踪每个查询【QUery】中修改的 Record ID。
4 表达式评估【Expression Evaluation】
DBMS 将 WHERE 子句表示为表达式树【Expression Tree】。我们前面看到查询计划【QUery Plan】是一颗关于操作符的数,在每个操作符内部依然可以是树结构。
表达式树中的节点代表不同的表达式类型:
- 比较(=、<、>、!=)
- 合取 (AND)、析取 (OR)
- 算术运算符(+、-、*、/、%)
- 常数值
- 元组属性引用【Tuple Attribute Reference】
例子:
1️⃣ 下面是我们要执行的 Prepared 语句,我们调用execute执行它
 2️⃣ 下面是该SQL中的表达式树:
2️⃣ 下面是该SQL中的表达式树:

以这种方式评估谓词的速度其实很慢,DBMS 遍历树,对于它访问的每个节点,它必须弄清楚操操作符需要做什么。
我们来考虑这个谓词:WHERE S.val=1
更好的方法,或者说是优化吧,就是直接计算表达式,回想一下 JIT 编译,Postgre 中就有这个特性,它会将表达式部分内联编译(set jit = 'on')。

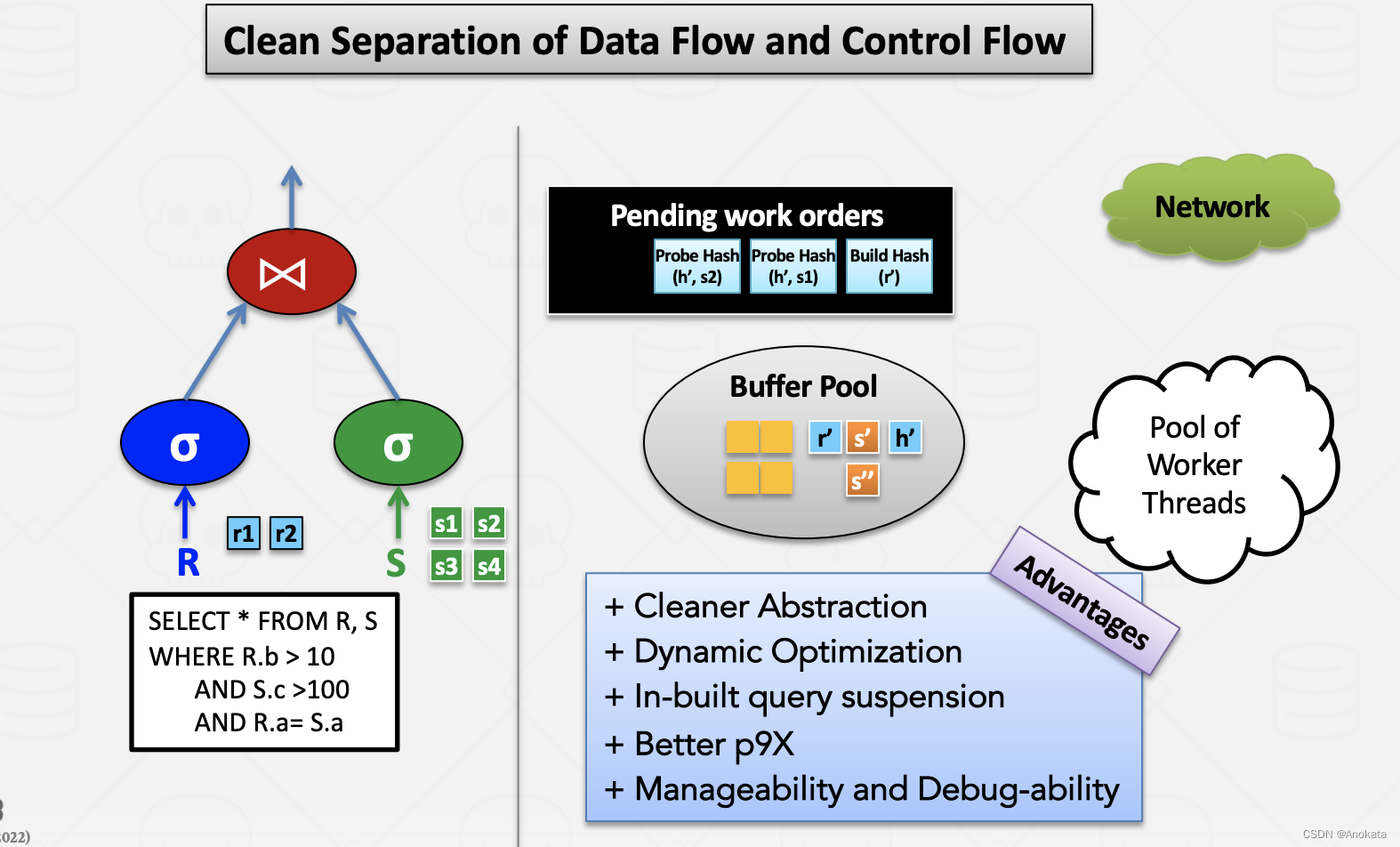
5. Schedule
到目前为止,我们基本上已经从数据流【data flow】的角度了解了查询处理模型【query processing model】。
控制流【conrol flow】隐含在处理模型【processing model】中。 我们可以使用调度程序【scheduler】使控制流更加明确。
数据库论文中通常不会讨论查询调度程序【scheduler】。 我们将看看 Quickstep(学术)项目中做了什么。 基于允许数据流和控制流之间的频繁切换。