需求:
利用python和xpath爬取微博热搜榜
步骤:
爬虫的步骤 获取网页数据-》分析网页数据-》提取网页数据。
1,首先获取微博热搜数据。
热搜主页为
https://s.weibo.com/top/summary?cate=realtimehot打开收,按F12获取网页源码,然后ctrl+hift+c 选择想要爬取的元素,右侧会定位到数据位置

2,分析数据
我们想要内容和链接。
首先看内容
位于 pl_top_realtimehoe 下的 table下的tbody下的tr下的td[2]
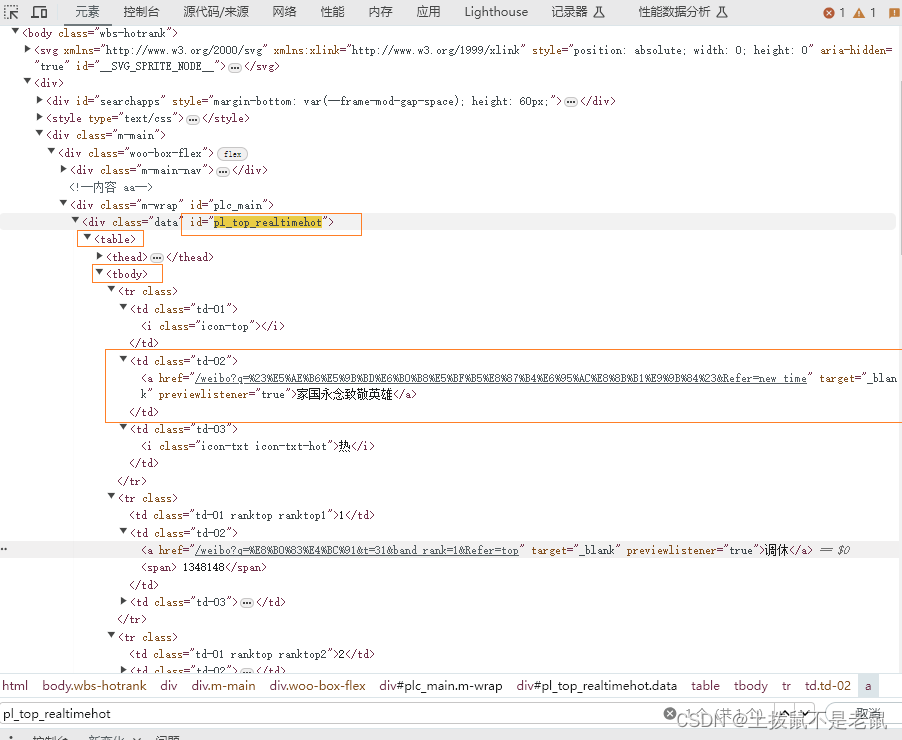
再看链接,跟内容是同一个元素
3,利用xpath提取数据
hot_data['content']=html.xpath('// *[ @ id = "pl_top_realtimehot"] / table / tbody / tr[{}] / td[2] / a/text()'.format(i + 2))[0]
hot_data['link'] = BASE_URL+html.xpath('// *[ @ id = "pl_top_realtimehot"] / table / tbody / tr[{}] / td[2] / a/@href'.format(i + 2))[0]源码:
import requests
from lxml import etree
import json
BASE_URL = 'https://s.weibo.com';
URL = BASE_URL+'/top/summary?cate=realtimehot'
def get():
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36',
'Cookie':'SUB=_2AkMVX_Daf8NxqwJRmP8dzWzrboh0zA3EieKjAwEBJRMxHRl-yT9jqnAatRB6Pt_eNXUD4Q6s4uR7shXrYHP6N5s0DWjy; SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9W5zapBNnh4B9Tkqsf9MdbS-; SINAGLOBAL=9740631714924.42.1644396619729; _s_tentry=-; Apache=7548092887889.8545.1644754490235; ULV=1644754490284:2:2:1:7548092887889.8545.1644754490235:1644396619996'
}
try:
response=requests.get(URL,headers=headers)
html=etree.HTML(response.text)
hot_data_list = []
for i in range(20):
hot_data = {}
hot_data['content']=html.xpath('// *[ @ id = "pl_top_realtimehot"] / table / tbody / tr[{}] / td[2] / a/text()'.format(i + 2))[0]
hot_data['link'] = BASE_URL+html.xpath('// *[ @ id = "pl_top_realtimehot"] / table / tbody / tr[{}] / td[2] / a/@href'.format(i + 2))[0]
hot_data_list.append(hot_data)
json_data =json.dumps(hot_data_list,ensure_ascii=False)
print(json_data)
return json_data
except:
return ("获取热搜数据失败")
if __name__ == '__main__':
get()效果:

备注:
header里需要加上cookie否则数据返回的不对。
最后 插播一条广告: