基于遗传算法(Genetic Algorithm, GA)优化支持向量机(Support Vector Machine, SVM)用于回归预测是一个常见的任务。在这个任务中,我们使用GA来寻找SVM的最佳超参数配置,以最大化回归性能指标,例如R²分数或均方根误差(RMSE)。
下面是一个基本的步骤指南:
步骤 1: 数据准备
准备你的数据集,确保它包含多个输入特征和一个单一的目标变量。确保数据已经进行了适当的预处理,如标准化或归一化。
步骤 2: 定义适应度函数
定义一个适应度函数,它将用来评估SVM模型的性能。这个函数应该接受SVM的超参数作为输入,并返回回归性能指标,如R²分数或RMSE。
步骤 3: 初始化种群
使用GA初始化一个种群,每个个体代表SVM的一个超参数组合。超参数可以包括核函数类型、正则化参数C、核函数的参数等。
步骤 4: 评估种群
对于每个个体(超参数组合),使用适应度函数评估其性能。
步骤 5: 选择操作
通过选择操作(如轮盘赌选择或锦标赛选择)选择适应度较高的个体,以便进行繁殖。
步骤 6: 交叉操作
对选定的个体进行交叉操作,生成新的个体。在SVM的情况下,可以考虑对超参数进行交叉操作。
步骤 7: 变异操作
对生成的新个体进行变异操作,以保持种群的多样性。
步骤 8: 重复迭代
重复步骤4到步骤7,直到满足停止条件(如达到最大迭代次数或达到期望的适应度阈值)。
步骤 9: 最优解提取
从最终种群中选择适应度最高的个体作为最佳超参数配置。
步骤 10: 构建最佳模型
使用最佳超参数配置训练一个新的SVM模型,并使用整个训练集进行训练。
步骤 11: 测试模型
使用测试集评估最佳模型的性能,并计算回归性能指标。
步骤 12: 结果分析
分析最佳模型的性能,并根据需要进行进一步的调整或优化。
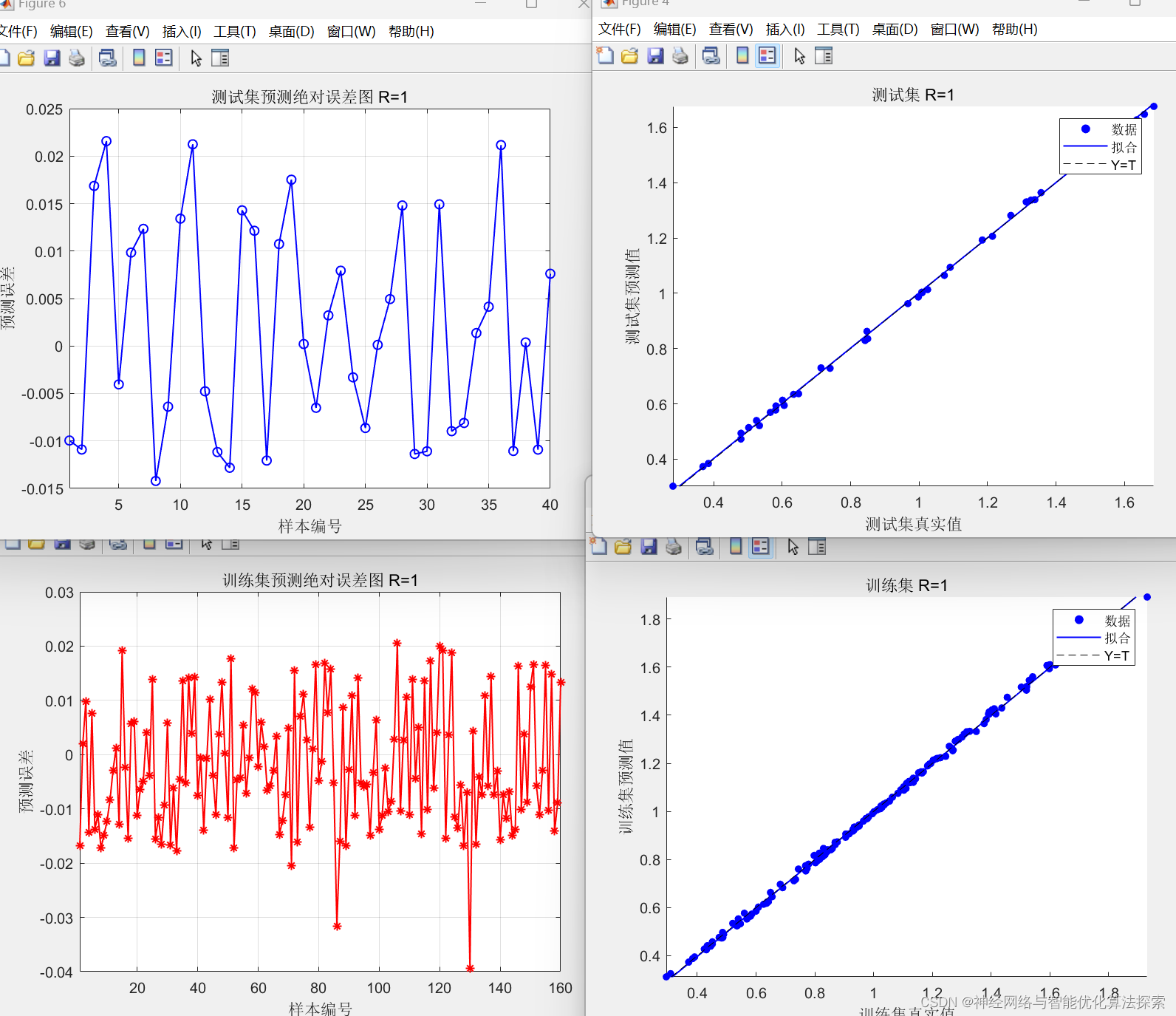
结果如下

代码获取方式如下:
https://mbd.pub/o/bread/mbd-ZZ6Ulp5s