编译和链接
1. 翻译环境和运⾏环境
2. 翻译环境:预编译+编译+汇编+链接
我们知道计算机能够执行的是二进制的指令 而我们的C语言代码都是文本信息
所以我们需要让C语言代码转变为二进制的指令(这是需要编译器来进行处理的)
翻译环境和运⾏环境
在ANSI C的任何⼀种实现中,存在两个不同的环境。
第1种是翻译环境,在这个环境中源代码被转换为可执⾏的机器指令(⼆进制指令)。
第2种是执⾏环境,它⽤于实际执⾏代码
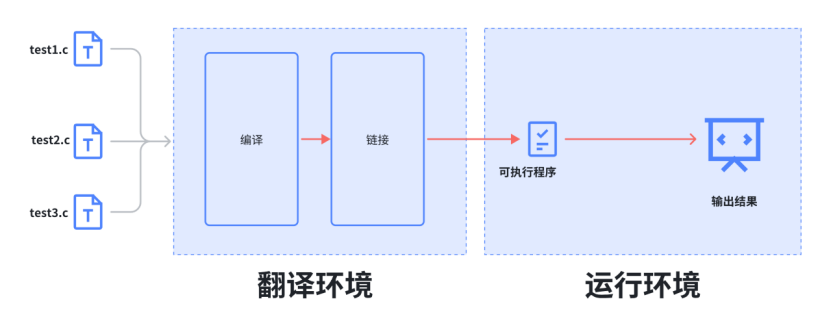
翻译环境
那翻译环境是怎么将源代码转换为可执⾏的机器指令的呢?这⾥我们就得展开开讲解⼀下翻译环境所做的事情。
其实翻译环境是由编译和链接两个⼤的过程组成的,⽽编译⼜可以分解成:预处理(有些书也叫预编译)、编译、汇编三个过程。

Windows环境下 .obj为目标文件
VS2020:集成开发环境(编辑器 编译器 链接器 调试器)
⼀个C语⾔的项⽬中可能有多个 .c ⽂件⼀起构建,那多个 .c ⽂件如何⽣成可执⾏程序呢?
• 多个.c⽂件单独经过编译器,编译处理⽣成对应的⽬标⽂件。
• 注:在Windows环境下的⽬标⽂件的后缀是 .obj ,Linux环境下⽬标⽂件的后缀是 .o
• 多个⽬标⽂件和链接库⼀起经过链接器处理⽣成最终的可执⾏程序。
• 链接库是指运⾏时库(它是⽀持程序运⾏的基本函数集合)或者第三⽅库。

如果再把编译器(预处理(有些书也叫预编译)、编译、汇编)展开成3个过程,那就变成了下⾯的过程:
Linux环境下


预处理(预编译)
在预处理阶段,源⽂件和头⽂件会被处理成为.i为后缀的⽂件。
在 gcc 环境下想观察⼀下,对 test.c ⽂件预处理后的.i⽂件,命令如下:
gcc -E test.c -o test.i
预处理阶段主要处理那些源⽂件中#开始的预编译指令。⽐如:#include,#define,处理的规则如下:
• 将所有的 #define 删除,并展开所有的宏定义。
• 处理所有的条件编译指令,如: #if、#ifdef、#elif、#else、#endif 。
• 处理#include 预编译指令,将包含的头⽂件的内容插⼊到该预编译指令的位置。这个过程是递归进⾏的,也就是说被包含的头⽂件也可能包含其他⽂件。
• 删除所有的注释
• 添加⾏号和⽂件名标识,⽅便后续编译器⽣成调试信息等。
• 或保留所有的#pragma的编译器指令,编译器后续会使⽤。
经过预处理后的.i⽂件中不再包含宏定义,因为宏已经被展开。并且包含的头⽂件都被插⼊到.i⽂件中。所以当我们⽆法知道宏定义或者头⽂件是否包含正确的时候,可以查看预处理后的.i⽂件来确认。
编译
编译过程就是将预处理后的⽂件进⾏⼀系列的:词法分析、语法分析、语义分析及优化,⽣成相应的汇编代码⽂件。
编译过程的命令如下:
gcc -S test.i -o test.s
对下⾯代码进⾏编译的时候,会怎么做呢?假设有下⾯的代码:
array[index] = (index+4)*(2+6);
词法分析:
将源代码程序被输⼊扫描器,扫描器的任务就是简单的进⾏词法分析,把代码中的字符分割成⼀系列的记号(关键字、标识符、字⾯量、特殊字符等)。
上⾯程序进⾏词法分析后得到了16个记号:

语法分析
接下来语法分析器,将对扫描产⽣的记号进⾏语法分析,从⽽产⽣语法树。这些语法树是以表达式为节点的树。

语义分析
由语义分析器来完成语义分析,即对表达式的语法层⾯分析。编译器所能做的分析是语义的静态分析。静态语义分析通常包括声明和类型的匹配,类型的转换等。这个阶段会报告错误的语法信息。
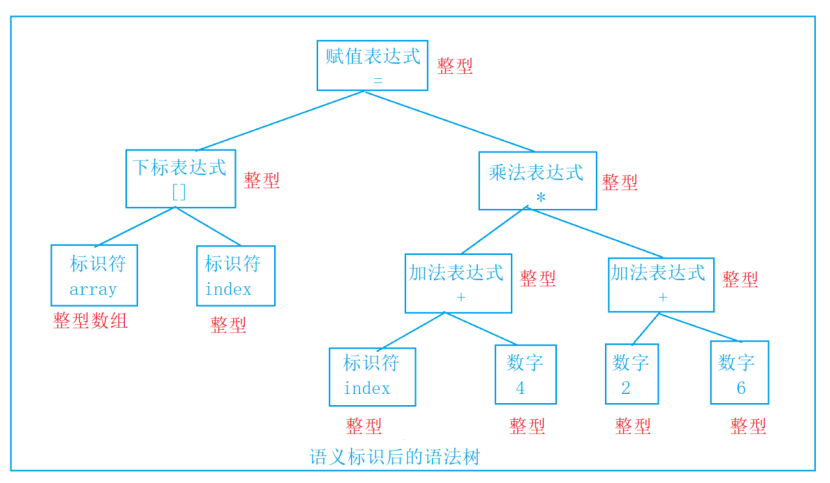
汇编
汇编器是将汇编代码转变成机器可执⾏的指令(目标文件),每⼀个汇编语句⼏乎都对应⼀条机器指令(二进制指令)。就是根据汇编指令和机器指令的对照表⼀⼀的进⾏翻译,也不做指令优化。
汇编的命令如下:
gcc -c test.s -o test.o
链接
链接是⼀个复杂的过程,链接的时候需要把⼀堆⽂件链接在⼀起才⽣成可执⾏程序。
链接过程主要包括:地址和空间分配,符号决议和重定位等这些步骤。
链接解决的是⼀个项⽬中多⽂件、多模块之间互相调⽤的问题。
⽐如:
在⼀个C的项⽬中有2个.c⽂件( test.c 和 add.c ),代码如下:
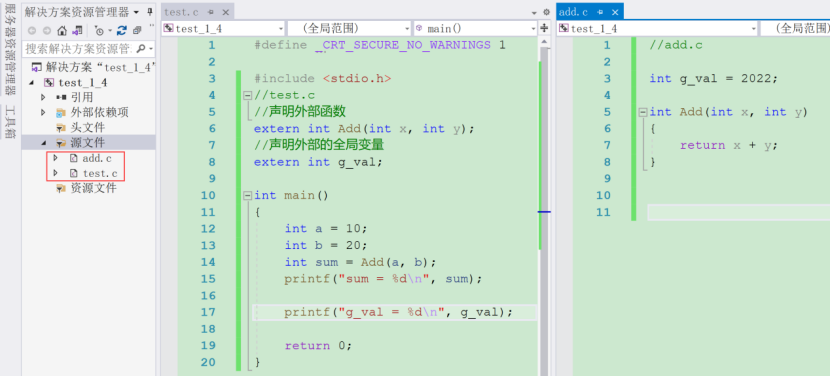
我们已经知道,每个源⽂件都是单独经过编译器处理⽣成对应的⽬标⽂件。
test.c 经过编译器处理⽣成 test.o
add.c 经过编译器处理⽣成 add.o
我们在 test.c 的⽂件中使⽤了 add.c ⽂件中的 Add 函数和 g_val 变量。
我们在 test.c ⽂件中每⼀次使⽤ Add 函数和 g_val 的时候必须确切的知道 Add 和 g_val 的地址,但是由于每个⽂件是单独编译的,在编译器编译 test.c 的时候并不知道 Add 函数和 g_val变量的地址,所以暂时把调⽤ Add 的指令的⽬标地址和 g_val 的地址搁置。等待最后链接的时候由链接器根据引⽤的符号 Add 在其他模块中查找 Add 函数的地址,然后将 test.c 中所有引⽤到
Add 的指令重新修正,让他们的⽬标地址为真正的 Add 函数的地址,对于全局变量 g_val 也是类似的⽅法来修正地址。这个地址修正的过程也被叫做:重定位。
前⾯我们⾮常简洁的讲解了⼀个C的程序是如何编译和链接,到最终⽣成可执⾏程序的过程,其实很多内部的细节⽆法展开讲解。⽐如:⽬标⽂件的格式elf,链接底层实现中的空间与地址分配,符号解析和重定位等,如果你有兴趣,可以看《程序的⾃我修养》⼀书来详细了解
运⾏环境
1. 程序必须载⼊内存中。在有操作系统的环境中:⼀般这个由操作系统完成。在独⽴的环境中,程序
的载⼊必须由⼿⼯安排,也可能是通过可执⾏代码置⼊只读内存来完成。
2. 程序的执⾏便开始。接着便调⽤main函数。
3. 开始执⾏程序代码。这个时候程序将使⽤⼀个运⾏时堆栈(stack),存储函数的局部变量和返回
地址。程序同时也可以使⽤静态(static)内存,存储于静态内存中的变量在程序的整个执⾏过程
⼀直保留他们的值。
4. 终⽌程序。正常终⽌main函数;也有可能是意外终⽌。
预处理详解
预定义符号
C语⾔设置了⼀些预定义符号,可以直接使⽤,预定义符号也是在预处理期间处理的。
__FILE__ //进⾏编译的源⽂件
__LINE__ //⽂件当前的⾏号
__DATE__ //⽂件被编译的⽇期
__TIME__ //⽂件被编译的时间
__STDC__ //如果编译器遵循ANSI C,其值为1,否则未定义
举个例⼦:

关于#define
- #define定义符号(变量)
- #define定义宏
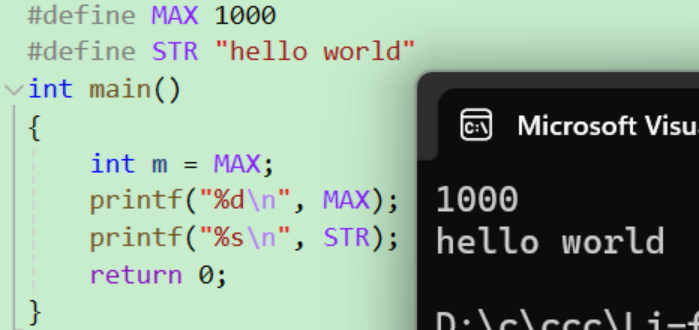
#define 定义常量
基本语法:
![]()
在预处理时 将用define定义的字符全转换成 我要转换的内容 然后将define这条代码删去

1思考:在define定义标识符的时候,要不要在最后加上 ; ?
⽐如:

建议不要加上 ; ,这样容易导致问题。
⽐如下⾯的场景:

如果加了分号 替换后 就变为printf(“%d”,1000;); 所以这里会报错
#define定义宏
#define 机制包括了⼀个规定,允许把参数替换到⽂本中,这种实现通常称为宏(macro)或定义宏(define macro)。
下⾯是宏的申明⽅式:
#define name( parament-list ) stuff
其中的 parament-list 是⼀个由逗号隔开的符号表,它们可能出现在stuff中。
注意:
参数列表的左括号必须与name紧邻,如果两者之间有任何空⽩存在,参数列表就会被解释为stuff的⼀部分。
举例:
1 #define SQUARE( x ) x * x

这个宏接收⼀个参数 x .如果在上述声明之后,你把 SQUARE( 5 ); 置于程序中,预处理器就会⽤下⾯这个表达式替换上⾯的表达式SQUARE( a ): 5 * 5
警告:
这个宏存在⼀个问题:
观察下⾯的代码段:
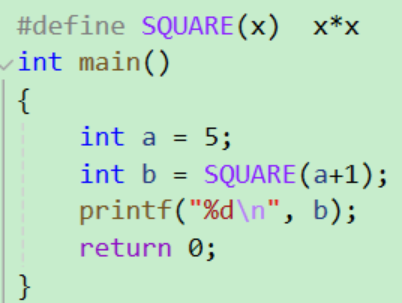
乍⼀看,你可能觉得这段代码将打印36,事实上它将打印11,为什么呢?
替换⽂本时,参数x被替换成a + 1,所以这条语句实际上变成了:

这样就⽐较清晰了,由替换产⽣的表达式并没有按照预想的次序进⾏求值。
在宏定义上加上两个括号,这个问题便轻松的解决了

这⾥还有⼀个宏定义:
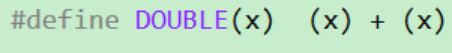
定义中我们使⽤了括号,想避免之前的问题,但是这个宏可能会出现新的错误。

这将打印什么值呢?看上去,好像打印100,但事实上打印的是55.
乘法运算先于宏定义的加法,所以出现了 55 .
这个问题的解决办法是在宏定义表达式两边加上⼀对括号就可以了。

提⽰:
所以⽤于对数值表达式进⾏求值的宏定义都应该⽤这种⽅式加上括号,避免在使⽤宏时由于参数中的操作符或邻近操作符之间不可预料的相互作⽤。
带有副作⽤的宏参数
当宏参数在宏的定义中出现超过⼀次的时候,如果参数带有副作⽤,那么你在使⽤这个宏的时候就可能出现危险,导致不可预测的后果。副作⽤就是表达式求值的时候出现的永久性效果。
例如:
x+1;//不带副作⽤
x++;//带有副作⽤

写一个宏 求2个数的较大值
正常情况如下图:

MAX宏可以证明具有副作⽤的参数所引起的问题。

这里我们大多会感到奇怪
现在我们进行解读 在替换之后 (a++)>(b++) 在这里比较时(a=3)<(b=5)
所以我们采用 (b++) 但在比较结束后 a和b的值都因为后置++的原因而加1 使得a=4,b=6
所以c的值为6
又因为我们采用了b++ b变为7
宏替换的规则
在程序中扩展#define定义符号和宏时,需要涉及⼏个步骤。
1. 在调⽤宏时,⾸先对参数进⾏检查,看看是否包含任何由#define定义的符号。如果是,它们⾸先被替换。
2. 替换⽂本随后被插⼊到程序中原来⽂本的位置。对于宏,参数名被他们的值所替换。
3. 最后,再次对结果⽂件进⾏扫描,看看它是否包含任何由#define定义的符号。如果是,就重复上述处理过程。
注意:
1. 宏参数和#define 定义中可以出现其他#define定义的符号。但是对于宏,不能出现递归。
2. 当预处理器搜索#define定义的符号的时候,字符串常量的内容并不被搜索。
宏函数的对⽐
宏通常被应⽤于执⾏简单的运算。
⽐如在两个数中找出较⼤的⼀个时,写成下⾯的宏,更有优势⼀些。
![]()
那为什么不⽤函数来完成这个任务?
原因有⼆:
1.⽤于调⽤函数和从函数返回的代码可能⽐实际执⾏这个⼩型计算所需要的时间更多。所以宏⽐函数在程序的规模和速度⽅⾯更胜⼀筹。
函数:1.调用函数2.执行运算3.函数返回
宏:没有调用和返回 预处理之后 直接进行数据的替换(只有执行运算时间的耗费)
2.更为重要的是函数的参数必须声明为特定的类型。所以函数只能在类型合适的表达式上使⽤。反之这个宏怎可以适⽤于整形、⻓整型、浮点型等可以⽤于 > 来⽐较的类型。宏的参数是类型⽆关的。
和函数相⽐宏的劣势:
1. 每次使⽤宏的时候,⼀份宏定义的代码将插⼊到程序中。除⾮宏⽐较短,否则可能⼤幅度增加程序的⻓度。
2. 宏是没法调试的。
3. 宏由于类型⽆关,也就不够严谨。
4. 宏可能会带来运算符优先级的问题,导致程序容易出现错误。
宏有时候可以做函数做不到的事情。⽐如:宏的参数可以出现类型,但是函数做不到。
如下图:

宏和函数的⼀个对⽐

#和##
#运算符
#运算符将宏的⼀个参数转换为字符串字⾯量。它仅允许出现在带参数的宏的替换列表中。
#运算符所执⾏的操作可以理解为”字符串化“。
先给大家一个铺垫:

多个字符串(多个“”)在一起可以形成一个字符串(一个“”)
比如我们给int a=1;我们想让程序打印出the value of a is 1
当然我们可以直接用printf来进行 如下图

那当我想多次打印类似的语句 我能不能将上述语句变为一个函数 使其可以多次调用 其实我们无法去封装这样的函数 但是宏可以实现

这里还有一个问题 就是在the value of n中的n 我们没能让其变为a b f
这时候就该我们的#上场了 #运算符将宏的⼀个参数转换为字符串字⾯量
什么意思呢 我们先看代码

#n就是将n变成字符串 ”n” 并替换到宏的体内
## 运算符
## 可以把位于它两边的符号合成⼀个符号,它允许宏定义从分离的⽂本⽚段创建标识符。
## 被称为记号粘合这样的连接必须产⽣⼀个合法的标识符。否则其结果就是未定义的。
使用了##后 形成标识符 如果该标识符中有数据需要被替换也是可以的 但如果没有## 就不要说替换一说了
这⾥我们想想,写⼀个函数求2个数的较⼤值的时候,不同的数据类型就得写不同的函数。
⽐如:

但是这样写起来太繁琐了,现在我们这样写代码试试:

使⽤宏,定义不同函数
预处理时
GENERIC_MAX(int)
替换到宏体内后int##_max生成了新的符号 int_max(做函数名)
GENERIC_MAX(float)
替换到宏体内后float##_max生成了新的符号 float_max(做函数名)
所以在函数调用时 我们便可直接使用这两个函数
在实际开发过程中##使⽤的很少,很难取出⾮常贴切的例⼦
命名约定
⼀般来讲函数的宏的使⽤语法很相似。所以语⾔本⾝没法帮我们区分⼆者。
那我们平时的⼀个习惯是:
把宏名全部⼤写
函数名不要全部⼤写
#undef
这条指令⽤于移除⼀个宏定义。


命令⾏定义
许多C 的编译器提供了⼀种能⼒,允许在命令⾏中定义符号。⽤于启动编译过程。
例如:当我们根据同⼀个源⽂件要编译出⼀个程序的不同版本的时候,这个特性有点⽤处。(假定某个程序中声明了⼀个某个⻓度的数组,如果机器内存有限,我们需要⼀个很⼩的数组,但是另外⼀个机器内存⼤些,我们需要⼀个数组能够⼤些。)

我们可以在编译时 去定义符号 比如这里定义数组大小
我们之前可能会使用#define ARRAY_SIZE=10但注意区别 这里是在编译时 才定义
条件编译
在编译⼀个程序的时候我们如果要将⼀条语句(⼀组语句)编译或者放弃是很⽅便的。因为我们有条件编译指令。
⽐如说:
调试性的代码,删除可惜,保留⼜碍事,所以我们可以选择性的编译。


常⻅的条件编译指令:
1.

如果常量表达式的值为0(假) 即编译器不会包含编译指令中的内容
常量表达式的值为1(真) 编译器便会包含编译指令中的内容
如:

如上图的:

2.多个分支的条件编译

举例:

3.判断是否被定义
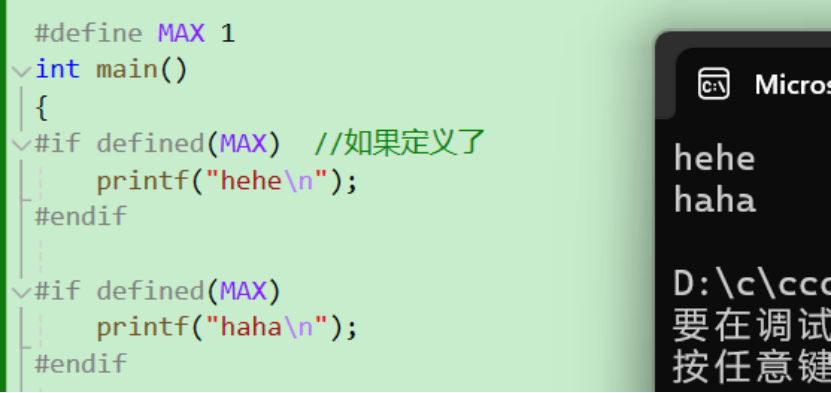

在第二张图中 #if !defined(MAX)和#ifndef MAX的作用是一样的 都是检查MAX有无被定义
注意这里只是看有没有定义 如果给MAX赋值为0 条件仍为真 执行编译
4.嵌套指令

头⽂件的包含
12.1 头⽂件被包含的⽅式:
12.1.1 本地⽂件包含
#include "filename"
查找策略:先在源⽂件所在⽬录下查找,如果该头⽂件未找到,编译器就像查找库函数头⽂件⼀样在标准位置查找头⽂件。
如果找不到就提⽰编译错误。

Linux环境的标准头⽂件的路径:
1 /usr/include
VS环境的标准头⽂件的路径:
1 C:\Program Files (x86)\Microsoft Visual Studio 12.0\VC\include
2 //这是VS2013的默认路径
注意按照⾃⼰的安装路径去找。
库⽂件包含
#include <filename.h>
查找头⽂件直接去标准路径下去查找,如果找不到就提⽰编译错误。
这样是不是可以说,对于库⽂件也可以使⽤ “” 的形式包含?
答案是肯定的,可以,但是这样做查找的效率就低些,当然这样也不容易区分是库⽂件还是本地⽂件了。
2 嵌套⽂件包含
我们已经知道, #include 指令可以使另外⼀个⽂件被编译。就像它实际出现于 #include 指令的地⽅⼀样。
这种替换的⽅式很简单:预处理器先删除这条指令,并⽤包含⽂件的内容替换。
⼀个头⽂件被包含10次,那就实际被编译10次,如果重复包含,对编译的压⼒就⽐较⼤。

如果直接这样写,test.c⽂件中将add.h包含5次,那么add.h⽂件的内容将会被拷⻉5份在test.c中。
如果add.h ⽂件⽐较⼤,这样预处理后代码量会剧增。如果⼯程⽐较⼤,有公共使⽤的头⽂件,被⼤家都能使⽤,⼜不做任何的处理,那么后果真的不堪设想。
如何解决头⽂件被重复引⼊的问题?答案:条件编译。
每个头⽂件的开头写:

第一次由于__TEST_H__ 未被定义 执行编译 然后用define定义 第二次已经定义 不再执行
或者
1 #pragma once
就可以避免头⽂件的重复引⼊。
其他预处理指令
#error
#pragma
#line
...
不做介绍,⾃⼰去了解。
C语言讲到这 已经讲完了 接下来将开启我的JAVA学习之旅



![[技术闲聊]我对电路设计的理解(七)-Cadence原理图绘制](https://img-blog.csdnimg.cn/direct/6db0f0f7ea204061a84e892703c9b629.png)