文章目录
- 环境准备
- 安装 Spark
- 启动 Hadoop(略)
- spark-shell 方式
- 启动 spark-shell
- 插入数据
- 查询数据
- 查询数据
- 更新数据
- 增量查询
- 指定时间点查询
- 删除数据
- 覆盖数据
环境准备
安装 Spark
1)Hudi 支持的 Spark 版本
| Hudi | Supported Spark 3 version |
|---|---|
| 0.12.x | 3.3.x,3.2.x,3.1.x |
| 0.11.x | 3.2.x(default build, Spark bundle only),3.1.x |
| 0.10.x | 3.1.x(default build), 3.0.x |
| 0.7.0-0.9.0 | 3.0.x |
| 0.6.0 and prior | Not supported |
Spark 安装
参考:https://blog.csdn.net/weixin_45417821/article/details/121323669
2)下载 Spark 安装包,解压
cd /opt/software/
wget https://dlcdn.apache.org/spark/spark-3.2.2/spark-3.2.2-binhadoop3.2.tgz
tar -zxvf spark-3.2.2-bin-hadoop3.2.tgz -C /opt/module/
mv /opt/module/spark-3.2.2-bin-hadoop3.2 /opt/module/spark-3.2.2
3)配置环境变量
sudo vim /etc/profile.d/my_env.sh
export SPARK_HOME=/opt/module/spark-3.2.2
export PATH=$PATH:$SPARK_HOME/bin
source /etc/profile.d/my_env.sh
4)拷贝编译好的包到 spark 的 jars 目录
cp /opt/software/hudi-0.12.0/packaging/hudi-spark-bundle/target/hudi-spark3.2-bundle_2.12-0.12.0.jar /opt/module/spark-3.2.2/jars
启动 Hadoop(略)
建议大家用Spark-Yarn的方式接入Hudi ,生产环境中,基本都是Spark on Yarn 同步
spark-shell 方式
启动 spark-shell
1)启动命令
针对 Spark 3.2
spark-shell \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
出现如下图片提示,则代表已经成功!
2)设置表名,基本路径和数据生成器
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val tableName = "hudi_trips_cow"
val basePath = "file:///opt/datas/hudi_trips_cow"
val dataGen = new DataGenerator
不需要单独的建表。如果表不存在,第一批写表将创建该表。
插入数据
新增数据,生成一些数据,将其加载到 DataFrame 中,然后将 DataFrame 写入 Hudi 表。
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Overwrite).
save(basePath)
Mode(overwrite)将覆盖重新创建表(如果已存在)。可以检查/opt/datas/hudi_trps_cow 路径下是否有数据生成。
cd /opt/datas/hudi_trips_cow/
ls

数据文件的命名规则,源码如下:

查询数据
1)转换成 DF
val tripsSnapshotDF = spark.
read.
format("hudi").
load(basePath)
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
查询数据
1)转换成 DF
val tripsSnapshotDF = spark.
read.
format("hudi").
load(basePath)
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
径需要按照分区目录拼接"",如:load(basePath + "////*"),当前版本不需要。
2)查询
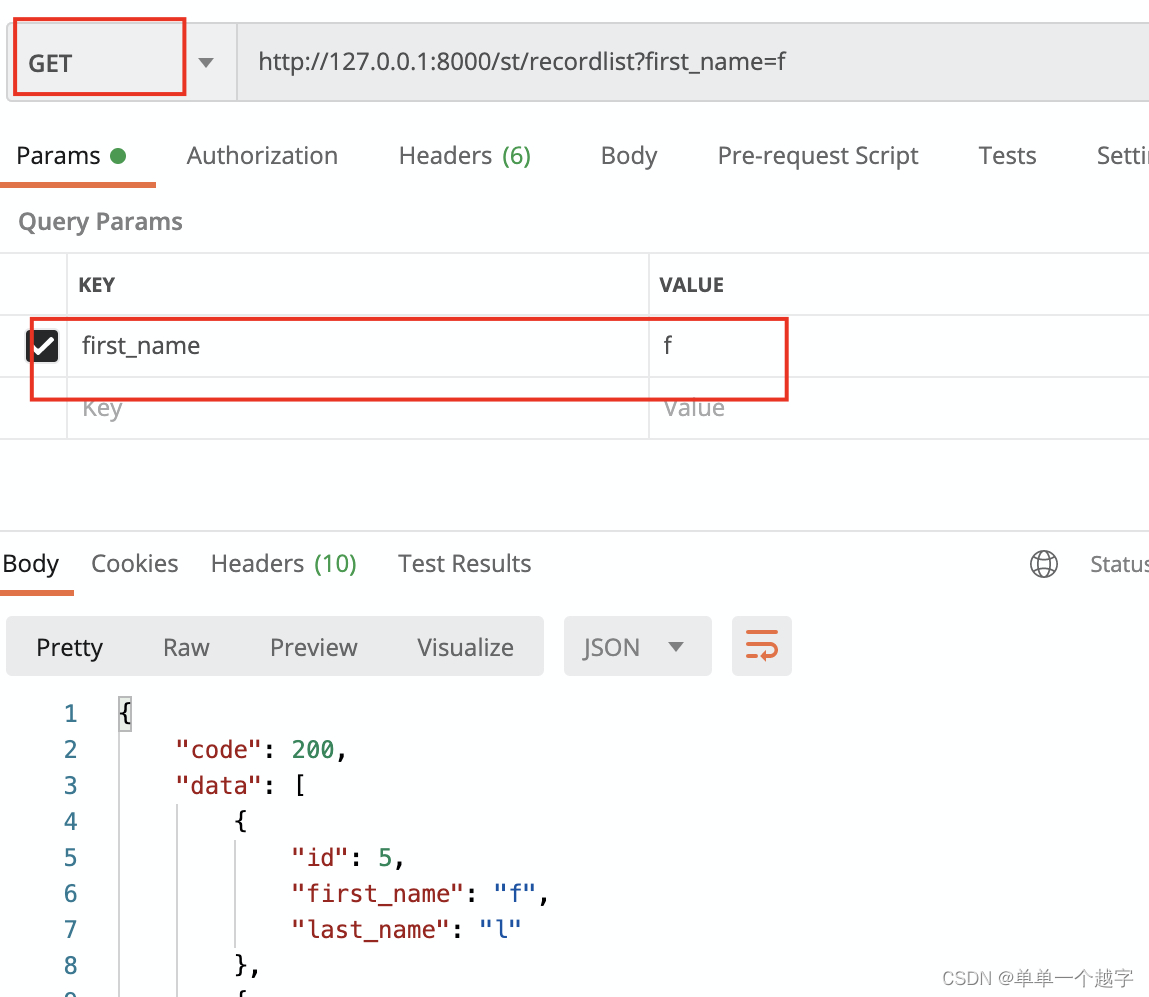
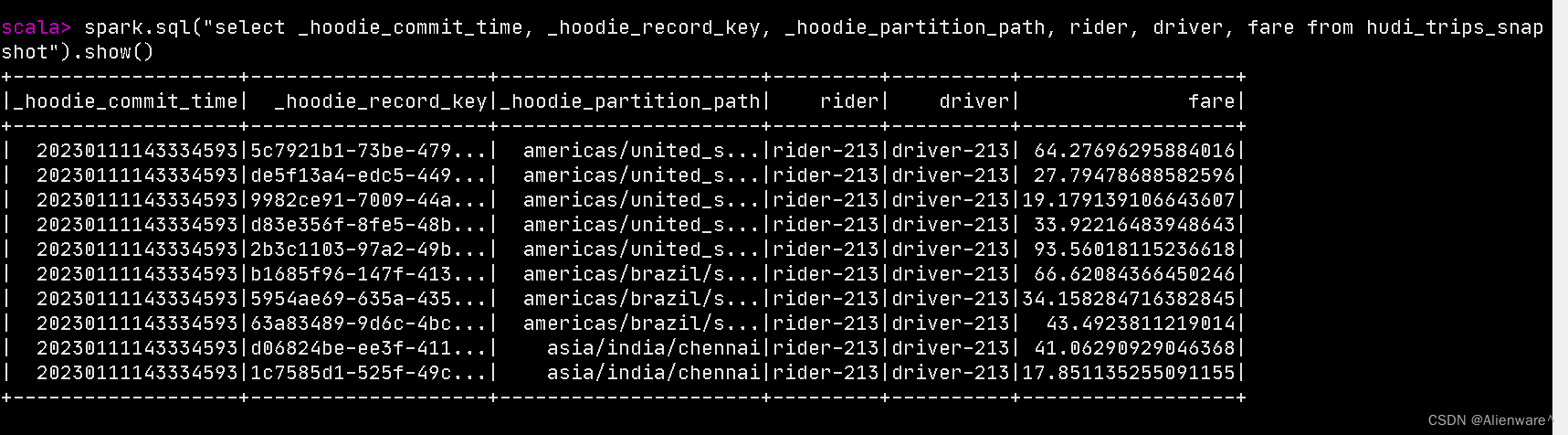
spark.sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0").show()
spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, rider, driver, fare from hudi_trips_snapshot").show()
查询后的效果图如下:
3)时间旅行查询
Hudi 从 0.9.0 开始就支持时间旅行查询。目前支持三种查询时间格式,如下所示。
spark.read.
format("hudi").
option("as.of.instant", "20210728141108100").
load(basePath)
spark.read.
format("hudi").
option("as.of.instant", "2021-07-28 14:11:08.200").
load(basePath)
// 表示 "as.of.instant = 2021-07-28 00:00:00"
spark.read.
format("hudi").
option("as.of.instant", "2021-07-28").
load(basePath)
更新数据
类似于插入新数据,使用数据生成器生成新数据对历史数据进行更新。将数据加载到DataFrame 中并将 DataFrame 写入 Hudi 表中。
val updates = convertToStringList(dataGen.generateUpdates(10))
val df = spark.read.json(spark.sparkContext.parallelize(updates,
2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath)
注意:保存模式现在是 Append。通常,除非是第一次创建表,否则请始终使用追加模式。现在再次查询数据将显示更新的行程数据。每个写操作都会生成一个用时间戳表示的新提交。查找以前提交中相同的_hoodie_record_keys 在该表的_hoodie_commit_time、rider、driver 字段中的变化。
查询更新后的数据,要重新加载该 hudi 表:
val tripsSnapshotDF1 = spark.
read.
format("hudi").
load(basePath)
tripsSnapshotDF1.createOrReplaceTempView("hudi_trips_snapshot1")
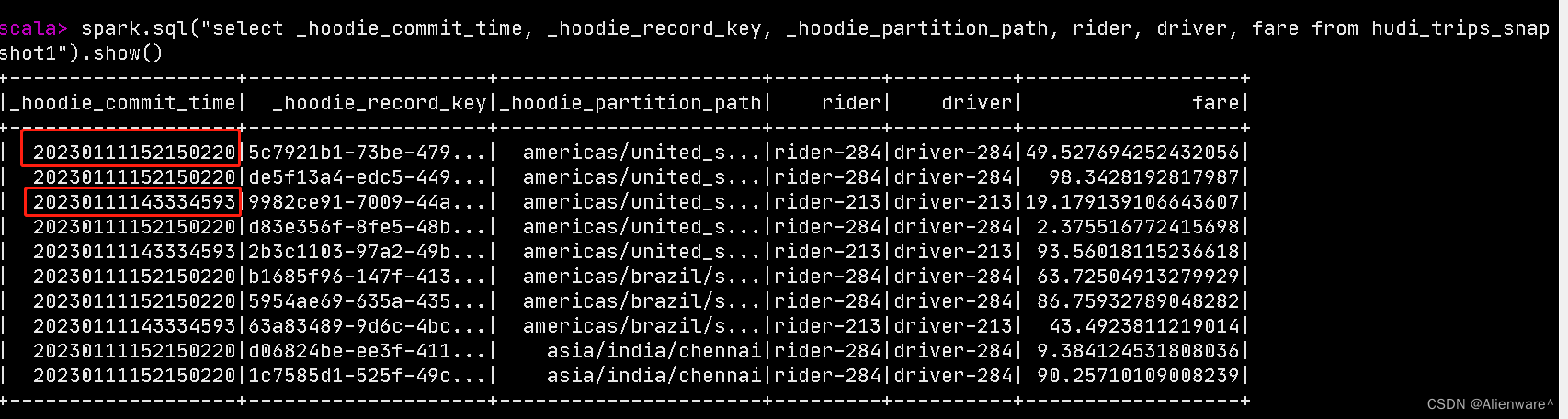
spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, rider, driver, fare from hudi_trips_snapshot1").show()
查询到两个不一样的commit_time
进入文件中查看
cd /opt/datas/hudi_trips_cow/americas/brazil/sao_paulo
发现有两拨更新文件了,下面是新文件,上面是旧文件

如果查看旧文件也很简单,基于查询章节中,基于时间查询即可,举例:
val tripsSnapshotDF2 = spark.read.
format("hudi").
option("as.of.instant", "20230111143334593").
load(basePath)
tripsSnapshotDF2.createOrReplaceTempView("hudi_trips_snapshot2")
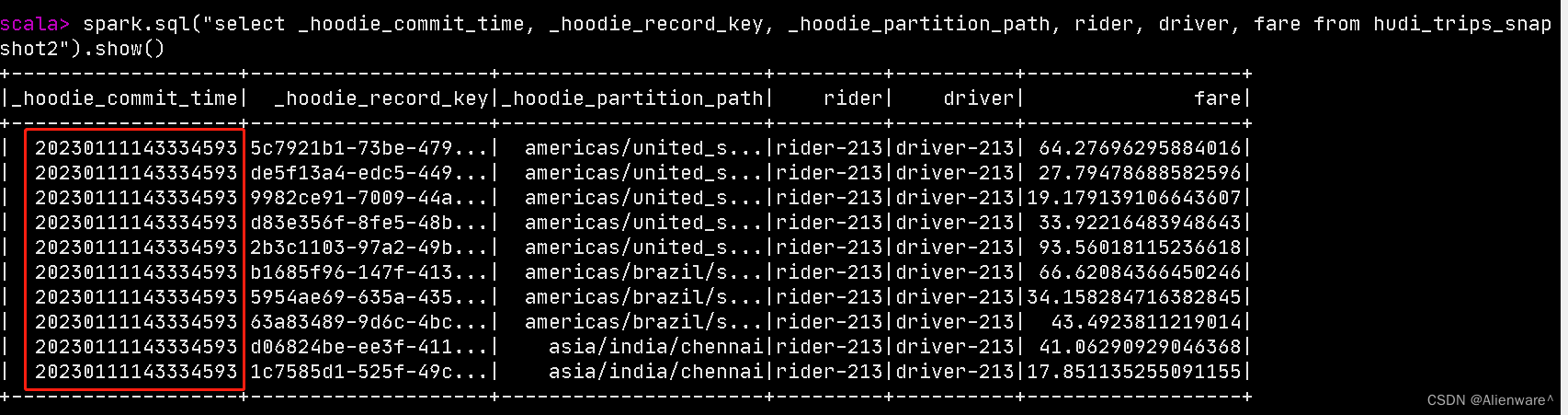
spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, rider, driver, fare from hudi_trips_snapshot2").show()
这样就能看到清一色的以前的文件了
增量查询
Hudi 还提供了增量查询的方式,可以获取从给定提交时间戳以来更改的数据流。需要指定增量查询的 beginTime,选择性指定 endTime。如果我们希望在给定提交之后进行所有更改,则不需要指定 endTime(这是常见的情况)。
1)重新加载数据
spark.
read.
format("hudi").
load(basePath).
createOrReplaceTempView("hudi_trips_snapshot")
2)获取指定 beginTime
val commits = spark.sql("select distinct(_hoodie_commit_time) as commitTime from hudi_trips_snapshot order by commitTime").map(k => k.getString(0)).take(50)
val beginTime = commits(commits.length - 2)
3)创建增量查询的表
val tripsIncrementalDF = spark.read.format("hudi").
option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL).
option(BEGIN_INSTANTTIME_OPT_KEY, beginTime).
load(basePath)
tripsIncrementalDF.createOrReplaceTempView("hudi_trips_incremental")
4)查询增量表
spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_trips_incremental where fare > 20.0").show()
这将过滤出 beginTime 之后提交且 fare>20 的数据。利用增量查询,我们能在批处理数据上创建 streaming pipelines。

指定时间点查询
查询特定时间点的数据,可以将 endTime 指向特定时间,beginTime 指向 000(表示最早提交时间)
1)指定 beginTime 和 endTime
val beginTime = "000"
val endTime = commits(commits.length - 2)
2)根据指定时间创建表
val tripsPointInTimeDF = spark.read.format("hudi").
option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL).
option(BEGIN_INSTANTTIME_OPT_KEY, beginTime).
option(END_INSTANTTIME_OPT_KEY, endTime).
load(basePath)
tripsPointInTimeDF.createOrReplaceTempView("hudi_trips_point_in_time")
3)查询
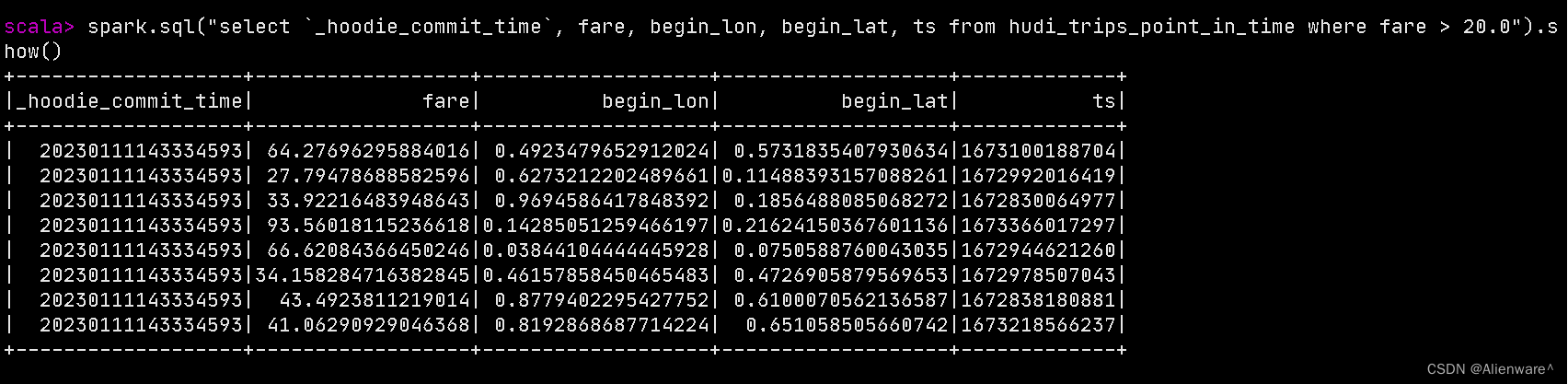
spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_trips_point_in_time where fare > 20.0").show()
查询到最早的时间
删除数据
根据传入的 HoodieKeys 来删除(uuid + partitionpath),只有 append 模式,才支持删除
功能。
1)获取总行数
spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count()
2)取其中 2 条用来删除
val ds = spark.sql("select uuid, partitionpath from hudi_trips_snapshot").limit(2)
3)将待删除的 2 条数据构建 DF
val deletes = dataGen.generateDeletes(ds.collectAsList())
val df = spark.read.json(spark.sparkContext.parallelize(deletes, 2))
4)执行删除
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(OPERATION_OPT_KEY,"delete").
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath)
5)统计删除数据后的行数,验证删除是否成功
val roAfterDeleteViewDF = spark.
read.
format("hudi").
load(basePath)
roAfterDeleteViewDF.registerTempTable("hudi_trips_snapshot")
// 返回的总行数应该比原来少 2 行
spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count()
覆盖数据
对于表或分区来说,如果大部分记录在每个周期都发生变化,那么做 upsert 或 merge 的效率就很低。我们希望类似 hive 的 "insert overwrite "操作,以忽略现有数据,只用提供的新数据创建一个提交。
也可以用于某些操作任务,如修复指定的问题分区。我们可以用源文件中的记录对该分区进行’插入覆盖’。对于某些数据源来说,这比还原和重放要快得多。Insert overwrite 操作可能比批量 ETL 作业的 upsert 更快,批量 ETL 作业是每一批次都要重新计算整个目标分区(包括索引、预组合和其他重分区步骤)。
1)查看当前表的 key
spark.
read.format("hudi").
load(basePath).
select("uuid","partitionpath").
sort("partitionpath","uuid").
show(100, false)
2)生成一些新的行程数据
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.
read.json(spark.sparkContext.parallelize(inserts, 2)).
filter("partitionpath = 'americas/united_states/san_francisco'")
3)覆盖指定分区
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(OPERATION.key(),"insert_overwrite").
option(PRECOMBINE_FIELD.key(), "ts").
option(RECORDKEY_FIELD.key(), "uuid").
option(PARTITIONPATH_FIELD.key(), "partitionpath").
option(TBL_NAME.key(), tableName).
mode(Append).
save(basePath)
4)查询覆盖后的 key,发生了变化
spark.
read.format("hudi").
load(basePath).
select("uuid","partitionpath").
sort("partitionpath","uuid").
show(100, false)