文章目录
- stack的理解和应用
- 栈的理解
- 栈的模拟实现
- string实现stack
- vector实现stack
- queue的理解和应用
- 队列的理解
- 队列的模拟实现
- 双端队列
- 原理的简单理解
- deque的缺陷
- 为什么选择deque作为stack和queue的底层默认容器
- STL标准库中对于stack和queue的模拟实现
- stack的模拟实现
- queue的模拟实现

stack的理解和应用
栈是一种后进先出(Last In, First Out, LIFO)的数据结构,类似于向弹夹里面装子弹和卸子弹。在C++中,栈通常用于实现递归算法、表达式求值、括号匹配等场景。

栈的理解
在C++中,std::stack 是一个容器适配器,它提供了栈的功能。它基于其他容器(如 std::vector、std::deque 等)实现,但只暴露了栈的接口。栈的基本操作包括:
push():向栈顶添加一个元素。pop():移除栈顶的元素。top():访问栈顶元素,但不移除它。empty():检查栈是否为空。size():返回栈中元素的数量。
下面通过一段代码来进行理解
void usestack()
{
stack<int> st;//栈的创建
st.push(1);//入栈
st.push(2);
st.push(3);
st.push(4);
st.push(5);
cout << st.size() << endl;//返回栈中的元素的数量
while (!st.empty())//判断栈是否为空
{
cout << st.top() << " ";//输出栈顶元素
st.pop();//出栈
}
cout << endl;
}
栈的模拟实现
栈的实现通常使用一个动态数组或者链表来存储数据,但栈的接口只允许从栈顶进行操作。
所以通常我们进行实现stack直接用vector或者string来实现就非常的方便
string实现stack
#include <iostream>
#include <string>
#include <stdexcept>
class StringStack {
private:
std::string data;
public:
void push(const std::string& item) {
data += item + " ";
}
void pop() {
if (empty()) {
throw std::out_of_range("Stack<>::pop(): empty stack");
}
size_t lastSpace = data.rfind(' ');
if (lastSpace != std::string::npos) {
data.erase(lastSpace);
} else {
data.clear();
}
}
std::string top() const {
if (empty()) {
throw std::out_of_range("Stack<>::top(): empty stack");
}
size_t lastSpace = data.rfind(' ');
return data.substr(lastSpace + 1);
}
bool empty() const {
return data.empty();
}
size_t size() const {
return data.size();
}
};
vector实现stack
#include <iostream>
#include <vector>
#include <stdexcept>
template <typename T>
class VectorStack {
private:
std::vector<T> data;
public:
void push(const T& item) {
data.push_back(item);
}
void pop() {
if (empty()) {
throw std::out_of_range("Stack<>::pop(): empty stack");
}
data.pop_back();
}
T top() const {
if (empty()) {
throw std::out_of_range("Stack<>::top(): empty stack");
}
return data.back();
}
bool empty() const {
return data.empty();
}
size_t size() const {
return data.size();
}
};
这样就可以很好的模拟实现stack了
queue的理解和应用

队列是一种先进先出(First In, First Out, FIFO)的数据结构,它类似于排队等候服务的队伍:新来的人排在队伍的末尾,而服务总是从队伍的最前面开始。在C++中,队列通常用于任务调度、消息队列、打印任务管理等场景。
队列的理解
在C++中,std::queue 是一个容器适配器,它提供了队列的功能。它基于其他容器(如 std::deque、std::list 等)实现,但只暴露了队列的接口。队列的基本操作包括:
enqueue():向队列尾部添加一个元素。dequeue():移除队列头部的元素。front():访问队列头部元素,但不移除它。empty():检查队列是否为空。size():返回队列中元素的数量。
下面通过一段代码来进行理解
void usequeue()
{
queue<int> qu;
qu.push(1);
qu.push(2);
qu.push(3);
qu.push(4);
qu.push(5);
cout << qu.size() << endl;
cout << qu.back() << endl;//输出队列最后一个元素
while (!qu.empty())//判断队列是否为空
{
cout << qu.front() << " ";//输出队列头元素
qu.pop();//出队列
}
cout << endl;
}
队列的模拟实现
队列的实现通常使用一个动态数组或者链表来存储数据,但队列的接口只允许从队列尾部进行添加操作,从队列头部进行移除操作。
因为string在头插和头删上实际拿上大大的增加,所以一般实现queue就用strack进行
#include <iostream>
#include <list>
#include <stdexcept>
template <typename T>
class ListQueue {
private:
std::list<T> data;
public:
void enqueue(const T& item) {
data.push_back(item);
}
void dequeue() {
if (data.empty()) {
throw std::out_of_range("Queue<>::dequeue(): empty queue");
}
data.pop_front();
}
T front() const {
if (data.empty()) {
throw std::out_of_range("Queue<>::front(): empty queue");
}
return data.front();
}
bool empty() const {
return data.empty();
}
size_t size() const {
return data.size();
}
};
双端队列
在实现栈和队列的时候list和sting或多或少都会有一些问题或者小毛病那有没有一个老大哥呢?这时候就引出了一个新的容器适配器
deque(双端队列):是一种双开口的"连续"空间的数据结构,双开口的含义是:可以在头尾两端进行插入和删除操作,且时间复杂度为O(1),与vector比较,头插效率高,不需要搬移元素;与list比较,空间利用率比较高。
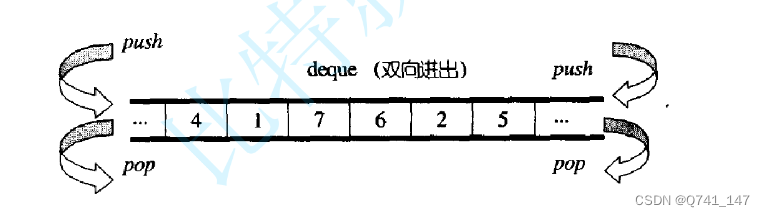
原理的简单理解
那么这个老大哥是怎么进行实现的呢?
deque并不是真正连续的空间,而是由一段段连续的小空间拼接而成的,实际deque类似于一个动态的二维数组,其底层结构如下图所示:
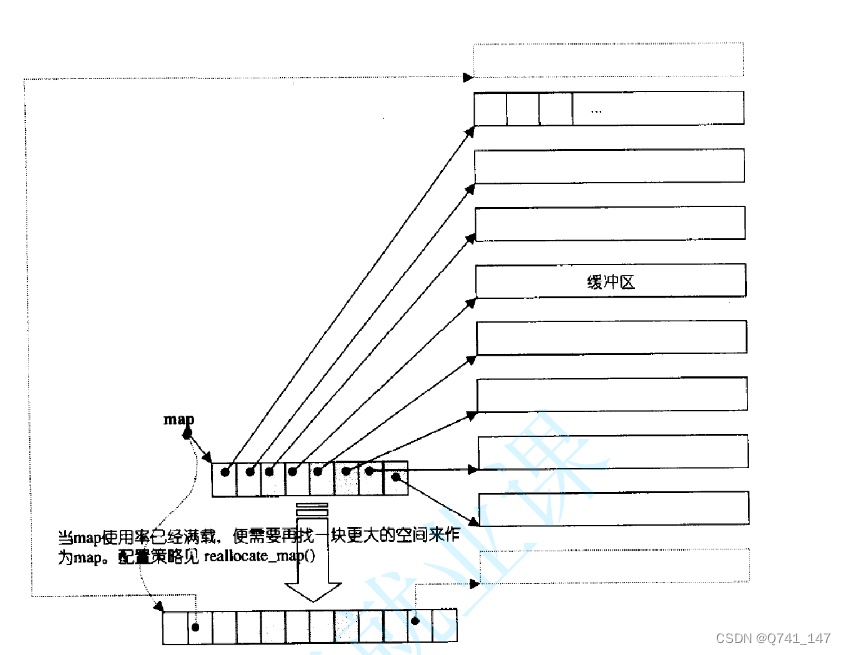
双端队列底层是一段假象的连续空间,实际是分段连续的,为了维护其“整体连续”以及随机访问的假象,落在了deque的迭代器身上,因此deque的迭代器设计就比较复杂,如下图所示:
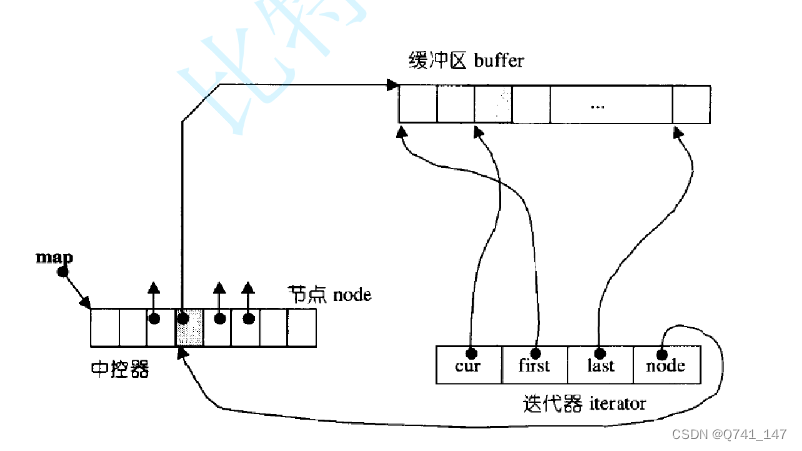
那deque是如何借助其迭代器维护其假想连续的结构呢?
通过一个中控器(图中map)来进行多个buffer的连接进而实现”连续空间“然后通过两个迭代器start和finish进行查找和遍历每个迭代器都有四个节点cur,first,last分别是在buffer指向任意位置,头尾的。而node是指向中控器进而连接下一个buffer而finsh指向随后一个buffer的最后一个元素二点下一个位置进行结尾的定位
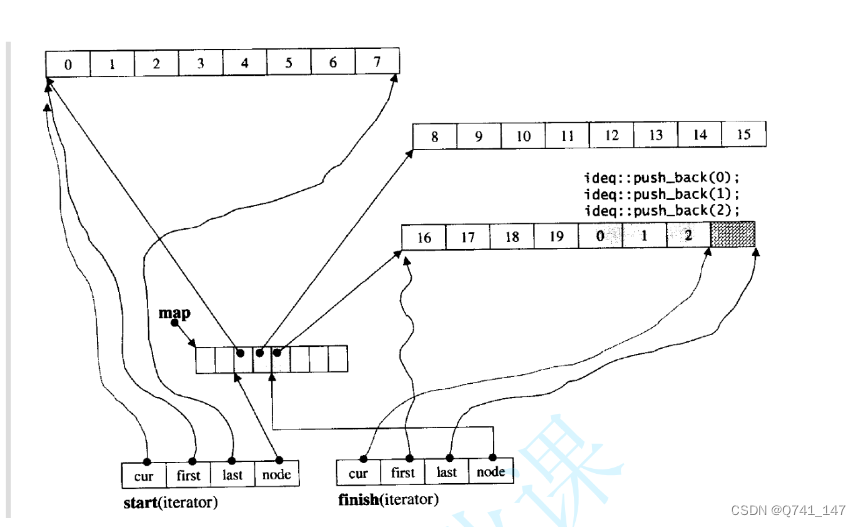
deque的缺陷
- 与
vector比较,deque的优势是:头部插入和删除时,不需要搬移元素,效率特别高,而且在扩容时,也不需要搬移大量的元素,因此其效率是必vector高的。 - 与
list比较,其底层是连续空间,空间利用率比较高,不需要存储额外字段。 - 但是,
deque有一个致命缺陷:不适合遍历,因为在遍历时,deque的迭代器要频繁的去检测其是否移动到某段小空间的边界,导致效率低下,而序列式场景中,可能需要经常遍历,因此在实际中,需要线性结构时,大多数情况下优先考虑vector和list,deque的应用并不多,而目前能看到的一个应用就是,STL用其作为stack和queue的底层数据结构。
所以这么看这个老大哥也不是万能的

为什么选择deque作为stack和queue的底层默认容器
stack是一种后进先出的特殊线性数据结构,因此只要具有push_back()和pop_back()操作的线性结构,都可以作为stack的底层容器,比如vector和list都可以;queue是先进先出的特殊线性数据结构,只要具有push_back和pop_front操作的线性结构,都可以作为queue的底层容器,比如list。但是STL中对stack和queue默认选择deque作为其底层容器,主要是因为:
stack和queue不需要遍历(因此stack和queue没有迭代器),只需要在固定的一端或者两端进行操作。- 在stack中元素增长时,deque比
vector的效率高(扩容时不需要搬移大量数据);queue中的元素增长时,deque不仅效率高,而且内存使用率高。
结合了deque的优点,而完美的避开了其缺陷。
STL标准库中对于stack和queue的模拟实现

stack的模拟实现
#include<deque>
namespace bite
{
template<class T, class Con = deque<T>>
//template<class T, class Con = vector<T>>
//template<class T, class Con = list<T>>
class stack
{
public:
stack() {}
void push(const T& x)
{
_c.push_back(x);
}
void pop()
{
_c.pop_back();
}
T& top()
{
return _c.back();
}
const T& top()const
{
return _c.back();
}
size_t size()const
{
return _c.size();
}
bool empty()const
{
return _c.empty();
}
private:
Con _c;
};
}
queue的模拟实现
#include<deque>
#include <list>
namespace bite
{
template<class T, class Con = deque<T>>
//template<class T, class Con = list<T>>
class queue
{
public:
queue()
{}
void push(const T& x)
{
_c.push_back(x);
}
void pop()
{
_c.pop_front();
}
T& back()
{
return _c.back();
}
const T& back()const
{
return _c.back();
}
T& front()
{
return _c.front();
}
const T& front()const
{
return _c.front();
}
size_t size()const
{
return _c.size();
}
bool empty()const
{
return _c.empty();
}
private:
Con _c;
};
}
感觉好的话点个赞