目录
- Introduction
利用大型语言模型(LLM)进行推荐最近引起了相当大的关注,其中微调在 LLM 的适应中发挥着关键作用。然而,在快速扩展的推荐数据上微调LLMs的成本限制了其实际应用。为了应对这一挑战,小样本微调提供了一种很有前途的方法,可以使LLMs快速适应新的推荐数据。我们提出了基于 LLM 的高效推荐的 数据修剪任务,旨在识别为 LLM 的 小样本微调量身定制的代表性样本。虽然核心集选择与所提出的任务密切相关,但现有的核心集选择方法通常依赖于次优启发式指标,或者需要对大规模推荐数据进行成本高昂的优化。为了解决这些问题,我们在基于LLM的推荐背景下引入了数据修剪任务的两个主要目标:1)高精度旨在识别可以 带来高整体性能的有影响力的样本; 2)高效率强调了数据 修剪过程的低成本。为了实现这两个目标,我们提出了一种新颖的数据修剪方法,结合了两个分数,即影响力分数和努力分数,以有效地识别有影响力的样本。特别是, 引入影响分数来准确估计删除每个样本对整体性能的影响。为了实现数据修剪过程的低成本,我们采用 小型代理模型来代替 LLM 以获得影响力得分。考虑到替代模型和LLMs之间的潜在差距,我们进一步提出了一个努力分数,以优先考虑专门针对LLMs的一些 硬样本。我们在两个基于 LLM 的竞争性推荐模型上实例化了所提出的方法,并且三个真实世界数据集的实证结果验证了我们所提出方法的有效性。特别是,所提出的方法仅使用 2% 的样本就超越了全数据微调,减少了 97% 的时间成本。
Introduction
LLM 中编码的丰富的世界知识为高效微调提供了一种有前途的解决方案:少样本微调。之前的研究发现,LLM 有潜力通过对随机采样的少量数据进行微调来快速适应推荐任务 [3,4,32](图 1(a)),从而显着减少训练时间和计算成本。尽管其效率很高,但随机采样的数据可能缺乏足够的代表性,无法使法LLMs有效理解新项目和用户行为。为了解决这个问题,我们引入了数据修剪任务,以实现基于 LLM 的高效推荐,其目的是识别为 LLM 的小样本微调量身定制的代表性样本。与此数据修剪任务密切相关的文献是核心集选择[16]。它尝试从完整数据中选择一个较小但具有代表性的子集,旨在实现可比较的性能。现有的核心集选择方法通常分为两类2:1)启发式方法根据预定义的指标选择硬样本或多样化样本[36,39,53]。这种启发式方法不估计选择的样本对经验风险的影响,从而可能导致次优的核心集选择; 2)基于优化的方法主要考虑选择可以最小经验风险的子集。训练有素的 LLM 对完整数据进行研究。然而,由于复杂且成本高昂的双层优化,这些方法不适用于大规模推荐数据集,或者追求这两个目标面临两个挑战: • 为了实现高精度,必须测量离散优化问题[20]。更糟糕的是,无论是启发式的还是基于优化的方法都依赖于通过评估所有样本的一致性来训练良好的模型,成本高昂,因为它需要完整的数据来选择核心集,例如,计算预定义的分数。因此,直接应用这些方法是不可行的。
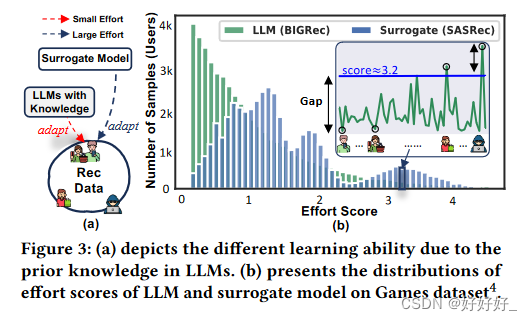
为了克服上述问题,我们总结了在基于LLM的推荐背景下数据修剪的两个主要目标:1)高准确性,重点是选择可以导致低经验风险的样本; 2)高效率,强调数据修剪过程的低成本,即消除训练有素的LLMs对完整数据的依赖。然而,实现这两个目标面临着两个挑战: • 为了实现高精度,必须衡量删除每个训练样本对经验风险的影响。然而,评估所有样本的影响是昂贵的,因为它需要对每个样本进行留一再训练[46]。为了实现高效率,一种可能的解决方案是训练用于样本选择的代理模型,例如使用小型传统推荐模型,与LLM相比,这可以大大减少GPU内存使用和训练时间(见图1( b))。然而,LLMs和代理模型之间存在差距,因为它们在学习用户行为方面的能力不同(参见图 3)。因此,替代模型选择的有影响力的样本可能会偏离LLMs的样本,从而可能损害 大模型的迁移性。
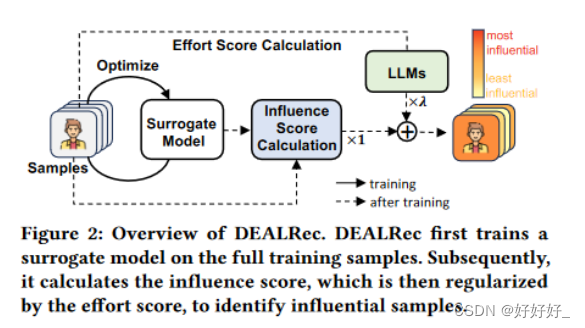
为了应对这些挑战,我们提出了一种新的数据修剪方法,以有效地识别有影响力的样本,以进行基于LLM的推荐器微调(简称为DEALRec)。 DEALRec 利用两个分数,即影响力分数和努力度分数来识别有影响力的样本。制定影响分数来估计删除每个训练样本对经验风险的影响。它是通过链规则和二阶优化技术[28]扩展影响函数[18]来计算的。为了有效计算所有样本的影响力得分,DEALRec 采用了一种简单而有效的对称属性来加速计算,只需要对所有样本进行一次估计(参见第 3.1 节)。此后,DEALRec使用传统的推荐模型作为替代模型来获取影响力分数,并引入努力分数来缩小替代模型与LLM之间的差距。努力分数是通过计算样本损失的梯度范数获得的,直观地衡量LLMs适应特定样本的努力。通过用努力分数对影响力分数进行正则化,DEALRec 识别出具有影响力的样本,这些样本既包含完整数据的代表性,又包含对LLMs的重要性。我们在两个基于 LLM 的推荐模型上实例化 DEALRec,并在三个真实数据集上进行广泛的实验,验证了 DEALRec 在效率和准确性方面的优越性