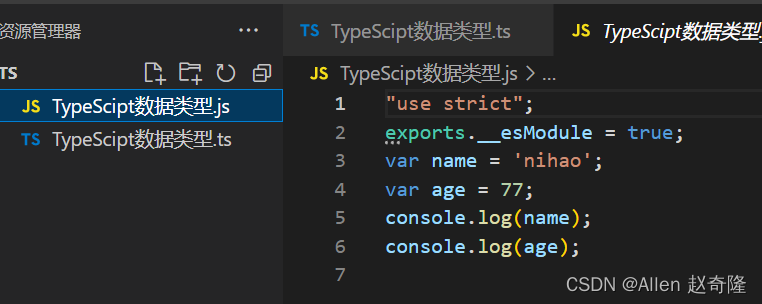
大小写的转换
难度:青铜
0时间限制:1秒
巴占用内存:64M
请编写一个简单程序,实现输入字符大小写的转换。其他非法输入(非
字母的输入)则原样输出。
#include <bits/stdc++.h>
using namespace std;
int main()
{
char ch = getchar();
if(islower(ch))
printf("%c",ch-32);
else
putchar(tolower(ch));
return 0;}作为智能对话系统,ChatGPT最近两天爆火,都火出技术圈了,网上到处都在转ChatGPT相关的内容和测试例子,效果确实很震撼。我记得上一次能引起如此轰动的AI技术,NLP领域是GPT 3发布,那都是两年半前的事了,当时人工智能如日中天如火如荼的红火日子,今天看来恍如隔世;多模态领域则是以DaLL E2、Stable Diffusion为代表的Diffusion Model,这是最近大半年火起来的AIGC模型;而今天,AI的星火传递到了ChatGPT手上,它毫无疑问也属于AIGC范畴。所以说,在AI泡沫破裂后处于低谷期的今天,AIGC确实是给AI续命的良药,当然我们更期待估计很快会发布的GPT 4,愿OpenAI能继续撑起局面,给行业带来一丝暖意。
说回ChatGPT,例子就不举了,在网上漫山遍野都是,我们主要从技术角度来聊聊。那么,ChatGPT到底是采用了怎样的技术,才能做到如此超凡脱俗的效果?既然ChatGPT功能如此强大,那么它可以取代Google、百度等现有搜索引擎吗?如果能,那是为什么,如果不能,又是为什么?
本文试图从我个人理解的角度,来尝试回答上述问题,很多个人观点,偏颇难免,还请谨慎参考。我们首先来看看ChatGPT到底做了什么才获得如此好的效果。

ChatGPT的技术原理
整体技术路线上,ChatGPT在效果强大的GPT 3.5大规模语言模型(LLM,Large Language Model)基础上,引入“人工标注数据+强化学习”(RLHF,Reinforcement Learning from Human Feedback ,这里的人工反馈其实就是人工标注数据)来不断Fine-tune预训练语言模型,主要目的是让LLM模型学会理解人类的命令指令的含义(比如给我写一段小作文生成类问题、知识回答类问题、头脑风暴类问题等不同类型的命令),以及让LLM学会判断对于给定的prompt输入指令(用户的问题),什么样的答案是优质的(富含信息、内容丰富、对用户有帮助、无害、不包含歧视信息等多种标准)。
在“人工标注数据+强化学习”框架下,具体而言,ChatGPT的训练过程分为以下三个阶段:
点击进入—>CV微信技术交流群
作者:张俊林 | (源:知乎)编辑:CVer
https://zhuanlan.zhihu.com/p/589533490
作为智能对话系统,ChatGPT最近两天爆火,都火出技术圈了,网上到处都在转ChatGPT相关的内容和测试例子,效果确实很震撼。我记得上一次能引起如此轰动的AI技术,NLP领域是GPT 3发布,那都是两年半前的事了,当时人工智能如日中天如火如荼的红火日子,今天看来恍如隔世;多模态领域则是以DaLL E2、Stable Diffusion为代表的Diffusion Model,这是最近大半年火起来的AIGC模型;而今天,AI的星火传递到了ChatGPT手上,它毫无疑问也属于AIGC范畴。所以说,在AI泡沫破裂后处于低谷期的今天,AIGC确实是给AI续命的良药,当然我们更期待估计很快会发布的GPT 4,愿OpenAI能继续撑起局面,给行业带来一丝暖意。
说回ChatGPT,例子就不举了,在网上漫山遍野都是,我们主要从技术角度来聊聊。那么,ChatGPT到底是采用了怎样的技术,才能做到如此超凡脱俗的效果?既然chatGPT功能如此强大,那么它可以取代Google、百度等现有搜索引擎吗?如果能,那是为什么,如果不能,又是为什么?
本文试图从我个人理解的角度,来尝试回答上述问题,很多个人观点,偏颇难免,还请谨慎参考。我们首先来看看ChatGPT到底做了什么才获得如此好的效果。
ChatGPT的技术原理
整体技术路线上,ChatGPT在效果强大的GPT 3.5大规模语言模型(LLM,Large Language Model)基础上,引入“人工标注数据+强化学习”(RLHF,Reinforcement Learning from Human Feedback ,这里的人工反馈其实就是人工标注数据)来不断Fine-tune预训练语言模型,主要目的是让LLM模型学会理解人类的命令指令的含义(比如给我写一段小作文生成类问题、知识回答类问题、头脑风暴类问题等不同类型的命令),以及让LLM学会判断对于给定的prompt输入指令(用户的问题),什么样的答案是优质的(富含信息、内容丰富、对用户有帮助、无害、不包含歧视信息等多种标准)。
在“人工标注数据+强化学习”框架下,具体而言,ChatGPT的训练过程分为以下三个阶段:
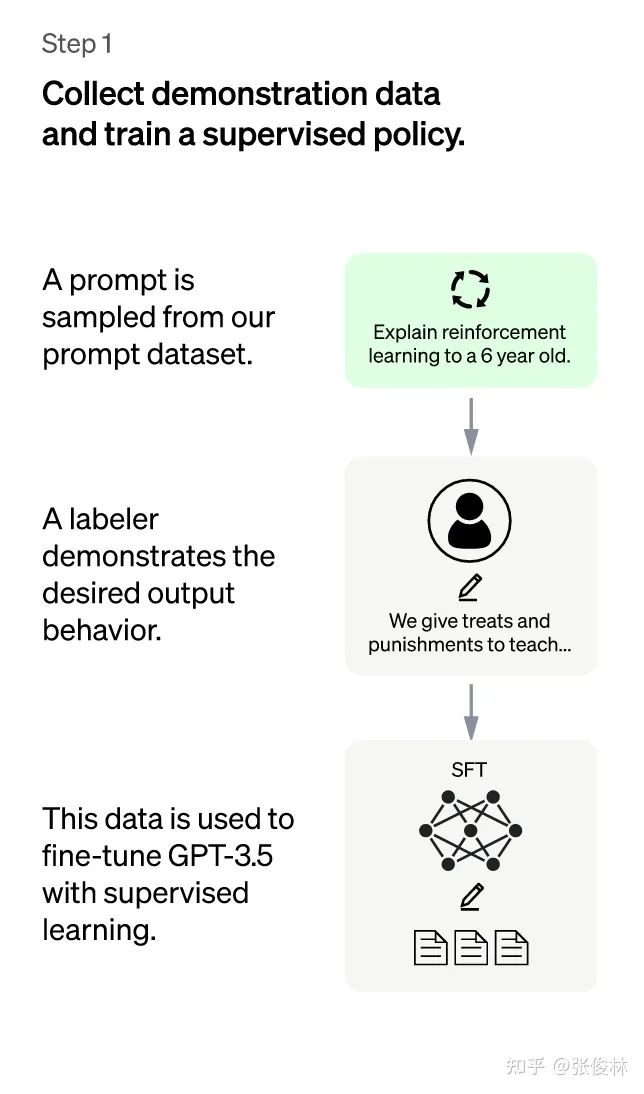
ChatGPT:第一阶段
第一阶段:冷启动阶段的监督策略模型。靠GPT 3.5本身,尽管它很强,但是它很难理解人类不同类型指令中蕴含的不同意图,也很难判断生成内容是否是高质量的结果。为了让GPT 3.5初步具备理解指令中蕴含的意图,首先会从测试用户提交的prompt(就是指令或问题)中随机抽取一批,靠专业的标注人员,给出指定prompt的高质量答案,然后用这些人工标注好的<prompt,answer>数据来Fine-tune GPT 3.5模型。经过这个过程,我们可以认为GPT 3.5初步具备了理解人类prompt中所包含意图,并根据这个意图给出相对高质量回答的能力,但是很明显,仅仅这样做是不够的。







![[JS]JavaScript基础学习笔记(黑马pink+尚硅谷李立超)](https://img-blog.csdnimg.cn/be0cb7e7812a48c2adc1d52dbdcea016.png)