Redis监控方案以及相关黄金指标提升稳定性和可靠性
- 1. 需要了解的词
- 2. 「基准性能」相关指标
- 2.1 Latency
- 2.2 最大响应延迟
- 2.3 平均响应延迟
- 2.4 OPS(instantaneous_ops_per_sec)
- 2.5 Hit Rate
- 3. 「内存」相关指标
- 3.1 内存使用量(used_memory)
- 3.2 内存碎片率(mem_fragmentation_ratio)
- 3.3 被驱逐的 key 数(evicted_keys)
- 3.4 阻塞客户端数(blocked_clients)
- 4. 「基础事件」相关指标
- 4.1 客户端连接数(connected_clients)
- 4.2 副本连接数(connected_slaves)
- 4.3 距离上一次与主实例同步的时间(master_last_io_seconds_ago)
- 4.4 总key数(keyspace)
- 5. 「持久化」相关指标
- 5.1 rdb_last_save_time & rdb_changes_since_last_save
- 6. 「Error」相关指标
- 6.1 拒绝的连接请求(rejected_connections)
- 6.2 未命中key数(keyspace_misses)
- 6.3 与主实例断开的时间( master_link_down_since_seconds )
- 7. 监控方案
- 8. 疑问和思考
- 9. 参考文档
Redis 是非常经典优秀的内存数据库,其拥有非常高的性能;其单机实例在数据结构设计良好,实例健康的情况下能达到10w左右的OPS 现代应用程序对实时性的需求和计算机体系结构的限制决定了:很多时候我们都需要将 in-memory data stores 放在现代应用程序的中心,因此在很多常见场景中我们也都能见到 Redis,如:
- 数据库:可作为传统的基于磁盘的数据库的替代方案。Redis非常简单粗暴地以持久性换取运行速度,并且支持异步磁盘持久化;同时提供了一组丰富的数据原语和非常广泛的命令列表
- 消息队列:Redis 的 blocking list 和低延迟特性使其成为 Message Broker 服务的良好支持
- 内存缓存:Redis 提供了可配置的针对过期 key 的驱逐策略,包括但不限于 LRU 和 LFU等等(下面会提到),使得 Redis 成为了缓存服务器的理想选择,并且 Redis 还支持持久化到磁盘以及快速恢复的机制,提高了其可靠性
即使作为一款高性能数据库,我们也必须建设良好的监控,以保障Redis的稳定性和可靠性,发挥其最大的能力;本文就从来探讨一下 Redis 有哪些值得注意的指标以及相关的监控方案
关于常见分布式组件高可用设计原理的理解和思考
1. 需要了解的词
- OPS:Operates per second 字面含义
- LRU:LRU是Least Recently Used的缩写,意为“最近最少使用”;LRU是一种缓存淘汰策略,用于确定在缓存达到最大容量时哪些项目应该被清除
其基本思想为:当缓存达到其最大容量时,应该清除最近最少使用的项目。具体来说,每当某个项目被访问时,该项目将被移动到一个队列的前面。当缓存达到容量限制时,队列的尾部项目将被清除
由于LRU策略通常具有较好的性能,因此它被广泛用于各种系统中,如操作系统内存管理、数据库、网络缓存等
2. 「基准性能」相关指标
对于 Redis 来说,基准性能可以是 Redis 在一台负载正常的机器上的延迟、OPS以及hit rate(狭义上可以理解为缓存命中率);在不同的硬件环境下 Redis 的性能不尽相同,所以我们需要在相同的硬件条件下来判断 Redis 是否真的变慢了 以下是 Redis 值得注意的基准性能指标:
2.1 Latency
这里的延迟是指对客户端请求和实际服务器响应之间的时间的度量;检查 Redis 实例的延迟是检测 Redis 性能变化最简单也最直接的方式 由于Redis的单线程特性,延迟分布中的异常值可能会导致严重的性能瓶颈,一个请求的响应时间较长就会增加所有后续请求的延迟(在 Redis 6.0 后网络请求由另其它线程管理,一定程度上解决了这个问题)
2.2 最大响应延迟
为了避免业务服务器到 Redis 服务器之间的网络延迟,我们需要直接在 Redis server 上测试实例的响应延迟情况;执行以下命令,就可以得到一个 Redis 实例 60 秒内的最大响应延迟:
bash-5.0# redis-cli -h 127.0.0.1 -p 6379 --intrinsic-latency 60
Max latency so far: 1 microseconds.
Max latency so far: 12 microseconds.
Max latency so far: 38 microseconds.
Max latency so far: 51 microseconds.
Max latency so far: 185 microseconds.
Max latency so far: 213 microseconds.
Max latency so far: 224 microseconds.
Max latency so far: 227 microseconds.
Max latency so far: 228 microseconds.
Max latency so far: 278 microseconds.
Max latency so far: 361 microseconds.
Max latency so far: 677 microseconds.
1980070837 total runs (avg latency: 0.0303 microseconds / 30.30 nanoseconds per run).
Worst run took 22342x longer than the average latency.
从输出结果可以看到,这 60 秒内的最大响应延迟为 677 微秒(0.672ms)
2.3 平均响应延迟
我们还可以使用以下命令查看一段时间内 Redis 的最小、最大、平均访问延迟:
bash-5.0# redis-cli -h 127.0.0.1 -p 6379 --latency-history -i 1
min: 0, max: 1, avg: 0.11 (100 samples) -- 1.01 seconds range
min: 0, max: 1, avg: 0.07 (99 samples) -- 1.01 seconds range
min: 0, max: 1, avg: 0.09 (98 samples) -- 1.00 seconds range
min: 0, max: 1, avg: 0.11 (99 samples) -- 1.01 seconds range
min: 0, max: 1, avg: 0.10 (99 samples) -- 1.01 seconds range
min: 0, max: 1, avg: 0.09 (99 samples) -- 1.01 seconds range
min: 0, max: 1, avg: 0.14 (99 samples) -- 1.01 seconds range
min: 0, max: 1, avg: 0.08 (99 samples) -- 1.01 seconds range
min: 0, max: 1, avg: 0.12 (99 samples) -- 1.00 seconds range
min: 0, max: 1, avg: 0.07 (99 samples) -- 1.01 seconds range
min: 0, max: 4, avg: 0.09 (99 samples) -- 1.01 seconds range
min: 0, max: 3, avg: 0.14 (98 samples) -- 1.00 seconds range
min: 0, max: 1, avg: 0.10 (99 samples) -- 1.01 seconds range
min: 0, max: 1, avg: 0.07 (99 samples) -- 1.00 seconds range
min: 0, max: 1, avg: 0.10 (99 samples) -- 1.00 seconds range
min: 0, max: 1, avg: 0.05 (99 samples) -- 1.01 seconds range
min: 0, max: 1, avg: 0.05 (99 samples) -- 1.01 seconds range
min: 0, max: 1, avg: 0.10 (99 samples) -- 1.01 seconds range
以上输出结果是,每间隔 1 秒,采样 Redis 的平均操作耗时,其结果分布在 0.05 ~ 0.14ms 之间
2.4 OPS(instantaneous_ops_per_sec)
OPS 可以显著地反映 Redis 实例中导致高延迟的原因,高延迟可能由很多问题引起,从积压的命令队列到缓慢的命令,再到网络链路过度使用等等;我们可以通过测量 OPS 来定位问题-如果 OPS 几乎保持不变,则原因不是个别的复杂命令(计算密集型命令);如果一个或多个较慢的命令导致延迟问题,我们或许可以看到 OPS 下降甚至完全归零 每秒处理的命令数量下降可能是 Redis 服务端收到的命令量低或命令阻塞系统速度慢的迹象;服务端收到的命令量低可能是正常的,也可能是服务上游有问题导致的

instantaneous_ops_per_sec 即为我们能直接在 redis-cli 中看到的实时 OPS 指标
2.5 Hit Rate
当使用Redis作为缓存时,监控缓存命中率可以告诉您缓存是否得到有效利用;低命中率意味着客户端正在寻找不再存在的 key,Redis不直接提供命中率指标,但我们仍然可以这样简单计算得到缓存命中率: hit rate = keyspace_hits / (keyspace_hits + keyspace_misses) 缓存命中率低可能由许多因素引起,包括数据过期和分配给Redis的内存不足(这可能会导致 key 的删除)等;低命中率可能会导致上游服务延迟增加,因为它们必须从其它较慢的数据源中获取数据
3. 「内存」相关指标
3.1 内存使用量(used_memory)
内存使用率是 Redis 性能很重要的一part,如果 used_memory 超过总的可用系统内存,操作系统将开始交换旧的/未使用的内存段,每个交换的区段都会写入磁盘,从而严重影响性能;从磁盘写入或读取数据比从内存写入或读取慢5个数量级!(内存为0.1微秒,而磁盘为10毫秒) 我们可以通过在 redis.conf 文件中设置 MaxMemory 来直接控制 Redis 的内存使用限制;启用 MaxMemory 还需要配置 Redis 的驱逐策略,以确定它应该如何释放内存
# Set a memory usage limit to the specified amount of bytes.
# When the memory limit is reached Redis will try to remove keys
# according to the eviction policy selected (see maxmemory-policy).
#
# If Redis can't remove keys according to the policy, or if the policy is
# set to 'noeviction', Redis will start to reply with errors to commands
# that would use more memory, like SET, LPUSH, and so on, and will continue
# to reply to read-only commands like GET.
#
# This option is usually useful when using Redis as an LRU or LFU cache, or to
# set a hard memory limit for an instance (using the 'noeviction' policy).
#
# WARNING: If you have replicas attached to an instance with maxmemory on,
# the size of the output buffers needed to feed the replicas are subtracted
# from the used memory count, so that network problems / resyncs will
# not trigger a loop where keys are evicted, and in turn the output
# buffer of replicas is full with DELs of keys evicted triggering the deletion
# of more keys, and so forth until the database is completely emptied.
#
# In short... if you have replicas attached it is suggested that you set a lower
# limit for maxmemory so that there is some free RAM on the system for replica
# output buffers (but this is not needed if the policy is 'noeviction').
#
maxmemory <bytes>
如下图是一个内存使用量的监控图标:

对于缓存型 Redis 实例来说,一条相对平稳的线就是比较正常的,表示已使用内存得到了合理的运用,旧数据被驱逐的速度和新数据被插入的速度相当
3.2 内存碎片率(mem_fragmentation_ratio)
- 内存碎片率( mem_fragmentation_ratio )指标给出了操作系统(used_memory_rss )
- 使用的内存与 Redis( used_memory )
- 分配的内存的比率
mem_fragmentation_ratio = used_memory_rss / used_memory
操作系统负责为每个进程分配物理内存,而操作系统中的虚拟内存管理器保管着由内存分配器分配的实际内存映射 那么如果我们的 Redis 实例的内存使用量为1 GB,内存分配器将首先尝试找到一个连续的内存段来存储数据;如果找不到连续的段,则分配器必须将进程的数据分成多个段,从而导致内存开销增加,具体的相关解释可参考这篇文章:Redis内存碎片的产生与清理 内存碎片率大于1表示正在发生碎片,内存碎片率超过1.5表示碎片过多,Redis 实例消耗了其实际申请的物理内存的150%的内存;另一方面,如果内存碎片率低于1,则表示Redis需要的内存多于系统上的可用内存,这会导致 swap 操作。内存交换到磁盘将导致延迟显著增加 理想情况下,操作系统将在物理内存中分配一个连续的段,Redis 的内存碎片率等于1或略大于1
3.3 被驱逐的 key 数(evicted_keys)
在使用 Redis 作为缓存的场景下,我们一般都需要将其配置为在达到最大内存限制时自动清除 key ,这时就需要监控被驱逐的 key 了,因为驱逐大量 key 会显著降低 hit rate,从而导致上游服务 latency 增加 如果我们为插入 Redis 的 key 配置了TTL,我们一般也期望它们不是被驱逐出去而是直接过期的(Redis内存过期策略也分为三类:定时策略、惰性策略和定期策略);在这种情况下,如果该指标大于零,我们很可能会发现实例中的 latency 陡然增加(最终请求打在较慢的数据源上导致缓存雪崩) 而大多数其它不使用TTL的配置最终将耗尽内存并开始逐步驱逐 key,但只要上游服务最终对外的平均响应时间是可以接受的,稳定的驱逐率(稳定增长的驱逐数)也就是可以接受的 常见的驱逐策略有以下几种:
- noeviction: 不删除策略,达到最大内存限制时,如果需要更多内存,直接返回错误信息;大多数写命令都会导致占用更多的内存(有极少数会例外, 如 DEL )
- allkeys-lru: 所有key通用; 优先删除最长时间未被使用(less recently used ,LRU) 的 key
- volatile-lru: 只限于设置了 expire 的部分; 优先删除最长时间未被使用(less recently used ,LRU) 的 key
- allkeys-random: 所有key通用; 随机删除一部分 key
- volatile-random: 只限于设置了 expire 的部分; 随机删除一部分 key
- volatile-ttl: 只限于设置了 expire 的部分; 优先删除剩余时间(time to live,TTL) 短的key
- volatile-lfu: added in Redis 4, 从设置了expire 的 key 中删除使用频率最低的 key
- allkeys-lfu: added in Redis 4, 从所有 key 中删除使用频率最低的 key
3.4 阻塞客户端数(blocked_clients)
Redis提供了许多对列表进行操作的阻塞命令,如 BLPOP, BRPOP, BRPOPLPUSH 分别是命令 LPOP, RPOP, RPOPLPUSH 的阻塞版本;当源列表非空时,命令将按预期执行;但当源列表为空时,阻塞命令将一直等到源列表被填充或是命令超时 被「等待数据」阻塞的客户端请求增加可能导致上游服务产生预期外的行为,延迟等很多其它问题都可能会阻止源列表被填充导致阻塞命令;虽然被阻塞的客户端本身不会引起警报,但如果这项指标的值始终非零,我们还是需要重视其根因
4. 「基础事件」相关指标
4.1 客户端连接数(connected_clients)
由于对 Redis 的访问通常由应用程序端处理(用户通常不直接通过 redis-cli 等访问 Redis),因此在大多数场景下,客户端连接数将得到合理的控制。如果该数字超出正常范围,则表示上游服务可能存在问题;如果该数字太低,则表示上游服务可能已经无法连接上 Redis,并且如果客户端连接数太高,大量并发的客户端连接可能会导致 Redis Server 处理请求的能力不堪重负
4.2 副本连接数(connected_slaves)
如果上游服务是读密集型的场景,那么我们经常会使用 Redis 提供的主从复制能力;在这种情况下,监视连接的副本的数量就很重要了,如果连接的复制副本数量突然变动,可能表示主 Redis 实例挂掉了或是复制副本实例出现了问题
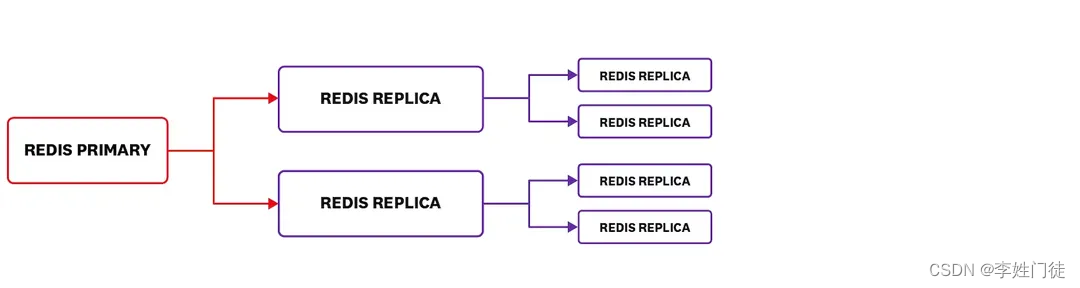
注意:Redis 支持多级主从复制,在上图中,Redis 主实例将显示它有两个连接的副本实例,第一个子节点下的两个一级副本实例也各自有两个二级副本实例。由于二级副本实例不直接连接到 Redis 主实例,因此它们不包括在连接到主实例的副本连接数中
4.3 距离上一次与主实例同步的时间(master_last_io_seconds_ago)
使用 Redis 的主从复制功能时,副本实例会定期同步其主实例(主实例通过发送命令流保证副本实例完全同步),长时间没有同步可能代表着我们的的 Redis 主实例 / 副本实例或介于二者之间的某个地方出现了问题,并且这可能还代表着副本实例中有部分数据已过时 当副本实例在中断后重新连接到主实例时,它会发送 PSYNC 命令,仅尝试对中断期间丢失的命令进行部分同步(partial resynchronization);当 partial resynchronization 不可能完成时,副本实例将向主实例请求完全同步,这时主实例会立即将保存当前数据库的快照到磁盘,并发送给副本实例;同时缓冲将修改数据集的所有新命令也发送给副本实例,这就导致副本实例每次执行完全同步时,都会导致主实例上的延迟显著增加 在这样一种 Redis 主从实例同步的场景下,最大限度地减少主从实例通信的中断就非常重要了,下面的 master_link_down_since_seconds 指标也能直接地监控到这一点
4.4 总key数(keyspace)
作为内存中的数据存储,key 总空间越大,Redis 需要的物理内存就越多,以确保最佳性能;Redis 会继续正常存储 key 直到它达到 maxmemory 限制,然后它开始以新 key 进入的相同速度驱逐 key;这会产生一个「相对平稳的线」,如上面在「内存使用量」一章中的图中所示 如果我们使用 Redis 作为缓存,并看到 key 空间饱和(即出现「相对平稳的线」),且 hit rate 也相对较低,那么上游服务可能正在请求旧数据或被驱逐的数据;
这时监控 keyspace_misses 或许有助于我们的排障和优化 再来看到将 Redis 用作数据库或消息队列的场景,这种不可丢弃数据的场景下我们一般不会设置 volatile 等驱逐策略;那么随着 keyspace 的增长,我们就可能需要考虑加内存或是分布拆分数据集加内存是一种简单而有效的解决方案(加💰!),但当所需要的资源超过单机所能提供的资源量级时,对数据进行分区或分片可以将多台计算机的资源组合在一起。
应用分区计划可以让 Redis 可以在不驱逐或交换(swap)的情况下存储更多 key;当然,应用分区计划比加内存(加💰!)更具挑战性,也面临着很多限制.
5. 「持久化」相关指标
在很多场景下我们都可以启用 Redis 的持久化功能,尤其是在使用 Redis 的主从复制功能时,由于副本实例会同步对主实例所做的任何更改,因此如果主实例重新启动(未启用持久化),则连接到它的所有副本实例都将同步其现在为空的数据集 但如果是缓存场景下的 Redis,或者在其它丢失数据无关紧要的场景中,则持久化就不是必需的了
5.1 rdb_last_save_time & rdb_changes_since_last_save
rdb_last_save_time 和 rdb_changes_since_last_save ,即「上一次rdb持久化的时间点」和「自上一次rdb持久化后的变动」 当 Redis 实例挂掉时,两次持久化之间的时间间隔过长可能会导致过多的数据丢失;
监控 rdb_changes_since_last_save 能让我们够更深入地了解数据的变化,如果数据集在该时间间隔内没有太大变化,那么两次持久化之间的时间间隔较长也没啥问题;同时监控这两个指标,我们就可以了解和大致估计在给定时间点发生故障时会丢失多少数据:
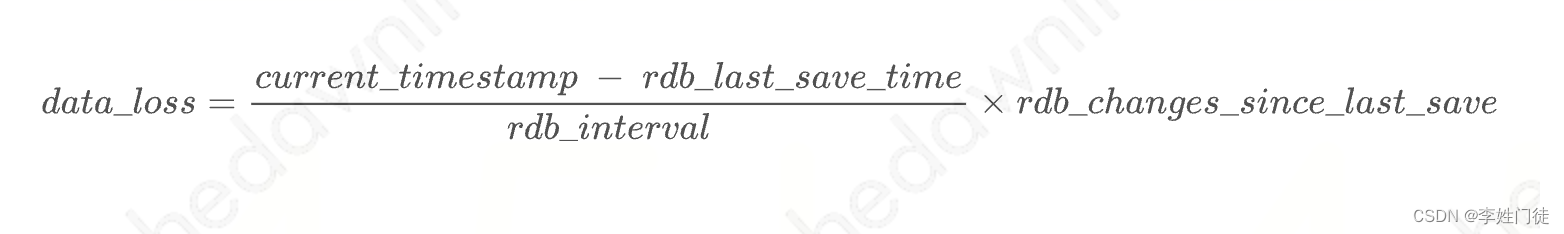
6. 「Error」相关指标
6.1 拒绝的连接请求(rejected_connections)
Redis 能够同时处理非常多的活动连接(长连接),默认配置下有10000个客户端连接可用;我们可以通过更改 redis.conf 中的 maxclient 以配置最大连接数, Redis 实例达到最大连接数后,任何新的连接请求都将被拒绝,以下是客户端建立 Redis 连接的流程图:

⚠️注意:Redis 实例所在的宿主机系统可能不支持 maxclient 需求的连接数; Redis 会检查系统内核以确定可用的文件描述符数,如果可用的文件描述符数小于 maxclient + 32 ( Redis保留32个文件描述符供自己使用),则忽略 maxclient 的配置,使用最大可用文件描述符的数量
6.2 未命中key数(keyspace_misses)
每次 Redis 查找 key 时,只有两种可能的结果:key 存在或不存在;查找不存在的 key 会导致 keyspace_misses 计数递增 此指标的值非零意味着客户端正在尝试查找数据库中不存在的键,如果不使用 Redis 作为缓存,则 keyspace_misses 应该等于或接近0 ⚠️注意:对空键调用的任何阻塞操作( BLPOP、BRPOP和BRPOPLPUSH )也将计入 keyspace_misses
6.3 与主实例断开的时间( master_link_down_since_seconds )
仅当主实例与其副本实例之间的连接断开时,这个指标才会出现在INFO命令的结果中 理想情况下,这项指标永远不应出现,主实例与其副本实例应保持持续通信,以确保副本实例不会提供过时数据,同时如本文上面👆的 master_last_io_seconds_ago 部分提到过的,断开重连后副本实例发出的 PSYNC 命令很可能导致延迟显著增加
7. 监控方案
了解了有哪些值得关注的指标后,我们还需要一套监控方案以真正地实时监控我们的Redis实例,以下是一些开源的监控方案:
-
Redis Desktop Manager
一个免费的跨平台 GUI 工具,支持 Windows、Linux 和 macOS,提供了实时监控 Redis 实例的各种指标、执行命令和脚本等功能 -
Redis-Stat
一个终端 Redis 监控工具,可以轻松查看 Redis 实例的状态信息和性能指标。它支持颜色输出和曲线图显示,并提供了丰富的指标查询选项;在新的版本中也提供了web监控面板 -
RedisLive
这是一个基于 Web 的监控工具,界面美观、易用性高;且提供了多方面实时监控 Redis 实例的面板,包括连接数、内存使用情况、操作频率等等 -
Redis Commander
这是一个类似于 Redis Desktop Manager 的图形化管理工具,但它是在 Web 界面上运行的,可以通过浏览器进行访问。它也提供了实时监控 Redis 实例的很多核心指标,以及 CRUD 操作界面 -
基于 Promethues + Grafana 的 redis 监控方案
当然我们也可以使用更加具有自定义能力的 Promethues + Grafana 的 redis 监控方案,Github上有大量的开源的 Promethues** exporter 以及对应的示例 Grafana Dashboard ,基于这些方案,再针对业务添加一些指标和的 panel 就可以非常完善且贴合实际业务地监控redis了
以下就是一个不错的仓库:https://github.com/oliver006/redis_exporter, 以及其中预置的Grafana Dashboard截图:
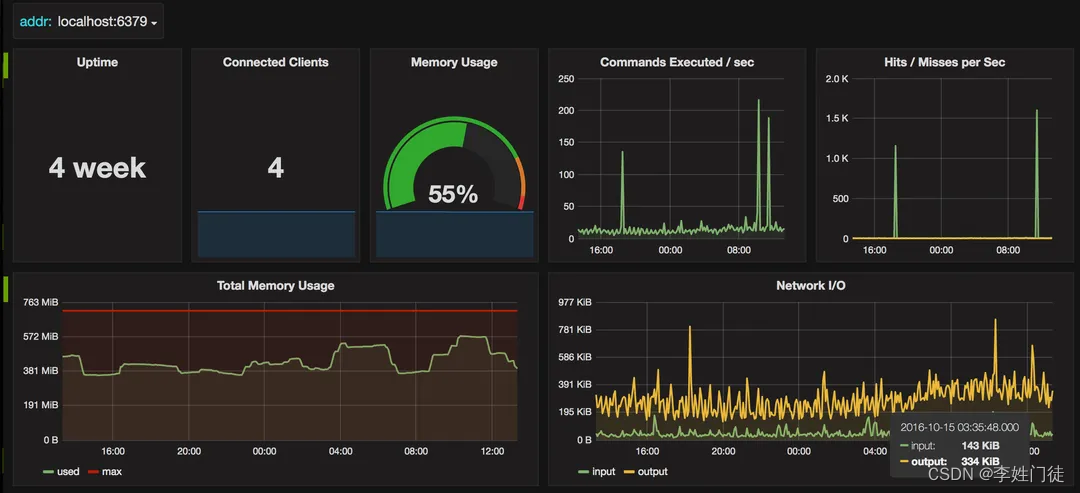
8. 疑问和思考
一些总结
本篇文章中,我们提到了一些值得关注的指标,基于它们可以很好地监控 Redis 实例;如果聚焦于Redis的基本使用与性能表现,监视以下核心指标就能够比较好地了解 Redis 的运行状况和性能:
- OPS(instantaneous_ops_per_sec)
- Latency(最大响应延迟和平均响应延迟)
- 内存碎片率(Memory fragmentation ratio)
- 被驱逐的 key 数(evicted_keys)
- 阻塞客户端数(blocked_clients)
9. 参考文档
- 暂无
![[AutoSar]BSW_Memory_Stack_003 NVM与APP的显式和隐式同步](https://img-blog.csdnimg.cn/direct/0830a813a7a44b30a17d4f68f399fbdf.png)