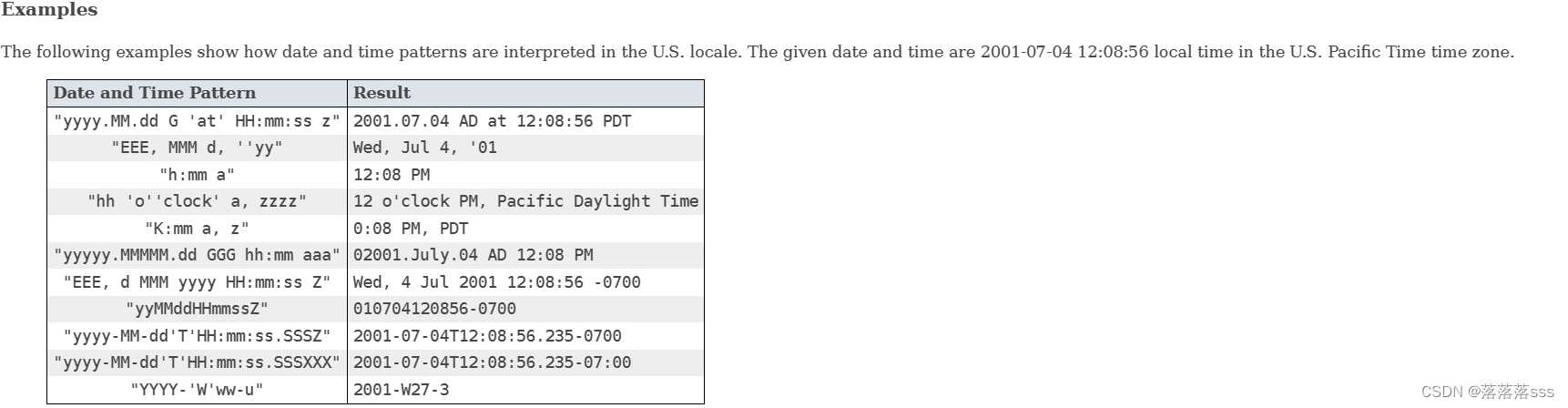
引言
在处理自动化数据解析时,格式错误是常见的问题。本文将展示如何使用OutputFixingParser来自动纠正这些错误,确保数据解析的顺利进行。
问题场景
在解析JSON数据时,如果格式不正确,Python的内建JSON解析器会抛出错误。例如,属性名称未用双引号包围时,会导致解析失败。这种格式错误可能导致数据解析过程中断,影响数据处理的自动化效率。
解决方案
OutputFixingParser是一个强大的工具,它可以自动检测并修复常见的格式错误,使得数据解析过程更加顺畅。通过使用OutputFixingParser,我们可以提高数据处理的自动化程度和准确性,从而节省时间和精力。
实战步骤
-
导入所需库和模块:
from langchain.output_parsers import PydanticOutputParser, OutputFixingParser from langchain.langchain_openaiimport ChatOpenAI from pydantic import BaseModel, Field from typing import List # 使用Pydantic创建数据格式 class Flower(BaseModel): name: str = Field(description="name of a flower") colors: List[str] = Field(description="the colors of this flower") -
定义查询和错误输出:
# 定义查询 flower_query = "Generate the characters for a random flower." # 定义格式错误的输出 misformatted = "{'name': '康乃馨', 'colors': ['粉红色','白色','红色','紫色','黄色']}" -
创建Pydantic解析器:
# 创建用于解析输出的Pydantic解析器 parser = PydanticOutputParser(pydantic_object=Flower) -
尝试解析错误输出:
# 尝试使用Pydantic解析器解析错误格式的输出 try: parser.parse(misformatted) except Exception as e: print(f"解析错误:{e}") -
使用
OutputFixingParser修复格式错误:# 设置OpenAI API密钥 import os os.environ["OPENAI_API_KEY"] = '你的OpenAI API Key' # 创建一个新的OutputFixingParser解析器 new_parser = OutputFixingParser.from_llm(parser=parser, llm=ChatOpenAI()) # 使用新的解析器解析错误格式的输出 result = new_parser.parse(misformatted) print(result) # 打印解析后的输出结果
工作原理
OutputFixingParser内部调用了原有的PydanticOutputParser。如果解析成功,则直接返回结果。如果解析失败,它会将错误输出和格式化指令传递给大型语言模型(LLM),请求LLM进行修复。这样,LLM不仅提供知识,还帮助分析和解决程序错误。通过这种方式,我们可以自动修复格式错误,使数据解析过程更加顺畅。
效果

结论
通过使用OutputFixingParser,我们可以有效地解决数据解析过程中的格式错误问题,提高数据处理的自动化程度和准确性。这种方法减少了手动干预的需求,使得开发和维护过程更加高效。通过本文提供的实战指南,读者可以轻松地应用这一强大工具,提升数据处理的效率和质量,从而更好地应对自动化数据解析的挑战。
请注意,上述代码中的API密钥需要替换为您自己的有效密钥。此外,文章中的示例代码是为了展示OutputFixingParser如何自动修复常见的格式错误。