传奇开心果系列博文
- 系列博文目录
- Python自动化办公库技术点案例示例系列
- 博文目录
- 前言
- 一、Python自动化操作Word介绍
- 二、使用python-docx示例代码
- 二、**使用`win32com`示例代码**
- 三、使用comtypes示例代码
- 四、使用docx-mailmerge示例代码
- 五、基本操作示例代码
- 六、高级操作示例代码
- 七、知识点归纳
系列博文目录
Python自动化办公库技术点案例示例系列
博文目录
前言

Python自动化操作Word通常指的是使用Python编程语言配合特定的第三方库来创建、编辑、格式化、转换以及批量处理Microsoft Word文档,无需人工介入或仅需少量人为干预。这种自动化方式极大地提高了工作效率,尤其适用于处理大量重复性工作、生成标准化报告、数据导出为文档格式等场景。Python通过python-docx、win32com等库提供了强大的Word自动化操作能力,能够满足从简单文档创建到复杂办公自动化流程的各种需求。开发者可以根据具体任务、文件格式要求、平台环境等因素选择合适的库进行自动化操作。
一、Python自动化操作Word介绍

以下是对Python自动化操作Word的主要介绍:
(一) 主要库及功能
-
python-docx:
- 功能:
python-docx是专为处理.docx文件格式设计的库,提供了丰富的API来创建、修改和分析Word文档。它不支持老式的.doc格式。 - 操作:可以创建新文档,添加和编辑文本、段落、表格、列表、图片、页面分隔符、样式等元素。可以读取现有文档的内容并进行结构化操作,如查找和替换文本、提取特定部分信息等。
- 优点:轻量级、跨平台,对
.docx格式支持全面且易于使用。
- 功能:
-
win32com或 comtypes:
- 功能:这两个库允许Python通过COM接口直接与Microsoft Office应用程序(包括Word)交互,这意味着它们可以操作任何Word版本支持的所有功能和文件格式(包括
.doc和.docx)。 - 操作:可以新建、打开、编辑、保存文档,应用复杂的样式和格式,执行宏,甚至控制Word的用户界面(如显示对话框)。此外,还能将文档转换为其他格式(如PDF)。
- 优点:功能极其强大,几乎可以实现与Word程序本身相同的功能。适用于需要处理旧版
.doc文件或进行高级格式化、交互式操作的场景。缺点是依赖于本地安装的Office套件,且主要在Windows平台上使用。
- 功能:这两个库允许Python通过COM接口直接与Microsoft Office应用程序(包括Word)交互,这意味着它们可以操作任何Word版本支持的所有功能和文件格式(包括
-
docx-mailmerge:
- 功能:专门用于执行Word的邮件合并功能,即根据模板和数据源批量生成个性化文档。
- 操作:准备一个包含占位符的Word模板,提供一个数据源(如CSV文件),然后使用
docx-mailmerge库自动填充模板并生成多个文档。 - 优点:简化了邮件合并过程,适用于制作批量信函、标签、报表等。
(二)基本操作
- 创建新文档并添加文本或内容。
- 修改已有文档。
(三)高级应用
- 批量处理:结合Python的数据处理能力(如
pandas库),可以批量读取数据、生成模板化的Word文档,或者批量修改多个Word文档的内容。 - 格式转换:利用
win32com将Word文档转换为PDF或其他格式。 - 关键词标记与替换:遍历文档内容,识别并高亮特定关键词,或者执行全文搜索与替换。
- 自动化报告生成:根据数据库查询结果、数据分析输出等动态生成带有图表、表格的详细报告。
(三) 注意事项
- 兼容性:确保目标系统上已安装相应库(如
python-docx)和必要的依赖(如本地Office套件对于win32com)。 - 错误处理:妥善处理文件不存在、权限问题、格式不兼容等异常情况。
- 性能:大规模操作时注意内存和CPU使用,可能需要分批处理或优化代码以避免资源耗尽。
二、使用python-docx示例代码

(一)实现功能的示例代码
当然,以下是使用python-docx库进行一些基本功能的示例代码,展示如何创建、修改和分析Word文档:
1. 创建新文档并添加内容
from docx import Document
from docx.shared import Inches
# 创建新文档
doc = Document()
# 添加段落
doc.add_paragraph('这是一个简单的段落。')
# 添加带样式的段落
styled_para = doc.add_paragraph('这是一个带样式的段落。', style='Heading 1')
# 添加列表项
list_items = ['苹果', '香蕉', '橙子']
for item in list_items:
doc.add_paragraph(item, style='List Bullet')
# 插入表格
table = doc.add_table(rows=2, cols=3)
for row in table.rows:
for cell in row.cells:
cell.text = '单元格内容'
# 插入图片
image_path = 'example_image.png'
doc.add_picture(image_path, width=Inches(1))
# 保存文档
doc.save('example.docx')
2. 修改已有文档
from docx import Document
# 打开已存在的文档
doc = Document('existing.docx')
# 替换文本
for paragraph in doc.paragraphs:
if '旧文本' in paragraph.text:
paragraph.text = paragraph.text.replace('旧文本', '新文本')
# 添加新段落到文档末尾
doc.add_paragraph('这是新增的一段文字。')
# 更新表格内容
table = doc.tables[0] # 假设要修改第一个表格
table.cell(0, 0).text = '修改后的单元格内容'
# 保存修改
doc.save('updated.docx')
3. 分析文档内容
from docx import Document
# 打开待分析的文档
doc = Document('analysis.docx')
# 获取文档中的所有文本内容
full_text = []
for paragraph in doc.paragraphs:
full_text.append(paragraph.text)
print('文档全文:\n', '\n'.join(full_text))
# 统计段落数量
paragraph_count = len(doc.paragraphs)
print(f"文档包含 {paragraph_count} 个段落。")
# 查找特定段落
target_text = '关键词'
for para in doc.paragraphs:
if target_text in para.text:
print(f"找到包含 '{target_text}' 的段落:")
print(para.text)
break
# 提取表格数据
table_data = []
for table in doc.tables:
for row in table.rows:
row_data = [cell.text for cell in row.cells]
table_data.append(row_data)
print("表格数据:\n", table_data)
以上代码示例展示了如何使用python-docx库创建新文档、修改已有文档以及对文档内容进行分析。实际应用中,您可以根据需求进一步定制这些操作,例如添加更复杂的样式、处理嵌套列表、遍历文档中的表格和图片等。
(二)主要操作示例代码

为了进一步说明python-docx库如何进行上述操作,以下是一些示例代码:
- 创建新文档并添加元素
from docx import Document
from docx.shared import Inches
# 创建新文档
doc = Document()
# 添加文本与段落
doc.add_paragraph('这是第一段文本。')
doc.add_paragraph('这是第二段文本,具有不同的样式。', style='Intense Quote')
# 添加列表
unordered_list = doc.add_paragraph('Unordered List:')
unordered_list.level = 0 # 设置为顶级列表
unordered_list.add_run('Item 1').bold = True
unordered_list.add_run('\tItem 1.1') # 使用制表符缩进子项
unordered_list.add_run('\nItem 2')
# 添加表格
table = doc.add_table(rows=2, cols=3)
table.style = 'Table Grid' # 应用预定义表格样式
for row in table.rows:
for cell in row.cells:
cell.text = f'Cell {row.index + 1}-{cell.column_index + 1}'
# 插入图片
image_path = 'example.jpg'
doc.add_picture(image_path, width=Inches(1), height=Inches(1))
# 添加页面分隔符
section = doc.sections[-1] # 获取当前最后一节
section.page_break_before = True # 在下一节前插入分页符
# 保存文档
doc.save('new_document.docx')
- 读取现有文档并进行结构化操作
from docx import Document
# 打开现有文档
doc = Document('existing_document.docx')
# 查找与替换文本
for paragraph in doc.paragraphs:
if 'old_text' in paragraph.text:
paragraph.text = paragraph.text.replace('old_text', 'new_text')
# 提取特定段落
target_style = 'Heading 1'
heading_paragraphs = [para for para in doc.paragraphs if para.style.name == target_style]
for para in heading_paragraphs:
print(f'找到标题段落: {para.text}')
# 提取表格数据
table_data = []
for table in doc.tables:
for row in table.rows:
row_data = [cell.text for cell in row.cells]
table_data.append(row_data)
print("表格数据:\n", table_data)
# 保存更新后的文档(如果需要)
# doc.save('updated_document.docx')
这些示例代码展示了如何使用python-docx库创建新文档,添加文本、段落、列表、表格、图片和页面分隔符,以及如何读取现有文档,进行查找与替换文本、提取特定样式段落和表格数据等结构化操作。您可以根据实际需求调整这些示例,以实现更复杂的文档自动化处理任务。
(三)优点特性示例代码

python-docx库的优点包括其轻量级、跨平台的特性,以及对.docx格式的全面支持和易用性。以下代码示例将进一步说明这些优点:
- 轻量级
python-docx库专注于.docx文件格式的处理,没有额外的依赖,安装方便,占用资源少。以下是如何快速安装并使用python-docx创建一个简单文档:
pip install python-docx
from docx import Document
# 创建新文档
doc = Document()
# 添加段落
doc.add_paragraph('这是一个使用python-docx创建的简单文档。')
# 保存文档
doc.save('simple_document.docx')
- 跨平台
python-docx基于纯Python编写,因此可以在支持Python的任何操作系统(如Windows、macOS、Linux)上运行,无需依赖特定于平台的软件。下面是在不同操作系统上创建同一文档的示例:
# 无论在哪个操作系统上运行,这段代码都能创建相同的Word文档
from docx import Document
doc = Document()
doc.add_paragraph('跨平台创建的文档内容')
doc.save('cross_platform_document.docx')
- 对.docx格式支持全面
python-docx不仅支持创建基本的文本内容,还能够处理复杂的文档结构,如样式、列表、表格、图片、页眉/页脚、页码、分节符等。以下是一个包含多种元素的示例:
from docx import Document
from docx.shared import Inches
doc = Document()
# 添加标题
doc.add_heading('文档标题', level=1)
# 添加样式化的段落
styled_para = doc.add_paragraph('强调文本', style='Emphasis')
# 添加有序列表
doc.add_paragraph('有序列表:')
for i in range(3):
doc.add_paragraph(f'{i+1}. 列表项', style='List Number')
# 插入表格
table = doc.add_table(rows=2, cols=3)
for row in table.rows:
for cell in row.cells:
cell.text = f'Cell {row.index + 1}-{cell.column_index + 1}'
# 插入图片
doc.add_picture('image.jpg', width=Inches(1), height=Inches(1))
# 添加页眉与页脚
header = doc.sections[0].header
footer = doc.sections[0].footer
header.add_paragraph('页眉内容')
footer.add_paragraph('页脚内容')
# 保存文档
doc.save('complex_document.docx')
- 易于使用
python-docx提供了直观且易于理解的API,使得开发者可以快速上手,通过简单的函数调用来操作Word文档。以下是如何使用几个基本方法创建文档的示例:
from docx import Document
doc = Document()
# 添加段落
doc.add_paragraph('第一段')
doc.add_paragraph('第二段')
# 添加换行符
doc.add_paragraph('').add_run('\n') # 创建空段落并添加换行符
# 添加超链接
hyperlink = 'https://www.example.com'
doc.add_paragraph('点击访问 ', style='Hyperlink')
doc.add_paragraph(hyperlink, style='Hyperlink', hyperlink_target=hyperlink)
# 保存文档
doc.save('easy_to_use_document.docx')
这些示例代码充分体现了python-docx库的轻量级、跨平台、对.docx格式支持全面以及易于使用的优点。开发者可以利用这些特点,高效地完成各种Word文档自动化处理任务。
二、使用win32com示例代码
(一)实现功能示例代码
win32com库是Python中用于与Microsoft Office应用程序(如Word)进行交互的工具,通过COM(Component Object Model)接口实现。下面是一些使用win32com库操作Word文档的示例代码:
- 安装与导入
首先确保已经安装了pywin32库(包含win32com模块),可通过以下命令安装:
pip install pywin32
然后在Python脚本中导入相关模块:
import win32com.client
- 创建新文档
# 启动Word应用程序
word = win32com.client.Dispatch('Word.Application')
# 创建一个新文档
doc = word.Documents.Add()
# 添加文本
doc.Range().InsertAfter('这是使用win32com创建的新文档内容')
# 保存文档
doc.SaveAs('new_doc.docx')
# 关闭文档(但保持Word应用程序运行)
doc.Close()
# 可选:关闭Word应用程序
word.Quit()
- 打开并编辑现有文档
# 启动Word应用程序
word = win32com.client.Dispatch('Word.Application')
# 打开已有文档
doc = word.Documents.Open('existing_doc.docx')
# 替换文本
search_text = '旧文本'
replace_text = '新文本'
find_obj = doc.Content.Find
find_obj.ClearFormatting()
find_obj.Text = search_text
while find_obj.Execute():
find_obj.Replacement.ClearFormatting()
find_obj.Replacement.Text = replace_text
find_obj.Execute(Replace=2) # 参数2表示替换
# 保存更改并关闭文档
doc.Save()
doc.Close()
# 可选:关闭Word应用程序
word.Quit()
- 批量替换文档中的文本
# 同上,启动Word应用程序和打开文档
# 定义一个字典,键为要查找的文本,值为对应的替换文本
replacements = {'旧文本1': '新文本1', '旧文本2': '新文本2'}
# 遍历字典,逐个执行替换操作
for search_text, replace_text in replacements.items():
find_obj = doc.Content.Find
find_obj.ClearFormatting()
find_obj.Text = search_text
while find_obj.Execute():
find_obj.Replacement.ClearFormatting()
find_obj.Replacement.Text = replace_text
find_obj.Execute(Replace=2)
# 保存更改并关闭文档
doc.Save()
doc.Close()
# 可选:关闭Word应用程序
word.Quit()
- 合并多个文档
# 启动Word应用程序
word = win32com.client.Dispatch('Word.Application')
# 定义要合并的文档路径列表
documents_to_merge = ['doc1.docx', 'doc2.docx', 'doc3.docx']
# 创建一个新的空白文档作为目标文档
merged_doc = word.Documents.Add()
# 将每个源文档的内容复制并粘贴到目标文档末尾
for doc_path in documents_to_merge:
source_doc = word.Documents.Open(doc_path)
source_content = source_doc.Content
merged_content = merged_doc.Content
merged_content.Collapse(win32com.client.constants.wdCollapseEnd)
merged_content.FormattedText = source_content.FormattedText
source_doc.Close()
# 保存合并后的文档
merged_doc.SaveAs('merged_docs.docx')
# 关闭目标文档并退出Word
merged_doc.Close()
word.Quit()
这些示例代码展示了如何使用win32com库与Word进行交互,包括创建新文档、打开并编辑现有文档、批量替换文本以及合并多个文档。由于win32com直接与Word应用程序通信,它可以操作Word支持的所有功能和文件格式(.doc 和 .docx),适用于需要高级功能或对旧版文件格式兼容性有要求的场景。请注意,使用win32com通常需要本地安装有Microsoft Office。
(二) 主要操作示例代码
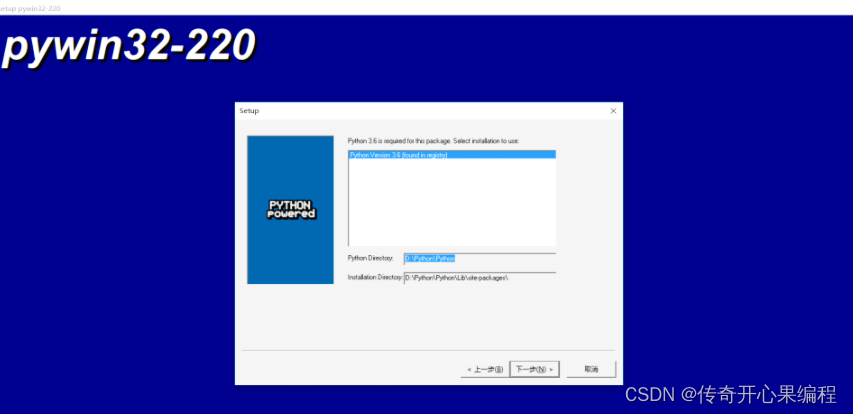
以下是一些使用win32com库操作Word的示例代码,涵盖了新建、打开、编辑、保存文档,应用样式和格式,执行宏,控制用户界面,以及转换文档格式等操作:
- 新建、打开、编辑、保存文档
import win32com.client
# 启动Word应用程序
word = win32com.client.Dispatch('Word.Application')
# 新建文档
doc = word.Documents.Add()
doc.Range().InsertAfter('这是新建文档的内容')
# 保存文档
doc.SaveAs('new_doc.docx')
# 打开已有文档
existing_doc = word.Documents.Open('existing_doc.docx')
existing_doc.Range().InsertAfter('\n这是追加到已有文档的内容')
# 保存并关闭文档
existing_doc.Save()
existing_doc.Close()
# 关闭Word应用程序
word.Quit()
- 应用复杂样式和格式
# 启动Word并打开文档(同上)
# 应用预定义样式
paragraph = doc.Paragraphs.Add()
paragraph.Range().Text = '这是一个标题'
paragraph.Style = 'Heading 1'
# 自定义格式化
run = paragraph.Range()
run.Bold = True
run.Font.ColorIndex = 2 # 蓝色
run.Font.Size = 14
# 保存并关闭文档(同上)
- 执行宏
# 启动Word并打开文档(同上)
# 执行宏(假设宏名为'MyMacro')
word.Run('MyMacro')
# 保存并关闭文档(同上)
- 控制用户界面(显示对话框)
# 启动Word并打开文档(同上)
# 显示“查找和替换”对话框
word.Dialogs(win32com.client.constants.wdDialogEditFind).Show()
# 保存并关闭文档(同上)
5.转换文档格式(如转为PDF)
# 启动Word并打开文档(同上)
# 将文档保存为PDF
doc.SaveAs('document.pdf', FileFormat=17) # 17对应PDF格式
# 保存并关闭文档(同上)
请注意,上述代码示例假设您已经熟悉win32com库的基本使用,并在本地计算机上安装了Microsoft Word。由于win32com直接与Word应用程序交互,因此能够实现对Word的深度控制,包括应用复杂的样式和格式、执行宏、控制用户界面,以及转换文档格式等操作。这些功能往往在需要完全模拟用户操作或利用Word内部功能进行复杂处理时非常有用。记得在完成操作后关闭Word应用程序以释放资源。
(三)优点特性示例代码
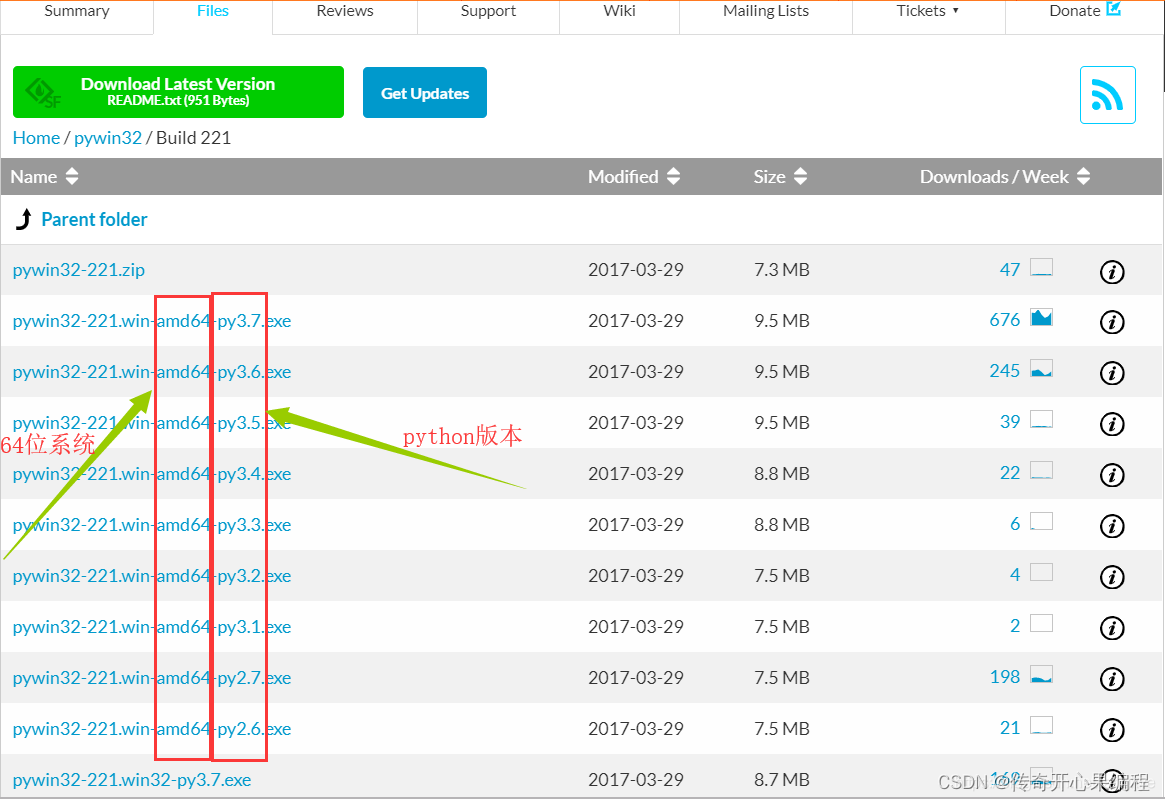
win32com库作为Python与Microsoft Office应用程序(如Word)进行交互的工具,具有以下优点:
-
功能强大:几乎可以实现与Word程序本身相同的功能,这意味着它可以处理Word支持的所有功能和文件格式(包括
.doc和.docx),以及进行高级格式化、交互式操作等。 -
处理旧版
.doc文件:对于需要处理较早版本Word文档(.doc格式)的情况,win32com库是一个理想的选择,因为它直接与Word应用程序通信,不受限于特定文件格式的支持。 -
高级格式化:能够应用复杂的样式和格式,包括但不限于字体、颜色、大小、段落样式、表格样式、列表样式、页面布局等。
-
交互式操作:能够执行宏、控制Word的用户界面(如显示对话框),实现与用户交互类似的操作。

然而,win32com库也存在一些限制:
-
依赖本地安装的Office套件:使用
win32com处理Word文档需要在本地计算机上安装完整的Microsoft Office套件。如果目标环境中没有Office,或者仅安装了Office的某些组件(如仅安装了Word,未安装Excel或PowerPoint),可能会导致功能受限或无法使用。 -
主要在Windows平台上使用:尽管
win32com理论上也可在其他支持COM的平台上使用,但其主要设计目的是与Windows操作系统上的Microsoft Office应用程序交互。在非Windows环境中(如Linux或macOS),使用win32com可能存在兼容性问题,或者需要额外的配置和工具(如 Wine)来模拟Windows环境。

以下是一些示例代码,展示了win32com库如何实现高级格式化和交互式操作:
- 高级格式化示例
import win32com.client
# 启动Word应用程序
word = win32com.client.Dispatch('Word.Application')
# 新建文档
doc = word.Documents.Add()
# 添加一段文本并应用复杂格式
paragraph = doc.Paragraphs.Add()
paragraph.Range().Text = '这是应用复杂格式的文本'
run = paragraph.Range()
# 字体属性
run.Font.Name = 'Arial'
run.Font.Size = 14
run.Font.Bold = True
run.Font.Italic = True
run.Font.ColorIndex = 3 # 红色
# 段落属性
paragraph.Format.SpaceAfter = 18 # 空行18磅
paragraph.Format.Alignment = 2 # 居中对齐
# 保存文档
doc.SaveAs('formatted_doc.docx')
# 关闭文档并退出Word
doc.Close()
word.Quit()
- 交互式操作示例:显示“查找和替换”对话框
import win32com.client
# 启动Word应用程序
word = win32com.client.Dispatch('Word.Application')
# 显示“查找和替换”对话框
word.Dialogs(win32com.client.constants.wdDialogEditFind).Show()
# 关闭Word
word.Quit()
这些示例代码展示了win32com库如何实现与Word程序相同的功能,包括高级格式化和交互式操作。然而,请注意其对本地安装的Office套件的依赖,以及主要在Windows平台上使用的特性。在选择使用win32com时,应确保目标环境满足这些条件。如果需要跨平台或无Office环境下的解决方案,可以考虑使用如python-docx这样的库。
三、使用comtypes示例代码
(一)实现功能示例代码
comtypes库同样允许Python通过COM接口与Microsoft Office应用程序(如Word)进行交互,从而实现对Word文档的操作。以下是一些使用comtypes库操作Word文档的示例代码:
- 安装与导入
首先确保已经安装了comtypes库,可通过以下命令安装:
pip install comtypes
然后在Python脚本中导入相关模块:
import comtypes.client
- 创建新文档
# 创建Word应用程序实例
word = comtypes.client.CreateObject('Word.Application')
# 设置是否可见
word.Visible = True # 若要在后台运行,设置为False
# 创建一个新文档
doc = word.Documents.Add()
# 添加文本
doc.Range().InsertAfter('这是使用comtypes创建的新文档内容')
# 保存文档
doc.SaveAs('new_doc.docx')
# 关闭文档(但保持Word应用程序运行)
doc.Close()
# 可选:关闭Word应用程序
word.Quit()
- 打开并编辑现有文档
# 启动Word应用程序(同上)
# 打开已有文档
doc = word.Documents.Open('existing_doc.docx')
# 替换文本
search_text = '旧文本'
replace_text = '新文本'
find_obj = doc.Range().Find
find_obj.ClearFormatting()
find_obj.Text = search_text
while find_obj.Execute():
find_obj.Replacement.ClearFormatting()
find_obj.Replacement.Text = replace_text
find_obj.Execute(Replace=2) # 参数2表示替换
# 保存更改并关闭文档
doc.Save()
doc.Close()
# 可选:关闭Word应用程序
word.Quit()
- 批量替换文档中的文本
# 同上,启动Word应用程序和打开文档
# 定义一个字典,键为要查找的文本,值为对应的替换文本
replacements = {'旧文本1': '新文本1', '旧文本2': '新文本2'}
# 遍历字典,逐个执行替换操作
for search_text, replace_text in replacements.items():
find_obj = doc.Range().Find
find_obj.ClearFormatting()
find_obj.Text = search_text
while find_obj.Execute():
find_obj.Replacement.ClearFormatting()
find_obj.Replacement.Text = replace_text
find_obj.Execute(Replace=2)
# 保存更改并关闭文档
doc.Save()
doc.Close()
# 可选:关闭Word应用程序
word.Quit()
这些示例代码展示了如何使用comtypes库与Word进行交互,包括创建新文档、打开并编辑现有文档、批量替换文本等操作。与win32com类似,comtypes通过COM接口直接与Word应用程序通信,可以操作Word支持的所有功能和文件格式(.doc 和 .docx),适用于需要高级功能或对旧版文件格式兼容性有要求的场景。同样需要注意的是,使用comtypes通常需要本地安装有Microsoft Office。
(二) 主要操作示例代码
以下是一些使用comtypes库操作Word的示例代码,涵盖了新建、打开、编辑、保存文档,应用样式和格式,执行宏,控制用户界面,以及转换文档格式等操作:
- 新建、打开、编辑、保存文档
import comtypes.client
# 创建Word应用程序实例
word = comtypes.client.CreateObject('Word.Application')
# 设置是否可见
word.Visible = True # 若要在后台运行,设置为False
# 新建文档
doc = word.Documents.Add()
doc.Range().InsertAfter('这是新建文档的内容')
# 保存文档
doc.SaveAs('new_doc.docx')
# 打开已有文档
existing_doc = word.Documents.Open('existing_doc.docx')
existing_doc.Range().InsertAfter('\n这是追加到已有文档的内容')
# 保存并关闭文档
existing_doc.Save()
existing_doc.Close()
# 关闭Word应用程序
word.Quit()
- 应用复杂样式和格式
# 启动Word并打开文档(同上)
# 应用预定义样式
paragraph = doc.Paragraphs.Add()
paragraph.Range().Text = '这是一个标题'
paragraph.Range().Style = 'Heading 1'
# 自定义格式化
run = paragraph.Range()
run.Font.Bold = True
run.Font.Color = RGB(0, 0, 255) # 蓝色
run.Font.Size = 14
# 保存并关闭文档(同上)
- 执行宏
# 启动Word并打开文档(同上)
# 执行宏(假设宏名为'MyMacro')
word.Run('MyMacro')
# 保存并关闭文档(同上)
- 控制用户界面(显示对话框)
# 启动Word并打开文档(同上)
# 显示“查找和替换”对话框
word.Dialogs(comtypes.gen.Word.WdWordDialog.wdDialogEditFind).Show()
# 保存并关闭文档(同上)
- 转换文档格式(如转为PDF)
# 启动Word并打开文档(同上)
# 将文档保存为PDF
doc.SaveAs('document.pdf', FileFormat=17) # 17对应PDF格式
# 保存并关闭文档(同上)
请注意,上述代码示例假设您已经熟悉comtypes库的基本使用,并在本地计算机上安装了Microsoft Word。由于comtypes直接与Word应用程序交互,因此能够实现对Word的深度控制,包括应用复杂的样式和格式、执行宏、控制用户界面,以及转换文档格式等操作。这些功能往往在需要完全模拟用户操作或利用Word内部功能进行复杂处理时非常有用。记得在完成操作后关闭Word应用程序以释放资源。
(三)优点特性示例代码
comtypes库作为Python与Microsoft Office应用程序(如Word)进行交互的工具,具有以下优点:
-
功能强大:几乎可以实现与Word程序本身相同的功能,这意味着它可以处理Word支持的所有功能和文件格式(包括
.doc和.docx),以及进行高级格式化、交互式操作等。 -
**处理旧版
.doc文件 **:对于需要处理较早版本Word文档(.doc格式)的情况,comtypes库是一个理想的选择,因为它直接与Word应用程序通信,不受限于特定文件格式的支持。 -
高级格式化:能够应用复杂的样式和格式,包括但不限于字体、颜色、大小、段落样式、表格样式、列表样式、页面布局等。
-
交互式操作:能够执行宏、控制Word的用户界面(如显示对话框),实现与用户交互类似的操作。
然而,comtypes库也存在一些限制:
-
依赖本地安装的Office套件:使用
comtypes处理Word文档需要在本地计算机上安装完整的Microsoft Office套件。如果目标环境中没有Office,或者仅安装了Office的某些组件(如仅安装了Word,未安装Excel或PowerPoint),可能会导致功能受限或无法使用。 -
主要在Windows平台上使用:尽管
comtypes理论上也可在其他支持COM的平台上使用,但其主要设计目的是与Windows操作系统上的Microsoft Office应用程序交互。在非Windows环境中(如Linux或macOS),使用comtypes可能存在兼容性问题,或者需要额外的配置和工具(如 Wine)来模拟Windows环境。

以下是一些示例代码,展示了comtypes库如何实现高级格式化和交互式操作:
- 高级格式化示例
import comtypes.client
# 创建Word应用程序实例
word = comtypes.client.CreateObject('Word.Application')
# 新建文档
doc = word.Documents.Add()
# 添加一段文本并应用复杂格式
paragraph = doc.Paragraphs.Add()
paragraph.Range().Text = '这是应用复杂格式的文本'
run = paragraph.Range()
# 字体属性
run.Font.Name = 'Arial'
run.Font.Size = 14
run.Font.Bold = True
run.Font.Italic = True
run.Font.Color = RGB(255, 0, 0) # 红色
# 段落属性
paragraph.Range.ParagraphFormat.SpaceAfter = 18 # 空行18磅
paragraph.Range.ParagraphFormat.Alignment = 2 # 居中对齐
# 保存文档
doc.SaveAs('formatted_doc.docx')
# 关闭文档并退出Word
doc.Close()
word.Quit()
- 交互式操作示例:显示“查找和替换”对话框
import comtypes.client
# 创建Word应用程序实例
word = comtypes.client.CreateObject('Word.Application')
# 显示“查找和替换”对话框
word.Dialogs(comtypes.gen.Word.WdWordDialog.wdDialogEditFind).Show()
# 关闭Word
word.Quit()
这些示例代码展示了comtypes库如何实现与Word程序相同的功能,包括高级格式化和交互式操作。然而,请注意其对本地安装的Office套件的依赖,以及主要在Windows平台上使用的特性。在选择使用comtypes时,应确保目标环境满足这些条件。如果需要跨平台或无Office环境下的解决方案,可以考虑使用如python-docx这样的库。
四、使用docx-mailmerge示例代码
(一)实现功能示例代码
在Python中,可以使用第三方库如docx-mailmerge来实现Word邮件合并的功能。以下是一个使用docx-mailmerge库进行邮件合并的示例代码:
import pandas as pd
from mailmerge import MailMerge
# 1. 加载数据源(假设为CSV文件)
data = pd.read_csv('data.csv')
# 2. 准备模板
template_file = 'template.docx'
# 3. 初始化MailMerge对象
doc = MailMerge(template_file)
# 4. 定义数据字段映射
field_mapping = {
'Name': '姓名',
'Email': '邮箱',
'Message': '个性化信息'
} # 假设模板中使用的字段与数据源列名不完全一致,此处进行映射
# 5. 遍历数据源,逐条进行合并
for _, row in data.iterrows():
# 将数据行转换为字典,便于合并
merge_data = {field_mapping[k]: v for k, v in row.to_dict().items() if k in field_mapping}
# 执行邮件合并
doc.merge(**merge_data)
# 生成并保存单个个性化文档
output_filename = f'output_{row["ID"]}.docx' # 使用ID或其他唯一标识作为文件名
doc.write(output_filename)
# 清空MailMerge对象,准备合并下一条数据
doc.clear_merge_fields()
# 或者,如果需要一次性生成所有文档到一个大的Word文档中,并用分页符隔开
# (假设`list_temp`已经包含了所有要合并的数据字典)
# with MailMerge(template_file) as doc:
# doc.merge_templates(list_temp, separator='page_break')
# doc.write('all_outputs.docx')
# 6. (可选)发送合并后的文档作为电子邮件附件
# 使用例如smtplib和email库来构建并发送邮件
# ...
在这个示例中:
- 首先,我们使用
pandas库加载数据源(这里假设为CSV文件)。 - 然后,指定Word模板文件的位置。
- 初始化一个
MailMerge对象,传入模板文件路径。 - 定义数据字段与模板中占位符之间的映射关系(如果两者名称不直接对应)。
- 遍历数据源的每一行,将数据转化为字典形式,并通过
doc.merge()方法将数据合并到模板中。 - 合并后,使用
doc.write()方法将生成的个性化文档保存到指定路径,文件名可以包含来自数据源的唯一标识符(如ID)。 - 如果需要生成所有文档到一个大的Word文档中,并用分页符隔开,可以使用
merge_templates()方法,传入数据字典列表以及分隔符。
请注意,实际使用时需要确保docx-mailmerge库已正确安装,可以通过pip install docx-mailmerge命令进行安装。同时,根据实际需求调整数据源类型、模板文件路径、字段映射、输出文件命名规则等细节。
(二)主要操作示例代码

为了准备一个包含占位符的Word模板,使用docx-mailmerge库自动填充模板并生成多个文档,您可以按照以下步骤操作:
步骤 1:创建Word模板
-
打开Microsoft Word,新建一个空白文档。
-
在文档中添加您希望个性化的内容,如标题、正文、表格等。对于需要动态填充的部分,插入邮件合并域(占位符)。操作方法如下:
- 点击顶部菜单栏中的“邮件”选项卡。
- 在“编写和插入字段”区域,点击“插入合并域”。
- 从弹出的列表中选择相应的字段名(如“姓名”、“地址”等),或者自定义字段名。Word会自动插入带有大括号
{}包裹的占位符,如{Name}、{Address}。
示例模板内容可能如下:
尊敬的 {Name}, 感谢您对我们的支持!以下是您的订单详情: 订单编号:{OrderID} 订单日期:{OrderDate} 商品名称:{ProductName} 数量:{Quantity} 单价:{UnitPrice} 总价:{TotalPrice} 如有任何问题,请随时联系我们的客服团队。 最诚挚的问候, [Your Company Name]
步骤 2:准备数据源(CSV文件)
-
使用Excel或其他支持CSV格式的软件创建一个CSV文件,包含与模板中占位符对应的列名和数据。
示例CSV数据:
Name,OrderID,OrderDate,ProductName,Quantity,UnitPrice,TotalPrice John Doe,12345,2024-03-¼,Product A,1,29.99,29.99 Jane Smith,67890,2024-03-½,Product B,3,19.99,59.97确保数据源的列名与Word模板中的合并域名称完全一致。
步骤 3:使用docx-mailmerge库进行邮件合并
-
安装
docx-mailmerge库(如果尚未安装):pip install docx-mailmerge -
编写Python脚本,使用
docx-mailmerge库读取模板文件、数据源,并生成多个文档。下面是一个示例脚本:import csv from mailmerge import MailMerge # 模板文件路径 template_path = "template.docx" # 数据源(CSV文件)路径 data_source_path = "data.csv" # 初始化MailMerge对象 mail_merge = MailMerge(template_path) # 读取CSV数据 with open(data_source_path, newline='') as csvfile: reader = csv.DictReader(csvfile) for row in reader: # 合并数据到模板 mail_merge.merge(row) # 生成并保存个性化文档 output_file = f"{row['Name'].replace(' ', '_')}_order_details.docx" mail_merge.write(output_file) # 清除已合并的数据,准备合并下一行 mail_merge.clear_merge_fields() print("邮件合并完成,生成的文档已保存。")这个脚本首先读取CSV数据源,然后遍历每一行,将行数据作为字典传递给
mail_merge.merge()方法,填充模板。生成的个性化文档以客户的姓名(替换空格为下划线)加上“_order_details.docx”作为文件名保存。
执行上述Python脚本后,docx-mailmerge会根据提供的数据源自动填充Word模板,并为每个数据记录生成一个单独的文档。这些文档将保存在脚本运行的目录下,文件名如John_Doe_order_details.docx和Jane_Smith_order_details.docx。
至此,您已经成功使用docx-mailmerge库完成了基于Word模板和CSV数据源的邮件合并任务,生成了多个个性化的文档。

(三)优点特性示例代码
docx-mailmerge库具有以下显著优点,使得邮件合并过程得以简化,特别适用于制作批量信函、标签、报表等场景:
-
简洁易用:
- 基于命令行界面,提供清晰的参数选项,无需复杂的编程知识即可快速上手。
- Python API设计直观,易于理解,减少了学习成本。
-
跨平台兼容:
- 支持Windows、macOS和Linux操作系统,能够在不同环境下无缝工作。
-
多种数据源支持:
- 可以从CSV或JSON文件导入数据,便于与各种数据库或电子表格软件集成。
- 支持通过管道传递数据,方便与其他命令行工具结合使用,进行数据预处理或实时生成。
-
模板自定义灵活:
- 在Word文档中直接使用
{}包围变量名作为占位符,无需深入理解复杂标记语言或特定模板语法。 - 允许用户使用Word的全部功能设计模板,包括样式、表格、图片、图表等,保持专业文档的高质量外观。
- 在Word文档中直接使用
-
批量化处理高效:
- 一次性操作即可根据数据源生成大量定制化文档,极大地提高了工作效率。
- 对大数据集处理性能良好,避免了手动重复劳动可能导致的错误和耗时。
-
无需依赖Microsoft Word应用程序:
docx-mailmerge作为一个独立库,能够直接解析和操作.docx文件,无需在目标机器上安装Word软件。- 这意味着可以在服务器、无GUI环境或非Windows平台上高效生成Word文档。
以下是一个使用docx-mailmerge库进行邮件合并的简单示例代码:
import csv
from mailmerge import MailMerge
# 模板文件路径
template_path = "letter_template.docx"
# 数据源(CSV文件)路径
data_source_path = "recipients.csv"
# 初始化MailMerge对象
mail_merge = MailMerge(template_path)
# 读取CSV数据
with open(data_source_path, newline='') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
# 合并数据到模板
mail_merge.merge(**row)
# 生成并保存个性化文档
output_file = f"{row['Name'].replace(' ', '_')}_letter.docx"
mail_merge.write(output_file)
# 清除已合并的数据,准备合并下一行
mail_merge.clear_merge_fields()
print("邮件合并完成,生成的文档已保存。")
在这个示例中:
- 首先导入所需的库,并指定模板文件和数据源(CSV文件)的路径。
- 创建一个
MailMerge对象,加载Word模板。 - 使用
csv.DictReader读取CSV数据行作为字典。 - 对于每一条数据记录,调用
mail_merge.merge(**row)方法,将字典中的键值对对应地填充到模板的占位符中。 - 根据数据中的
Name字段生成个性化文档名,并使用mail_merge.write(output_file)保存生成的文档。 - 清除已合并的数据,以便循环处理下一条记录。
- 最后,输出消息告知用户邮件合并过程已完成。
这段代码展示了如何轻松地使用docx-mailmerge库批量生成个性化信函。同样的原理可以应用于制作标签、报表等其他应用场景,只需调整模板和数据源以适应具体需求即可。
五、基本操作示例代码

要展示Python操作Word文档的基本操作,这里分别给出创建新文档并添加文本或内容以及修改已有文档的示例代码。我们将使用python-docx库来实现这些功能。
- 创建新文档并添加文本或内容:
from docx import Document
# 创建一个新文档
doc = Document()
# 添加一个空段落
doc.add_paragraph('这是文档中的第一段文字。')
# 添加带有样式的段落
styled_paragraph = doc.add_paragraph('这是带样式的段落。')
styled_paragraph.style = 'Heading 1'
# 添加列表项
unordered_list = doc.add_paragraph('无序列表:')
unordered_list.style = 'List Bullet'
unordered_list.add_run('项目一').italic = True
unordered_list.add_run('\n')
unordered_list.add_run('项目二')
# 添加表格
table = doc.add_table(rows=2, cols=3)
for row in table.rows:
for cell in row.cells:
cell.text = '单元格内容'
# 添加图片
image_path = 'path_to_your_image.png'
doc.add_picture(image_path, width=Inches(1.5))
# 保存新文档
doc.save('new_document.docx')
在这个示例中:
- 使用
Document()创建了一个新的Word文档。 - 使用
add_paragraph()方法添加了普通文本段落和带有样式的段落。 - 创建了一个无序列表,并使用
add_run()方法添加了带有样式的列表项。 - 添加了一个2行3列的表格,并设置每个单元格的文本内容。
- 插入了一张图片到文档中,指定图片路径、宽度(单位为英寸)。
- 最后,使用
save()方法保存新创建的文档。
- 修改已有文档:
from docx import Document
# 打开已有的Word文档
doc = Document('existing_document.docx')
# 获取文档中的第一个段落
first_paragraph = doc.paragraphs[0]
# 修改段落文本
first_paragraph.text = '这是修改后的第一段文字。'
# 更改段落样式
first_paragraph.style = 'Heading 1'
# 在文档末尾添加新段落
doc.add_paragraph('这是新添加的段落。')
# 查找并替换文本
doc.replace('旧文本', '新文本')
# 保存修改后的文档(会覆盖原有文件)
doc.save('existing_document.docx')
在这个示例中:
- 使用
Document()打开一个已存在的Word文档。 - 获取文档中的首个段落,通过其
text属性修改其内容。 - 调整该段落的样式。
- 在文档末尾新增一个段落。
- 使用
replace()方法在整个文档中查找并替换特定文本。 - 最后,保存修改后的文档,原文件会被更新。
以上代码展示了使用python-docx库进行Word文档创建、添加内容以及修改已有文档的基本操作。实际应用中,可以根据需要进一步扩展这些基本操作,如处理表格、列表、页眉页脚、样式等更复杂的文档元素。
六、高级操作示例代码

(一)批量处理示例代码
批量处理Word文档结合Python的数据处理能力(如使用pandas库)可以极大地提高工作效率,特别是在处理大量数据时,用于生成模板化的Word报告或批量修改多个Word文档的内容。下面给出两个示例场景及相应的代码片段:
场景一:批量生成模板化Word文档
假设您有一份包含多个记录(如员工信息)的CSV或Excel文件,需要根据这些数据生成一系列结构相同但具体内容各异的Word文档。您可以使用pandas加载数据,然后循环遍历每一行数据,根据数据填充预设的Word模板。
import pandas as pd
from docx import Document
from docx.shared import Inches
# 1. 读取数据
data = pd.read_csv('employee_data.csv') # 或 pd.read_excel('employee_data.xlsx')
# 2. 定义模板填充函数
def fill_template(employee_data, template_path, output_path):
template_doc = Document(template_path)
for para in template_doc.paragraphs:
if '{Name}' in para.text:
para.text = para.text.replace('{Name}', employee_data['Name'])
# 类似地处理其他占位符(如{Position}, {Department}等)
# 添加图片(如果数据中有图片路径)
if 'PhotoPath' in employee_data and employee_data['PhotoPath']:
template_doc.add_picture(employee_data['PhotoPath'], width=Inches(1))
# 保存生成的文档
template_doc.save(output_path)
# 3. 循环生成文档
for i, row in data.iterrows():
output_file = f'employee_{i+1}.docx'
fill_template(row.to_dict(), 'template.docx', output_file)
在这个示例中:
- 使用
pd.read_csv()或pd.read_excel()读取数据源。 - 定义一个
fill_template()函数,接受一行数据字典、模板文件路径和输出文件路径作为参数。 - 在函数内部,打开模板文档,遍历所有段落,寻找并替换预设的占位符(如
{Name})。 - 如果数据包含图片路径,根据路径添加图片到文档。
- 将填充好的模板保存为新的Word文档。
场景二:批量修改多个Word文档的内容
如果需要批量修改多个Word文档中的特定文本,可以结合pandas处理文件列表,并使用python-docx对每个文档进行内容替换。
import os
import pandas as pd
from docx import Document
# 1. 构建文件列表
folder_path = 'documents_folder'
file_list = [os.path.join(folder_path, f) for f in os.listdir(folder_path) if f.endswith('.docx')]
# 2. 定义替换函数
def replace_in_document(file_path, old_text, new_text):
doc = Document(file_path)
for para in doc.paragraphs:
para.text = para.text.replace(old_text, new_text)
doc.save(file_path)
# 3. 定义需要替换的文本对(可以存储在CSV文件中并用pandas加载)
replacement_data = pd.read_csv('replacements.csv')
replacements = [(old, new) for old, new in zip(replacement_data['OldText'], replacement_data['NewText'])]
# 4. 遍历文件列表,对每个文件执行替换操作
for file_path in file_list:
for old_text, new_text in replacements:
replace_in_document(file_path, old_text, new_text)
在这个示例中:
- 列出指定文件夹中所有
.docx文件的完整路径。 - 定义一个
replace_in_document()函数,接受文件路径、旧文本和新文本作为参数,打开文档并替换所有段落中的旧文本。 - 使用
pd.read_csv()读取包含替换规则的CSV文件,构建一个由(old_text, new_text)元组组成的列表。 - 遍历文件列表,对每个文件依次执行所有替换规则。
以上代码展示了如何利用pandas与python-docx库结合,实现批量生成模板化Word文档或批量修改多个Word文档内容的场景。实际应用中,请根据具体需求调整代码逻辑和数据处理方式。
(二)格式转换示例代码

利用win32com库可以方便地将Word文档转换为PDF或其他格式,因为它提供了与Microsoft Office应用程序(包括Word)的COM接口交互的能力。以下是一个示例代码,展示如何使用win32com.client模块将单个或批量Word文档转换为PDF:
- 单个Word文档转换为PDF
import os
import win32com.client
def word_to_pdf(word_file_path, pdf_output_path):
"""
将指定的Word文档转换为PDF。
参数:
word_file_path (str): Word文档的完整路径。
pdf_output_path (str): 输出PDF文件的完整路径。
"""
# 启动Word应用程序(若已启动则获取现有实例)
word = win32com.client.Dispatch('Word.Application')
try:
# 打开Word文档
doc = word.Documents.Open(word_file_path)
# 设置转换选项(此处仅做示例,可能需要根据实际需求调整)
conversion_options = win32com.client.constants.wdExportFormatPDF
export_flags = win32com.client.constants.wdExportOptimizeForPrint \
| win32com.client.constants.wdExportAllDocument \
| win32com.client.constants.wdExportCurrentPage \
| win32com.client.constants.wdExportFormFields \
| win32com.client.constants.wdExportBookmarks \
| win32com.client.constants.wdExportDocumentWithMarkup
# 执行转换
doc.ExportAsFixedFormat(pdf_output_path, conversion_options, False, export_flags)
finally:
# 关闭文档并退出Word(确保释放资源)
doc.Close(False)
word.Quit()
# 示例使用
word_file = r'C:\path\to\input.docx'
pdf_output = r'C:\path\to\output.pdf'
word_to_pdf(word_file, pdf_output)
- 批量转换Word文档为PDF
import os
import glob
import win32com.client
def batch_word_to_pdf(input_folder, output_folder, file_extension='docx'):
"""
批量将指定文件夹中的Word文档转换为PDF。
参数:
input_folder (str): 包含Word文档的文件夹路径。
output_folder (str): 存放转换后PDF文件的目标文件夹路径。
file_extension (str, optional): 要处理的Word文档扩展名,默认为'docx'。
"""
# 确保输出文件夹存在
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 启动Word应用程序(若已启动则获取现有实例)
word = win32com.client.Dispatch('Word.Application')
try:
# 遍历输入文件夹中的Word文档
for word_file in glob.glob(os.path.join(input_folder, f'*.{file_extension}')):
base_name = os.path.splitext(os.path.basename(word_file))[0]
pdf_output = os.path.join(output_folder, f'{base_name}.pdf')
# 调用单个转换函数
word_to_pdf(word_file, pdf_output)
finally:
# 关闭所有文档并退出Word(确保释放资源)
word.Documents.Close(NoPrompt=True)
word.Quit()
# 示例使用
input_dir = r'C:\path\to\input_folder'
output_dir = r'C:\path\to\output_folder'
batch_word_to_pdf(input_dir, output_dir)
以上代码定义了一个名为word_to_pdf的函数,用于将单个Word文档转换为PDF。同时,还有一个batch_word_to_pdf函数,用于遍历指定文件夹中的所有Word文档,并调用word_to_pdf进行批量转换。请注意,这些代码示例假定您的环境中已经安装了Microsoft Word,并且win32com库能够成功与其交互。实际使用时,请根据实际文件路径进行相应调整。
(三) 关键词标记与替换示例代码

使用Python操作Word文档时,可以实现关键词标记与替换功能。以下分别给出两个示例:一个用于遍历文档内容并高亮特定关键词,另一个用于执行全文搜索与替换。
- 关键词高亮示例
from docx import Document
from docx.oxml.ns import qn
from docx.oxml import OxmlElement
from docx.shared import RGBColor
def highlight_keyword(document_path, keyword, highlight_color=RGBColor(255, 255, 0)): # 黄色默认
"""
遍历Word文档内容,将指定关键词高亮显示。
参数:
document_path (str): Word文档的完整路径。
keyword (str): 要高亮显示的关键词。
highlight_color (docx.shared.RGBColor, optional): 高亮颜色,默认为黄色。
"""
doc = Document(document_path)
for para in doc.paragraphs:
if keyword in para.text:
run = para.runs
for i in range(len(run)):
if keyword in run[i].text:
text = run[i].text.split(keyword)
for j in range(len(text)-1):
run[i].text = text[j]
run[i].add_break()
new_run = para.add_run(keyword)
new_run.font.highlight_color = highlight_color
run[i].text = text[-1]
doc.save(document_path)
# 示例使用
document_path = r'C:\path\to\your_document.docx'
keyword = 'example'
highlight_keyword(document_path, keyword)
这段代码定义了一个名为highlight_keyword的函数,它接收Word文档路径、关键词以及高亮颜色作为参数。函数首先打开文档,遍历每个段落。对于包含关键词的段落,它将段落拆分成多个部分,将关键词部分以新的运行(run)添加回段落,并设置该运行的高亮颜色。最后,保存修改后的文档。
- 全文搜索与替换示例
from docx import Document
def search_and_replace(document_path, search_text, replace_text):
"""
在Word文档中执行全文搜索与替换。
参数:
document_path (str): Word文档的完整路径。
search_text (str): 要搜索的文本。
replace_text (str): 替换文本。
"""
doc = Document(document_path)
for para in doc.paragraphs:
para.text = para.text.replace(search_text, replace_text)
for table in doc.tables:
for row in table.rows:
for cell in row.cells:
for para in cell.paragraphs:
para.text = para.text.replace(search_text, replace_text)
doc.save(document_path)
# 示例使用
document_path = r'C:\path\to\your_document.docx'
search_text = 'old_text'
replace_text = 'new_text'
search_and_replace(document_path, search_text, replace_text)
这个示例中的search_and_replace函数接受Word文档路径、要搜索的文本和替换文本作为参数。函数首先打开文档,遍历所有段落,直接在段落文本上执行字符串替换。接着,处理文档中的表格,递归遍历表格的行、单元格和单元格内的段落,同样进行文本替换。最后,保存修改后的文档。
这两个示例分别展示了如何使用Python对Word文档进行关键词高亮和全文搜索与替换。实际使用时,请根据具体需求调整代码逻辑。请注意,这些操作会直接修改原始文档,如需保留备份,请提前复制或另存文档。
(四)自动化报告生成示例代码

为了提供一个更具体的Python示例,假设我们使用SQLAlchemy进行数据库查询,Pandas进行数据处理,Matplotlib和Seaborn生成图表,以及Jinja2模板引擎来编排报告。以下是整个流程的示例代码:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sqlalchemy import create_engine
from jinja2 import Environment, FileSystemLoader
# 1. 数据库连接与查询
DB_URL = 'sqlite:///your_database.db' # 替换为你的数据库连接字符串
engine = create_engine(DB_URL)
query = """
SELECT column1, column2, ...
FROM your_table
WHERE condition
GROUP BY ...
ORDER BY ...
"""
df = pd.read_sql(query, con=engine)
# 2. 数据分析与预处理
# 对df进行数据清洗、转换、聚合等操作
# ...
# 3. 可视化图表生成
plt.style.use('seaborn-whitegrid')
bar_chart = sns.countplot(x='column_name', data=df)
bar_chart.figure.savefig('bar_chart.png')
line_chart = sns.lineplot(x='date_column', y='metric_column', data=df)
line_chart.figure.savefig('line_chart.png')
# 4. 使用Jinja2模板生成报告
template_dir = 'report_templates'
env = Environment(loader=FileSystemLoader(template_dir))
template = env.get_template('report_template.html')
output_html = template.render(
bar_chart_img='bar_chart.png',
line_chart_img='line_chart.png',
table=df.to_html(index=False, classes='table table-striped'),
summary_text='Your summary text here...',
additional_info='Any other relevant information'
)
# 5. 输出或保存报告
with open('generated_report.html', 'w') as f:
f.write(output_html)
在这个示例中:
-
首先,我们使用SQLAlchemy通过指定的数据库连接字符串连接到数据库,并执行SQL查询语句,将结果读取到Pandas DataFrame
df中。 -
接着,对
df进行所需的数据清洗、转换、聚合等分析操作(这部分代码未展示,根据具体业务需求编写)。 -
使用Seaborn库(基于Matplotlib)生成条形图(
countplot)和折线图(lineplot),并将图表保存为PNG文件。 -
初始化Jinja2环境,加载HTML报告模板。然后,将生成的图表文件路径、表格HTML代码、总结文本和其他相关信息作为参数传入模板,渲染出最终的报告HTML。
-
最后,将生成的HTML报告保存到磁盘上的
generated_report.html文件。
请确保已经安装了所需的Python库(如sqlalchemy, pandas, matplotlib, seaborn, jinja2)并根据实际情况调整数据库连接、查询语句、数据处理步骤、报告模板路径等细节。同时,创建一个名为report_templates的目录(或其他自定义目录),并在其中放置一个名为report_template.html的HTML模板文件,用于定义报告的结构和样式,其中应包含占位符以便Jinja2填充图表、表格和文本内容。例如:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Automated Report</title>
<style>
/* Add any custom CSS styles here */
</style>
</head>
<body>
<h1>Report Title</h1>
<img src="{{ bar_chart_img }}" alt="Bar Chart">
<p>{{ summary_text }}</p>
<img src="{{ line_chart_img }}" alt="Line Chart">
<h2>Data Table</h2>
{{ table|safe }}
<p>{{ additional_info }}</p>
</body>
</html>
七、知识点归纳

在Python中进行Word文档的自动化操作,主要涉及以下几个知识点:
-
库的选择:
python-docx:这是一个广泛使用的Python库,专门用于创建、修改Microsoft Word (.docx)文件。它提供了丰富的API来处理文档的各个部分,如段落、表格、样式、图片等。
-
基础操作:
- 创建文档:使用
Document()函数创建一个新的Word文档对象。 - 打开文档:使用
Document()函数并传入文件路径,可以打开已存在的Word文档。 - 保存文档:调用文档对象的
.save()方法,指定保存路径即可。
- 创建文档:使用
-
文档结构理解:
- 段落:文档中的文本通常组织成段落。可以通过
.add_paragraph()方法添加新段落,或通过索引访问现有段落。 - 运行(Run):段落内部可包含一个或多个运行,每个运行包含连续的文本并可能具有独立的样式。可以使用
.add_run()方法添加文本到段落,或通过段落的.runs属性访问。 - 表格:使用
.add_table()方法添加表格,传入行数和列数。表格由行(.rows)和列(.cells)组成,可以进一步操作单元格内容。 - 样式:包括字体样式、段落样式等。可以应用预定义样式或自定义样式到段落或运行。
- 图片:使用
.add_picture()方法插入图片到文档。
- 段落:文档中的文本通常组织成段落。可以通过
-
文本格式化:
- 字体:设置字体类型、大小、颜色、粗体、斜体等。通过
Font对象(从运行或段落获取)进行设置。 - 段落样式:设置对齐方式、行距、首行缩进、编号列表等。通过
ParagraphFormat对象(从段落获取)进行设置。 - 表格样式:设置表格边框、单元格间距、合并单元格等。通过
Table和Cell对象的属性进行设置。
- 字体:设置字体类型、大小、颜色、粗体、斜体等。通过
-
查找与替换:
- 使用
document.paragraphs和paragraph.runs遍历文档内容,结合字符串方法(如.replace())实现简单查找与替换。 - 对于复杂条件和样式保留的需求,可以使用
python-docx提供的find()和replace()方法。
- 使用
-
批注与书签:
- 批注:通过
document.add_comment()方法添加批注,指定批注作者和文本内容。 - 书签:使用
document.bookmarks属性管理书签。可以添加、查找、删除书签,并通过书签定位文档中的特定位置。
- 批注:通过
-
模板处理:
- 填充模板:使用
python-docx-template(基于python-docx)库,通过类似Jinja2的模板语法填充预定义的Word模板,实现动态内容生成。 - 合并字段:对于邮件合并等场景,可以利用Word内置的“合并域”功能,通过编程控制数据源和合并过程。
- 填充模板:使用
-
高级操作:
- 宏支持:若需要处理包含VBA宏的Word文档,可能需要结合其他库(如
comtypes)或使用自动化接口(如win32com.client)。 - 保护与加密:对文档进行密码保护、限制编辑权限等操作,通常需要借助自动化接口实现。
- 宏支持:若需要处理包含VBA宏的Word文档,可能需要结合其他库(如

在实际应用中,根据具体需求选择合适的操作方法,并结合上述知识点,可以实现Word文档的自动化创建、修改、格式化、内容替换等任务。务必确保已安装python-docx库(以及其他可能需要的扩展库),并查阅其官方文档以获取详细API说明和使用示例。