文章目录
- 一、使用LLM
- 1. 模型
- 2. 词嵌入
- 3. Prompt
- 二、加载
- 1. 加载
- 2. 转换
- (1)高级API
- (2)低级API
- 三、索引/Embedding
- Top K Retrieval
- 四、存储
- 五、查询
- 六、评估
- 1. 生成结果质量评估
- 2. 检索结果评估
RAG(检索增强生成)包括以下步骤:
- 首先从您的数据源检索信息。
- 将这些检索到的信息作为上下文添加到您的问题中。
- 根据增强的提示要求LLM(大型语言模型)进行回答,其中包括检索到的信息作为上下文。
这个过程通过利用从数据源检索到的额外信息,使LLM能够生成更准确和具有上下文相关性的回答。
LlamaIndex提供以下工具,可以快速搭建可投入生产的RAG系统:
- 数据连接器:从各种原生源和格式摄取现有数据,包括API、PDF、SQL等等。
- 数据索引:将数据结构化为中间表示。
- 引擎:提供对数据的自然语言访问。例如:
- 查询引擎:强大的检索接口,用于知识增强型输出。
- 聊天引擎:用于与数据进行多消息“来回”交互的对话接口。
- 数据代理:由LLM驱动的知识工作者,通过工具进行增强,从简单的辅助函数到API集成等等。
- 应用集成:将LlamaIndex与生态系统其他部分进行集成,可以是LangChain、Flask、Docker、ChatGPT等等。
RAG(检索增强生成)包括五个关键阶段:加载(Loading)、索引(Indexing)、存储(Storing)、查询(Querying)和评估(Evaluation)。
- 加载(Loading):加载阶段涉及从数据源获取数据,可以是文本文件、PDF、其他网站、数据库或API。LlamaHub提供了数百个连接器可供选择,用于将数据导入到数据处理流程中。
- 索引(Indexing):索引阶段意味着创建一个数据结构,以便对数据进行查询。对于LLM(大型语言模型)来说,这几乎总是意味着创建向量嵌入(vector embeddings),即数据含义的数值表示,以及许多其他元数据策略,使得可以轻松准确地找到上下文相关的数据。
- 存储(Storing):将数据存储到向量数据库中。
- 查询(Querying):对于任何给定的索引策略,可以利用LLM和LlamaIndex数据结构进行查询,包括子查询、多步查询和混合策略等多种方式。
- 评估(Evaluation):在任何流程中,评估都是至关重要的步骤,用于检查相对于其他策略或在进行更改时流程的有效性。评估提供了关于对查询的响应有多准确、忠实和快速的客观度量标准。
一、使用LLM
1. 模型
在LlamaIndex中,我们可以使用大语言模型的API接口或者本地大语言模型。例如:
使用ChatGPT
from llama_index.llms.openai import OpenAI
from llama_index.core import Settings
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
Settings.llm = OpenAI(temperature=0.2, model="gpt-4")
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(
documents,
)
使用HuggingFace的大语言模型
from llama_index.core import PromptTemplate
# Transform a string into input zephyr-specific input
def completion_to_prompt(completion):
return f"<|system|>\n</s>\n<|user|>\n{completion}</s>\n<|assistant|>\n"
# Transform a list of chat messages into zephyr-specific input
def messages_to_prompt(messages):
prompt = ""
for message in messages:
if message.role == "system":
prompt += f"<|system|>\n{message.content}</s>\n"
elif message.role == "user":
prompt += f"<|user|>\n{message.content}</s>\n"
elif message.role == "assistant":
prompt += f"<|assistant|>\n{message.content}</s>\n"
# ensure we start with a system prompt, insert blank if needed
if not prompt.startswith("<|system|>\n"):
prompt = "<|system|>\n</s>\n" + prompt
# add final assistant prompt
prompt = prompt + "<|assistant|>\n"
return prompt
import torch
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.core import Settings
Settings.llm = HuggingFaceLLM(
model_name="HuggingFaceH4/zephyr-7b-beta",
tokenizer_name="HuggingFaceH4/zephyr-7b-beta",
context_window=3900,
max_new_tokens=256,
generate_kwargs={"temperature": 0.7, "top_k": 50, "top_p": 0.95},
messages_to_prompt=messages_to_prompt,
completion_to_prompt=completion_to_prompt,
device_map="auto",
)
使用自定义大语言模型
from typing import Optional, List, Mapping, Any
from llama_index.core import SimpleDirectoryReader, SummaryIndex
from llama_index.core.callbacks import CallbackManager
from llama_index.core.llms import (
CustomLLM,
CompletionResponse,
CompletionResponseGen,
LLMMetadata,
)
from llama_index.core.llms.callbacks import llm_completion_callback
from llama_index.core import Settings
class OurLLM(CustomLLM):
context_window: int = 3900
num_output: int = 256
model_name: str = "custom"
dummy_response: str = "My response"
@property
def metadata(self) -> LLMMetadata:
"""Get LLM metadata."""
return LLMMetadata(
context_window=self.context_window,
num_output=self.num_output,
model_name=self.model_name,
)
@llm_completion_callback()
def complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:
return CompletionResponse(text=self.dummy_response)
@llm_completion_callback()
def stream_complete(
self, prompt: str, **kwargs: Any
) -> CompletionResponseGen:
response = ""
for token in self.dummy_response:
response += token
yield CompletionResponse(text=response, delta=token)
# define our LLM
Settings.llm = OurLLM()
# define embed model
Settings.embed_model = "local:BAAI/bge-base-en-v1.5"
# Load the your data
documents = SimpleDirectoryReader("./data").load_data()
index = SummaryIndex.from_documents(documents)
# Query and print response
query_engine = index.as_query_engine()
response = query_engine.query("<query_text>")
print(response)
2. 词嵌入
使用Embedding模型的几种方法;
- 本地Embedding模型
- HuggingFace Optimum ONNX模型
- 自定义Embedding模型
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.embeddings.huggingface_optimum import OptimumEmbedding
from typing import Any, List
from InstructorEmbedding import INSTRUCTOR
from llama_index.core.embeddings import BaseEmbedding
from llama_index.core import Settings
# local
Settings.embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-small-en-v1.5"
)
# ONNX
OptimumEmbedding.create_and_save_optimum_model(
"BAAI/bge-small-en-v1.5", "./bge_onnx"
)
Settings.embed_model = OptimumEmbedding(folder_name="./bge_onnx")
# custom
class InstructorEmbeddings(BaseEmbedding):
def __init__(
self,
instructor_model_name: str = "hkunlp/instructor-large",
instruction: str = "Represent the Computer Science documentation or question:",
**kwargs: Any,
) -> None:
self._model = INSTRUCTOR(instructor_model_name)
self._instruction = instruction
super().__init__(**kwargs)
def _get_query_embedding(self, query: str) -> List[float]:
embeddings = self._model.encode([[self._instruction, query]])
return embeddings[0]
def _get_text_embedding(self, text: str) -> List[float]:
embeddings = self._model.encode([[self._instruction, text]])
return embeddings[0]
def _get_text_embeddings(self, texts: List[str]) -> List[List[float]]:
embeddings = self._model.encode(
[[self._instruction, text] for text in texts]
)
return embeddings
async def _get_query_embedding(self, query: str) -> List[float]:
return self._get_query_embedding(query)
async def _get_text_embedding(self, text: str) -> List[float]:
return self._get_text_embedding(text)
3. Prompt
LlamaIndex提供了模板类,使用方法如下:
from llama_index.core import PromptTemplate
template = (
"We have provided context information below. \n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"Given this information, please answer the question: {query_str}\n"
)
qa_template = PromptTemplate(template)
# you can create text prompt (for completion API)
prompt = qa_template.format(context_str=..., query_str=...)
# or easily convert to message prompts (for chat API)
messages = qa_template.format_messages(context_str=..., query_str=...)
from llama_index.core import ChatPromptTemplate
from llama_index.core.llms import ChatMessage, MessageRole
message_templates = [
ChatMessage(content="You are an expert system.", role=MessageRole.SYSTEM),
ChatMessage(
content="Generate a short story about {topic}",
role=MessageRole.USER,
),
]
chat_template = ChatPromptTemplate(message_templates=message_templates)
# you can create message prompts (for chat API)
messages = chat_template.format_messages(topic=...)
# or easily convert to text prompt (for completion API)
prompt = chat_template.format(topic=...)
最常用的提示是text_qa_template 和refine_template。
- text_qa_template: 用于使用检索到的节点获取查询的初始答案
- refine_template: 当检索到的文本不适合使用,第一个查询的答案将作为现有答案插入,法学硕士必须根据新上下文更新或重复现有答案。
- response_mode =“compact”(默认)的单个LLM调用时
- response_mode =“refine”检索多个节点时使用
# shakespeare!
qa_prompt_tmpl_str = (
"Context information is below.\n"
"---------------------\n"
"{context_str}\n"
"---------------------\n"
"Given the context information and not prior knowledge, "
"answer the query in the style of a Shakespeare play.\n"
"Query: {query_str}\n"
"Answer: "
)
qa_prompt_tmpl = PromptTemplate(qa_prompt_tmpl_str)
query_engine.update_prompts(
{"response_synthesizer:text_qa_template": qa_prompt_tmpl}
)
query_engine = index.as_query_engine(
text_qa_template=custom_qa_prompt, refine_template=custom_refine_prompt
)
二、加载
在RAG(检索增强生成)中的加载阶段涉及以下内容:
- 节点和文档(Nodes and Documents):
- 文档是围绕任何数据源的容器,例如PDF、API输出或从数据库中检索的数据。
- 节点是LlamaIndex中的数据的原子单位,代表源文档的“块”,具有与所在文档和其他节点相关联的元数据。
- 连接器(Connectors):数据连接器(通常称为读取器)从不同的数据源和数据格式中摄取数据,并将其导入到文档和节点中。
1. 加载
加载数据
from llama_index.core import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
使用LlamaHub加载数据:在此示例中,LlamaIndex 使用 DatabaseReader 连接器,该连接器对 SQL 数据库运行查询并将结果的每一行作为文档返回:
from llama_index.core import download_loader
from llama_index.readers.database import DatabaseReader
reader = DatabaseReader(
scheme=os.getenv("DB_SCHEME"),
host=os.getenv("DB_HOST"),
port=os.getenv("DB_PORT"),
user=os.getenv("DB_USER"),
password=os.getenv("DB_PASS"),
dbname=os.getenv("DB_NAME"),
)
query = "SELECT * FROM users"
documents = reader.load_data(query=query)
2. 转换
加载数据后需要处理和转换数据,然后再将其放入存储系统。 这些转换包括分块、提取元数据和嵌入每个块。转换输入/输出是 Node 对象(Document 是 Node 的子类)。 转换也可以堆叠和重新排序。
转换包括高级和低级 API。
(1)高级API
index通过from_documents() 方法,它接受 Document 对象数组,并正确解析它们并将它们分块。
from llama_index.core.node_parser import SentenceSplitter
text_splitter = SentenceSplitter(chunk_size=512, chunk_overlap=10)
# global
from llama_index.core import Settings
Settings.text_splitter = text_splitter
# per-index
index = VectorStoreIndex.from_documents(
documents, transformations=[text_splitter]
)
(2)低级API
也可以明确定义这些步骤。通过使用转换模块(文本拆分器、元数据提取器等)作为独立组件,或在声明性转换管道接口中组合它们来实现此目的。
from llama_index.core import SimpleDirectoryReader
from llama_index.core.ingestion import IngestionPipeline
from llama_index.core.node_parser import TokenTextSplitter
documents = SimpleDirectoryReader("./data").load_data()
pipeline = IngestionPipeline(transformations=[TokenTextSplitter(), ...])
nodes = pipeline.run(documents=documents)
document = Document(
text="text",
metadata={"filename": "<doc_file_name>", "category": "<category>"},
)
三、索引/Embedding
在RAG(检索增强生成)中的索引阶段涉及以下内容:
- 索引(Indexes):在摄取数据后,LlamaIndex将数据索引到一个易于检索的结构中。通常这包括生成向量嵌入(vector embeddings),并将其存储在称为向量存储(vector store)的专门数据库中。索引还可以存储关于数据的各种元数据。
- 嵌入(Embeddings):LLM(大型语言模型)生成称为嵌入(embeddings)的数据的数值表示。在过滤与查询相关的数据时,LlamaIndex会将查询转换为嵌入,并且您的向量存储将找到与查询嵌入数值相似的数据。
LlamaIndex 提供了几种不同的索引类型。 在这里介绍几种最常见的。
- Vector Store Index:向量数据库索引获取文档并将它们分成节点。 然后,它创建每个节点文本的向量嵌入,以供LLM查询。要使用向量存储索引,将在加载阶段创建的文档列表或者Node 对象列表传递给它。
from llama_index.core import VectorStoreIndex
index = VectorStoreIndex.from_documents(documents)
index = VectorStoreIndex(nodes)
-
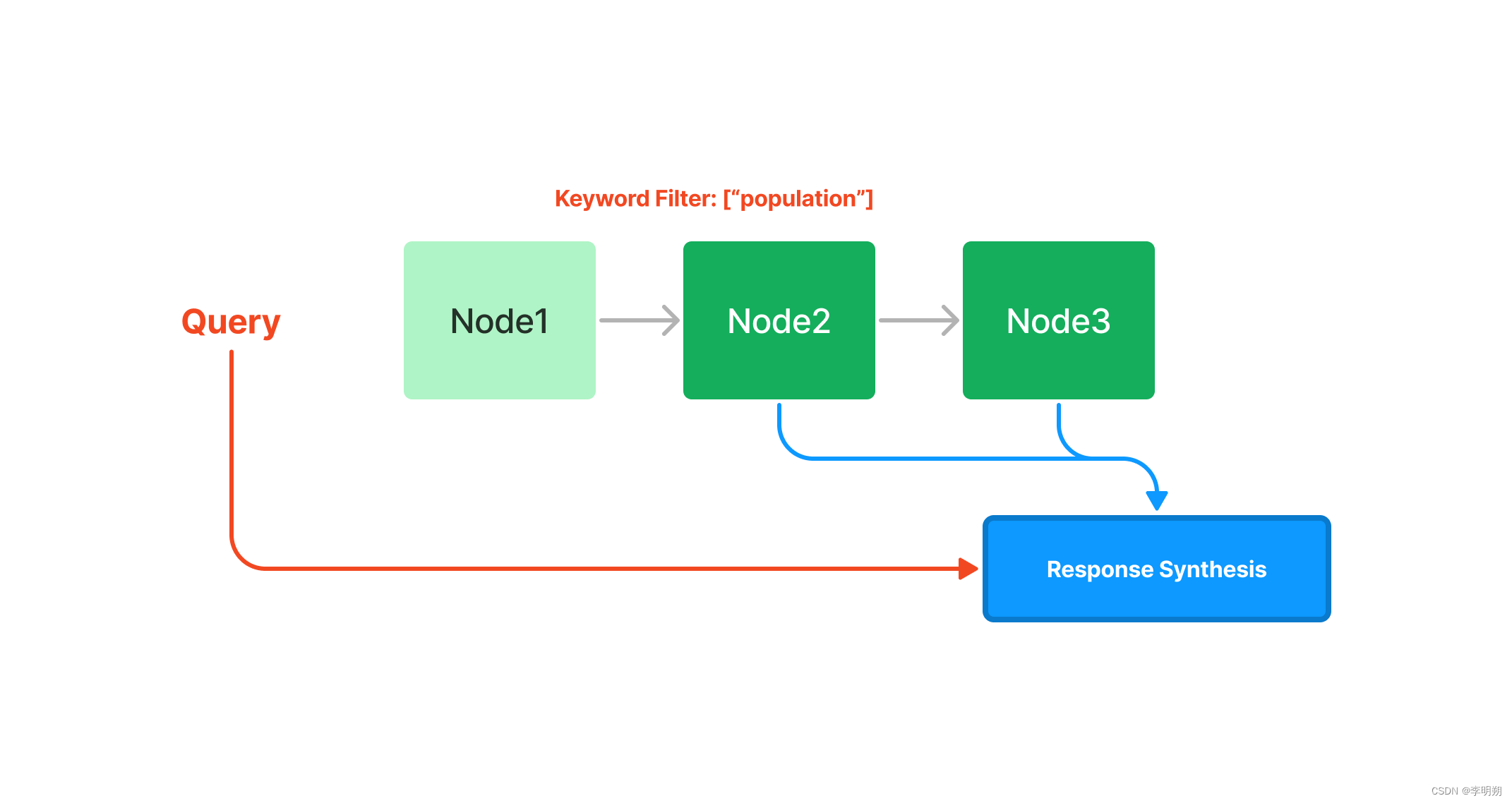
Summary Index:摘要索引是一种更简单的索引形式,最适合查询,目的是生成文档中文本的摘要。 摘要索引只是将节点存储为顺序链。在查询期间,如果没有指定其他查询参数,LlamaIndex 只是将列表中的所有节点加载到我们的响应合成模块中。摘要索引提供了多种查询摘要索引的方法, 包括来自基于嵌入的查询,该查询将获取前 k 个邻居,或者添加关键字过滤器
-
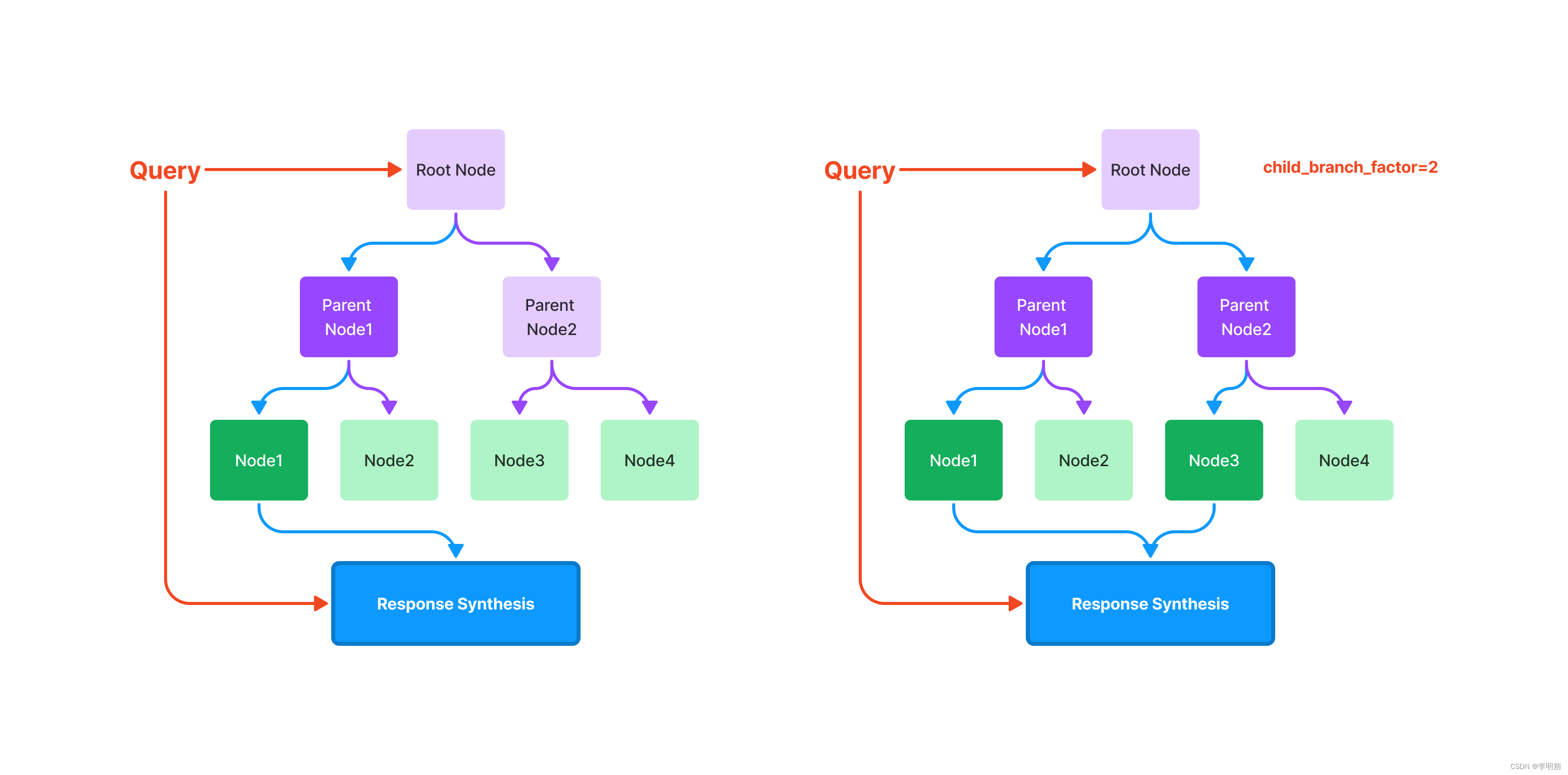
Tree index:树索引从一组节点(成为该树中的叶节点)构建层次树。查询树索引涉及从根节点向下遍历到叶节点。 默认情况下,(child_branch_factor=1),查询会在给定父节点的情况下选择一个子节点。 如果 child_branch_factor=2,则查询每个级别选择两个子节点。
-
其他索引方法参见官方文档:Module Guides
Top K Retrieval
当搜索嵌入时,查询本身会转换为向量嵌入,然后由 VectorStoreIndex 执行数学运算,根据所有嵌入与查询在语义上的相似程度对它们进行排名。排名完成后,VectorStoreIndex 会返回最相似的嵌入作为相应的文本块。 它返回的嵌入数量称为 k,因此控制返回多少嵌入的参数称为 top_k。 由于这个原因,整个类型的搜索通常被称为“top-k 语义检索”。Top-k 检索是查询向量索引的最简单形式。
四、存储
LlamaIndex 还支持可交换存储组件,包括:
- 文档存储:存储摄取的文档(即 Node 对象)的位置,
- 索引存储:存储索引元数据的位置,
- 向量存储:存储嵌入向量的位置。
- 图存储:存储知识图的位置(即 KnowledgeGraphIndex)。
- 聊天存储:存储和组织聊天消息的地方。
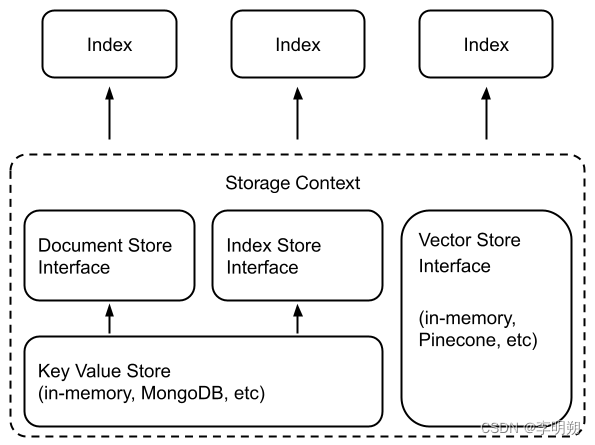
可以使用LlamaIndex提供的存储方法,也可能使用外部向量数据库。
内置方法:
from llama_index.core import StorageContext, load_index_from_storage
# save the index
index.storage_context.persist(persist_dir="<persist_dir>")
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir="<persist_dir>")
# load index
index = load_index_from_storage(storage_context)
外部向量数据库;LlamaIndex 支持很多向量数据库,这些向量存储的架构、复杂性和成本各不相同。 许多向量存储(FAISS 除外)将存储数据和索引(嵌入)。 这意味着不需要使用单独的文档存储或索引存储。在此示例中,我们将使用 Chroma,一个开源向量数据库。
使用 Chroma 存储 VectorStoreIndex 中的嵌入步骤如下:
- 初始化 Chroma 客户端
- 创建一个collection来将数据存储在 Chroma 中
- 将 Chroma 指定为 StorageContext 中的 vector_store
- 使用 StorageContext 初始化 VectorStoreIndex
import chromadb
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.core import StorageContext
# load some documents
documents = SimpleDirectoryReader("./data").load_data()
# initialize client, setting path to save data
db = chromadb.PersistentClient(path="./chroma_db")
# create collection
chroma_collection = db.get_or_create_collection("quickstart")
# assign chroma as the vector_store to the context
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# create your index
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context
)
# create a query engine and query
query_engine = index.as_query_engine()
response = query_engine.query("What is the meaning of life?")
print(response)
下面的代码是加载一个创建好的向量数据库
import chromadb
from llama_index.core import VectorStoreIndex
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.core import StorageContext
# initialize client
db = chromadb.PersistentClient(path="./chroma_db")
# get collection
chroma_collection = db.get_or_create_collection("quickstart")
# assign chroma as the vector_store to the context
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# load your index from stored vectors
index = VectorStoreIndex.from_vector_store(
vector_store, storage_context=storage_context
)
# create a query engine
query_engine = index.as_query_engine()
response = query_engine.query("What is llama2?")
print(response)
五、查询
简单的查询只是对LLM的prompt调用:它可以是一个问题并获得答案,或者是一个总结请求。更复杂的查询可能涉及重复/链接prompt+ LLM 调用,甚至跨多个组件的推理循环。
在RAG(检索增强生成)中的查询阶段涉及以下内容:
- 检索器(Retrievers):检索器定义了如何在给定查询时从索引中高效检索相关上下文。检索策略对于检索到的数据的相关性和效率至关重要。
- 路由器(Routers):路由器确定将使用哪个检索器从知识库中检索相关上下文。更具体地说,RouterRetriever类负责选择一个或多个候选检索器来执行查询。它们使用选择器根据每个候选的元数据和查询选择最佳选项。
- 节点后处理器(Node Postprocessors):节点后处理器接收一组检索到的节点,并对它们应用转换、过滤或重新排序逻辑。
- 响应合成器(Response Synthesizers):响应合成器使用用户查询和一组检索到的文本块从LLM生成响应。
在下面的示例中,我们自定义检索器以对 top_k 使用不同的值,并添加一个后处理步骤,该步骤要求检索到的节点达到要包含的最小相似度分数。 当有相关结果时,这将提供大量数据,但如果没有任何相关结果,则可能不会提供任何数据。
from llama_index.core import VectorStoreIndex, get_response_synthesizer
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.postprocessor import SimilarityPostprocessor
# build index
index = VectorStoreIndex.from_documents(documents)
# configure retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=10,
)
# configure response synthesizer
response_synthesizer = get_response_synthesizer()
# assemble query engine
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
node_postprocessors=[SimilarityPostprocessor(similarity_cutoff=0.7)],
)
# query
response = query_engine.query("What did the author do growing up?")
print(response)
节点后处理器:支持高级节点过滤和增强,可以进一步提高检索到的节点对象的相关性。 这可以帮助减少 LLM 调用的时间/次数/成本或提高响应质量。例如:
- KeywordNodePostprocessor:通过required_keywords和exclusion_keywords过滤节点。
- SimilarityPostprocessor:通过设置相似度分数的阈值来过滤节点(因此仅受基于嵌入的检索器支持)
- PrevNextNodePostprocessor:使用基于节点关系的附加相关上下文来增强检索到的节点对象。
响应合成:检索器获取相关节点后,BaseSynthesizer 通过组合信息来合成最终响应。配置query_engine = RetrieverQueryEngine.from_args(retriever, response_mode=response_mode),目前支持以下选项:
- default:通过顺序遍历每个检索到的节点来“创建和完善”答案; 这使得每个节点都有一个单独的 LLM 调用。 适合更详细的答案。
- compact:通过填充尽可能多的节点文本块来“压缩”每次 LLM 调用期间的提示,使其适合最大提示大小。 如果一个提示中的内容太多,无法填充,请通过多个提示来“创建和完善”答案。
- tree_summarize:给定一组 Node 对象和查询,递归构造一棵树并返回根节点作为响应。 适合总结目的。
- no_text:仅运行检索器来获取本应发送到 LLM 的节点,而不实际发送它们。 然后可以通过检查response.source_nodes来检查。 第 5 节更详细地介绍了响应对象。
- accumulate:给定一组 Node 对象和查询,将查询应用于每个 Node 文本块,同时将响应累积到数组中。 返回所有响应的串联字符串。 适合当您需要对每个文本块单独运行相同的查询时。
六、评估
LlamaIndex 提供了衡量生成结果质量和检索质量的关键模块。
1. 生成结果质量评估
LlamaIndex 提供基于LLM的评估模块来衡量结果的质量。 这使用“黄金”LLM(例如 GPT-4)以多种方式决定预测答案是否正确。当前的评估模块不需要真实标签。 可以通过查询、上下文、响应的某种组合来完成评估,并将这些与 LLM 调用结合起来。
这些评估模块有以下形式:
- 正确性:生成的答案是否与给定查询的参考答案匹配(需要标签)。
- 语义相似度 预测答案在语义上是否与参考答案相似(需要标签)。
- 忠实性(Faithfulness):评估答案是否忠实于检索到的上下文(换句话说,是否存在幻觉)。
- 上下文相关性:检索到的上下文是否与查询相关。
- 答案相关性:生成的答案是否与查询相关。
- 准则遵守情况:预测答案是否遵守特定准则。
from llama_index.core import VectorStoreIndex
from llama_index.llms.openai import OpenAI
from llama_index.core.evaluation import FaithfulnessEvaluator
# create llm
llm = OpenAI(model="gpt-4", temperature=0.0)
# build index
...
vector_index = VectorStoreIndex(...)
# define evaluator
evaluator = FaithfulnessEvaluator(llm=llm)
# query index
query_engine = vector_index.as_query_engine()
response = query_engine.query(
"What battles took place in New York City in the American Revolution?"
)
eval_result = evaluator.evaluate_response(response=response)
print(str(eval_result.passing))
2. 检索结果评估
给定问题数据集和真实排名,我们可以使用平均倒数排名(MRR)、命中率、精度等排名指标来评估检索器。核心检索评估步骤围绕以下内容:
- 数据集生成:给定非结构化文本语料库,综合生成(问题、上下文)对。
- 检索评估:给定检索器和一组问题,使用排名指标评估检索结果。
from llama_index.core.evaluation import RetrieverEvaluator
# define retriever somewhere (e.g. from index)
# retriever = index.as_retriever(similarity_top_k=2)
retriever = ...
retriever_evaluator = RetrieverEvaluator.from_metric_names(
["mrr", "hit_rate"], retriever=retriever
)
retriever_evaluator.evaluate(
query="query", expected_ids=["node_id1", "node_id2"]
)