1、memcpy内存拷贝
不仅可以拷贝,还可以拷贝整型、结构体等,因为直接拷贝了内存。
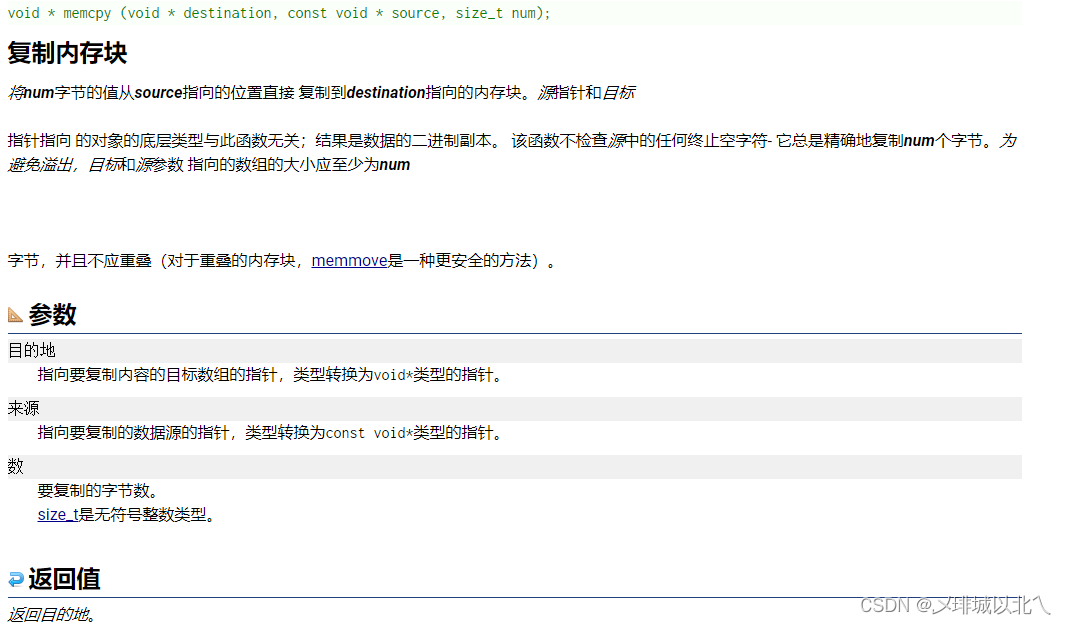
因为不知道要拷贝的类型是什么,所以都用void*来接收。num是拷贝的字节数
拷贝时可任意选择dest,src,以及字节数。返回void*类型的指针,使用时强制转换即可。
注意:假设拷贝整型时,如果不是4的倍数,拷贝时仅拷贝某个整型的一部分,而拷贝的这个部分又因为大小端字节序存储而不同,从而导致一些复杂情况甚至错误。因此尽量按需拷贝,一次拷贝完整,不要随意拷贝。
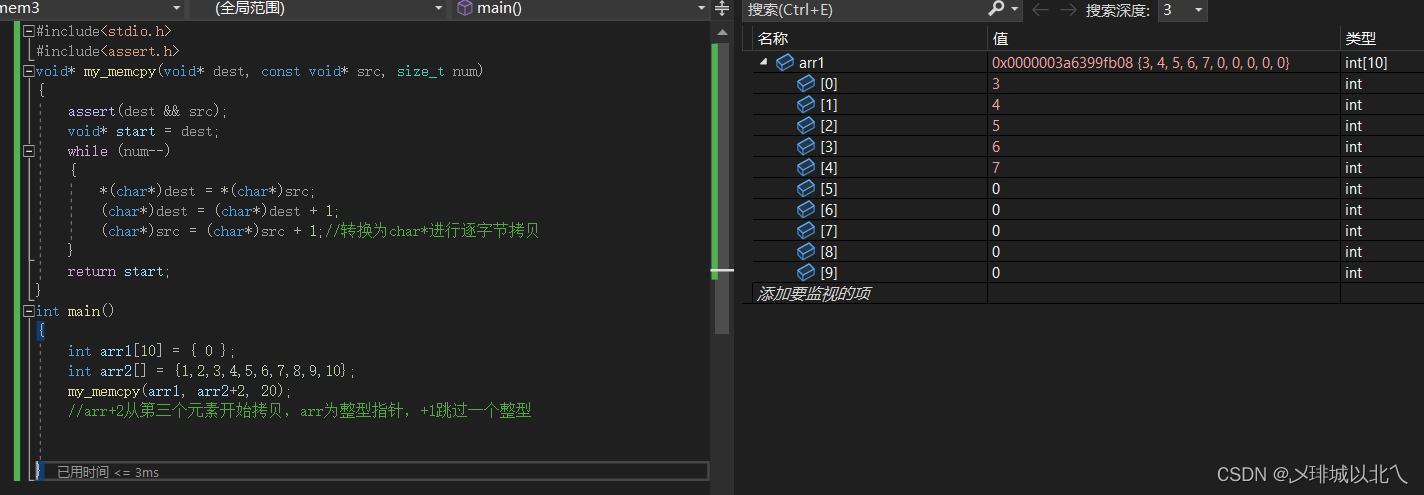
void* my_memcpy(void* dest, const void* src, size_t num)
{
assert(dest && src);
void* start = dest;
while (num--)
{
*(char*)dest = *(char*)src;
(char*)dest = (char*)dest + 1;
(char*)src = (char*)src + 1;//转换为char*进行逐字节拷贝
}
return start;
}
int main()
{
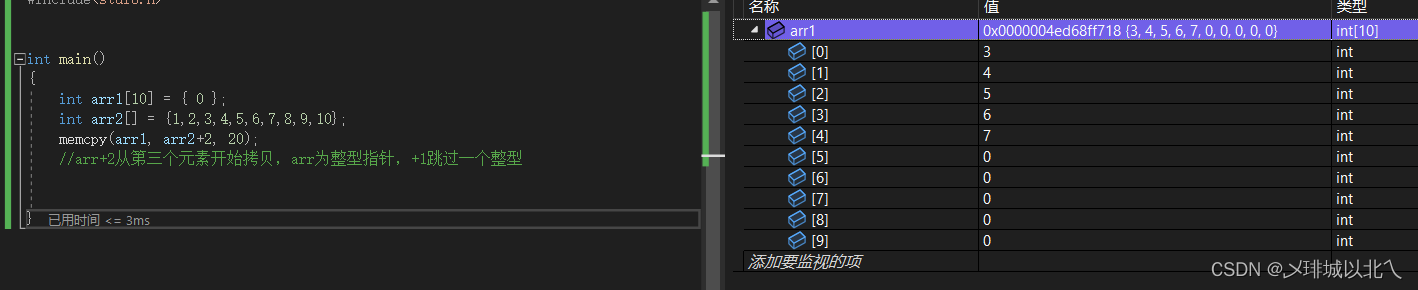
int arr1[10] = { 0 };
int arr2[] = {1,2,3,4,5,6,7,8,9,10};
my_memcpy(arr1, arr2+2, 20);
//arr+2从第三个元素开始拷贝,arr为整型指针,+1跳过一个整型
}内存拷贝其实是一种不分类型的拷贝,我们之前在讲解冒泡bubble实现qsort函数时,也是利用void*,覆盖时强制类型转化为最小单元char*来进行逐字节覆盖的。以后在不分类型时都可考虑。
与字符串拷贝与追加相同的是,当dest和src重叠时就会产生一些问题。当拷贝时改变了src的内容,进而导致后续拷贝的错误。

进一步的,我们对这种内存重叠的情况进行分析。
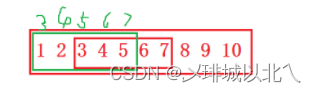
当我们要将1-5拷贝3-7时,可以从src的后面开始拷贝,即先拷贝5,再4,...直到全部拷贝
当我们要将3-7拷贝到1-5,可以从src的前面开始拷贝,即先拷贝3,再4,...直到全部拷贝
当dest<src时,从src前部开始拷贝,反之从后。(不重叠时随意)
2、memmove
有了上述规律,我们可以将memcpy升级为memmove。即实现时加上上述规律。
void* my_memmove(void* dest, const void* src, size_t num)
{
assert(dest && src);
void* start = dest;
if (dest>src)//后到前
{
while (num--)
{
*((char*)dest + num) = *((char*)src + num);
}
}
else//前到后
{
while (num--)
{
*(char*)dest = *(char*)src;
(char*)dest = (char*)dest + 1;
(char*)src = (char*)src + 1;
}
}
}
int main()
{
int arr1[] = { 1,2,3,4,5,6,7,8,9,10 };
my_memcpy(arr1 + 2, arr1, 20);
}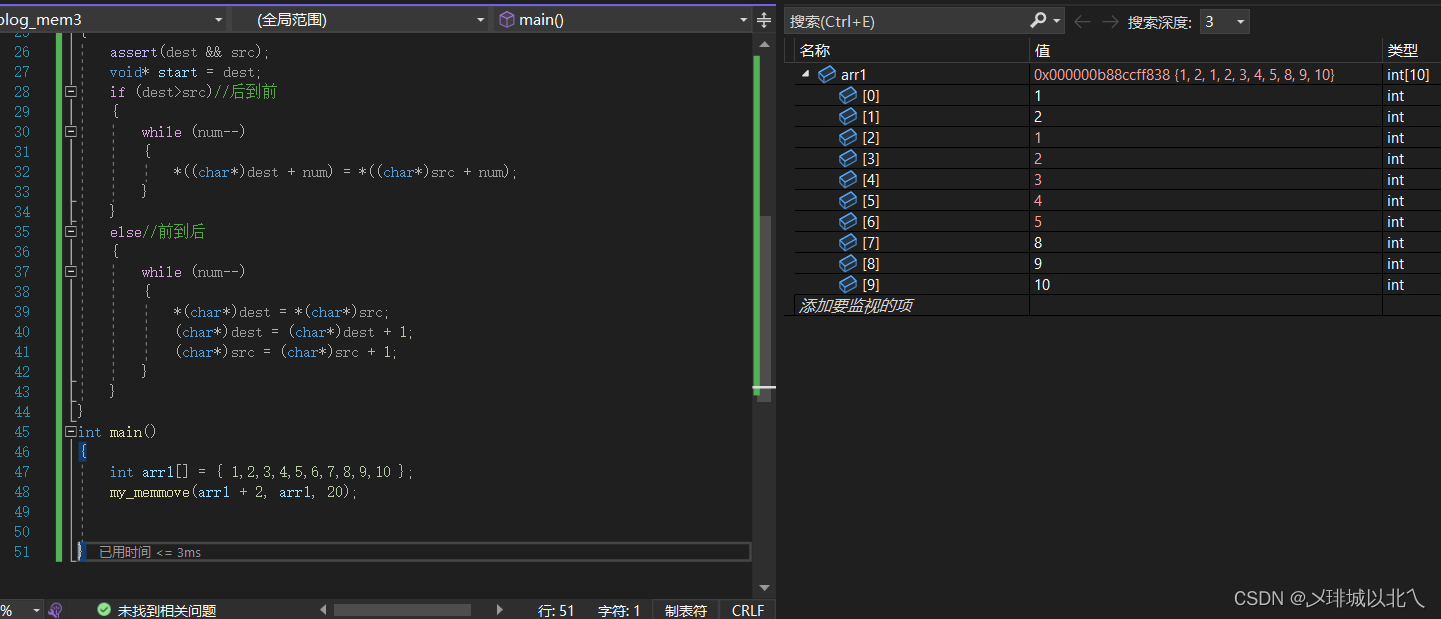
升级过后就可以完成有内存覆盖的拷贝了。
3、memset
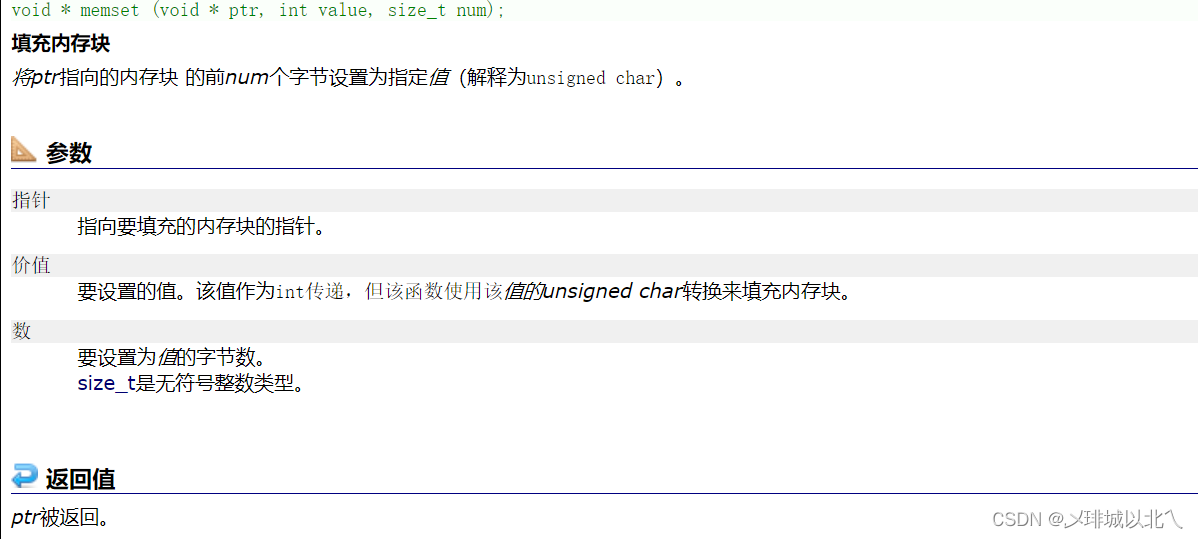
将目标数组的指定个字节数设置为某值。

传入的字符或ASCLL码值。
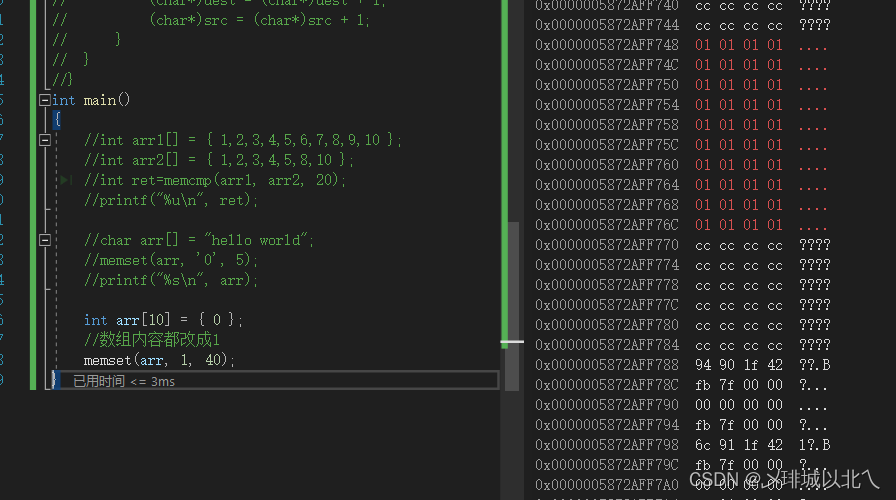 把每个字节改为1,会发生截断。
把每个字节改为1,会发生截断。
4、memcmp
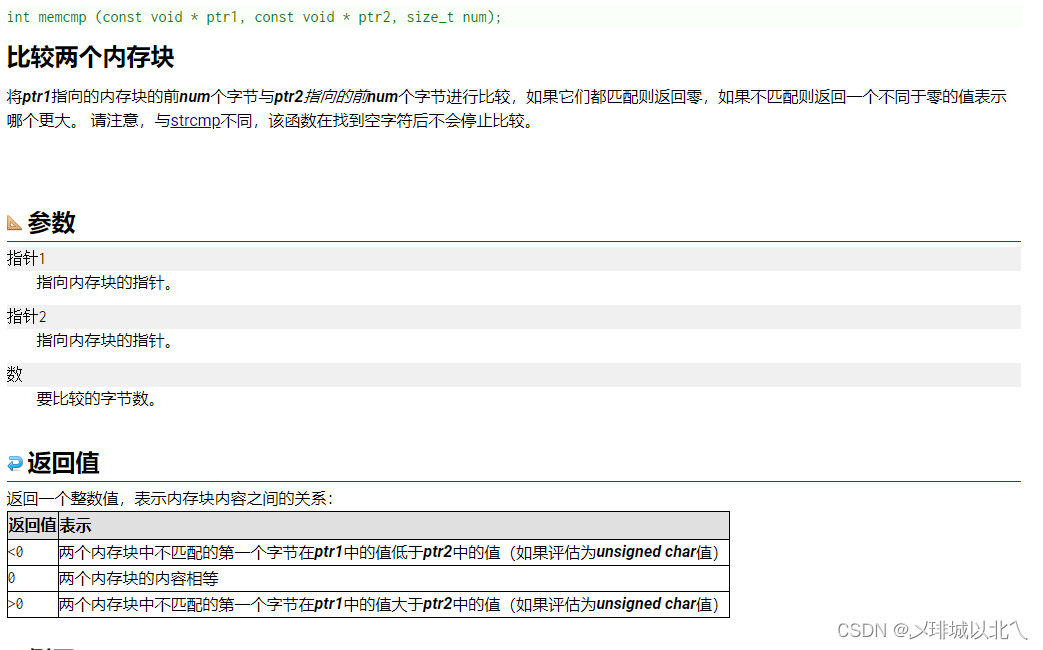
和strcmp类似,只是参数是void*类型,也可以指定字节数来进行比较,返回值0则相同,+-则为内存ASCLL码值的比较。

总结:
内存函数的优势:内存函数的实现是无关类型的,可以通过逐字节来实现,因为无关类型,所以函数参数返回值等要考虑使用void*类型,实现时可强制类型转换为char*后解引用或+-,接收时也是如此。
内存函数的劣势:因为不考虑具体类型而通过逐字节实现,我们还原到原来的类型时,常常会因为大小端字节序存储等原因,无法将这几个字节联系成一个整体,而进行单个的应用,从而导致一些麻烦和错误。
为了避开劣势,我们程序员在使用时应当充分考虑到使用的类型对应字节的整数倍,从而避免麻烦,快速方便的达到我们的需求。











![P8630 [蓝桥杯 2015 国 B] 密文搜索](https://img-blog.csdnimg.cn/8aa439044d284067956877bbb7e453a2.png)