【论文速递】ECCV2022 - ConMatch:置信度引导的半监督学习
【论文原文】:ConMatch: Semi-Supervised Learning with Confidence-Guided Consistency Regularization
获取地址:https://arxiv.org/abs/2208.08631
博主关键词: 半监督学习,对比学习,一致性正则化
摘要:
我们提出了一种新的半监督学习框架,智能地利用模型预测之间的一致性正则化,从图像的两个强增强视图,由伪标签置信度加权,称为ConMatch。虽然最新的半监督学习方法使用图像的弱增强视图和强增强视图来定义方向一致性损失,但如何为两个强增强视图之间的一致性正则化定义这种方向仍未探索。为了解释这一点,我们提出了新的伪标签置信度测量方法,通过弱增强视图作为非参数和参数方法的锚。特别是在参数化方法中,我们首次提出了在网络中学习伪标签置信度的方法,这是通过骨干网模型端到端学习的。此外,我们还提出了分阶段训练,以促进训练的收敛。当将ConMatch整合到现有的半监督学习器中时,它能不断提高性能。我们通过实验来证明ConMatch比最新方法的有效性,并提供广泛的消融研究。代码已在https://github.com/JiwonCocoder/ConMatch上公开提供。
简介:
半监督学习已经成为一种有吸引力的解决方案,以减轻对大量标记数据的依赖,这些数据通常很难获得,并智能地利用大量未标记数据,以至于被部署在许多计算机视觉应用程序中,特别是图像分类[40,53,55]。该任务一般采用伪标记[1,19,30,40,46,51,61]或一致性正则化[17,24,29,36,48,53]。一些方法[4,5,42,47,52,54,58]提出将这两种方法整合在一个统一的框架中,这通常被称为整体方法。FixMatch[47]是一项开创性的工作,它首先根据模型对弱增强实例的预测生成一个伪标签,然后鼓励来自强增强实例的预测遵循伪标签。他们的成功激发了许多变体,例如,curriculum learning[54,58]。
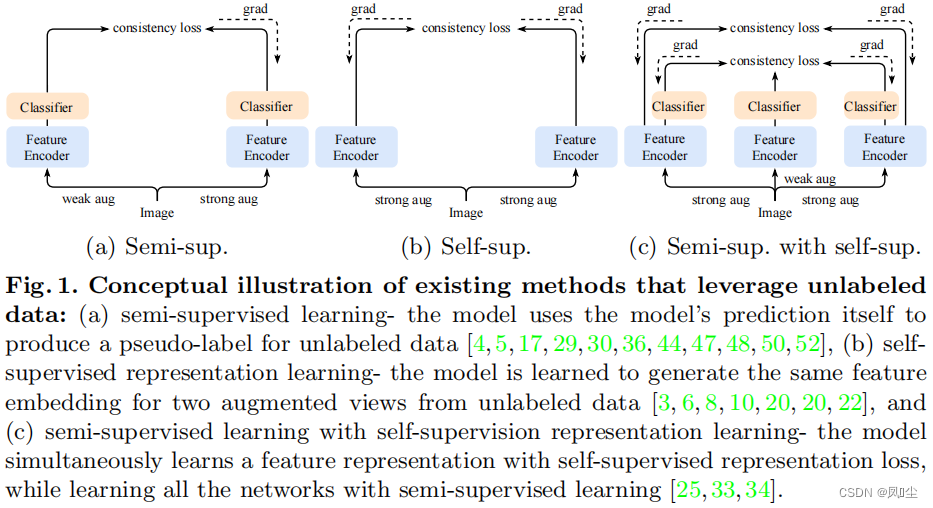
另一方面,在争夺更好的半监督学习方法的同时[47,54,58],自监督表示学习取得了实质性进展,特别是**对比学习[3,6,8,10,20,22],旨在学习一种不需要任何监督的任务不确定特征表示,可以很好地转移到下游任务中**。形式上,它们鼓励从两张不同增强图像中提取的特征相互拉取,这为模型注入了一些不变性或鲁棒性。毫不奇怪,半监督学习框架肯定可以从自监督表示学习中受益[25,33,34],因为来自特征编码器的良好表示可以通过半监督学习产生更好的性能,因此,一些方法[25,33]试图结合上述两种范式,通过实现更好的特征编码器来提高性能。
扩展现有的自监督表示学习[3,6,8,10,20,22]中提出的技术,只关注学习特征编码器,进一步考虑模型的预测本身,这将是有效结合两种范式的有效解决方案,这不仅可以增强特征编码器,还可以增强分类器。但是,相对于特征表示学习[3,6,8,10,20,22],应该通过考虑哪个方向在图像分类中既能达到不变性又能达到较高的准确率来定义模型两种不同增强预测的一致性。如果没有这一点,像[3,6,8,10,20,22]中那样简单地提取模型的预测可能会阻碍分类器的输出,从而降低准确性。
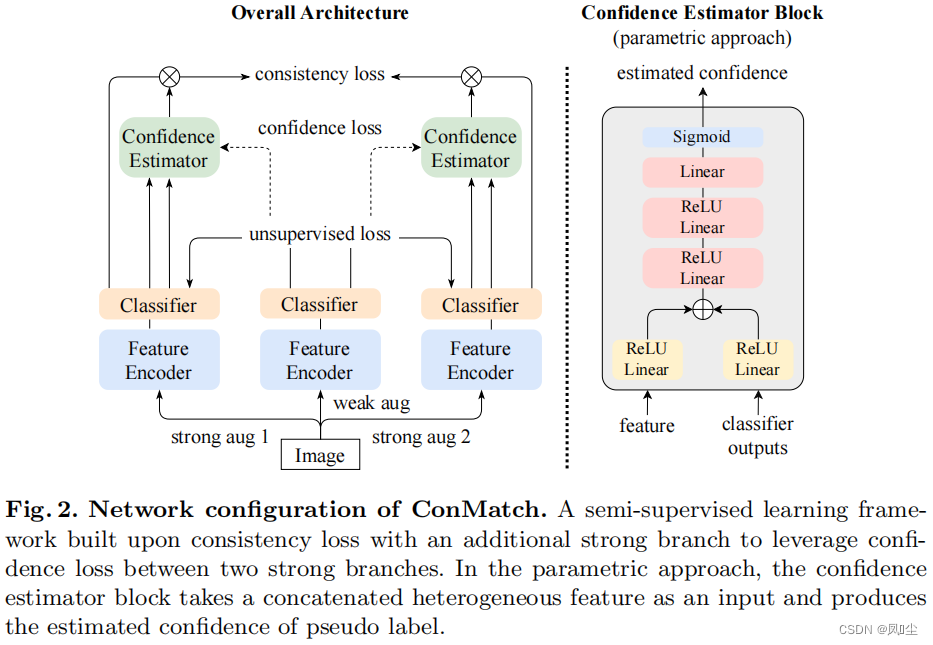
在本文中,我们提出了一种新的半监督学习框架,称为ConMatch,它智能地利用了来自两个强增强图像的模型预测之间的置信度引导一致性正则化。基于传统框架[47,58],我们考虑两张强增强图像和一张弱增强图像,并定义来自两张强增强图像的模型预测之间的一致性,同时仍然使用来自其中一张强增强图像和弱增强图像的模型预测之间的无监督损失,如[47,58]中所做的那样。由于定义两个强增强图像之间一致性正则化的方向是最重要的,而不是以确定性的方式进行选择,我们提出了一种概率技术,通过测量来自每个强增强图像的伪标签的置信度,并用这个置信度加权一致性损失。为了测量伪标签的置信度,我们提出了两种方法,包括非参数方法和参数方法。通过这种信心引导的一致性正则化,我们的框架极大地提高了现有半监督学习器的性能[47,58]。此外,我们还提出了分阶段的训练方案,以促进训练的收敛。我们的框架是一个即插即用的模块,因此各种半监督学习模型[4,25,33,34,47,52,54,58]可以从我们的框架中受益。我们在表1中简要地总结了我们的方法与半监督学习中其他高度相关的工作。实验结果和消融研究表明,所提出的框架不仅提高了收敛性,而且在大多数标准基准上都达到了最先进的性能[12,28,37]。

![P8630 [蓝桥杯 2015 国 B] 密文搜索](https://img-blog.csdnimg.cn/8aa439044d284067956877bbb7e453a2.png)