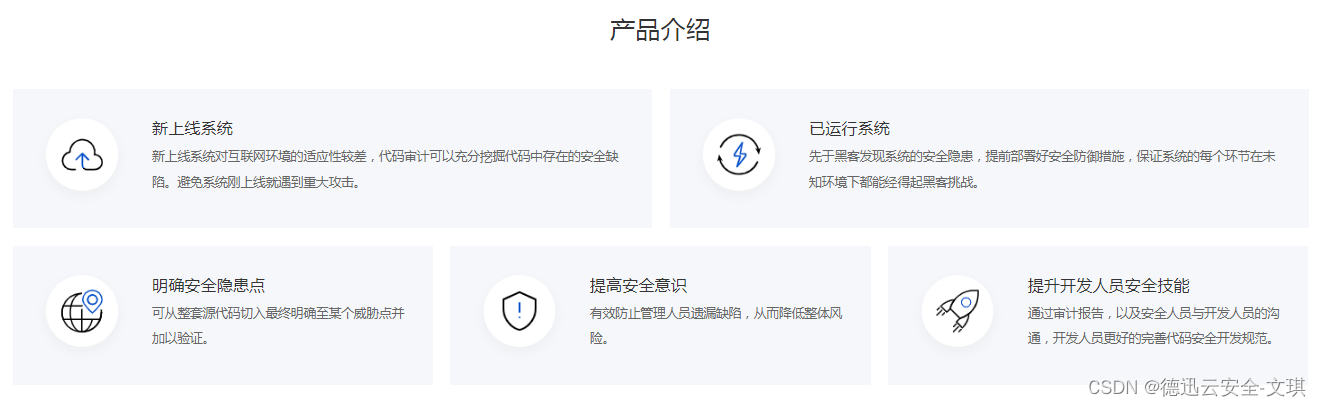
1. 引言
在当今数据驱动的世界里,机器学习技术已成为解决复杂问题和提升决策制定效率的关键工具。随着数据的增长和计算能力的提升,传统的单一模型方法已逐渐无法满足高精度和泛化能力的双重要求。集成学习,作为一种结合多个学习算法以获得比单个算法更优性能的方法,因其卓越的准确性和鲁棒性而受到广泛关注。本文旨在深入探讨集成学习的原理、方法及其在各个领域的应用,希望能为读者提供一个全面的理解框架。
2. 集成学习概述
集成学习是一种机器学习范式,旨在通过构建并组合多个模型来解决单一预测问题。它基于一个简单却强大的理念:“三个臭皮匠,顶一个诸葛亮”,或者用西方的谚语来说,“两个头脑胜过一个头脑”。在集成学习的背景下,这意味着多个模型的集成通常会比单个模型的表现要好。



集成学习背后的直觉非常直接:不同的模型可能会在不同的数据子集或不同的问题方面表现出优势。通过合理地结合这些模型,可以利用各个模型的优点,从而提高整体的预测准确性。在集成学习中,模型可以是同种类型的(如全部是决策树),也可以是不同类型的(如决策树、神经网络和支持向量机的组合)。
集成学习中的模型分为两种:强学习器和弱学习器。强学习器指的是那些表现出高准确性的模型,而弱学习器则是准确率仅略高于随机猜测的模型。集成学习的魔力在于它能够通过组合多个弱学习器来构建一个强学习器,显著提升模型的性能。
3. 集成学习的直觉和理论基础
集成学习的核心思想源于对“群体智慧”的信任。在多个模型的决策中,即使每个模型都不完美,它们的集体决策往往能够达到令人惊讶的准确度。这背后的直觉是,每个模型都可能从不同角度捕捉到数据的特征,而将这些不同角度的理解综合起来,就能够得到一个更全面、更准确的视角。
从理论上讲,集成学习之所以有效,有几个关键理由:
- 多样性:组成集成的模型越是多样化,集成的效果通常越好。模型的多样性意味着它们在数据的不同方面或不同子集上表现出优异的性能。
- 独立性:如果模型间的错误是相互独立的,那么通过组合模型,这些错误在集成中可能会被相互抵消,从而提高总体性能。
- 专业化:每个模型可能在数据集的某个特定部分表现得非常好。通过集成,可以构建一个更加“专业化”的系统,每个模型负责它擅长的部分。
接下来的部分,我会继续探讨集成学习的具体策略和方法,并深入讨论它们在实际应用中的优势及注意事项。
4. 集成学习策略
集成学习的实现可以通过多种策略完成,主要包括平均法、投票法和学习法。每种策略都有其独特的应用场景和优势。
平均法
平均法是最直接的集成策略之一,通常用于回归问题。它可以是简单平均,即直接计算所有模型预测的平均值;也可以是加权平均,即根据每个模型的性能赋予不同的权重,然后计算加权平均值。加权平均法可以进一步提高集成的性能,特别是当某些模型表现明显优于其他模型时。
投票法
投票法常用于分类问题,包括多数投票法和加权投票法。在多数投票法中,每个模型对样本类别的预测被视为一票,最终结果由获得票数最多的类别确定。加权投票法则考虑了模型的权重,即性能更好的模型在最终决策中具有更大的影响力。
学习法
学习法,也称为元学习法,是一种更复杂的集成策略,它通过另一个学习算法来整合各个模型的预测。最典型的例子是堆叠(Stacking),其中基学习器的输出被用作次级学习器的输入,以产生最终的预测结果。这种方法可以捕捉不同基学习器输出之间的复杂关系,从而进一步提升性能。
5. 主要集成学习方法
加权多数算法
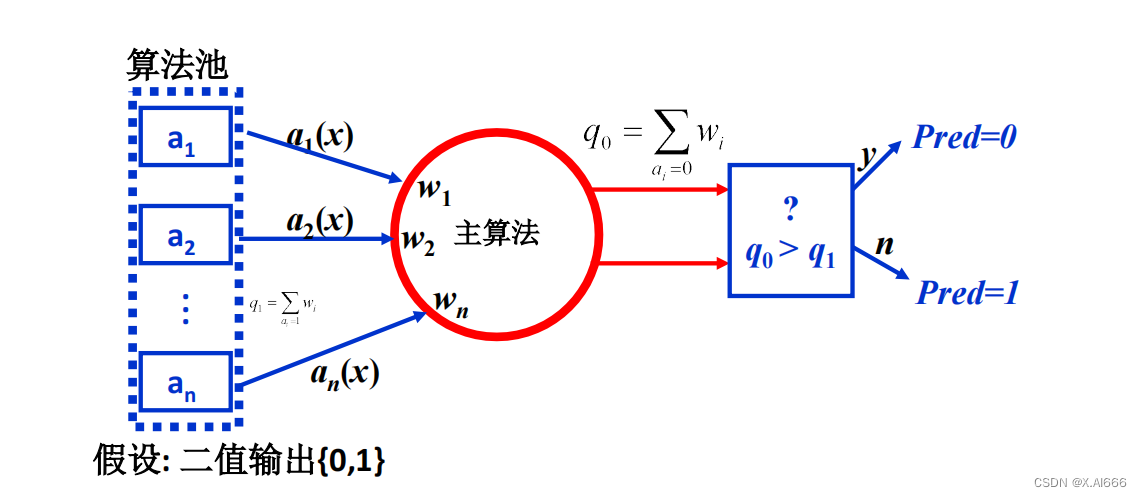

加权多数算法是一种基本的集成方法,它通过为每个模型分配一个权重,并根据模型预测的正确性来调整这些权重。模型预测正确,则增加其权重;预测错误,则减少其权重。这种方法强调了正确预测的重要性,并通过动态调整权重来优化集成的性能。
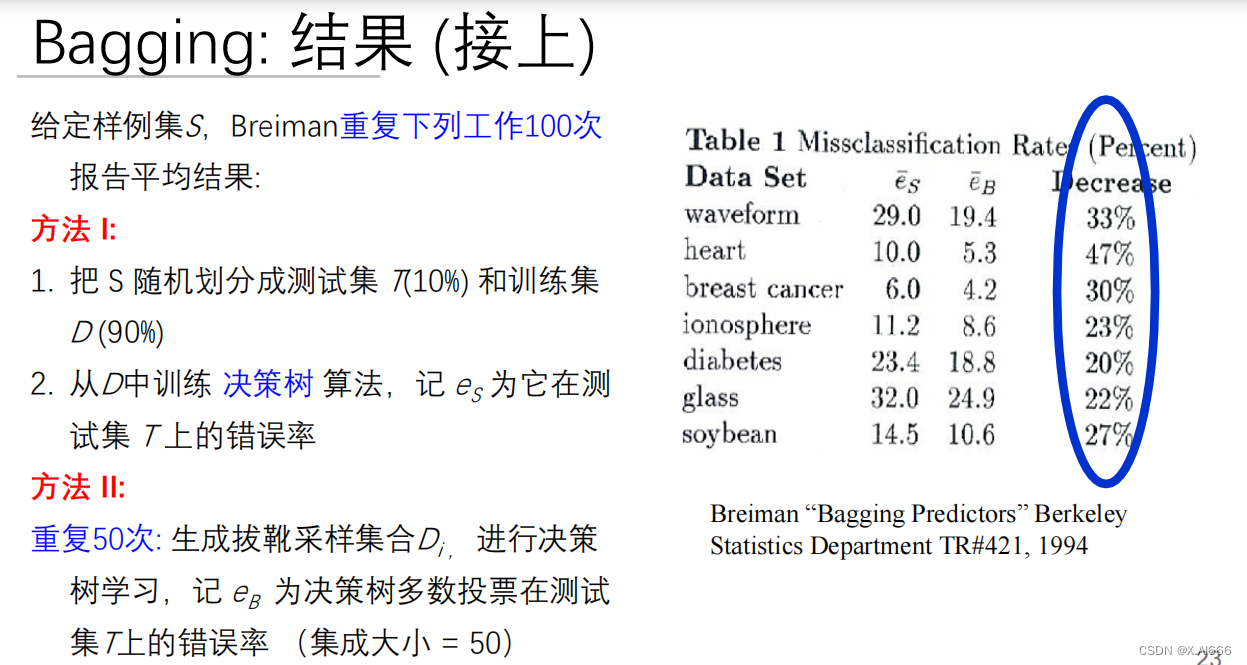
Bagging

Bagging,也称为自举汇聚法,通过在原始数据集上进行多次重采样(通常是有放回抽样)来创建多个训练集,然后分别训练多个模型。所有模型的预测结果通常通过简单平均或多数投票法来合并。Bagging的关键优势在于它可以显著减少模型的方差,尤其是对于那些容易过拟合的模型如决策树。


Boosting

Boosting是一种逐步增强模型性能的方法。它开始于对所有训练样本赋予相同的权重,然后迭代地训练模型。在每一次迭代中,错误分类的样本将获得更高的权重,这迫使下一个模型更加关注之前被错误分类的样本。Boosting的经典例子包括AdaBoost和梯度提升机(GBM)。Boosting能够提升模型的偏差和方差,是一种非常强大的集成技术。



6. 集成学习的应用
集成学习方法在许多领域都有广泛的应用,从互联网搜索和推荐系统到医疗诊断和股票市场分析。例如,随机森林(一种基于Bagging的方法)被广泛用于特征选择和分类问题。Boosting方法,特别是AdaBoost和梯度提升机,因其出色的性能而被用于各种竞赛和商业项目中。
7. 讨论:Bagging与Boosting的比较
尽管Bagging和Boosting都旨在通过结合多个模型来提高预测性能,但它们在设计和实现上有本质的不同。Bagging通过减少模型的方差来提高性能,而Boosting则通过同时减少偏差和方差来实现。Bagging中的模型可以并行训练,而Boosting需要顺序训练模型,因为每个模型的训练依赖于前一个模型的结果。
8. 结论
集成学习是机器学习中一个非常强大的范式,通过组合多个模型来提升预测性能。不同的集成策略和方法适用于不同的问题和数据集,选择合适的集成方法可以显著提高模型的准确性和泛化能力。随着机器学习技术的不断发展,集成学习无疑将继续在各个领域发挥重要作用。