高性能计算(High performance computing, 缩写HPC)
指通常使用很多处理器(作为单个机器的一部分)
或者某一集群中组织的几台计算机(作为单个计 算资源操作)的计算系统和环境。
有许多类型的HPC 系统,其范围从标准计算机的大型集群,到高度专用的硬件。
大多数基于集群的HPC系统使用高性能网络互连,比如那些来自 InfiniBand 或 Myrinet 的网络互连。
基本的网络拓扑和组织可以使用一个简单的总线拓扑,
在性能很高的环境中,网状网络系统在主机之间提供较短的潜伏期,
所以可改善总体网络性能和传输速率。
让深度学习更高效运行的两个视角 | 计算量和访存
海思NNIE之Mobilefacenet量化部署
斯坦福大学Fall 2018课程-机器学习硬件加速器 cs217
浮点运算和代码优化, 并行计算, Optimizer软件
第十七章 模型压缩及移动端部署
这个Model是指计算机上的一个应用,它占用了两类最主要的资源:算术逻辑单元的计算资源,存储器的带宽资源。这里的计算资源以FLOPS来表示;带宽资源以byte/s表示。
Roofline model是说什么呢?横轴是Operational Intensity,就是计算的密度,单位是FLOPS/byte;纵轴是performance,也就是性能,单位是FLOPS。
图中有一条折线,这个折线开始的时候是随着计算密度的增加而增加,最终会稳定在一个固定的performance上。这个意思是:当这个应用程序的计算密度大于一定值之后,将会变成一个受算术逻辑单元的计算量所限制的程序;而这个计算密度如果小于一定值,将会变成一个受存储器带宽所限制的程序。
这里折线的拐点非常重要。这个拐点跟硬件很相关,它实际上表示的是硬件的理论计算能力和它的内存带宽之间的一个比值。
举两个具体的例子,第一个是矩阵乘矩阵,矩阵C等于A乘B,而A跟B分别是一千乘一千的矩阵。假设存储和计算都是用float 32位来表示,这样一个计算将会做1000乘1000乘1000的浮点乘加,也就是2G FLOPS的运算。我们要读取A和B,然后计算出来C,把它写回去,最少的存储器访问就是三个矩阵的大小,也就是12个MB。
另外一个是矩阵乘向量,也就是矩阵A乘向量B,等于向量C,这时候维度还是1000的情况下,它的计算量就是1000乘1000的浮点乘加,也就是2M。而存储器访问的话最少大约是1000乘于1000个浮点数,也就是4MB。
可以明显地看到上面乘矩阵的操作,它的计算量是2G,访存量是12M,那么它的这个计算量除以访存量,也就是刚刚提到的计算密度,大概是200左右。下面这个矩阵和向量中,它的计算量是2M,访存量是4M,那它的计算量除以访存量大约就只有0.5,显然这两个就是非常不同的程序。
上面矩阵乘矩阵,是一个典型的受计算量约束的程序;而下面矩阵乘向量则是一个典型的受存储器带宽所约束的程序。
小模型部署在这些硬件上,通常都是被存储带宽所限制住了,而不是被计算量所限制住。
卷积计算优化
目前,卷积的计算大多采用间接计算的方式,主要有以下三种实现方式:
1、im2col + GEMM。
caffe等很多框架中都使用了这种计算方式,
原因是将问题转化为矩阵乘法后可以方便的使用很多矩阵运算库(如MKL、openblas、Eigen等)。
openblas
GEMM 普通矩阵乘法(General Matrix Multiplication)多种优化
2、FFT变换。
时域卷积等于频域相乘,因此可将问题转化为简单的乘法问题。
3、Winograd。
这种不太熟悉,据说在GPU上效率更高。
NNPACK就是FFT和Winograd方法的结合。
上面三种方法执行效率都还不错,但对内存占用比较高,因为需要存储中间结果或者临时辅助变量。
1、Strassen 算法:
分析 CNN 的线性代数特性,增加加法减少乘法,
这样降低了卷积运算的计算的复杂度(o(n^3) -> o(n^2.81)),
但是这种方法不适合在硬件里面使用,这里就不做详细的介绍了。
2、 MEC:
一种内存利用率高且速度较快的卷积计算方法
MEC: Memory-efficient Convolution for Deep Neural Network 论文
快速矩阵乘法 分块矩阵乘法 Strassen算法 Coppersmith-Winograd算法
博客解析
openblas GEMM 矩阵乘法优化
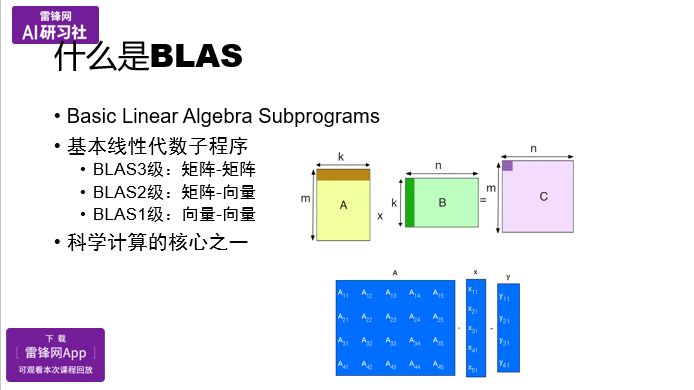
BLAS是 Basic Linear Algebra Subprograms (基本线性代数子程序)的首字母缩写,主要用来做基础的矩阵计算,或者是向量计算。它分为三级:
BLAS 1级,主要做向量与向量间的dot或乘加运算,对应元素的计算;
BLAS 2级,主要做矩阵和向量,就类似PPT中蓝色部分所示,矩阵A*向量x, 得到一个向量y。除此之外,可能还会有对称的矩阵变形;
BLAS 3级,主要是矩阵和矩阵的计算,最典型的是A矩阵*B矩阵,得到一个C矩阵。由矩阵的宽、高,得到一个m*n的C矩阵。
最原始3个for循环 (矩阵比较小的时候,速度还能快一些,当矩阵大了的时候,一定会跌下去,cache缓存问题):

矩阵分块,块复用,减少仿存,相当于减少内存访问,提高Cache利用率:

核心汇编优化:
- 寄存器分块
- SIMD指令
- 指令流水线优化,循环展开,重排,预取
操作寄存器,不是操作内存:
我可以申请一堆C 00,01这样的寄存器变量,在C语言中是register double,还有矩阵A的部分,也用寄存器变量。
当然B还是之前的方式,最后再写回C里面。
只是我们引入了寄存器变量,让更多的数据保存到寄存器里,而不是放到cache缓存里,来减轻cache的压力.

B矩阵仿存,使用指针访问,
一开始先把对应的指针位置指好,每次计算的时候只要指针连续移动就好,而不是每次读一个位置重新算一遍,这样速度就会快一些。

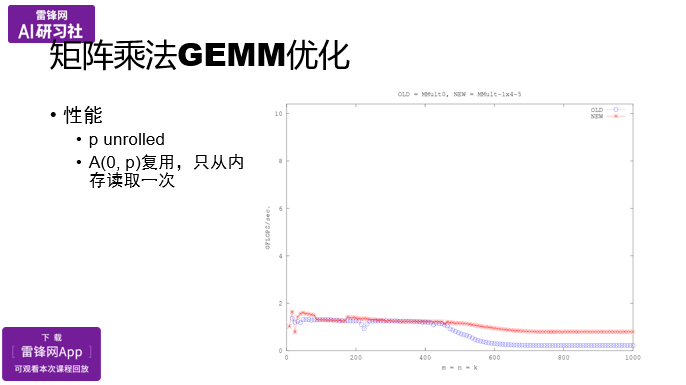
最里层循环展开:
在最里层循环,是不是可以展开成4次,在做这个的时候,我们可以降低整个循环这部分的开销,而且让它流水的情况更好。

通过使用寄存器变量,使用了指针,在做了一定的底层循环展开之后,达到了红色线的性能:
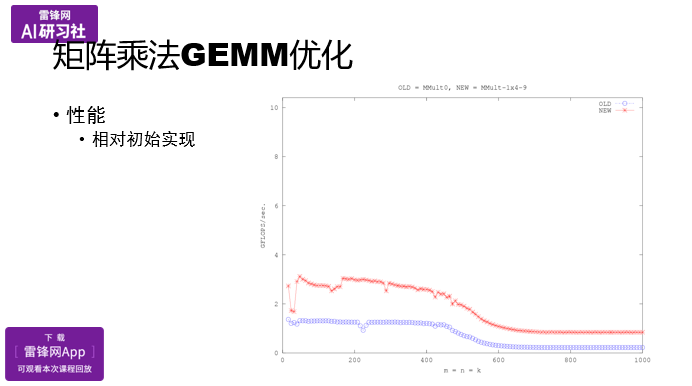
之后可以使用更大的分块,在进行寄存器,指针,展开优化。
高通SNPE 神经网络处理引擎(SNPE)
SNPE(Snapdragon Neural Processing Engine)是高通公司推出的面向移动端和物联网设备的深度学习推理框架。它充分利用了高通处理器的并行计算能力,为开发者提供更快的神经网络推理。通过SNPE,开发者可以更好地将模型部署在移动平台,既可以对不同的应用进行神经网络的开发、训练和实现,也能高效地使用CPU、GPU、DSP和NPU。
SNPE的基本工作流程包括将网络模型转换为可以被SNPE加载的DLC文件,可选择性地将DLC文件量化以在Hexagon DSP上运行,为模型准备输入数据,以及使用SNPE运行时加载和执行模型。
SNPE是一个面向AI和IoT开发者的工具,适合学生、对AI/IoT感兴趣的个人以及企业的相关技术人员使用。其包含的内容涵盖了神经网络转化、准备数据、网络推理、模型后量化等各个方面。
snpe-1.6.0/helper.md
可运行于搭载了高通Zeroth机器智能平台的820芯片处理器,开发者可以在SNPE上搭建自己的深度学习网络模型。更详细的介绍可以登录高通SNPE相关网页了解:https://developer.qualcomm.com/software/snapdragon-neural-processing-engine
高通提供了用户定义层(UDL)功能,通过回调函数可以自定义算子,并通过重编译C++代码将自定义文件编译到可执行文件中。如果开发就是使用的C++,那比较容易实现用户定义层,但如果是运行在Android上就比较麻烦了,上层java代码需要通过JNI来调用snpe原生的C++编译好的.so文件,因为用户定义层的代码是不可能预先编译到snpe原生.so文件中的,所以用snpe提供的Java
API是无法获得用户定义层的功能的,所以,必须重新开发SNPE的JNI。
使用SNPE,用户可以:
1.执行任意深度的神经网络
2.在SnapdragonTM CPU,AdrenoTM GPU或HexagonTM DSP上执行网络。
3.在x86 Ubuntu Linux上调试网络执行
4.将Caffe,Caffe2,ONNXTM和TensorFlowTM模型转换为SNPE深度学习容器(DLC)文件
5.将DLC文件量化为8位定点,以便在Hexagon DSP上运行
6.使用SNPE工具调试和分析网络性能
7.通过C ++或Java将网络集成到应用程序和其他代码中
模型训练在流行的深度学习框架上进行(SNPE支持Caffe,Caffe2,ONNX和TensorFlow模型。)训练完成后,训练的模型将转换为可加载到SNPE运行时的DLC文件。 然后,可以使用此DLC文件使用其中一个Snapdragon加速计算核心执行前向推断传递。
基本的SNPE工作流程只包含几个步骤:
1.将网络模型转换为可由SNPE加载的DLC文件。
2.可选择量化DLC文件以