感谢大家的阅读,这篇文章我们接着了解C++对于C的一些优化。
函数重载
了解C++这个特殊用法之前,我们先考虑一个问题,如何交换两个整数。相信大家一定信手捏来,实参传地址而非变量,于是可以写出如下函数。
void Swap(int* p1, int* p2)
{
int t = *p1;
*p1 = *p2;
*p2 = t;
}这段代码的逻辑也十分简单,但假如我们要交换两个浮点数呢?我们可以类似上面的思路,把整型改为浮点型写出如下的代码。但在C语言中函数名不可以相同,我们便要将函数名改变。
void SwapInt(int* p1, int* p2)
{
int t = *p1;
*p1 = *p2;
*p2 = t;
}
void SwapDouble(double* p1, double* p2)
{
double t = *p1;
*p1 = *p2;
*p2 = t;
}我们人的思维是直接的,交换两个数直接就是交换两数,而没考虑类型,但在C中因为传递的参数不同,就必须要设置为两个不同的函数。本贾尼祖师爷也深受其烦,想要优化这种代码,简化我们记忆和使用的负担,将复杂甩手给编译器,于是便有了函数重载的语法。
下面我们来看下函数重载的官方定义:函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这 些同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同。
于是在C++的语法中,上面的代码便可以写为如下形式。
void Swap(int* p1, int* p2)
{
int t = *p1;
*p1 = *p2;
*p2 = t;
}
void Swap(double* p1, double* p2)
{
double t = *p1;
*p1 = *p2;
*p2 = t;
}两个函数的名字都叫Swap,但是形参类型却不同。再函数调用的时候,他会根据函数实参的类型找到对应要调用的函数。
下面我们看待代码.
#include<iostream>
using namespace std;
void Swap(int* p1, int* p2)
{
int t = *p1;
*p1 = *p2;
*p2 = t;
}
void Swap(double* p1, double* p2)
{
double t = *p1;
*p1 = *p2;
*p2 = t;
}
int main()
{
int a = 10, b = 5;
double c = 1.21, d = 2.54;
cout << "交换前:" << a <<" " << b << endl;
Swap(&a, &b);
cout << "交换后:" << a << " " << b << endl;
cout << "交换前:" << c << " " << d << endl;
Swap(&c, &d);
cout << "交换后:" << c <<" "<< d << endl;
return 0;
}上面的代码运行结果如下

成功的输出了交换后的数字,并且没有报错,如果实在C语言的编译下,这一定是会报错的。但C++引入了函数重载的概念便可以这样写,大大简化了程序员记忆的负担。
根据函数重载的定义,函数的形参个数,类型或者顺序不同才可以构成重载。下面我们看段代码。
void fun(int a, char ch)
{
//…………
}
void fun(char ch,int a )
{
//…………
}
这两个函数构成重载么?
答案是他们构成重载因为他们的类型不同,尽管他们的形参个数类型相同!!
下面我们再看一段代码。
void fun(int a, char ch)
{
//…………
}
int fun(int a, char ch)
{
//…………
}上面的函数构成重载么?有的读者仔细看发现他们的返回值不一样,可能觉得他们就构成重载了,但这是错误的!!
上面的两个函数并不构成重载,原因很简单,判断是不是重载首先看函数名,其次看参数不看返回值。他们的函数名相同,参数的个数,顺序,类型也完全相同,故而不构成重载!!有的读者可能有些难以理解,返回值明明也可以作为判断依据,为什么不用呢?那么就继续往下读下一个小章节。
为什么C++支持函数重载,而C不支持函数重载
聊到这里我们要简单了解下程序运行的过程.我们都知道一个程序的运行包含很多步骤,可以分为 预处理,编译,汇编,链接,以至最后的输出。VS将 预处理,编译,汇编,链接封装运行,所以又被称为高度集成开发的IDE。Linux下便可以观察具体处理细节。每个步骤细节多,在这里我只能简单的介绍每个步骤的使用。
首先便是预处理,在这个阶段的核心任务是将头文件展开,注释的删除,预处理指令,刚开始的时候不同的.cpp文件是分开处理的。
紧接着是编译,这个时候对代码进行词义分析,语义分析,词法分析,将C代码转换为汇编代码。在这个时候有个·操作对于我们要讲的十分重要,便是汇总符号!!对于电脑而言,函数也不过是个符号罢了。
然后是汇编,他将汇编代码翻译为机器码,也就是一连串的二进制01序列,并且形成符号表。
最后一步是链接,将外部库的代码汇总到main.c文件中,同时将不同的.c文件内容汇总,其中便有符号表汇总,每个符号分配一个地址。
而我们在调用函数的时候,会首先对于函数名进行修饰然后在符号表中查找。下面我们看段C语言的代码
int Add(int a, int b)
{
return a + b;
}
void fun(int a,double b,int*p)
{
//…………
}利用Linux查看程序处理结果会得到如下函数名修饰

我们发现它经过处理的函数名只有函数名,没有参数的信息,假如换到cpp环境下呢?

我们可以明显的发现,函数名修饰后多了许多东西。按照我们实际参数的信息,不难反推出i就是int,pi就算是int*,c就是char,这样参数的信息就加入到了函数名中。当我们调用参数时,他就可以根据重载找到对应函数。我们就可以简单的理解为重载函数,只是在我们看起来是相同的函数,其实对于计算机而言他就是两个完全不同的函数!!
总结起来C不支持重载的原因是他在编译处理代码的时候没有将函数名加以形参的修饰,区别不出不同函数,而C++进行了对应的修饰,电脑可以识别出你要调用那个函数。
同时按照这个想法的话,我们把返回值也假如修饰函数名的队伍中也可以,但祖师爷当初设计C++的时候没有制定加入返回值的规则,返回值便不可以作为判断依据。当然祖师爷也有可能是觉得返回值区别的意义不大,便没有加了。我们在学习C++的语法规则中可以不断地问为什么?但一直没有靠谱的回答时,便可能时C++开发时的考虑。C语言完全可以加入函数重载,但那还是C语言么?每个语言都有其特定的优势与局限。
缺省参数
我们首先看下他的定义.
缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实 参则采用该形参的缺省值,否则使用指定的实参。他的使用也十分简单,如下图·。
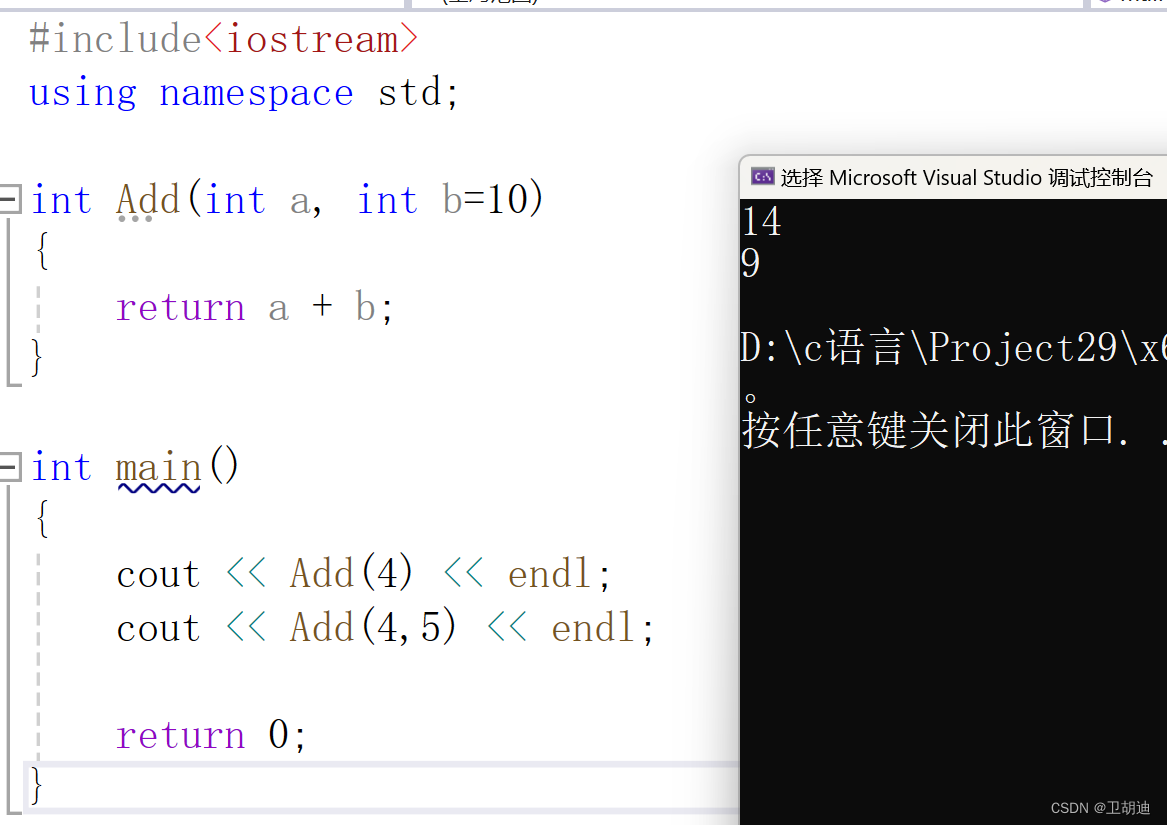
当我们调用Add函数的时候,由于b参数我们给了他一个初始值,我们便可以调用Add函数时只给她传递一个参数,那么b参数的值就是10,所以打印14.但如果我们传入两个参数,4,5那么b的值就为5,打印9.缺省参数的使用简化了我们记忆代码的负担,弥补了重载函数的一些不足。
他的语法十分简单,但有几点是我们需要特别注意的。
首先便是缺省参数必须从右往左依次给,不能跳跃,如下的代码都是错误的。
int Add(int a, int b=10,int c)
{
return a + b;
}
int Add(int a=10, int b )
{
return a + b;
}C++规定了实参与形参的匹配时从左往右依次匹配,他会默认缺省参数右边都是缺省参数。有的读者可能想从右往左匹配也可以,但C++制定的从左往右依次匹配,我们学习C++要遵守他的规则。
其次就是缺省参数不能在外部声明和定义时同时出现,当有声明时,缺省参数按照声明执行。如下图

缺省参数只需要在声明时给初始值,假如只有定义便在定义的时候给。否则就会重定义。
我们再看段有趣的代码。
#include<iostream>
using namespace std;
int Add()
{
return 0;
}
int Add(int a=5, int b=10)
{
return a + b;
}
int main()
{
cout << Add() << endl;
cout << Add(4,5) << endl;
return 0;
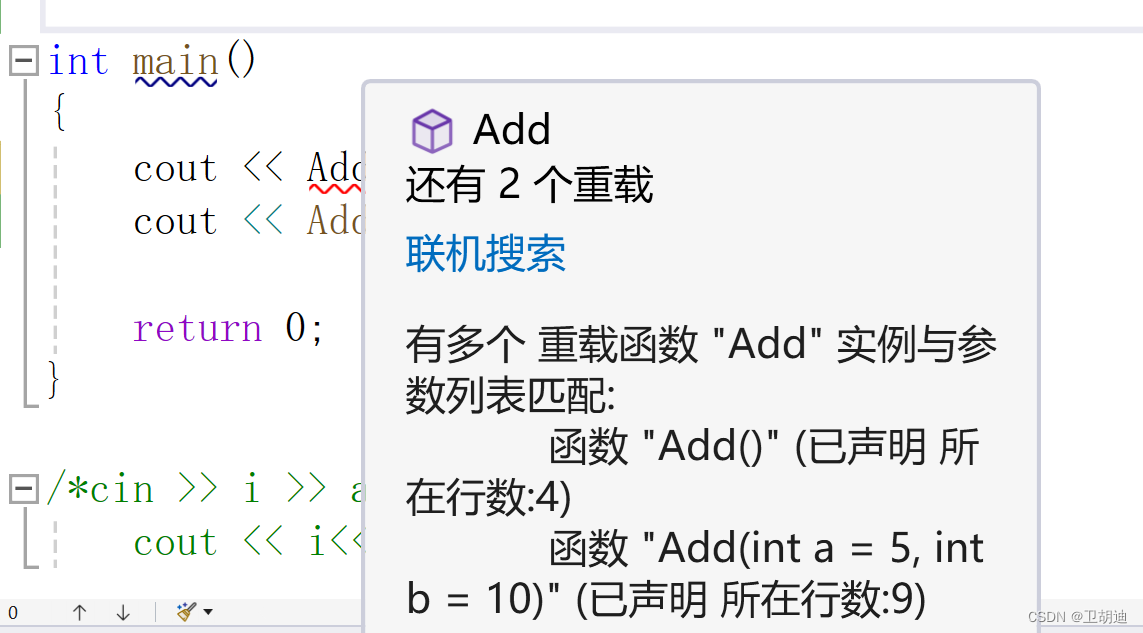
}上面的代码构成重载么?能运行么?
首先毫无疑问他们构成重载,他们的参数类型不同。但可以运行么?假如我们调用Add(),他似乎可以调用第一个,也可以调用第二个?我们要明白计算机是不允许有歧义的东西,对于·他来说,1就是1,0就是0.像这种产生了歧义的程序他不会运行,直接报错。
我们也可以看出他报错的理由是有多个匹配的重载。
今天的文章就到此结束了,喜欢的点点关注,如果有什么错误欢迎在评论区指出。