set
set是关联性容器
set的底层是在极端情况下都不会退化成单只的红黑树,也就是平衡树,本质是二叉搜索树.
set的性质:set的key是不允许被修改的
使用set需要包含头文件
set<int> s;
s.insert(1);
s.insert(1);
s.insert(1);
s.insert(1);
s.insert(2);
s.insert(56);
s.insert(7);
s.insert(7);
s.insert(7);
s.insert(3);
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
set<int>::iterator it = s.begin();
while (it != s.end())
{
cout << *it << " ";
it++;
}
cout << endl;
set中是没有重复的,重复的元素是无法插入set的,有时候去重可以选择使用set.可以避免使用去重算法.
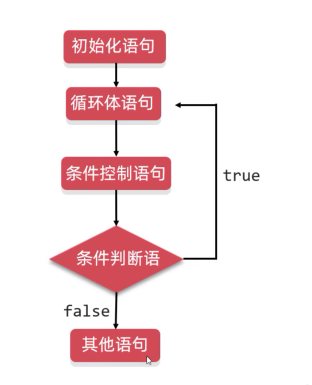
set的遍历方式:
- 迭代器
- 范围for(范围for的底层就就是迭代器.)
Find成员函数:
iterator find (const value_type& val) const;
Find函数找不到就返回set::end,指向最终的end迭代器.
set的Erase方法的参数是迭代器的时候:参数必须是有效的迭代器位置,否则会报错,当参数是一个key的时候,不管该值在不在都不会报错.
set的count函数:用于计算指定的元素的个数
size_type count (const value_type& val) const;lower_bound函数和upper_bound函数:
iterator lower_bound (const value_type& val) const; iterator upper_bound (const value_type& val) const;例如:要删除set中[3,5]的值,如何删除?
首先想到使用的是先一个一个找,接着使用erase进行删除,但是这个区间的断点值不一定存在.而且erase在删除不存在的迭代器的时候会报错,并且erase的删除区间是左闭右开的.而我们找不到这个的端点值.所以在想要删除某个闭区间的值的时候,我们使用erase,但是要给给erase提供左闭右开区间的迭代器的位置.左边闭区间的位置使用的是lower_bound提供,右边开区间的参数是upper_bound提供.接着将这个两个函数的返回值传递给erase即可.
注意:如果想要删除[3,8]的数,那么lower_bound和upper_bound的参数就要分别提供3和8
void test_set4() { set<int> s; s.insert(1); s.insert(2); s.insert(3); s.insert(4); s.insert(5); s.insert(6); s.insert(7); s.insert(8); // 删除[3,8] set<int>::iterator start = s.lower_bound(3); // >=val的最小值 set<int>::iterator finish = s.upper_bound(8); // >val最小值 s.erase(start, finish); for (auto e : s) { cout << e << " "; } }lower_bound和upper_bound用于查找某一段区间的元素.通过获取到左闭右开的区间,可以更好的遍历.
// 查找3-8之间的元素 void test_set5() { set<int> s; s.insert(1); s.insert(2); s.insert(3); s.insert(4); s.insert(5); s.insert(6); s.insert(7); s.insert(8); // 删除[3,8] set<int>::iterator start = s.lower_bound(3); // >=val的最小值 set<int>::iterator finish = s.upper_bound(8); // >val最小值 while (start != finish) { cout << *start << " "; start++; } }
multiset
multiset和set的用法类似.但是multiset只能排序,不能去重.multiset的底层遇见相同的值的节点的时候,会插入在已有的值的节点的左边或者是右边均可.最后经过旋转了之后结果都是一样的.
multiset的erase方法返回size_t时,此时就有意义了.
multiset的lower_bound和upper_bound函数的参数假如有多个的时候,一般都是返回指向在中序遍历中第一次出现的那个数的迭代器.Find也是同理.
map
map的结构上和set是完全相同的,但是map中插入数据要构造pair类.
map的特点:key是不能修改的,value能修改.
value_type就是pair,pair的key不能被修改.但是mapped_type是可以被修改的

pair<iterator,bool> insert (const value_type& val)
map结构数据的插入
map的节点中的数据都是pair,pair对象有两个成员,分别是first和second,first就是key_type,不可被修改,second是mapped_type,可被修改,插入数据的时候,也需要构造成pair再进行插入即可.
那么pair的构造函数长啥样呢?
| default (1) | pair(); |
|---|---|
| copy (2) | template<class U, class V> pair (const pair<U,V>& pr); |
| initialization (3) | pair (const first_type& a, const second_type& b); |
所以pair的构造方法:
pair<string,string> v("sort","排序"); //调用构造函数
pair<string,string> = {"right","右边"}; // C++11中新引入的多参数默认构造.
pair<string,string>("left","左边"); // pair的匿名对象
另一种构造pair的方法:
make_pair("integer","整形");
map<string, string> m;
m.insert(make_pair("sort","分类"));
m.insert(pair<string, string>("right", "右边"));
pair<string, string> p("left", "右边");
m.insert(p);
map结构数据的遍历
迭代器:
map中的迭代器也是指向的是pair对象,我们需要访问的值是pair对象的成员.map<string, string>::iterator begin = m.begin(); while (begin != m.end()) { cout << (*begin).first << " "; cout << (*begin).second << endl; // 也可以: // cout<<begin->first<<""; // cout<<begin->second<<endl; begin++; }范围for(这里最好是加上引用,否则拷贝代价很大)
for (auto& kv : m) { cout << kv.first << " "; cout << kv.second << endl; }
map的方括号

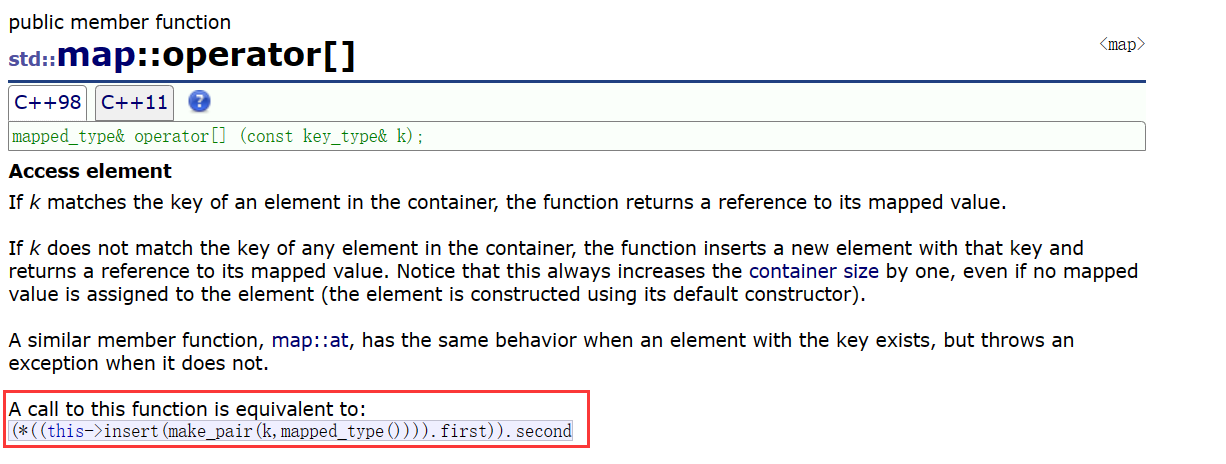
这里调用[]之后,相当于自动根据传入的参数和mapped_type的默认构造函数创建了一个pair,并调用insert将这个pair插入到map中,紧接着再获取到insert返回值的pair的第一个参数(通过后文可知,insert的返回值也是一个pair,并且这个pair的第一个参数的类型是map中的迭代器,第二个参数是一个bool类型的值),这个参数是一个迭代器,并且这个迭代器指向key的值为参数k的节点,这个节点中的存储的结构也是pair,最后将这个迭代器解引用,获取这个节点中的second值,也就是这个map中存储的pair中,key值为参数k的节点的第二个参数,
由上可见:[]重载的返回值是依赖于insert的返回值的,那么我们再去看看insert函数的返回值:

当使用向map插入一个pair时,这里会返回一个pair,这个返回的pair的对象的两个元素分别是:iterator和bool类型的.来看看对他们的说明吧:
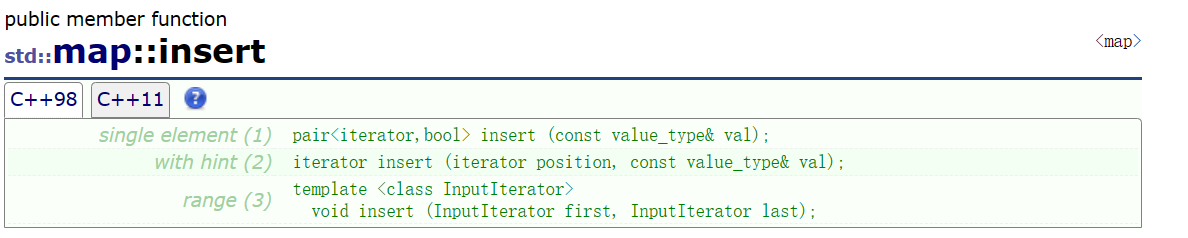

可见,当插入的值成功之后,iterator会指向这个新插入的pair,并且bool类型的参数的值为false,而当要被插入的值A在map中已经存在的时候,那么iterator会指向这个map中与A相同的key的pair对象.
insert函数用于查找元素
通过观察insert的返回值可见,由于返回值是一个pair类型,所以可以用insert函数来寻找特定的值是否存在,可将insert用于查找功能.假如要插入的值不存在,那么返回值pair的second的值就为true,假如要插入的值存在,那么返回值pair的second的值就是false.
来看一个案例:
使用map计算每种水果出现的次数:
**方法一:**利用普通的find函数和insert函数结合操作
int main() { map<string, int> m; string arr[] = { "西瓜","草莓","西瓜" }; for(auto& e:arr){ map<string,int>::iterator it = m.find(e); if(it!=m.end()){ // 不是第一次出现 it->second++; }else{ // 是第一次出现 m.insert(make_pair(e,1)); } } for(auto& e:m){ cout<<e.first<<" "; cout<<e.second<<endl; } return 0; }**方法二:**利用[]重载完成
int main() { map<string, int> m; string arr[] = { "西瓜","草莓","西瓜" }; for(auto& e:arr){ m[e]++; } for(auto& e:m){ cout<<e.first<<" "; cout<<e.second<<endl; } return 0; }方法三:利用insert的返回值完成:
int main() { string arr[] = { "西瓜","草莓","西瓜" }; map<string, int> m; pair<map<string, int>::iterator, bool> ret; for (auto& e : arr) { ret = m.insert(make_pair(e, 1)); if (ret.second) { // 插入成功,因为是第一次出现 } else { // 插入失败,因为已经出现过了 ret.first->second++; } } for (auto& e : m) { cout << e.first << " "; cout << e.second << endl; } return 0; }
map的[]能实现的4个功能
以后在map的函数中,使用的都是[]居多.因为[]的功能实在是太强大了.
- 插入
- 查找
- 修改
- 插入+修改
int main() { map<string, string> m; m["sort"]; // 插入元素 m["sort"] = "分类"; // 修改元素 cout << m["sort"] << endl;// 查找元素 m["right"] = "右边";// 插入+修改元素 return 0; }
map解决比较复杂的问题
138. 随机链表的复制 - 力扣(LeetCode)
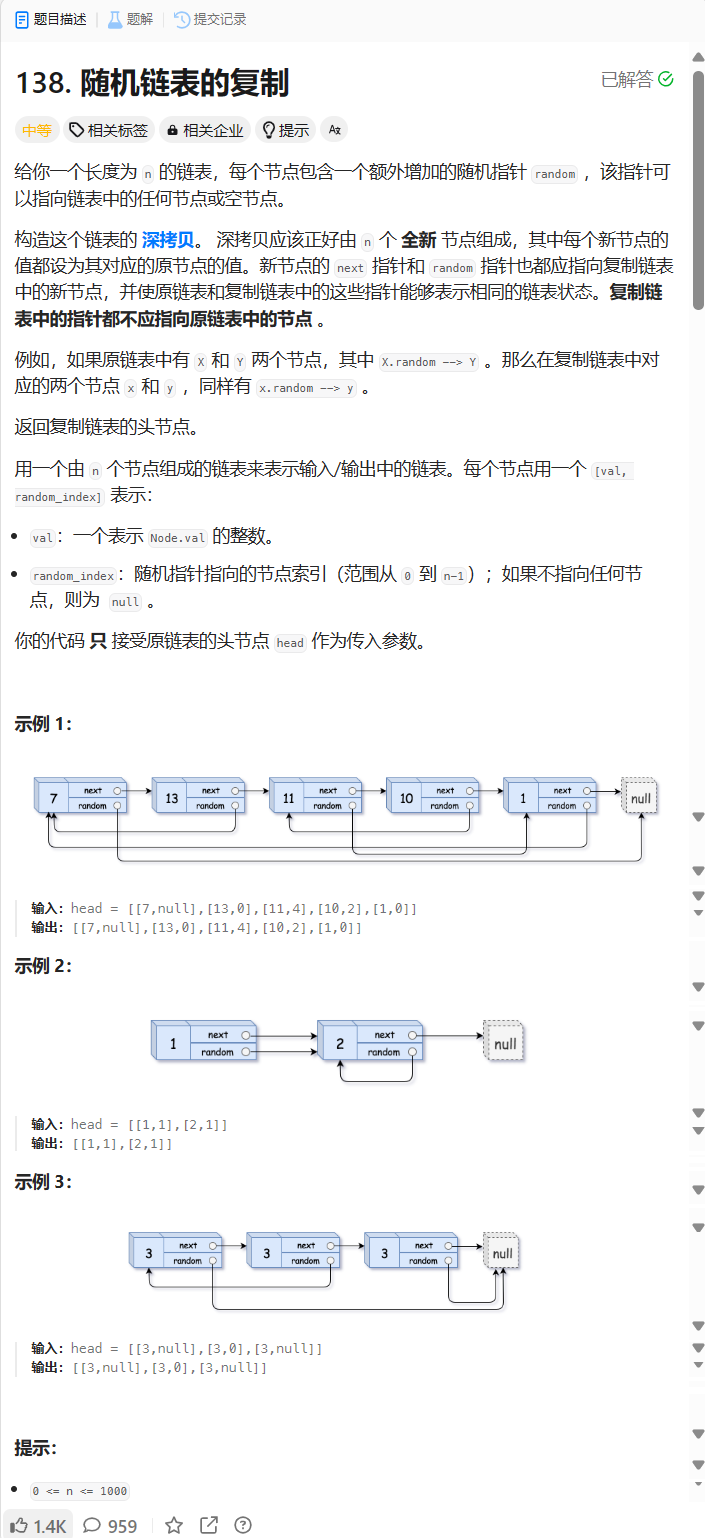
分析:
要做到深拷贝,我们可以首先使用一个map来保存原链表和新链表的节点之间的对应关系,在map中原链表和新链表的节点一一对应.这样在获取到了原链表的random的时候,这个原random节点也一定能够找到与之对应的random节点.
class Solution {
public:
Node* copyRandomList(Node* head) {
Node* newHead = nullptr;
Node* newTail = nullptr;
map<Node*,Node*> m;
Node* cur = head; // 从第一个链表的头开始遍历
while(cur)
{
// 假如是第一次连接
if(newHead == nullptr){
newHead = newTail = new Node(cur->val);
}else
{
// 不是第一次连接
newTail->next = new Node(cur->val);
newTail = newTail->next;
}
// newTail会依次指向新链表的每一个元素,新链表的random
m[cur] = newTail;
cur = cur->next;
}
cur = head;
Node* tail = newHead;
while(cur)
{
if(cur->random == nullptr){
tail->random = nullptr;
}else{
tail->random = m[cur->random];
}
cur = cur->next;
tail = tail->next;
}
return newHead;
}
};
349. 两个数组的交集 - 力扣(LeetCode)

寻找交集和差集比较中要的的算法思想:
定义两个迭代器,分别指向各自的set集合,迭代器从头开始遍历,并且比较两个迭代器指向的数据的大小,其中,小的数据,就是差集,接着让小的迭代器++,假如比较的数据相同,那么该值就是两个set的并集,此时两个迭代器都向后++,直到有一个迭代器走到了end位置.此时就找到了两个set的差集和交集.
方法一:
将两个数组存在在set中,去除重复元素之后,再看s1中的元素在s2中是否出现过.
class Solution { public: vector<int> intersection(vector<int>& nums1, vector<int>& nums2) { set<int> s1(nums1.begin(),nums1.end()); set<int> s2(nums2.begin(),nums2.end()); vector<int> ret; for(auto& e:s1){ // 在s2中是否出现过 if(s2.count(e)) { ret.push_back(e); } } return ret; } };方法二:
由于装入set集合中的数据都是有序的,所以使用两个迭代器分别指向两个set集合的开始,查看这两个迭代器指向的数据的大小,小的那个数据就是这两个set的差集,接着,小的那个迭代器++,大的迭代器不变,当两个相等时,此时所指向的数据就是两个set的交集.但是这种方法仅仅适用于数据时在有序的情况.这种方法可以同时寻找交集和并集,是一种很重要的思想.
class Solution { public: vector<int> intersection(vector<int>& nums1, vector<int>& nums2) { set<int> s1(nums1.begin(),nums1.end()); set<int> s2(nums2.begin(),nums2.end()); set<int>::iterator it1 = s1.begin(); set<int>::iterator it2 = s2.begin(); vector<int> ret; while(it1!=s1.end()&&it2!=s2.end()) { if((*it1)<(*it2)) { it1++; } else if((*it1)>(*it2)) { it2++; } else { ret.push_back(*it1); it1++; it2++; } } return ret; } };692. 前K个高频单词 - 力扣(LeetCode)

分析:
首先将数组存入
map<string,int> m的结构中,这里会默认按着key排序,也就是按着字符串的ascall码进行排序,但是我们想要的是按着出现的次数从大到小进行排序,所以我们需要将map中的元素存储在vector中,再对vector进行排序即可.注意sort函数的第三个参数,第三个这个参数是一个对象,就是一个比较器,这比较器是一个对象,并且对象要重载()方法,而且重载的这个()方法的返回值必须是bool类型的.前两个参数是比较的数据的类型,这里由于vector中存储的数据是pair类型.所以参数就是pair类型,返回的时候,假如前两个被比较的参数,符号是<,那么就是按着升序排列的,反之就是按着降序排列的.
class Cmp{ public: bool operator()(const pair<string,int>& kv1,const pair<string,int>& kv2){ return kv1.second > kv2.second; } }; class Solution { public: vector<string> topKFrequent(vector<string>& words, int k) { map<string,int> m; for(auto& e: words){ m[e]++; } vector<pair<string,int>> v(m.begin(),m.end()); stable_sort(v.begin(),v.end(),Cmp()); vector<string> ret; auto it = v.begin(); while(k--) { ret.push_back(it->first); it++; } return ret; } };
multimap
multimap和map的区别是:允许key的重复.
void test_map6()
{
multimap<string, string> m;
m.insert(make_pair("sort", "分类"));
m.insert(pair<string, string>("right", "右边"));
pair<string, string> p("left", "右边");
m.insert(p);
m.insert(p);
for (auto& e : m) {
cout << e.first << " ";
cout << e.second << endl;
}
}