Multi-Head Attention 代码实现
flyfish
MultiHead
(
Q
,
K
,
V
)
=
Concat
(
head
1
,
.
.
.
,
head
h
)
W
O
\text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, ..., \text{head}_h)W^O
MultiHead(Q,K,V)=Concat(head1,...,headh)WO
head
i
=
Attention
(
Q
W
i
Q
,
K
W
i
K
,
V
W
i
V
)
\text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V)
headi=Attention(QWiQ,KWiK,VWiV)
公式的另一种写法
h
e
a
d
i
=
Attention
(
Q
W
i
Q
,
K
W
i
K
,
V
W
i
V
)
MultiHead
(
Q
,
K
,
V
)
=
Concat
(
h
e
a
d
1
,
.
.
.
,
h
e
a
d
h
)
\begin{gather}head_i = \text{Attention}(\boldsymbol{Q}\boldsymbol{W}_i^Q,\boldsymbol{K}\boldsymbol{W}_i^K,\boldsymbol{V}\boldsymbol{W}_i^V)\\\text{MultiHead}(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = \text{Concat}(head_1,...,head_h)\end{gather}
headi=Attention(QWiQ,KWiK,VWiV)MultiHead(Q,K,V)=Concat(head1,...,headh)


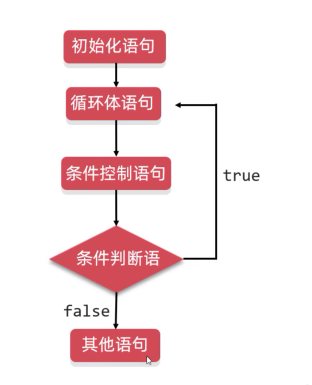
多头(Multi-head),其实就是多做几次 Scaled Dot-product Attention,然后把结果拼接
h1 = [1, 2, 3]
[4, 5, 6]
[7, 8, 9]
h2 = [10, 11, 12]
[13, 14, 15]
[16, 17, 18]
h3 = [19, 20, 21]
[22, 23, 24]
[25, 26, 27]
h_concatenate = [1, 2, 3, 10, 11, 12, 19, 20, 21]
[4, 5, 6, 13, 14, 15, 22, 23, 24]
[7, 8, 9, 16, 17, 18, 25, 26, 27]
第一种 写法
全部
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
import torch.nn.functional as F
import os
import math
def attention(query, key, value, mask=None, dropout=None):
# query的最后⼀维的⼤⼩, ⼀般情况下就等同于词嵌⼊维度, 命名为d_k
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
print("scores.shape:",scores.shape)#scores.shape: torch.Size([1, 12, 12])
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim = -1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(
torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model)
)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer("pe", pe)
def forward(self, x):
x = x + self.pe[:, : x.size(1)].requires_grad_(False)
return self.dropout(x)
#在测试attention的时候需要位置编码PositionalEncoding
import copy
def clones(module, N):
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
# 多头注意⼒机制的处理MultiHeadedAttention """head代表头数,embedding_dim代表词嵌入的维度"""
class MultiHeadedAttention(nn.Module):
def __init__(self, head, embedding_dim, dropout=0.1):
super(MultiHeadedAttention, self).__init__()
# 常⽤的assert语句,判断h是否能被d_model整除,
# 之后要给每个头分配等量的词特征.也就是embedding_dim/head个.
assert embedding_dim % head == 0
# 得到每个头获得的分割词向量维度d_k
self.d_k = embedding_dim // head
self.head = head
# 在多头注意⼒中,Q,K,V各需要⼀个,最后拼接的矩阵还需要⼀个,因此⼀共是四个.
self.linears = clones(nn.Linear(embedding_dim, embedding_dim), 4)
# self.attn为None,得到的注意⼒张量
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
# 如果存在掩码张量mask
if mask is not None:
mask = mask.unsqueeze(0)
batch_size = query.size(0)
query, key, value = \
[model(x).view(batch_size, -1, self.head, self.d_k).transpose(1,2) for model, x in zip(self.linears, (query, key, value))]
x, self.attn = attention(query, key, value, mask=mask,dropout=self.dropout)
x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.head *self.d_k)
return self.linears[-1](x)
# 词嵌⼊维度是8维
d_model = 512
# 置0⽐率为0.1
dropout = 0.1
# 句⼦最⼤⻓度
max_len=12
x = torch.zeros(1, max_len, d_model)
pe = PositionalEncoding(d_model, dropout, max_len)
pe_result = pe(x)
print("pe_result:", pe_result)
query = key = value = pe_result
print("pe_result.shape:",pe_result.shape)
#没有mask的输出情况
#pe_result.shape: torch.Size([1, 12, 8])
attn, p_attn = attention(query, key, value)
print("no mask\n")
print("attn:", attn)
print("p_attn:", p_attn)
#scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
# 除以math.sqrt(d_k) 表示这个注意力就是 缩放点积注意力,如果没有,那么就是 点积注意力
#当Q=K=V时,又叫⾃注意⼒机制
#有mask的输出情况
print("mask\n")
mask = torch.zeros(1, max_len, max_len)
attn, p_attn = attention(query, key, value, mask=mask)
print("attn:", attn)
print("p_attn:", p_attn)
#在测试attention的时候需要位置编码PositionalEncoding
# 头数head
head = 8
# 词嵌⼊维度embedding_dim
embedding_dim = d_model
mha = MultiHeadedAttention(head, embedding_dim, dropout)
print(mha)
mha_result = mha(query, key, value, mask)
print(mha_result)
第二种写法
全部
class _MultiheadAttention(nn.Module):
def __init__(self, hidden_size, n_heads, d_k=None, d_v=None,
res_attention=False, attn_dropout=0., proj_dropout=0., qkv_bias=True, lsa=False):
"""
Multi Head Attention Layer
Input shape:
Q: [batch_size (bs) x max_q_len x hidden_size]
K, V: [batch_size (bs) x q_len x hidden_size]
mask: [q_len x q_len]
"""
super().__init__()
d_k = hidden_size // n_heads if d_k is None else d_k
d_v = hidden_size // n_heads if d_v is None else d_v
self.n_heads, self.d_k, self.d_v = n_heads, d_k, d_v
self.W_Q = nn.Linear(hidden_size, d_k * n_heads, bias=qkv_bias)
self.W_K = nn.Linear(hidden_size, d_k * n_heads, bias=qkv_bias)
self.W_V = nn.Linear(hidden_size, d_v * n_heads, bias=qkv_bias)
# Scaled Dot-Product Attention (multiple heads)
self.res_attention = res_attention
self.sdp_attn = _ScaledDotProductAttention(hidden_size, n_heads, attn_dropout=attn_dropout,
res_attention=self.res_attention, lsa=lsa)
# Poject output
self.to_out = nn.Sequential(nn.Linear(n_heads * d_v, hidden_size), nn.Dropout(proj_dropout))
def forward(self, Q:torch.Tensor, K:Optional[torch.Tensor]=None, V:Optional[torch.Tensor]=None, prev:Optional[torch.Tensor]=None,
key_padding_mask:Optional[torch.Tensor]=None, attn_mask:Optional[torch.Tensor]=None):
bs = Q.size(0)
if K is None: K = Q
if V is None: V = Q
# Linear (+ split in multiple heads)
q_s = self.W_Q(Q).view(bs, -1, self.n_heads, self.d_k).transpose(1,2) # q_s : [bs x n_heads x max_q_len x d_k]
k_s = self.W_K(K).view(bs, -1, self.n_heads, self.d_k).permute(0,2,3,1) # k_s : [bs x n_heads x d_k x q_len] - transpose(1,2) + transpose(2,3)
v_s = self.W_V(V).view(bs, -1, self.n_heads, self.d_v).transpose(1,2) # v_s : [bs x n_heads x q_len x d_v]
# Apply Scaled Dot-Product Attention (multiple heads)
if self.res_attention:
output, attn_weights, attn_scores = self.sdp_attn(q_s, k_s, v_s,
prev=prev, key_padding_mask=key_padding_mask, attn_mask=attn_mask)
else:
output, attn_weights = self.sdp_attn(q_s, k_s, v_s, key_padding_mask=key_padding_mask, attn_mask=attn_mask)
# output: [bs x n_heads x q_len x d_v], attn: [bs x n_heads x q_len x q_len], scores: [bs x n_heads x max_q_len x q_len]
# back to the original inputs dimensions
output = output.transpose(1, 2).contiguous().view(bs, -1, self.n_heads * self.d_v) # output: [bs x q_len x n_heads * d_v]
output = self.to_out(output)
if self.res_attention: return output, attn_weights, attn_scores
else: return output, attn_weights
class _ScaledDotProductAttention(nn.Module):
"""
Scaled Dot-Product Attention module (Attention is all you need by Vaswani et al., 2017) with optional residual attention from previous layer
(Realformer: Transformer likes residual attention by He et al, 2020) and locality self sttention (Vision Transformer for Small-Size Datasets
by Lee et al, 2021)
"""
def __init__(self, hidden_size, n_heads, attn_dropout=0., res_attention=False, lsa=False):
super().__init__()
self.attn_dropout = nn.Dropout(attn_dropout)
self.res_attention = res_attention
head_dim = hidden_size // n_heads
self.scale = nn.Parameter(torch.tensor(head_dim ** -0.5), requires_grad=lsa)
self.lsa = lsa
def forward(self, q:torch.Tensor, k:torch.Tensor, v:torch.Tensor,
prev:Optional[torch.Tensor]=None, key_padding_mask:Optional[torch.Tensor]=None,
attn_mask:Optional[torch.Tensor]=None):
'''
Input shape:
q : [bs x n_heads x max_q_len x d_k]
k : [bs x n_heads x d_k x seq_len]
v : [bs x n_heads x seq_len x d_v]
prev : [bs x n_heads x q_len x seq_len]
key_padding_mask: [bs x seq_len]
attn_mask : [1 x seq_len x seq_len]
Output shape:
output: [bs x n_heads x q_len x d_v]
attn : [bs x n_heads x q_len x seq_len]
scores : [bs x n_heads x q_len x seq_len]
'''
# Scaled MatMul (q, k) - similarity scores for all pairs of positions in an input sequence
attn_scores = torch.matmul(q, k) * self.scale # attn_scores : [bs x n_heads x max_q_len x q_len]
# Add pre-softmax attention scores from the previous layer (optional)
if prev is not None: attn_scores = attn_scores + prev
# Attention mask (optional)
if attn_mask is not None: # attn_mask with shape [q_len x seq_len] - only used when q_len == seq_len
if attn_mask.dtype == torch.bool:
attn_scores.masked_fill_(attn_mask, -np.inf)
else:
attn_scores += attn_mask
# Key padding mask (optional)
if key_padding_mask is not None: # mask with shape [bs x q_len] (only when max_w_len == q_len)
attn_scores.masked_fill_(key_padding_mask.unsqueeze(1).unsqueeze(2), -np.inf)
# normalize the attention weights
attn_weights = F.softmax(attn_scores, dim=-1) # attn_weights : [bs x n_heads x max_q_len x q_len]
attn_weights = self.attn_dropout(attn_weights)
# compute the new values given the attention weights
output = torch.matmul(attn_weights, v) # output: [bs x n_heads x max_q_len x d_v]
if self.res_attention: return output, attn_weights, attn_scores
else: return output, attn_weights
第三种写法
全部
import math
import torch
from torch import nn
from d2l import torch as d2l
class MultiHeadAttention(nn.Module):
"""多头注意力"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
num_heads, dropout, bias=False, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = d2l.DotProductAttention(dropout)
self.W_q = nn.Linear(query_size, num_hiddens, bias=bias)
self.W_k = nn.Linear(key_size, num_hiddens, bias=bias)
self.W_v = nn.Linear(value_size, num_hiddens, bias=bias)
self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)
def forward(self, queries, keys, values, valid_lens):
# queries,keys,values的形状:
# (batch_size,查询或者“键-值”对的个数,num_hiddens)
# valid_lens 的形状:
# (batch_size,)或(batch_size,查询的个数)
# 经过变换后,输出的queries,keys,values 的形状:
# (batch_size*num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
queries = transpose_qkv(self.W_q(queries), self.num_heads)
keys = transpose_qkv(self.W_k(keys), self.num_heads)
values = transpose_qkv(self.W_v(values), self.num_heads)
if valid_lens is not None:
# 在轴0,将第一项(标量或者矢量)复制num_heads次,
# 然后如此复制第二项,然后诸如此类。
valid_lens = torch.repeat_interleave(
valid_lens, repeats=self.num_heads, dim=0)
# output的形状:(batch_size*num_heads,查询的个数,
# num_hiddens/num_heads)
output = self.attention(queries, keys, values, valid_lens)
# output_concat的形状:(batch_size,查询的个数,num_hiddens)
output_concat = transpose_output(output, self.num_heads)
return self.W_o(output_concat)
def transpose_qkv(X, num_heads):
"""为了多注意力头的并行计算而变换形状"""
# 输入X的形状:(batch_size,查询或者“键-值”对的个数,num_hiddens)
# 输出X的形状:(batch_size,查询或者“键-值”对的个数,num_heads,
# num_hiddens/num_heads)
X = X.reshape(X.shape[0], X.shape[1], num_heads, -1)
# 输出X的形状:(batch_size,num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
X = X.permute(0, 2, 1, 3)
# 最终输出的形状:(batch_size*num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
return X.reshape(-1, X.shape[2], X.shape[3])
def transpose_output(X, num_heads):
"""逆转transpose_qkv函数的操作"""
X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])
X = X.permute(0, 2, 1, 3)
return X.reshape(X.shape[0], X.shape[1], -1)
num_hiddens, num_heads = 100, 5
attention = MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens,
num_hiddens, num_heads, 0.5)
attention.eval()
batch_size, num_queries = 2, 4
num_kvpairs, valid_lens = 6, torch.tensor([3, 2])
X = torch.ones((batch_size, num_queries, num_hiddens))
Y = torch.ones((batch_size, num_kvpairs, num_hiddens))
attention(X, Y, Y, valid_lens).shape
多头(Multi-head),其实就是多做几次 Scaled Dot-product Attention,然后把结果拼接.
拼接结果然后再传给各个Decoder