RAPTOR:树结构的索引和检索系统的递归抽象处理-CSDN博客
原文地址:implementing-advanced-rag-in-langchain-using-raptor
2024 年 3 月 24 日
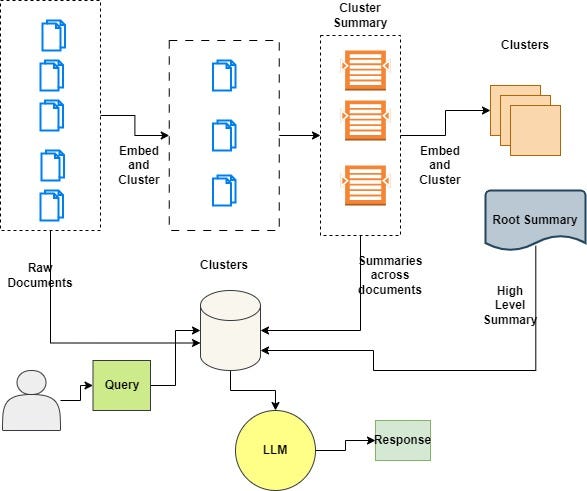
RAPTOR 简介
递归抽象处理树组织检索(RAPTOR)是种全新而强大的索引和检索技术,它全面适用于LLM。该方法采用自下而上的策略,通过聚类和汇总文本片段(块)来构建一个分层的树状结构。
RAPTOR 论文介绍了一种创新的文档索引和检索策略:
- 首先,将一组初始文档(单个文档的文本块或者完整文档)视为树的“叶子”。
- 这些叶子被嵌入并表示为向量,然后通过聚类算法进行分组。
- 接着,这些聚类被提炼为更高层次(更抽象)的信息,这些信息跨越相似的文档进行整合。
- 整个过程递归进行,形成了一棵从原始文档(叶子)到更抽象摘要的“树”。
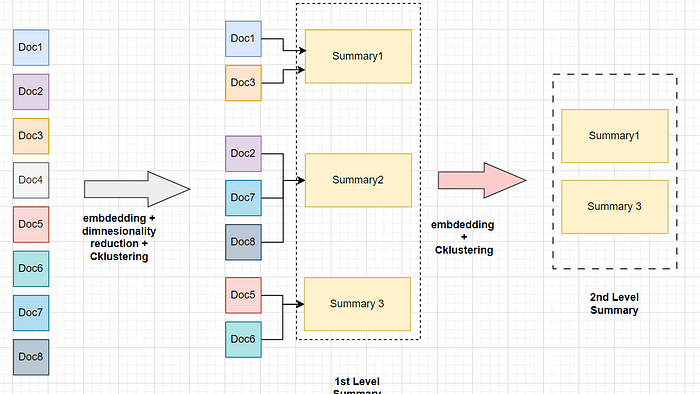
假设我们有来自于庞大手册的8个文档块,我们并不只是简单地对这些块进行嵌入并直接进行检索,而是首先将它们转换成向量形式,接着对这些高维向量进行降维处理。这样做是因为生成包含所有维度的簇会带来极高的计算成本,例如,在使用OpenAI的嵌入模型时,维度高达1536,而在使用常见的开源小型嵌入模型时,维度为384。
完成降维后,我们应用聚类算法对这些低维向量进行分组。接下来,我们收集每个聚类中的所有文档块,并对每个聚类的上下文进行总结。这样生成的摘要不仅反映了嵌入和聚类的结果,而且我们还重复这一过程,直到达到模型的令牌限制(即上下文窗口的大小)。
简而言之,RAPTOR方法的核心思想可以概括为:
- 聚类并总结相似的文档块。
- 将相关信息从相关文档中提取到摘要中。
- 为那些只需要少量上下文就能回答的问题提供支持。
LLM 应用技术栈
- Langchain
- llm :zephyr-7b-beta.Q4_K_M.gguf
- 嵌入模型 — thenlper/gte-small
- clustering 算法: GMM (Gaussian Mixture Model)
代码实现
安装所需的库
!pip install -U langchain umap-learn scikit-learn langchain_community tiktoken langchain-openai langchainhub chromadb
!CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 pip install -qU llama-cpp-python
import locale
def getpreferredencoding(do_setlocale = True):
return "UTF-8"
locale.getpreferredencoding = getpreferredencoding获取 Zephyr 模型参数文件
!wget "https://huggingface.co/TheBloke/zephyr-7B-beta-GGUF/resolve/main/zephyr-7b-beta.Q4_K_M.gguf"
实例化 LLM
from langchain_community.llms import LlamaCpp
from langchain_core.callbacks import CallbackManager, StreamingStdOutCallbackHandler
from langchain_core.prompts import PromptTemplate
# 放置在 GPU 上的层数,其余的将在 CPU 上进行,-1表示将所有层移至GPU。
n_gpu_layers = - 1
# 介于 1 和 n_ctx 之间,考虑 GPU 中的 VRAM 量。
n_batch = 512
# 回调支持 token-wise 流式处理
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])
model = LlamaCpp(
model_path="/content/zephyr-7b-beta.Q4_K_M.gguf",
n_gpu_layers=n_gpu_layers,
n_batch=n_batch,
temperature=0.75,
max_tokens=1000,
top_p=1,
n_ctx=35000,
callback_manager=callback_manager,
verbose=True, # Verbose is required to pass to the callback manager
)实例化嵌入模型
from langchain.vectorstores import Chroma
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores.utils import DistanceStrategy
EMBEDDING_MODEL_NAME = "thenlper/gte-small"
embd = HuggingFaceEmbeddings(
model_name=EMBEDDING_MODEL_NAME,
multi_process=True,
model_kwargs={"device": "cuda"},
encode_kwargs={"normalize_embeddings": True}, # set True for cosine similarity
)加载数据
使用LangChain的LCEL文档作为输入数据
import matplotlib.pyplot as plt
import tiktoken
from bs4 import BeautifulSoup as Soup
from langchain_community.document_loaders.recursive_url_loader import RecursiveUrlLoader
# 用于统计每个文本中 Token 数量的辅助函数
def num_tokens_from_string(string: str, encoding_name: str) -> int:
"""返回文本字符串中的令牌数量"""
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(string))
return num_tokens
# LCEL 文档
url = "https://python.langchain.com/docs/expression_language/"
loader = RecursiveUrlLoader(
url=url, max_depth=20, extractor=lambda x: Soup(x, "html.parser").text
)
docs = loader.load()
# LCEL w/ PydanticOutputParser (主要 LCEL 文档之外)
url = "https://python.langchain.com/docs/modules/model_io/output_parsers/quick_start"
loader = RecursiveUrlLoader(
url=url, max_depth=1, extractor=lambda x: Soup(x, "html.parser").text
)
docs_pydantic = loader.load()
# LCEL w/ Self Query (主要 LCEL 文档之外)
url = "https://python.langchain.com/docs/modules/data_connection/retrievers/self_query/"
loader = RecursiveUrlLoader(
url=url, max_depth=1, extractor=lambda x: Soup(x, "html.parser").text
)
docs_sq = loader.load()
# 文档文本
docs.extend([*docs_pydantic, *docs_sq])
docs_texts = [d.page_content for d in docs]通过计算每个文档的标记数量来检查我们的原始文档有多大,并使用直方图进行可视化
counts = [num_tokens_from_string(d, "cl100k_base") for d in docs_texts]
# 绘制标记计数的直方图
plt.figure(figsize=(10, 6))
plt.hist(counts, bins=30, color="blue", edgecolor="black", alpha=0.7)
plt.title("Histogram of Token Counts")
plt.xlabel("Token Count")
plt.ylabel("Frequency")
plt.grid(axis="y", alpha=0.75)
# 显示直方图
plt.show()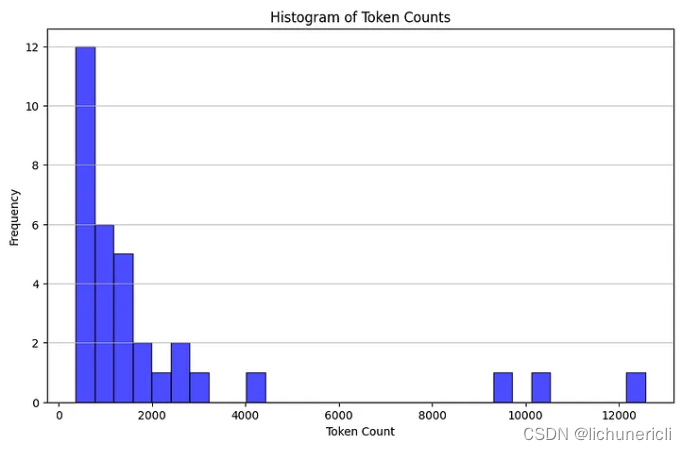
检查所有文档是否都适合我们文档的上下文窗口。
d_sorted = sorted(docs, key=lambda x: x.metadata["source"])
d_reversed = list(reversed(d_sorted))
concatenated_content = "\n\n\n --- \n\n\n".join(
[doc.page_content for doc in d_reversed]
)
print(
"Num tokens in all context: %s"
% num_tokens_from_string(concatenated_content, "cl100k_base")
)将文档分块以适合我们LLM的上下文窗口。
# 文档文本分割
from langchain_text_splitters import RecursiveCharacterTextSplitter
chunk_size_tok = 1000
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=chunk_size_tok, chunk_overlap=0
)
texts_split = text_splitter.split_text(concatenated_content)
print(f"Number of text splits generated: {len(texts_split)}")生成全局嵌入列表,它包含每个块的语义嵌入。
global_embeddings = [embd.embed_query(txt) for txt in texts_split]
print(len(global_embeddings[0])通过将维度从 384 减少到 2 并可视化嵌入来生成减少的簇。
import matplotlib.pyplot as plt
from typing import Optional
import numpy as np
import umap
def reduce_cluster_embeddings(
embeddings: np.ndarray,
dim: int,
n_neighbors: Optional[int] = None,
metric: str = "cosine",
) -> np.ndarray:
if n_neighbors is None:
n_neighbors = int((len(embeddings) - 1) ** 0.5)
return umap.UMAP(
n_neighbors=n_neighbors, n_components=dim, metric=metric
).fit_transform(embeddings)
dim = 2
global_embeddings_reduced = reduce_cluster_embeddings(global_embeddings, dim)
print(global_embeddings_reduced[0])
plt.figure(figsize=(10, 8))
plt.scatter(global_embeddings_reduced[:, 0], global_embeddings_reduced[:, 1], alpha=0.5)
plt.title("Global Embeddings")
plt.xlabel("Dimension 1")
plt.ylabel("Dimension 2")
plt.show()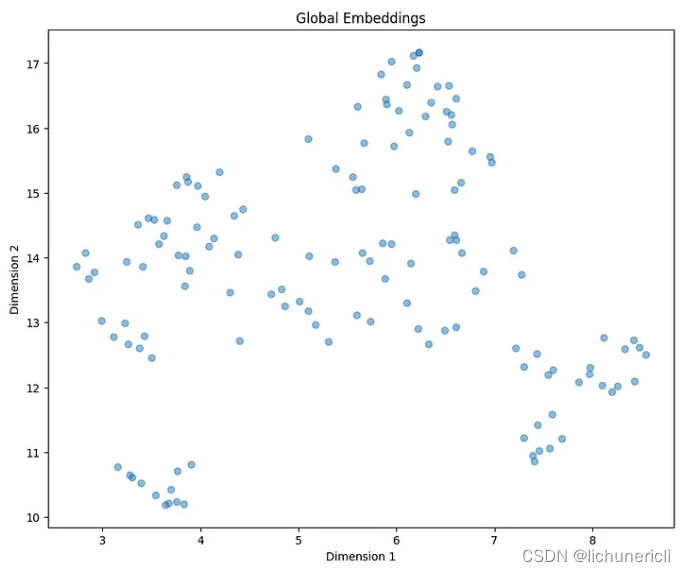
构建树
树构建过程中采用的聚类方法蕴含着几个引人入胜的创意。
GMM(高斯混合模型)
- 对不同集群中数据点的分布进行建模
- 通过评估模型的贝叶斯信息准则 (BIC) 来确定最佳簇数
UMAP(均匀流形逼近和投影)
- 支持集群
- 降低高维数据的维数
- UMAP 有助于突出显示数据点基于相似性的自然分组
本地和全局集群
- 用于分析不同尺度的数据
- 有效捕获数据中的细粒度和更广泛的模式
阈值化
- 在 GMM 上下文中应用以确定集群成员资格
- 基于概率分布(将数据点分配给 ≥ 1 个簇)
import matplotlib.pyplot as plt
import numpy as np
from sklearn.mixture import GaussianMixture
def get_optimal_clusters(embeddings: np.ndarray, max_clusters: int = 50, random_state: int = 1234):
max_clusters = min(max_clusters, len(embeddings))
bics = [GaussianMixture(n_components=n, random_state=random_state).fit(embeddings).bic(embeddings)
for n in range(1, max_clusters)]
return np.argmin(bics) + 1
def gmm_clustering(embeddings: np.ndarray, threshold: float, random_state: int = 0):
n_clusters = get_optimal_clusters(embeddings)
gm = GaussianMixture(n_components=n_clusters, random_state=random_state).fit(embeddings)
probs = gm.predict_proba(embeddings)
labels = [np.where(prob > threshold)[0] for prob in probs]
return labels, n_clusters
labels, _ = gmm_clustering(global_embeddings_reduced, threshold=0.5)
plot_labels = np.array([label[0] if len(label) > 0 else -1 for label in labels])
plt.figure(figsize=(10, 8))
unique_labels = np.unique(plot_labels)
colors = plt.cm.rainbow(np.linspace(0, 1, len(unique_labels)))
for label, color in zip(unique_labels, colors):
mask = plot_labels == label
plt.scatter(global_embeddings_reduced[mask, 0], global_embeddings_reduced[mask, 1], color=color, label=f'Cluster {label}', alpha=0.5)
plt.title("Cluster Visualization of Global Embeddings")
plt.xlabel("Dimension 1")
plt.ylabel("Dimension 2")
plt.legend()
plt.show()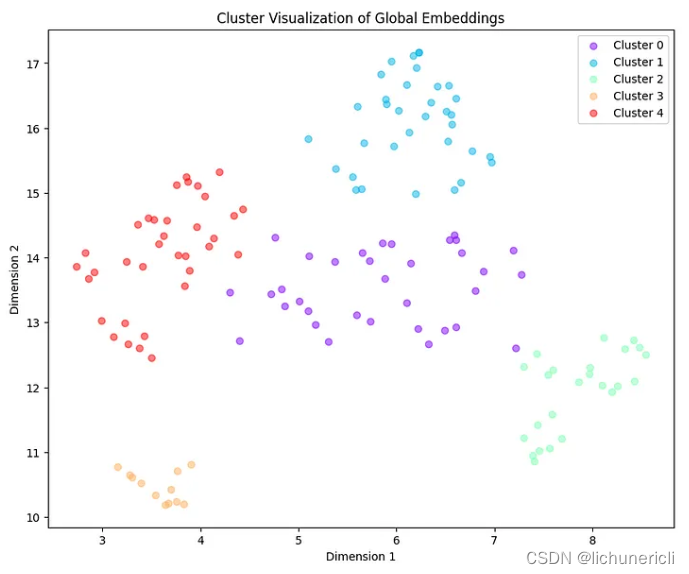
创建数据框来检查与每个集群关联的文本。
import pandas as pd
simple_labels = [label[0] if len(label) > 0 else -1 for label in labels]
df = pd.DataFrame({
'Text': texts_split,
'Embedding': list(global_embeddings_reduced),
'Cluster': simple_labels
})
print(df.head(3))
def format_cluster_texts(df):
clustered_texts = {}
for cluster in df['Cluster'].unique():
cluster_texts = df[df['Cluster'] == cluster]['Text'].tolist()
clustered_texts[cluster] = " --- ".join(cluster_texts)
return clustered_texts
#
clustered_texts = format_cluster_texts(df)定义 RAPTOR 辅助函数
from typing import Dict, List, Optional, Tuple
import numpy as np
import pandas as pd
import umap
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from sklearn.mixture import GaussianMixture
RANDOM_SEED = 224 # Fixed seed for reproducibility
def global_cluster_embeddings(
embeddings: np.ndarray,
dim: int,
n_neighbors: Optional[int] = None,
metric: str = "cosine",
) -> np.ndarray:
"""
使用 UMAP 对嵌入执行全局降维。
参数:
- embeddings:作为 numpy 数组的输入嵌入。
- dim:缩减空间的目标维度。
- n_neighbors:可选;数字每个点要考虑的邻居数。如果未提供,则默认为嵌入数量的平方根。
- metric:用于 UMAP 的距离度量。
返回:
- 减少到指定维度的嵌入的 numpy 数组。
"""
if n_neighbors is None:
n_neighbors = int((len(embeddings) - 1) ** 0.5)
return umap.UMAP(
n_neighbors=n_neighbors, n_components=dim, metric=metric
).fit_transform(embeddings)
def local_cluster_embeddings(
embeddings: np.ndarray, dim: int, num_neighbors: int = 10, metric: str = "cosine"
) -> np.ndarray:
"""
使用 UMAP 对嵌入执行局部降维,通常在全局聚类之后。
参数:
- embeddings:作为 numpy 数组的输入嵌入。
- dim:缩减空间的目标维度。
- num_neighbors:每个点要考虑的邻居数量。
- metric:用于 UMAP 的距离度量。
返回:
- 减少到指定维度的嵌入的 numpy 数组。
"""
return umap.UMAP(
n_neighbors=num_neighbors, n_components=dim, metric=metric
).fit_transform(embeddings)
def get_optimal_clusters(
embeddings: np.ndarray, max_clusters: int = 50, random_state: int = RANDOM_SEED
) -> int:
"""
使用贝叶斯信息准则 (BIC) 和高斯混合模型确定最佳簇数。
参数:
- embeddings:作为 numpy 数组的输入嵌入。
- max_clusters:要考虑的最大簇数。
- random_state:可重复性的种子。
返回:
- 表示找到的最佳簇数的整数。
"""
max_clusters = min(max_clusters, len(embeddings))
n_clusters = np.arange(1, max_clusters)
bics = []
for n in n_clusters:
gm = GaussianMixture(n_components=n, random_state=random_state)
gm.fit(embeddings)
bics.append(gm.bic(embeddings))
return n_clusters[np.argmin(bics)]
def GMM_cluster(embeddings: np.ndarray, threshold: float, random_state: int = 0):
"""
使用高斯聚类嵌入基于概率阈值的混合模型 (GMM)。
参数:
- embeddings:作为 numpy 数组的输入嵌入。
- 阈值:将嵌入分配给簇的概率阈值。
- random_state:可重复性的种子。
返回:
- 包含聚类标签和确定的聚类数量的元组。
"""
n_clusters = get_optimal_clusters(embeddings)
gm = GaussianMixture(n_components=n_clusters, random_state=random_state)
gm.fit(embeddings)
probs = gm.predict_proba(embeddings)
labels = [np.where(prob > threshold)[0] for prob in probs]
return labels, n_clusters
def perform_clustering(
embeddings: np.ndarray,
dim: int,
threshold: float,
) -> List[np.ndarray]:
"""
通过首先全局降低嵌入的维数,然后使用高斯混合模型进行聚类,最后对嵌入进行聚类在每个全局聚类中执行局部聚类。
参数:
- embeddings:作为 numpy 数组的输入嵌入。
- dim:UMAP 缩减的目标维数。
- Threshold:在 GMM 中将嵌入分配给聚类的概率阈值。
返回:
- numpy 数组列表,其中每个数组包含每个嵌入的簇 ID。
"""
if len(embeddings) <= dim + 1:
# Avoid clustering when there's insufficient data
return [np.array([0]) for _ in range(len(embeddings))]
# Global dimensionality reduction
reduced_embeddings_global = global_cluster_embeddings(embeddings, dim)
# Global clustering
global_clusters, n_global_clusters = GMM_cluster(
reduced_embeddings_global, threshold
)
all_local_clusters = [np.array([]) for _ in range(len(embeddings))]
total_clusters = 0
# Iterate through each global cluster to perform local clustering
for i in range(n_global_clusters):
# Extract embeddings belonging to the current global cluster
global_cluster_embeddings_ = embeddings[
np.array([i in gc for gc in global_clusters])
]
if len(global_cluster_embeddings_) == 0:
continue
if len(global_cluster_embeddings_) <= dim + 1:
# Handle small clusters with direct assignment
local_clusters = [np.array([0]) for _ in global_cluster_embeddings_]
n_local_clusters = 1
else:
# Local dimensionality reduction and clustering
reduced_embeddings_local = local_cluster_embeddings(
global_cluster_embeddings_, dim
)
local_clusters, n_local_clusters = GMM_cluster(
reduced_embeddings_local, threshold
)
# Assign local cluster IDs, adjusting for total clusters already processed
for j in range(n_local_clusters):
local_cluster_embeddings_ = global_cluster_embeddings_[
np.array([j in lc for lc in local_clusters])
]
indices = np.where(
(embeddings == local_cluster_embeddings_[:, None]).all(-1)
)[1]
for idx in indices:
all_local_clusters[idx] = np.append(
all_local_clusters[idx], j + total_clusters
)
total_clusters += n_local_clusters
return all_local_clusters
def embed(texts):
"""
为文本文档列表生成嵌入。
此函数假设存在 `embd` 对象,其方法 `embed_documents`
接受文本列表并返回其嵌入。
参数:
- texts:List[str],要嵌入的文本文档列表。
返回:
- numpy.ndarray:嵌入数组
"""
text_embeddings = embd.embed_documents(texts)
text_embeddings_np = np.array(text_embeddings)
return text_embeddings_np
def embed_cluster_texts(texts):
"""
嵌入文本列表并对它们进行聚类,返回包含文本的DataFrame 、它们的嵌入和聚类标签。
该函数将嵌入生成和聚类合并为一个步骤。它假设存在先前定义的“perform_clustering”函数,该函数对嵌入执行聚类。
参数:
- texts:List[str],要处理的文本文档列表。
返回:
- pandas.DataFrame:包含原始文本、其嵌入以及分配的簇标签的 DataFrame。
"""
text_embeddings_np = embed(texts) # Generate embeddings
cluster_labels = perform_clustering(
text_embeddings_np, 10, 0.1
) # Perform clustering on the embeddings
df = pd.DataFrame() # Initialize a DataFrame to store the results
df["text"] = texts # Store original texts
df["embd"] = list(text_embeddings_np) # Store embeddings as a list in the DataFrame
df["cluster"] = cluster_labels # Store cluster labels
return df
def fmt_txt(df: pd.DataFrame) -> str:
"""
将 DataFrame 中的文本文档格式化为单个字符串.
参数:
- df:包含要格式化的文本文档的 'text' 列的 DataFrame。
返回:
- 所有文本文档均由特定分隔符连接的单个字符串。
"""
unique_txt = df["text"].tolist()
return "--- --- \n --- --- ".join(unique_txt)
def embed_cluster_summarize_texts(
texts: List[str], level: int
) -> Tuple[pd.DataFrame, pd.DataFrame]:
"""
嵌入、聚类和总结文本列表。此函数首先生成文本的嵌入,
根据相似性对它们进行聚类,扩展聚类分配以便于处理,然后总结每个聚类内的内容。
参数:
- texts:要处理的文本文档列表。
- level:一个整数参数,可以定义处理的深度或细节。
返回:
- 包含两个 DataFrame 的元组:
1. 第一个 DataFrame (`df_clusters`) 包含原始文本、它们的嵌入和聚类分配。
2. 第二个 DataFrame (`df_summary`) 包含每个集群的摘要、指定的详细级别以及集群标识符。
"""
# Embed and cluster the texts, resulting in a DataFrame with 'text', 'embd', and 'cluster' columns
df_clusters = embed_cluster_texts(texts)
# Prepare to expand the DataFrame for easier manipulation of clusters
expanded_list = []
# Expand DataFrame entries to document-cluster pairings for straightforward processing
for index, row in df_clusters.iterrows():
for cluster in row["cluster"]:
expanded_list.append(
{"text": row["text"], "embd": row["embd"], "cluster": cluster}
)
# Create a new DataFrame from the expanded list
expanded_df = pd.DataFrame(expanded_list)
# Retrieve unique cluster identifiers for processing
all_clusters = expanded_df["cluster"].unique()
print(f"--Generated {len(all_clusters)} clusters--")
# Summarization
template = """Here is a sub-set of LangChain Expression Langauge doc.
LangChain Expression Langauge provides a way to compose chain in LangChain.
Give a detailed summary of the documentation provided.
Documentation:
{context}
"""
prompt = ChatPromptTemplate.from_template(template)
chain = prompt | model | StrOutputParser()
# Format text within each cluster for summarization
summaries = []
for i in all_clusters:
df_cluster = expanded_df[expanded_df["cluster"] == i]
formatted_txt = fmt_txt(df_cluster)
summaries.append(chain.invoke({"context": formatted_txt}))
# Create a DataFrame to store summaries with their corresponding cluster and level
df_summary = pd.DataFrame(
{
"summaries": summaries,
"level": [level] * len(summaries),
"cluster": list(all_clusters),
}
)
return df_clusters, df_summary
def recursive_embed_cluster_summarize(
texts: List[str], level: int = 1, n_levels: int = 3
) -> Dict[int, Tuple[pd.DataFrame, pd.DataFrame]]:
"""
递归地嵌入、聚类和汇总文本,直到指定级别或直到唯一聚类的数量变为 1,存储每个级别的结果。
参数:
- texts:List[str],要处理的文本。
- level:int,当前递归级别(从1开始)。
- n_levels:int,最大递归深度。
返回:
- Dict[int, Tuple[pd.DataFrame, pd.DataFrame]],一个字典,其中键是递归级别,值是包含该级别的簇 DataFrame 和摘要 DataFrame 的元组。
"""
results = {} # Dictionary to store results at each level
# Perform embedding, clustering, and summarization for the current level
df_clusters, df_summary = embed_cluster_summarize_texts(texts, level)
# Store the results of the current level
results[level] = (df_clusters, df_summary)
# Determine if further recursion is possible and meaningful
unique_clusters = df_summary["cluster"].nunique()
if level < n_levels and unique_clusters > 1:
# Use summaries as the input texts for the next level of recursion
new_texts = df_summary["summaries"].tolist()
next_level_results = recursive_embed_cluster_summarize(
new_texts, level + 1, n_levels
)
# Merge the results from the next level into the current results dictionary
results.update(next_level_results)
return results
构建树
leaf_texts = docs_texts
results = recursive_embed_cluster_summarize(leaf_texts, level=1, n_levels=3)生成最终摘要
此步骤很大程度上取决于我们如何从向量存储中检索文档。基本上有两种选择。
- 树遍历检索

树遍历从树的根级别开始,并根据向量嵌入的余弦相似度检索节点的前 k 个文档。因此,在每个级别,它都会从子节点检索前 k 个文档。
2. 倒塌树检索
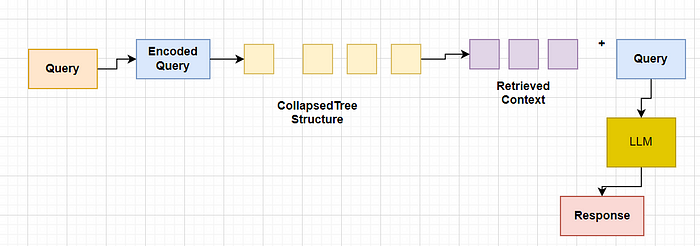
折叠树检索是一种更简单的方法。它将所有树折叠成单层并检索节点,直到基于查询向量的余弦相似度达到令牌的阈值数量。
在我们的代码中,我们将提取数据框文本、集群文本、最终摘要文本,并将它们组合起来创建一个包含根文档和摘要的大型文本列表。然后将该文本存储到矢量存储中。
# Initialize all_texts with leaf_texts
all_texts = leaf_texts.copy()
# Iterate through the results to extract summaries from each level and add them to all_texts
for level in sorted(results.keys()):
# Extract summaries from the current level's DataFrame
summaries = results[level][1]["summaries"].tolist()
# Extend all_texts with the summaries from the current level
all_texts.extend(summaries)
#Final Summaries extracted
print(all_texts)将文本加载到矢量存储中:构建索引
vectorstore = Chroma.from_texts(texts=all_texts, embedding=embd)
retriever = vectorstore.as_retriever()构建查询引擎
from langchain import hub
from langchain_core.runnables import RunnablePassthrough
# Prompt
prompt = hub.pull("rlm/rag-prompt")
# Post-processing
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# Chain
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)Langchain Hub RAG Prompt
print(prompt)
print(prompt.messages[0].prompt.template)Ask Query
response =rag_chain.invoke("What is LCEL?")
print(str(response))
response =rag_chain.invoke("How to define a RAG chain? Give me a specific code example.")Conclusion
在这里,我们使用了先进的检索技术RAPTOR来实现长上下文中的基于检索的生成(RAG)。