一、排序
排序算法是指将一组数据按照某种规则重新排列,使得数据呈现出递增或递减的顺序。常见的排序算法包括冒泡排序、选择排序、插入排序、快速排序、归并排序、堆排序等。
1.冒泡排序
解释: 冒泡排序通过不断交换相邻两个元素的位置,使较大的元素逐渐“浮”到数组的末尾。
# 冒泡排序函数
def bubble_sort(arr):
# 获取数组的长度
n = len(arr)
# 外层循环控制所有轮排序
for i in range(n):
# 内层循环负责相邻元素的比较和交换
for j in range(0, n - i - 1): # 只需要遍历到未排序部分的最后一个元素
# 如果当前元素大于下一个元素,则交换它们的位置
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
# print(arr)
"""
[34, 25, 12, 22, 11, 64, 90]
[25, 12, 22, 11, 34, 64, 90]
[12, 22, 11, 25, 34, 64, 90]
[12, 11, 22, 25, 34, 64, 90]
[11, 12, 22, 25, 34, 64, 90]
[11, 12, 22, 25, 34, 64, 90]
[11, 12, 22, 25, 34, 64, 90]
"""
# 定义一个待排序的数组
data = [64, 34, 25, 12, 22, 11, 90]
# 调用冒泡排序函数对数组进行排序
bubble_sort(data)
# 打印排序后的数组
print("冒泡排序后的结果:", data)2.选择排序
解释: 选择排序在每轮迭代中找到剩余未排序部分的最小(或最大)元素,将其与当前未排序部分的第一个元素交换位置。
def selection_sort(arr):
n = len(arr) # 获取数组的长度
for i in range(n): # 外层循环,控制排序的轮数
min_idx = i # 初始化最小元素的索引为当前轮次的起始索引
for j in range(i+1, n): # 内层循环,从当前轮次的下一个元素开始遍历到数组末尾
if arr[j] < arr[min_idx]: # 如果发现更小的元素
min_idx = j # 更新最小元素的索引
# 将找到的最小元素与当前轮次的起始位置的元素交换
arr[i], arr[min_idx] = arr[min_idx], arr[i]
# 示例数据
data = [64, 34, 25, 12, 22, 11, 90]
# 调用选择排序函数对数组进行排序
selection_sort(data)
# 打印排序后的数组
print("选择排序后的结果:", data)3.插入排序
解释: 插入排序将待排序数组分为已排序部分和未排序部分,每次从未排序部分取出一个元素,将其插入到已排序部分的正确位置。
def insertion_sort(arr):
# 从数组的第二个元素开始,将其与之前的元素比较并插入到正确的位置
for i in range(1, len(arr)):
# 取出当前要插入的元素,并保存其值
key = arr[i]
# 从当前元素的前一个元素开始比较
j = i - 1
# 当j指向的元素大于key,并且j没有越界时,执行循环
while j >= 0 and key < arr[j]:
# 将当前元素向后移动一位,为其后面的元素腾出位置
arr[j + 1] = arr[j]
# 继续与前一个元素比较
j -= 1
# 找到key的正确位置,将其插入
arr[j + 1] = key
# 示例数据
data = [64, 34, 25, 12, 22, 11, 90]
# 调用插入排序函数对数组进行排序
insertion_sort(data)
# 打印排序后的数组
print("插入排序后的结果:", data)4.快速排序
解释: 快速排序采用分治策略,选取一个基准元素,将数组分为两部分,使得基准左侧元素都不大于基准,右侧元素都不小于基准,然后对左右两部分递归进行快速排序。快速排序的平均时间复杂度是O(n log n),其中n是数组的长度。但在最坏情况下(例如数组已经是有序的),它的时间复杂度会退化到O(n^2)。在实际应用中,可以通过随机选择基准值或使用三数取中等技术来减少最坏情况发生的概率。
def quick_sort(arr):
# 如果数组长度小于等于1,则数组已经是排序好的,直接返回
if len(arr) <= 1:
return arr
# 选择一个基准值,这里选择数组中间的元素作为基准
pivot = arr[len(arr) // 2]
# 初始化左、中、右三个列表,用于存放小于、等于和大于基准值的元素
left = [x for x in arr if x < pivot] # 存放小于基准值的元素
middle = [x for x in arr if x == pivot] # 存放等于基准值的元素
right = [x for x in arr if x > pivot] # 存放大于基准值的元素
# 递归地对左列表和右列表进行快速排序,并将结果与中间的列表拼接起来
# 注意:这里是对左列表和右列表递归排序,而不是对原数组arr
return quick_sort(left) + middle + quick_sort(right)
# 示例数据
data = [64, 34, 25, 12, 22, 11, 90]
# 调用快速排序函数对数组进行排序
sorted_data = quick_sort(data)
# 打印排序后的数组
print("快速排序后的结果:", sorted_data)5.归并排序
解释: 归并排序同样采用分治策略,将数组不断二分为两半,对每一半递归进行归并排序,然后将两个已排序的半部分合并成一个有序数组。归并排序的时间复杂度是 O(n log n),其中 n 是数组的长度。它不受输入数据的影响,是一种稳定的排序算法。
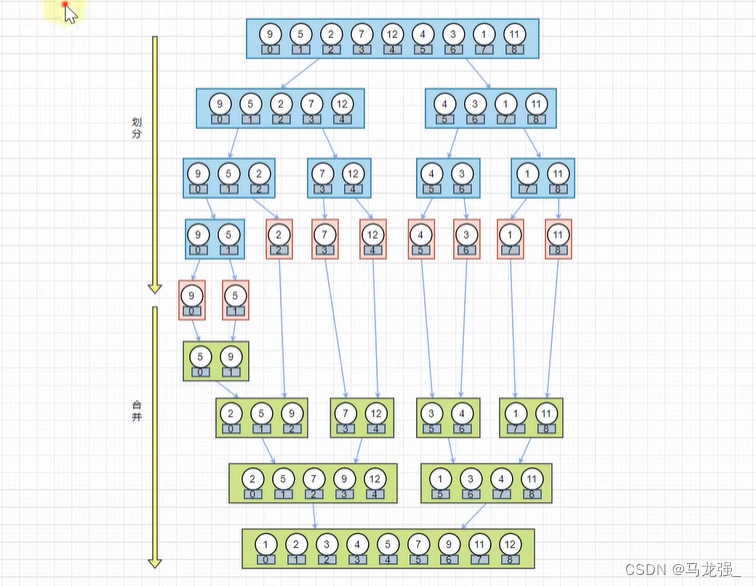
def merge_sort(arr):
# 如果数组长度小于等于1,那么它已经是有序的,直接返回
if len(arr) <= 1:
return arr
# 找到数组的中间位置
mid = len(arr) // 2
# 递归地对左半部分数组进行归并排序
left = merge_sort(arr[:mid])
# 递归地对右半部分数组进行归并排序
right = merge_sort(arr[mid:])
# 将两个已排序的数组合并成一个有序数组
return merge(left, right)
def merge(left, right):
# 创建一个空列表,用于存放合并后的结果
merged = []
# 初始化两个指针,分别指向左数组和右数组的开始位置
i = j = 0
# 当两个数组都还有元素时,进行合并操作
while i < len(left) and j < len(right):
# 比较两个数组当前指针所指向的元素大小,将较小的元素添加到merged中
if left[i] <= right[j]:
merged.append(left[i])
i += 1
else:
merged.append(right[j])
j += 1
# 将左数组剩余的元素添加到merged中
merged.extend(left[i:])
# 将右数组剩余的元素添加到merged中
merged.extend(right[j:])
# 返回合并后的有序数组
return merged
# 示例数据
data = [64, 34, 25, 12, 22, 11, 90]
# 调用归并排序函数对数组进行排序
sorted_data = merge_sort(data)
# 打印排序后的数组
print("归并排序后的结果:", sorted_data)6.堆排序
解释: 堆排序利用堆这种数据结构(一种特殊的完全二叉树),通过构建大顶堆或小顶堆,并反复调整堆结构,将最大(或最小)元素放到数组末尾,再重新调整剩余部分为堆,重复此过程直到数组完全有序。
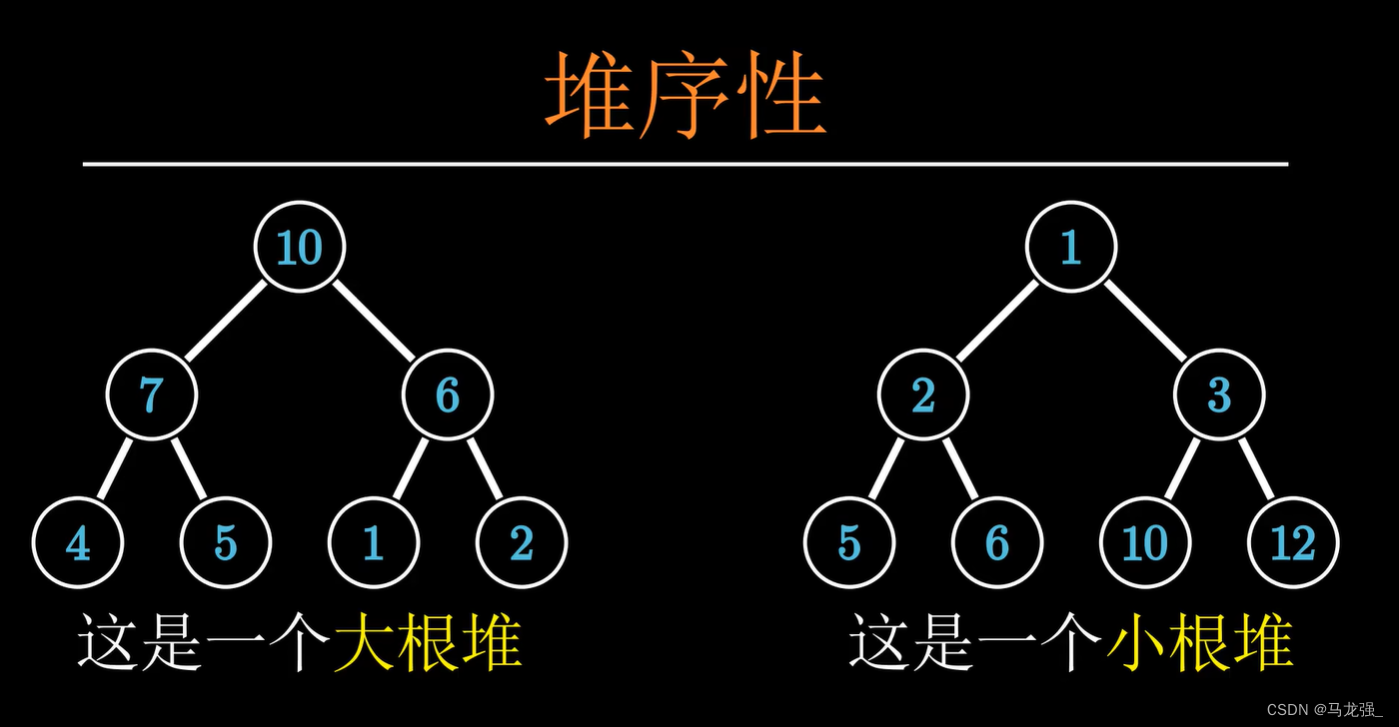
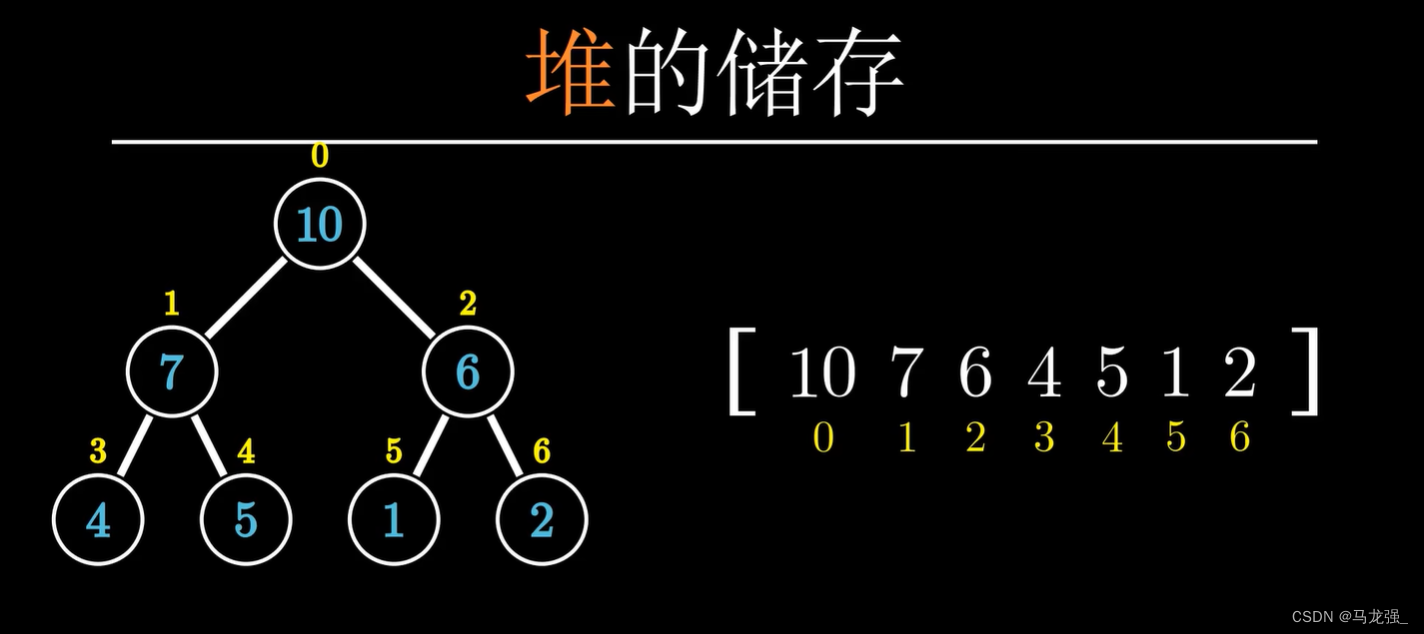
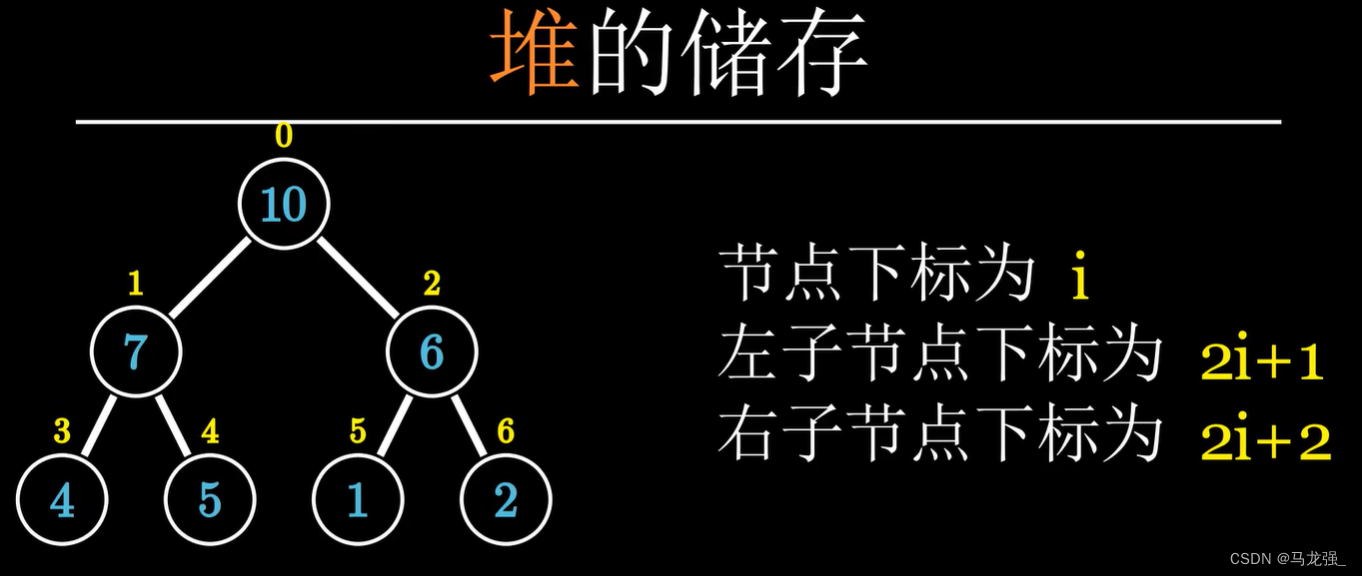
def heapify(arr, n, i):
# 初始化当前最大元素索引为根节点索引
largest = i
# 左子节点索引
left = 2 * i + 1
# 右子节点索引
right = 2 * i + 2
# 如果左子节点存在且大于根节点
if left < n and arr[i] < arr[left]:
largest = left
# 如果右子节点存在且大于当前已知的最大元素
if right < n and arr[largest] < arr[right]:
largest = right
# 如果最大元素不是根节点,则交换根节点和最大元素
if largest != i:
arr[i], arr[largest] = arr[largest], arr[i] # 交换
# 递归调用堆化函数,继续维护以最大元素为根的子堆
heapify(arr, n, largest)
# 堆排序函数
def heap_sort(arr):
n = len(arr)
# 构建最大堆
# 堆顶元素为最大元素
for i in range(n, -1, -1):
heapify(arr, n, i)
# 从堆中逐个取出最大元素并重新维护堆
for i in range(n - 1, 0, -1):
arr[i], arr[0] = arr[0], arr[i] # 交换堆顶元素和当前最大元素
# 对剩余元素重新进行堆化
heapify(arr, i, 0)
# 示例数据
data = [64, 34, 25, 12, 22, 11, 90]
heap_sort(data)
# 打印排序后的结果
print("堆排序后的结果:", data)二、查找
解释: 查找算法用于在数据集合中定位特定元素或查询相关信息。常见的查找算法包括线性查找、二分查找、哈希查找等。
1.线性查找
解释: 线性查找从数组(或其他线性结构)的一端开始,按顺序检查每个元素,直到找到目标元素或者遍历完整个数组。
# 定义一个线性搜索函数,用于在数组中查找目标值
def linear_search(arr, target):
# 遍历数组中的每个元素
for index, element in enumerate(arr):
# 如果当前元素等于目标值
if element == target:
# 返回目标值在数组中的索引
return index
# 如果遍历完整个数组都没有找到目标值,则返回-1
return -1
# 定义一个待搜索的数组
data = [64, 34, 25, 12, 22, 11, 90]
# 定义要搜索的目标值
target = 25
# 调用线性搜索函数,并将返回的索引赋值给变量index
index = linear_search(data, target)
# 判断返回的索引是否不等于-1
if index != -1:
# 如果不等于-1,说明找到了目标值,打印目标值及其索引
print(f"在数组中找到了目标值{target}, 其索引为{index}")
else:
# 如果等于-1,说明未找到目标值,打印提示信息
print(f"在数组中未找到目标值{target}")2.二分查找
解释: 二分查找适用于已排序的数组。它从数组中间开始,比较中间元素与目标值,如果目标值等于中间元素,则查找结束;如果目标值小于中间元素,则在左半部分继续查找;如果目标值大于中间元素,则在右半部分查找。重复此过程,直到找到目标值或确定其不存在于数组中。
# 定义二分查找函数,用于在已排序的数组中查找目标值
def binary_search(arr, target):
# 初始化左右指针,分别指向数组的第一个元素和最后一个元素
left, right = 0, len(arr) - 1
# 当左指针小于等于右指针时,循环继续
while left <= right:
# 计算中间元素的索引
mid = (left + right) // 2
# 如果中间元素等于目标值
if arr[mid] == target:
# 返回中间元素的索引
return mid
# 如果中间元素小于目标值,说明目标值在右半部分
elif arr[mid] < target:
left = mid + 1
# 如果中间元素大于目标值,说明目标值在左半部分
else:
right = mid - 1
# 如果循环结束还没有找到目标值,则返回-1
return -1
# 定义一个已排序的数组
sorted_data = [11, 22, 25, 34, 64, 90]
# 定义要搜索的目标值
target = 25
# 调用二分查找函数,并将返回的索引赋值给变量index
index = binary_search(sorted_data, target)
# 判断返回的索引是否不等于-1
if index != -1:
# 如果不等于-1,说明找到了目标值,打印目标值及其索引
print(f"在已排序数组中找到了目标值{target},其索引值为{index}")
else:
# 如果等于-1,说明未找到目标值,打印提示信息
print(f"在已排序数组中未找到目标值{target}")3.哈希查找
解释: 哈希查找利用哈希函数将键映射到哈希表(通常是数组或字典)的特定位置。理想情况下,哈希函数能保证键与位置的唯一对应关系,使得查找时可以直接通过哈希函数计算出目标键的存储位置,从而实现常数时间复杂度的查找。
# 定义一个哈希表查找函数,用于在哈希表中根据键查找对应的值
def hash_lookup(hash_table, key):
# 如果键在哈希表中存在
if key in hash_table:
# 返回该键对应的值
return hash_table[key]
# 如果键在哈希表中不存在
return None
# 定义一个哈希表,存储水果及其价格
hash_table = {
"apple": 1.25, # 苹果的价格为1.25
"banana": 0.5, # 香蕉的价格为0.5
"orange": 0.75, # 橙子的价格为0.75
"pear": 1.0 # 梨的价格为1.0
}
# 定义要查找的键
target_key = "banana"
# 调用哈希表查找函数,并将返回的值赋给变量price
price = hash_lookup(hash_table, target_key)
# 判断返回的price是否不为None
if price is not None:
# 如果不为None,说明找到了键,打印键及其对应的值
print(f"在哈希表中找到了键{target_key},其对应的值为{price}")
else:
# 如果为None,说明未找到键,打印提示信息
print(f"在哈希表中未找到键{target_key}")以上各示例代码演示了如何使用线性查找、二分查找和哈希查找在给定的数据结构中查找目标元素,并输出查找结果或未找到的通知。注意,二分查找要求输入数组是有序的,而哈希查找则依赖于哈希表的构建和哈希函数的有效性。
三、递归
解释: 递归是一种解决问题的方法,它将问题分解为规模较小的同类问题,直到达到基本情况可以直接求解。递归函数通常包含两个关键部分:基本情况(base case)和递归情况(recursive case)。
1.阶乘(Factorial)
问题描述:计算一个正整数 n 的阶乘,即 n! = n × (n-1) × (n-2) × ... × 2 × 1。
递归函数实现:
def factorial(n):
if n == 0 or n == 1: # 基础情况:0! = 1! = 1
return 1
else:
return n * factorial(n - 1) # 递归情况:n! = n × (n-1)!
n = 5
result = factorial(n)
print(result)2.斐波那契数列(Fibonacci Sequence)
问题描述:生成斐波那契数列的第 n 项,其中 F(n) = F(n-1) + F(n-2),且 F(0) = 0 和 F(1) = 1。
递归函数实现:
def fibonacci(n):
# 如果n为0,则返回0,因为Fibonacci序列的第0项是0
if n == 0:
return 0
# 如果n为1,则返回1,因为Fibonacci序列的第1项是1
elif n == 1:
return 1
else:
# 否则,递归地调用fibonacci函数计算前两项的和
# fibonacci(n - 1)返回的是第n-1项的值
# fibonacci(n-2)返回的是第n-2项的值
# 两者的和即为第n项的值
return fibonacci(n - 1) + fibonacci(n - 2)
# 设定要计算的Fibonacci数的位置
n = 10
# 调用fibonacci函数计算第n项的值
fib_number = fibonacci(n)
# 打印结果,但注意这里的格式字符串中遗漏了一个空格,应该是"The {n}th"
print(f"The {n}th Fibonacci number is {fib_number}.")3.汉诺塔(Hanoi Tower)
问题描述:将一组大小不等的圆盘从源柱A借助辅助柱B,按照大小顺序全部移动到目标柱C,每次只能移动一个圆盘,且任何时候大盘都不能压在小盘之上。
递归函数实现:
def move_disk(n, source, destination, auxiliary):
# 如果只有一个盘子,直接将其从源柱子移动到目标柱子
if n == 1:
print(f"Move disk 1 from {source} to {destination}")
return
# 将 n-1 个盘子从源柱子借助目标柱子移动到辅助柱子
move_disk(n-1, source, auxiliary, destination)
# 将第 n 个盘子从源柱子移动到目标柱子
print(f"Move disk {n} from {source} to {destination}")
# 将 n-1 个盘子从辅助柱子借助源柱子移动到目标柱子
move_disk(n-1, auxiliary, destination, source)
# 调用函数,将 3 个盘子从 A 柱子借助 B 柱子移动到 C 柱子
move_disk(3, 'A', 'B', 'C')
4.计算目录及其子目录下的文件数量
问题描述:统计给定目录(包括其所有子目录)中包含的文件数量。
递归函数实现(假设使用 os 库来处理文件系统操作):
import os
def count_files(directory):
total_files = 0
# 遍历目录中的所有条目
for entry in os.scandir(directory):
# 如果条目是文件,计数器加1
if entry.is_file():
total_files += 1
# 如果条目是目录,递归调用count_files函数,并将结果累加到计数器上
elif entry.is_dir():
total_files += count_files(entry.path)
return total_files
root_dir = "C:\\Users\\malongqiang\\PycharmProjects"
file_count = count_files(root_dir)
print(f"The are {file_count} files in directory {root_dir} and its subdirectories.")
四、分治
解释: 分治策略是将一个复杂问题分解成若干个相同或相似的子问题,再将子问题分解直至变为基本可直接求解的问题,最后将子问题的解合并得到原问题的解。分治算法通常包括三个步骤:分解、解决子问题、合并。
1.快速幂
def power(base, exponent):
if exponent == 0:
return 1
elif exponent % 2 == 0:
return power(base * base, exponent // 2)
else:
return base * power(base, exponent - 1)
base = 2
exponent = int(1 / 8)
result = power(base, exponent)
print(result)五、动态规划
解释: 动态规划是一种通过把原问题分解为相互重叠的子问题来求解复杂问题的方法。它通过记忆化存储子问题的解,避免重复计算,逐步构造出原问题的最优解。
1. 最长递增子序列(Longest Increasing Subsequence, LIS)
给定一个整数数组 nums,找到其中最长的严格递增子序列的长度。
def length_of_lis(nums):
n = len(nums) # 获取数组长度
dp = [1] * n # 初始化动态规划数组,每个元素为1
for i in range(1, n): # 遍历数组
for j in range(i): # 遍历当前元素之前的元素
if nums[i] > nums[j]: # 如果当前元素大于之前的元素
dp[i] = max(dp[i], dp[j] + 1) # 更新动态规划数组
return max(dp) # 返回动态规划数组中的最大值
nums = [10, 9, 2, 5, 3, 7, 101, 18]
print(length_of_lis(nums)) # 输出最长递增子序列的长度2. 最大子数组和(Maximum Subarray Sum)
给定一个整数数组 nums,找出其中连续子数组的最大和。
def max_subarray_sum(nums):
n = len(nums) # 获取数组长度
dp = [0] * n # 初始化动态规划数组,长度与输入数组相同
dp[0] = nums[0] # 将第一个元素赋值给动态规划数组的第一个元素
for i in range(1, n): # 遍历输入数组,从第二个元素开始
dp[i] = max(nums[i], dp[i-1] + nums[i]) # 计算当前位置的最大子数组和,取当前元素和当前元素加上前一个位置的最大子数组和的较大值
return max(dp) # 返回动态规划数组中的最大值,即最大子数组和
nums = [-2, 1, -3, 4, -1, 2, 1, -5, 4] # 定义输入数组
print(max_subarray_sum(nums)) # 调用函数并打印结果3. 斐波那契数列(Fibonacci Sequence)
计算第 n 个斐波那契数。
def fibonacci(n):
# 如果n小于等于1,直接返回n
if n <= 1:
return n
else:
# 初始化一个长度为n+1的列表dp,用于存储斐波那契数列的值
dp = [0] * (n + 1)
# 将dp[0]和dp[1]赋值为斐波那契数列的前两个值
dp[0], dp[1] = 0, 1
# 从第2个元素开始,计算斐波那契数列的值
for i in range(2, n + 1):
dp[i] = dp[i - 1] + dp[i - 2]
# 返回第n个斐波那契数列的值
return dp[n]
n = 10
print(fibonacci(n))4. 零钱兑换问题(Coin Change)
给定不同面额的硬币和一个总金额,求出组成总金额的最少硬币数量。
def coin_change(coins, amount):
n = len(coins) # 硬币种类数
dp = [0] + [float('inf')] * amount # 初始化动态规划数组,dp[i]表示金额为i时需要的最少硬币数
for i in range(1, amount + 1): # 遍历金额从1到amount
for j in range(n): # 遍历硬币种类
if coins[j] <= i: # 如果当前硬币面值小于等于当前金额
dp[i] = min(dp[i], dp[i - coins[j]] + 1) # 更新dp[i]为min(dp[i], dp[i-coins[j]] + 1)
return dp[-1] if dp[-1] != float('inf') else -1 # 如果dp[-1]不为无穷大,则返回dp[-1],否则返回-1
coins = [1, 2, 5]
amount = 11
print(coin_change(coins, amount))
5.爬楼梯问题(Climbing Stairs)
一个人每次可以爬1阶或2阶楼梯,问到达第 n 阶楼梯有多少种不同的爬法。
def climb_stairs(n):
# 如果楼梯数小于等于2,直接返回楼梯数
if n <= 2:
return n
# 初始化动态规划数组,dp[i]表示爬到第i阶楼梯的方法数
dp = [0, 1, 2] + [0] * (n - 2)
# 从第3阶楼梯开始遍历到第n阶楼梯
for i in range(3, n + 1):
# 爬到第i阶楼梯的方法数等于爬到第i-1阶楼梯的方法数加上爬到第i-2阶楼梯的方法数
dp[i] = dp[i - 1] + dp[i - 2]
# 返回爬到第n阶楼梯的方法数
return dp[n]
n = 4
print(climb_stairs(n))
六、贪心
解释: 贪心算法在每一步决策时都采取在当前状态下看起来最优的选择,希望以此逐步达到全局最优解。它适用于能够通过局部最优解构造全局最优解的问题。
1. 找零问题(Coin Change)
给定一系列面额的硬币和一个总金额,设计一个算法找出用最少数量的硬币来凑成这个总金额的方法。假设每种硬币无限供应。
def make_change(amount, coins):
# 初始化一个列表,长度为 amount + 1,用于存储每个金额所需的最小硬币数
min_coins = [float('inf')] * (amount + 1)
# 当金额为0时,所需硬币数为0
min_coins[0] = 0
# 遍历硬币面值
for coin in coins:
# 从当前硬币面值开始,遍历到目标金额
for i in range(coin, amount + 1):
# 更新当前金额所需的最小硬币数
min_coins[i] = min(min_coins[i], min_coins[i - coin] + 1)
# 返回目标金额所需的最小硬币数
return min_coins[amount]
amount = 93
coins = [1, 5, 10, 25]
num_coins = make_change(amount, coins)
print(num_coins)2. 背包问题(Knapsack Problem, Fractional Variant)
给定一组物品,每个物品有其价值和重量,以及一个背包的容量,目标是尽可能让背包内物品的总价值最大,允许物品被分割。
def fractional_knapsack(values, weights, capacity):
# 计算每个物品的价值与重量之比,并将其与价值和重量一起存储为元组
items = [(value / weight, value, weight) for value, weight in zip(values, weights)]
# 按价值与重量之比降序排序物品
items.sort(reverse=True)
total_value = 0
# 遍历排序后的物品列表
for ratio, value, weight in items:
# 如果当前容量大于等于物品的重量,则将物品全部装入背包
if capacity >= weight:
capacity -= weight
total_value += value
# 否则,将物品按照比例装入背包,并更新总价值和剩余容量
else:
total_value += ratio * capacity
break
return total_value
values = [60, 100, 120]
weights = [10, 20, 30]
capacity = 50
print(fractional_knapsack(values, weights, capacity))3. 活动安排问题(Activity Selection Problem)
给定一系列活动,每个活动有开始时间和结束时间,选择其中互不冲突的最多活动进行。
def activity_selector(activities):
# 按照活动的结束时间进行排序
activities.sort(key=lambda x: x[1])
# 用于存储被选中的活动
selector_activities = []
# 初始化结束时间为0,这里假设所有活动的开始时间都是非负的
end_time = 0
# 遍历排序后的活动列表
for start, finish in activities:
# 如果当前活动的开始时间大于或等于前一个被选中活动的结束时间
# 则选择该活动
if start >= end_time:
selector_activities.append((start, finish))
# 更新结束时间为当前被选中活动的结束时间
end_time = finish
# 返回被选中的活动列表
return selector_activities
# 示例活动列表
activities = [(1, 3), (3, 4), (0, 6), (5, 7)]
# 打印选中的活动
print(activity_selector(activities))4. Huffman编码(Huffman Coding)
构建一个前缀码(霍夫曼树),用于对给定字符及其出现频率进行高效编码。
import heapq
class Node:
def __init__(self, char, freq):
self.char = char # 字符
self.freq = freq # 频率
self.left = None # 左子节点
self.right = None # 右子节点
def build_huffman_tree(freqs):
# 将字符和频率组成列表,然后构建最小堆
heap = [[freq, char] for char, freq in freqs.items()]
heapq.heapify(heap)
# 当堆中元素个数大于1时,循环执行以下操作
while len(heap) > 1:
# 弹出堆中频率最小的两个元素
left_freq, left_char = heapq.heappop(heap)
right_freq, right_char = heapq.heappop(heap)
# 创建一个新的节点,将弹出的两个元素作为左右子节点
merged_node = Node(None, left_freq + right_freq)
merged_node.left = Node(left_char, left_freq)
merged_node.right = Node(right_char, right_freq)
# 将新节点加入堆中
heapq.heappush(heap, [merged_node.freq, merged_node])
# 返回堆中剩余的根节点
return heap[0][1]
freqs = {'A': 9, 'B': 10, 'C': 12, 'D': 13}
root = build_huffman_tree(freqs)
print(root)以上就是一些使用Python实现的贪心算法经典案例,包括找零问题、背包问题(分数版)、活动安排问题以及Huffman编码。这些案例展示了贪心算法如何在每一步选择中选取局部最优解,期望最终得到全局最优解。请注意,贪心算法并不总是能得到全局最优解,只有在问题具有贪心选择性质时才适用。
七、回溯
解释: 回溯算法是一种试探性的解决问题方法,通过尝试所有可能的候选解来找出正确的解。当发现当前路径无法得到解时,就“回溯”到上一步,撤销部分操作,尝试其他可能性。
1.全排列问题
给定一个不含重复元素的列表,求出所有可能的排列。
def permute(nums):
# 定义回溯函数,用于生成排列
def backtrack(first=0):
# 如果first等于数组长度,说明已经遍历完所有元素,将当前排列添加到结果列表中
if first == len(nums):
result.append(nums.copy())
return
# 从first开始遍历数组
for i in range(first, len(nums)):
# 交换first和i位置的元素
nums[first], nums[i] = nums[i], nums[first]
# 继续递归生成下一个元素的排列
backtrack(first + 1)
# 撤销交换操作,回溯到上一层
nums[first], nums[i] = nums[i], nums[first]
# 初始化结果列表
result = []
# 调用回溯函数生成排列
backtrack()
# 返回结果列表
return result
# 测试代码
nums = [1, 2, 3]
permutations = permute(nums)
print(permutations) # 输出: [[1, 2, 3], [1, 3, 2], [2, 1, 3], [2, 3, 1], [3, 1, 2], [3, 2, 1]]
2. 八皇后问题(算法理解有困难)
在8×8的棋盘上放置8个皇后,要求任何两个皇后都不能处于同一行、同一列或同一斜线上。
def solve_queens(size):
def is_safe(row, col, placed):
for r, c in enumerate(placed):
if c is not None and (c == col or
row - r == col - c or
row + r == col + c):
return False
return True
def backtrack(row=0, placed=None):
if placed is None:
placed = [None] * size # 初始化placed列表
if row == size:
return [col for col in placed if col is not None]
solutions = []
for col in range(size):
if is_safe(row, col, placed):
placed[row] = col
solutions.extend(backtrack(row + 1, placed.copy()))
placed[row] = None # 回溯,撤销选择
return solutions
return backtrack()
# 示例:
solutions = solve_queens(4)
for sol in solutions:
print(sol)3. 组合问题(Combinations)
从一个集合中选择指定数量的元素,不考虑元素的顺序。
def backtrack(start, path, n, k, result):
# 当路径的长度等于k时,将路径添加到结果中
if len(path) == k:
result.append(path[:])
return
# 遍历可能的数字
for i in range(start, n):
# 将当前数字添加到路径中
path.append(i)
# 递归调用backtrack函数,从下一个数字开始,继续构建组合
backtrack(i + 1, path, n, k, result)
# 回溯,将当前数字从路径中移除,以尝试其他数字
path.pop()
def combination(n, k):
# 存储最终结果的列表
result = []
# 调用backtrack函数开始构建组合
backtrack(0, [], n, k, result)
return result
# 测试示例
n = 5
k = 3
print(combination(n, k))4.数独求解
使用回溯算法解决经典的数独问题,填充一个 9x9 的空格矩阵,使得每行、每列、每个 3x3 宫内数字 1 到 9 都恰好出现一次。
# @Time: 2024/3/31 11:21
# @Author: 马龙强
# @File: 数独求解.py
# @software: PyCharm
def is_valid(board, row, col, num):
# 检查行和列是否有重复数字
for i in range(9):
if board[row][i] == num or board[i][col] == num:
return False
# 检查3x3的小方格是否有重复数字
box_row = (row // 3) * 3
box_col = (col // 3) * 3
for i in range(box_row, box_row + 3):
for j in range(box_col, box_col + 3):
if board[i][j] == num:
return False
return True
def solve_sudoku(board):
# 使用回溯算法解决数独问题
def backtrack(row=0, col=0):
# 如果已经处理完所有列,则转到下一行的第一列
if col == 9:
col = 0
row += 1
# 如果已经处理完所有行,则返回True表示找到了解决方案
if row == 9:
return True
# 如果当前位置已经有数字,则跳过
if board[row][col] != 0:
return backtrack(row, col + 1)
# 尝试在当前位置放置1到9的数字
for num in range(1, 10):
if is_valid(board, row, col, num):
board[row][col] = num
# 如果放置成功,继续处理下一个位置
if backtrack(row, col + 1):
return True
# 如果放置失败,回溯并尝试其他数字
board[row][col] = 0
return False
return backtrack() and board
board = [
[5, 3, 0, 0, 7, 0, 0, 0, 0],
[6, 0, 0, 1, 9, 5, 0, 0, 0],
[0, 9, 8, 0, 0, 0, 0, 6, 0],
[8, 0, 0, 0, 6, 0, 0, 0, 3],
[4, 0, 0, 8, 0, 3, 0, 0, 1],
[7, 0, 0, 0, 2, 0, 0, 0, 6],
[0, 6, 0, 0, 0, 0, 2, 8, 0],
[0, 0, 0, 4, 1, 9, 0, 0, 5],
[0, 0, 0, 0, 8, 0, 0, 7, 9]
]
solve_board = solve_sudoku(board)
for row in solve_board:
print(row)八、搜索(深度优先、广度优先)
1. 线性搜索(Linear Search)
线性搜索从数据结构(如列表)的一端开始,按顺序检查每个元素,直到找到目标元素或遍历完整个结构。
def linear_search(lst, target):
# 使用enumerate函数遍历列表,同时获取索引和元素
for index, element in enumerate(lst):
# 如果当前元素等于目标值,则返回当前索引
if element == target:
return index
# 如果列表中没有找到目标值,则返回-1
return -1
data = [3, 5, 6, 7, 11, 13]
target = 7
# 调用线性搜索函数查找目标值在列表中的索引
result = linear_search(data, target)
# 根据搜索结果输出相应的消息
if result != -1:
print(f"Element {target} found at index {result}")
else:
print(f"Element {target} not found in the list")2. 二分搜索(Binary Search)
二分搜索适用于已排序的列表。它通过不断缩小搜索范围来查找目标元素,每次将待搜索区间划分为两半,并根据中间元素与目标值的大小关系决定继续在左半部分还是右半部分搜索。
def binary_search(sorted_lst, target):
left, right = 0, len(sorted_lst) - 1
# 当左边界小于等于右边界时,继续查找
while left <= right:
# 计算中间位置
mid = (left + right) // 2
# 如果中间位置的元素等于目标值,返回中间位置
if sorted_lst[mid] == target:
return mid
# 如果中间位置的元素小于目标值,将左边界移动到中间位置的右侧
elif sorted_lst[mid] < target:
left = mid + 1
# 如果中间位置的元素大于目标值,将右边界移动到中间位置的左侧
else:
right = mid - 1
# 如果没有找到目标值,返回-1
return -1
sorted_data = [2, 4, 6, 8, 10, 12, 14]
target = 10
result = binary_search(sorted_data, target)
if result != -1:
print(f"Element {target} found at index {result}")
else:
print(f"Element {target} not found in the list")3.深度优先搜索 (DFS)
解释: 深度优先搜索是一种沿着一条路径尽可能深地搜索,直到到达叶子节点或无法继续前进时回退到上一个节点,再选择另一条路径继续搜索的策略。
from collections import defaultdict
class Graph:
def __init__(self):
# 初始化一个空的图,使用defaultdict存储邻接表
self.graph = defaultdict(list)
def add_edge(self, u, v):
# 添加一条从u到v的边
self.graph[u].append(v)
def dfs(self, start, target, visited=None):
# 深度优先搜索,从start节点开始寻找target节点
if visited is None:
# 如果visited为空,则初始化一个空的集合
visited = set()
visited.add(start)
# 将当前节点添加到已访问集合中
if start == target:
# 如果当前节点就是目标节点,返回True
return True
for neighbor in self.graph[start]:
# 遍历当前节点的所有邻居节点
if neighbor not in visited:
# 如果邻居节点没有被访问过
if self.dfs(neighbor, target, visited):
# 递归调用dfs函数,如果找到目标节点,返回True
return True
return False
# 如果遍历完所有邻居节点都没有找到目标节点,返回False
g = Graph()
# 创建一个Graph对象
g.add_edge('A', 'B')
g.add_edge('A', 'C')
g.add_edge('A', 'D')
g.add_edge('A', 'E')
g.add_edge('A', 'F')
g.add_edge('A', 'G')
# 添加边
start_node = 'A'
target_node = 'G'
found = g.dfs(start_node, target_node)
# 调用dfs方法,查找从A到G的路径
if found:
print(f"A path exists from {start_node} to {target_node}")
else:
print(f"No path exits from {start_node} to {target_node}")
# 输出结果4.广度优先搜索 (BFS)
解释: 广度优先搜索是一种从起始节点开始,逐层遍历所有相邻节点,直到找到目标节点或遍历完整个图的搜索策略。
from collections import deque, defaultdict # 导入deque用于队列操作和defaultdict用于图表示
class Graph:
def __init__(self):
# 初始化一个图,用字典表示,键为节点,值为相邻节点的列表
self.graph = defaultdict(list)
def add_edge(self, u, v):
# 在节点u和v之间添加一条边,通过将v追加到u的相邻节点列表
self.graph[u].append(v)
def bfs(self, start, target):
# 初始化一个集合来跟踪访问过的节点
visited = set()
# 创建一个队列并加入起始节点
queue = deque([start])
# 执行BFS直到队列为空
while queue:
# 从队列中弹出一个当前节点
current = queue.popleft()
# 标记当前节点为已访问
visited.add(current)
# 检查当前节点是否是目标节点
if current == target:
return True # 如果找到目标则返回True
# 遍历当前节点的所有相邻节点
for neighbor in self.graph[current]:
# 如果相邻节点未被访问过,则加入队列
if neighbor not in visited:
queue.append(neighbor)
return False # 如果未找到目标则返回False
# 创建一个Graph对象
g = Graph()
# 在节点'A'和'B'之间添加一条边
g.add_edge('A', 'B')
# 在节点'A'和'C'之间添加一条边
g.add_edge('A', 'C')
# 在节点'A'和'D'之间添加一条边
g.add_edge('A', 'D')
# 在节点'A'和'E'之间添加一条边
g.add_edge('A', 'E')
# 在节点'A'和'F'之间添加一条边
g.add_edge('A', 'F')
# 在节点'A'和'G'之间添加一条边
g.add_edge('A', 'G')
# 设置起始节点为'A'
start_node = 'A'
# 设置目标节点为'G'
target_node = 'G'
# 调用bfs方法寻找从起始节点到目标节点的路径
found = g.bfs(start_node, target_node)
# 如果找到了路径,打印存在的路径信息
if found:
print(f"存在从{start_node}到{target_node}的路径")
# 如果没有找到路径,打印不存在的路径信息
else:
print(f"不存在从{start_node}到{target_node}的路径")九、图算法(如最短路径、最小生成树等)
最短路径: 解释: 最短路径算法用于寻找图中两点间最短的路径,如Dijkstra算法、Bellman-Ford算法或Floyd-Warshall算法。
1. Dijkstra 最短路径算法
使用 heapq 库实现 Dijkstra 算法,计算单源最短路径。
import heapq # 导入heapq模块,它提供了堆队列算法的支持
def dijkstra(graph, start, end):
# 初始化距离字典,每个节点的距离设置为无穷大
distances = {node: float('inf') for node in graph}
# 起始点到自身的距离设置为0
distances[start] = 0
# 创建优先队列,并将起始点及其距离作为元组放入队列
pq = [(0, start)]
# 当优先队列不为空时循环
while pq:
# 从优先队列中弹出具有最小距离的节点
current_distance, current_node = heapq.heappop(pq)
# 如果当前节点计算出的距离大于已知的最短距离,则跳过
if current_distance > distances[current_node]:
continue
# 遍历当前节点的所有邻居及对应的权重
for neighbor, weight in graph[current_node].items():
# 计算通过当前节点到达邻居的距离
distance_through_current = current_distance + weight
# 如果新计算的距离小于已知的最短距离,更新距离并重置优先队列
if distance_through_current < distances[neighbor]:
distances[neighbor] = distance_through_current
heapq.heappush(pq, (distance_through_current, neighbor))
# 返回结束节点的最短路径长度
return distances[end]
# 定义带权重的图
weighted_graph = {
'A': {'B': 1, 'C': 4},
'B': {'A': 1, 'D': 2, 'E': 5},
'C': {'A': 4, 'F': 8},
'D': {'B': 2, 'E': 1},
'E': {'B': 5, 'D': 1, 'F': 6},
'F': {'C': 8, 'E': 6}
}
# 使用dijkstra函数计算从节点'A'到节点'F'的最短路径长度
shortest_path_length = dijkstra(weighted_graph, 'A', 'F')
# 打印最短路径长度
print(shortest_path_length)2. Prim 最小生成树算法
使用 heapq 实现 Prim 算法,构造加权无向图的最小生成树。
import heapq # 导入heapq模块,它提供了堆队列算法的支持
def prim(graph, start):
# 初始化最小生成树集合
mst = set()
# 初始化已访问节点集合,包含起始节点
visited = {start}
# 创建优先队列,并将起始节点及其与父节点的边权重设为0(无父节点)
pq = [(0, start, None)]
# 当优先队列不为空时循环
while pq:
# 从优先队列中弹出具有最小边权重的节点
edge_weight, vertex, parent = heapq.heappop(pq)
# 如果该节点已被访问,跳过
if vertex in visited:
continue
# 将该节点标记为已访问
visited.add(vertex)
# 如果有父节点,将父节点到当前节点的边加入最小生成树集合
mst.add((parent, vertex)) if parent else None
# 遍历当前节点的所有邻居及对应的权重
for neighbor, weight in graph[vertex].items():
# 如果邻居节点未被访问,将其与当前节点的边权重和节点加入优先队列
if neighbor not in visited:
heapq.heappush(pq, (weight, neighbor, vertex))
# 返回最小生成树的边集合
return mst
# 定义带权重的图
weighted_graph = {
'A': {'B': 1, 'C': 4},
'B': {'A': 1, 'D': 2, 'E': 5},
'C': {'A': 4, 'F': 8},
'D': {'B': 2, 'E': 1},
'E': {'B': 5, 'D': 1, 'F': 6},
'F': {'C': 8, 'E': 6}
}
# 使用prim函数计算以节点'A'为起始点的最小生成树的边集合
mst_edges = prim(weighted_graph, 'A')
# 打印最小生成树的边集合
print(mst_edges)3. 拓扑排序
使用队列实现拓扑排序,适用于有向无环图(DAG)。
import collections # 导入collections模块,提供deque等数据结构
def topological_sort(graph):
# 初始化每个节点的入度为0
indegree = {node: 0 for node in graph}
# 遍历图中每个节点及其邻居
for node, neighbors in graph.items():
# 遍历当前节点的所有邻居
for neighbor in neighbors:
# 增加邻居节点的入度
indegree[neighbor] += 1
# 创建一个双端队列,并将所有入度为0的节点加入队列
queue = collections.deque([node for node, degree in indegree.items() if degree == 0])
# 初始化拓扑排序结果列表
topological_order = []
# 当队列不为空时循环
while queue:
# 从队列左侧弹出一个节点
vertex = queue.popleft()
# 将节点加入拓扑排序结果列表
topological_order.append(vertex)
# 遍历当前节点的所有邻居
for neighbor in graph[vertex]:
# 减少邻居节点的入度
indegree[neighbor] -= 1
# 如果邻居节点的入度变为0,将其加入队列
if indegree[neighbor] == 0:
queue.append(neighbor)
# 如果拓扑排序结果列表的长度等于图中的节点数,说明图中没有环,返回拓扑排序结果
if len(topological_order) == len(graph):
return topological_order
# 否则,说明图中存在环,返回提示信息
else:
return "Graph contains cycles"
# 定义依赖关系图
dependency_graph = {
'A': ['B', 'C'],
'B': ['D', 'E'],
'C': ['D'],
'D': [],
'E': ['F'],
'F': [],
}
# 使用topological_sort函数对依赖关系图进行拓扑排序
topological_sequence = topological_sort(dependency_graph)
# 打印拓扑排序结果
print(topological_sequence)4.Bellman-Ford 算法
Bellman-Ford 算法用于计算具有负权边的图中单源最短路径。以下是一个简单的 Python 实现:
def bellman_ford(graph, source):
# 获取图中节点的数量
n = len(graph)
# 初始化距离数组,所有节点的距离设置为无穷大
dist = [float('inf')] * n
# 设置源点到自身的距离为0
dist[source] = 0
# 进行 V-1 轮松弛操作
for _ in range(n - 1):
# 遍历每个节点
for u in range(n):
# 遍历当前节点的所有出边
for v, weight in graph[u]:
# 如果当前节点到起点的距离不是无穷大且通过当前边可以缩短到终点的距离
if dist[u] != float('inf') and dist[u] + weight < dist[v]:
# 更新终点到起点的最短距离
dist[v] = dist[u] + weight
# 检查是否存在负权回路
for u in range(n):
# 遍历当前节点的所有出边
for v, weight in graph[u]:
# 如果当前节点到起点的距离不是无穷大且通过当前边可以缩短到终点的距离
if dist[u] != float('inf') and dist[u] + weight < dist[v]:
# 如果存在这样的边,说明存在负权回路,抛出异常
raise ValueError("Graph contains negative-weight cycles")
# 返回所有节点到起点的最短距离数组
return dist
# 示例图(邻接列表表示,其中元组 (v, w) 表示从 u 到 v 的边,权值为 w)
bellman_ford_graph = {
0: [(1, -1), (2, 4)],
1: [(3, 2)],
2: [(1, 3), (3, 0.5)],
3: []
}
# 指定源点为节点0
source = 0
# 调用Bellman-Ford算法计算最短路径
shortest_distances = bellman_ford(bellman_ford_graph, source)
# 遍历并打印所有节点到源点的最短距离
for node, distance in enumerate(shortest_distances):
print(f"Shortest distance from {source} to {node}: {distance}")5.Floyd-Warshall 算法
Floyd-Warshall 算法用于计算图中任意两点间的最短距离。以下是一个简洁的 Python 实现:
def floyd_warshall(graph):
# 获取图中节点的数量
n = len(graph)
# 初始化距离矩阵,复制输入的邻接矩阵
dist = graph.copy()
# 通过中间节点 k 进行松弛
for k in range(n):
# 遍历每个节点对 (i, j)
for i in range(n):
for j in range(n):
# 更新节点 i 到节点 j 的最短距离
dist[i][j] = min(dist[i][j], dist[i][k] + dist[k][j] if dist[i][k] != float('inf') else float('inf'))
# 返回所有节点对的最短距离矩阵
return dist
# 示例图(邻接矩阵表示,其中 dist[i][j] 表示从 i 到 j 的边的权值)
floyd_warshall_graph = [
[0, 1, 2, float('inf')],
[float('inf'), 0, -1, 4],
[float('inf'), float('inf'), 0, 0.75],
[float('inf'), float('inf'), float('inf'), 0]
]
# 调用Floyd-Warshall算法计算所有节点对的最短路径
all_pairs_shortest_distances = floyd_warshall(floyd_warshall_graph)
# 遍历并打印所有节点对的最短距离矩阵
for row in all_pairs_shortest_distances:
print(row)