MySQL中的各种Buffer和Log以及表空间
MySQL中一次事务涉及了各种Buffer,Log和表空间,主要涉及:Buffer Pool, Binlog, Undo Log, Redo Log以及表空间。
我们来探讨下。
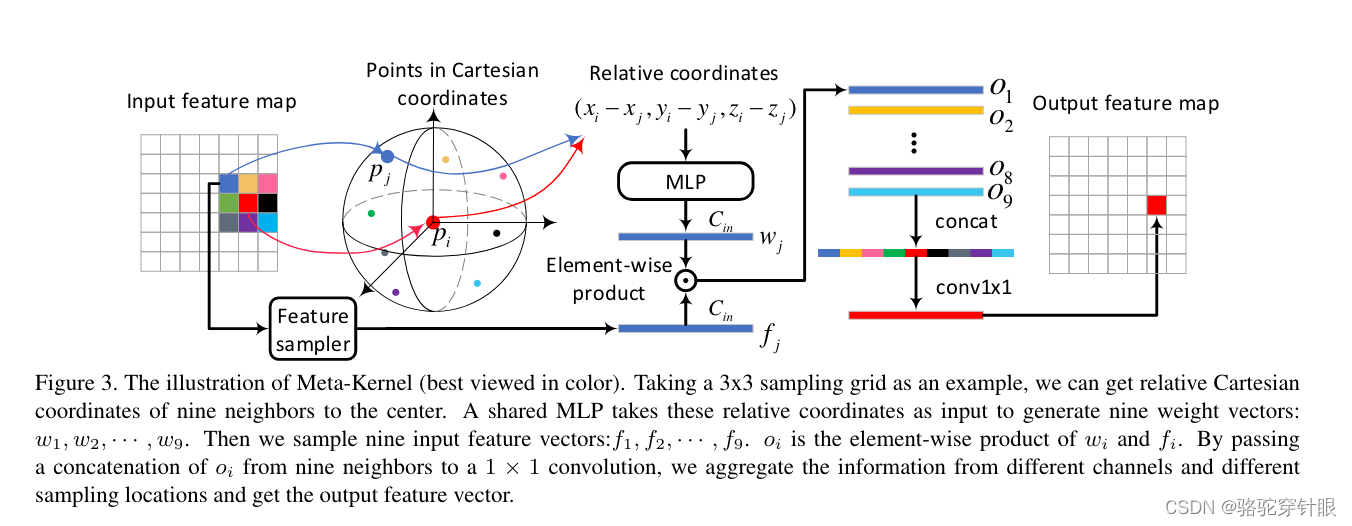
Buffer Pool
Buffer Pool主要存放在内存中,它是一个缓存区域,用来缓存InnoDB读取的数据页和索引页。此外,它也暂存了那些待写入磁盘的修改后的数据页,也就是“脏页”。
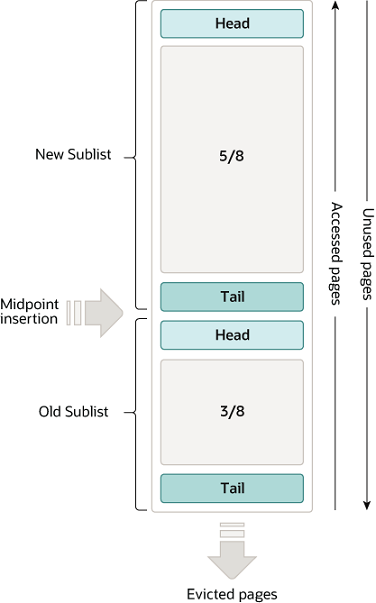
Buffer Pool关键词:LRU,配置一大堆,步步惊心。
- Binlog (Binary Log):
Binlog不是InnoDB特有的,而是MySQL数据库的一种日志系统,它记录了所有修改数据库数据的SQL语句及其执行的时间点。Binlog主要用于复制和数据恢复。Binlog信息首先存储在内存中,然后会定期刷新到磁盘文件中去。

Binlog关键词 WAL, 复制, 数据持久性,硬盘转个不停,高性能SSD可能也不行
Undo Log:
Undo Log用来保存数据修改前的信息。它存在于内存中,并且可以被部分持久化到磁盘上。Undo Log主要用于事务的回滚,以及提供多版本并发控制(MVCC)时所需的行数据的旧版本。
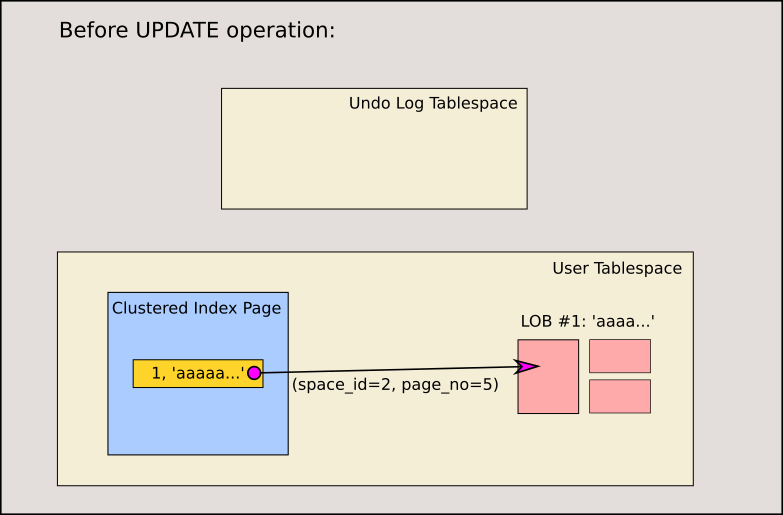
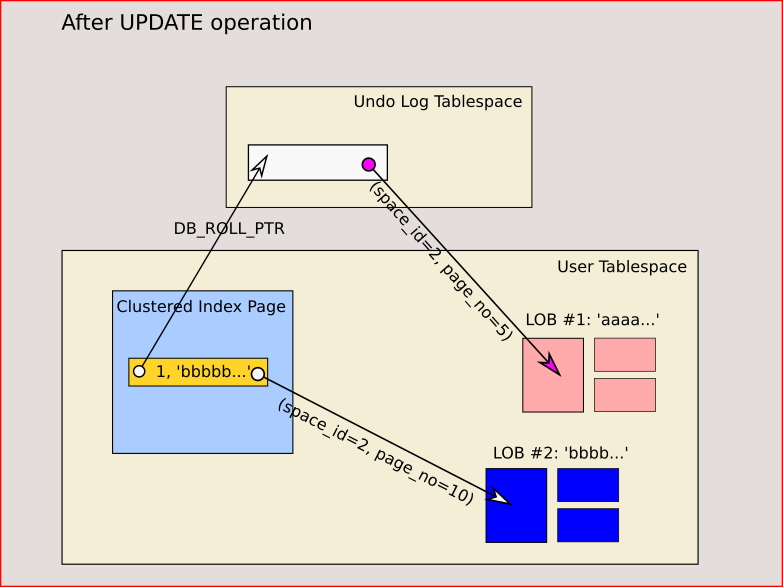
Undo Log MVCC, 事务回滚, 保存旧数据 返璞归真
Redo Log:
Redo Log记录了事务所做的更改,可以在系统崩溃后用于数据的恢复。Redo Log在实现起来通常分为两个部分,一部分是在内存中维护的缓冲区(Redo Log Buffer),另外一部分则是磁盘上的文件(Redo Log Files)。Redo Log Buffer中的内容会定期刷新到Redo Log Files以确保数据的持久性。
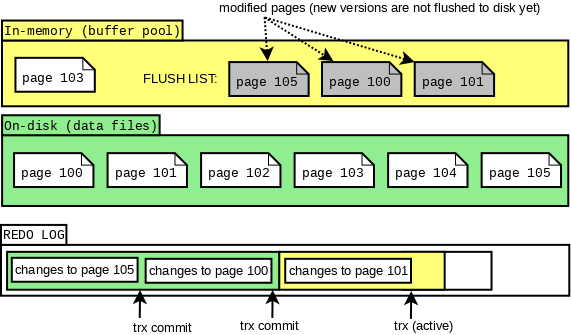
Redo Log关键词:WAL, Crash Recovery, 保护新数据,活力四射的硬盘,SSD的挑战者
事务过程
在事务操作期间, 以上的Buffer,Log和表空间保证了事务的ACID特性(原子性、一致性、隔离性、持久性)。内存是用于快速数据访问和处理的,而日志文件(Binlog和Redo Log Files)和Undo信息的持久化存储位于磁盘上,用来确保数据在系统崩溃后能够恢复。通过将内存计算与磁盘持久化结合,MySQL能够在保证性能,同事保证数据的完整性和可靠性。
在MySQL中,一个事务的过程一般会涉及以下步骤:
开始一个事务
用户发起一个事务(例如,执行START TRANSACTION;),此时事务开始。
读取和修改数据
用户读取和修改数据时,InnoDB首先从Buffer Pool查找所需的数据页。如果数据页不在Buffer Pool中,则从磁盘加载数据页到Buffer Pool。修改数据时,InnoDB会将更改写入Buffer Pool中的数据页,并将这些修改作为“脏页”标记。
写入Undo Log
在内存中,InnoDB记录Undo Log以保存数据修改前的状态。Undo Log在事务过程中可能会持续增加,在事务提交之前,一部分或全部Undo Log可以持久化到磁盘上,以支持可能的事务回滚或系统崩溃后的数据恢复。
记录Redo Log
同时,InnoDB会在内存的Redo Log Buffer中记录Redo Log,详细记录数据页的修改操作。这些日志信息是事务的一部分,并且最重要的是,事务提交前,这些Redo Log会被刷写(flush)到磁盘上的Redo Log Files中,以保证事务的持久性,这就是著名的Write-Ahead Logging(WAL)技术。
写入Binlog
如果启用了Binlog(比如在MySQL主从复制配置中),MySQL服务器层会将修改操作记录到Binlog Cache中,事务提交时,Binlog Cache中的内容会被写入到磁盘上的Binlog文件中,确保记录了修改数据库的所有操作。
提交事务
当用户执行COMMIT;命令提交事务,发生以下动作:
- Redo Log Buffer中与该事务相关的日志被刷写到磁盘上的Redo Log Files,这步操作是确保数据持久性的重要一步。
- Binlog在提交之前也被刷写到磁盘,这确保了急停(如电源突然中断)的情况下,已提交的事务能够通过Redo Log和Binlog恢复。
- 一旦Redo Log和Binlog都写入了磁盘,事务就被认为是成功提交了,此时,即使系统崩溃,已提交的事务也不会丢失。
清理和维护
在事务提交后,InnoDB可能会清理Undo Log,释放资源。同时,后台进程会负责将Buffer Pool中的脏页异步地刷写到磁盘上,此过程被称为Checkpointing。它不是立即发生的,而是根据InnoDB的配置和当前的系统负载情况进行调整的。这样做的好处是可以批量写入数据,并且分摊I/O压力。
刷盘时机
- Redo Log刷盘:事务提交时,为保证事务的持久性。
- Binlog刷盘:事务提交时,用于确保数据可以复制或恢复。
- Buffer Pool刷盘:通过后台Checkpoint或者主动Flush操作,不一定与事务提交同步。

通过这个流程,可以看到InnoDB事务处理中不同组件的作用:
- Buffer Pool: 提高数据操作效率,避免频繁磁盘I/O。
- Undo Log: 提供事务回滚,支持多版本并发控制(MVCC)。
- Redo Log: 确保事务的原子性和持久性,帮助恢复未提交的数据修改。
- Binlog: 用于数据的复制和恢复工作,但不是InnoDB特有的,属于MySQL Server层的组件。
- 表空间(Tablespace): 存储数据及索引的物理文件。
MySQL会丢数据吗?
在事务提交时,确实涉及Redo Log和Binlog的写入到磁盘,但是否是“实时”取决于具体配置。以下是更详细的解释:
- Redo Log 写入磁盘:
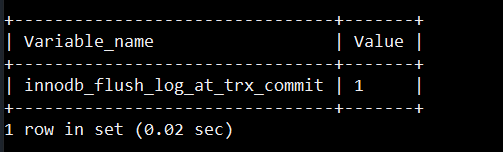
InnoDB使用Write-Ahead Logging (WAL) 机制。在事务提交时,它会确保所有的Redo Log记录至少已经写入了Redo Log Buffer,并且要求这些记录在事务被认为已提交之前写入磁盘。控制这个行为的MySQL配置参数是innodb_flush_log_at_trx_commit,来看一下每个值对应的策略:
| 选项值 | 说明 | MySQL 8 默认值 |
|---|---|---|
| 0 | 对Redo Log的刷写会在每秒进行一次,这种设置在性能与数据安全之间提供了折衷方案。如果发生崩溃,可能会丢失最近一秒内的改动。 | – |
| 1 | 每次事务提交时都将Redo Log从缓冲区刷写到磁盘。这提供了最高级别的数据持久性,但可能会对性能产生影响,因为涉及到更频繁的磁盘IO操作。 | 默认 |
| 2 | Redo Log会被定期地,但不是在每个事务提交时,从缓冲区刷写到磁盘。这种设置提高了性能,但如果发生崩溃,可能会导致最近一秒内的事务数据丢失。 | – |
- Binlog 写入磁盘:
Binlog的写入行为是由sync_binlog配置参数控制的。
| 选项值 | 说明 | MySQL 8 默认值 |
|---|---|---|
| 0 | 提交事务时不会强制刷新Binlog,而是依赖操作系统的刷写策略。这种设置在性能上有所优势,但在系统崩溃时可能会导致Binlog丢失,因此在数据安全性方面有所妥协。 | No |
| 1 | 每个事务的Binlog都会被刷写到磁盘。这在数据安全性方面提供了最高的保证,但可能会对性能产生影响由于涉及频繁的磁盘IO操作。 | Yes |
| N (>1) | 每N次事务才会刷写一次Binlog到磁盘。这种设置可以减少磁盘I/O,提升性能,但同时也增加了数据丢失的风险。具体的N值应根据具体的业务需求和硬件性能进行调整。 | No |
答案
MySQL在事务成功提交后是不会丢数据的,但是如果你调整了这两个参数那么就有可能丢失事务数据。
参考
MySQL 牺牲性能产出的ACID – FOF编程网