自动化处理 PDF 文件
目录
自动化处理 PDF 文件
谷歌浏览器 Chrome与浏览器驱动ChromeDriver安装
(一)批量下载 PDF 文件
1.使用Selenium模块爬取多页内容
2.使用Selenium模块下载PDF文件
3.使用urllib模块来进行网页的下载和保存
4.使用urllib&Selenium模块判断下载和保存
(二)批量合并 PDF 文件
(三)批量拆分 PDF 文件
(四)批量加密 PDF 文件
(五)批量为 PDF 文件添加水印
1.自定义函数创建水印文件
2.自定义函数添加水印
3.使用循环为每个PDF文件添加水印
Chrome:浏览器
Selenium:是一个用于浏览器自动化测试的工具集,是一个完整的自动化测试框架
WebDriver:是Selenium的一个关键组件,用于控制和操作浏览器
ChromeDriver:是Webdriver的一个实现,专门用于控制和操作Google Chrome浏览器
谷歌浏览器 Chrome与浏览器驱动ChromeDriver安装
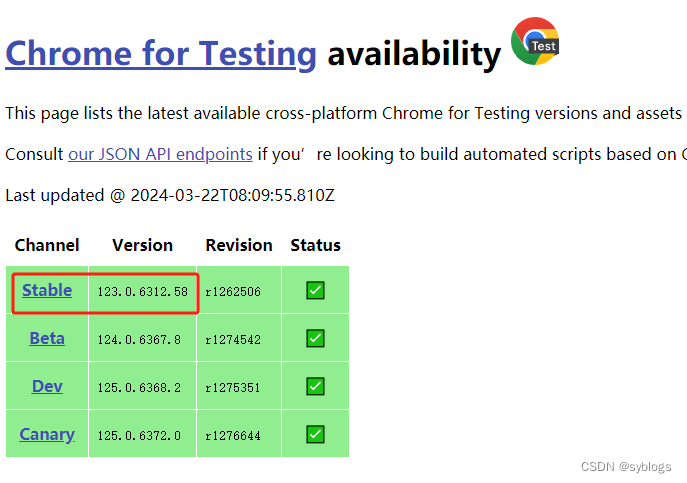
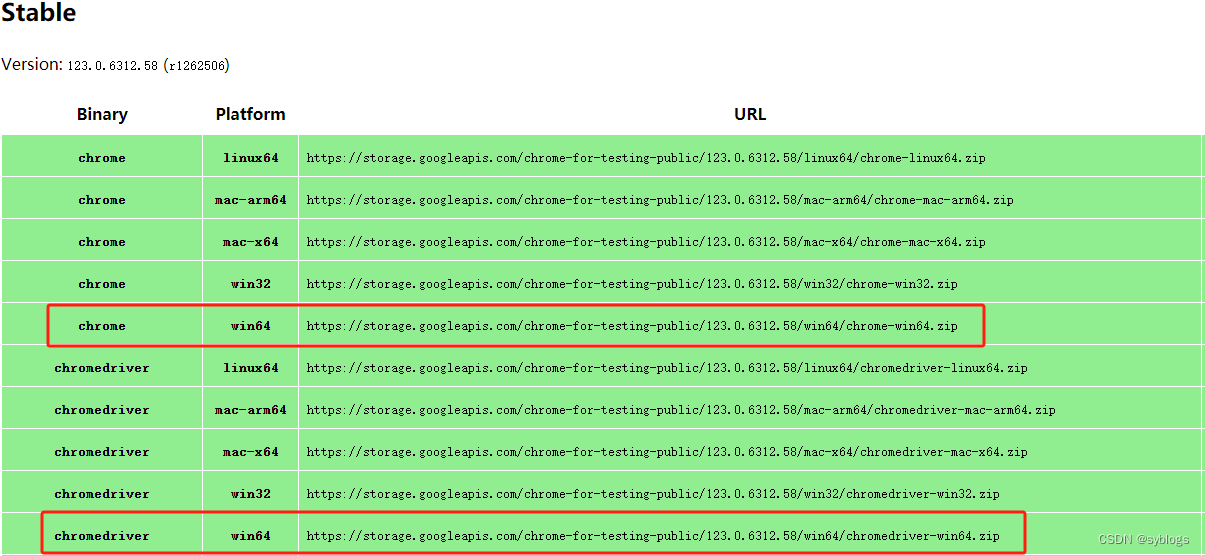
Chrome 73 版本以后, ChromeDriver 和 Chrome 版本是一对一,版本号是一样的。
查看网址:Chrome for Testing availability
“安装路径展示”
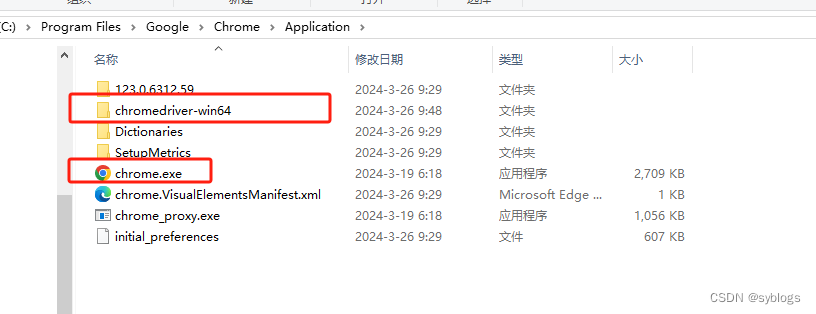
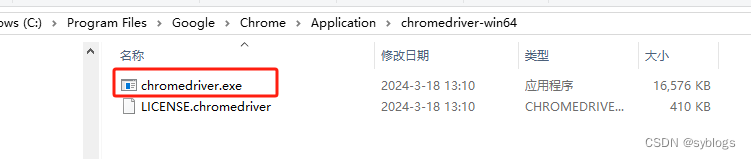
(一)批量下载 PDF 文件
1.使用Selenium模块爬取多页内容
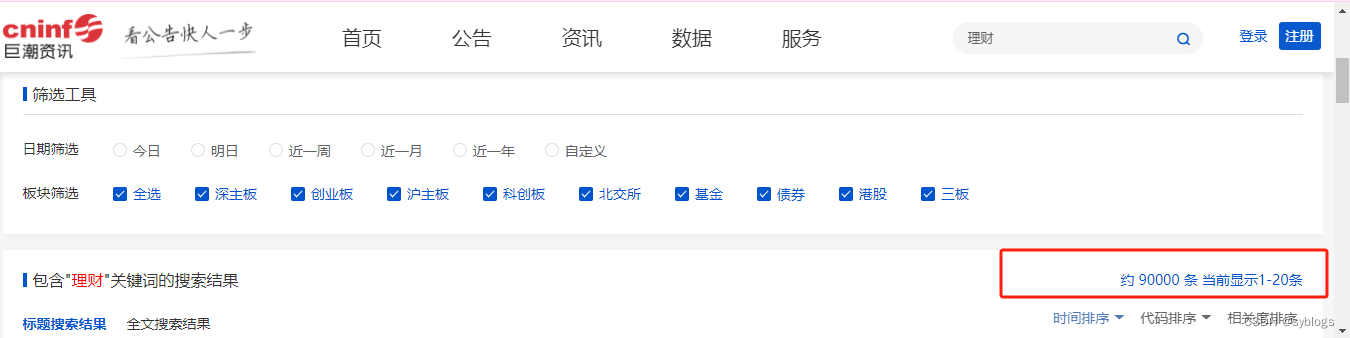
Eg:以下载巨潮资讯网的上市公司公告PDF文件为例。
“获取公告总数”
“获取[下一页]单击按钮”
“获取公告标题和网址”
"python程序完整代码"
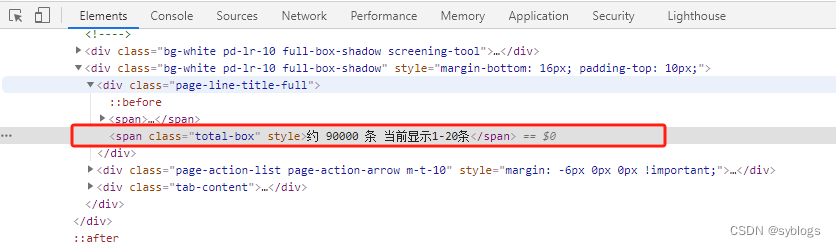
在Selenium 4之后的版本中,由于引入了新的查找策略,原来的基于
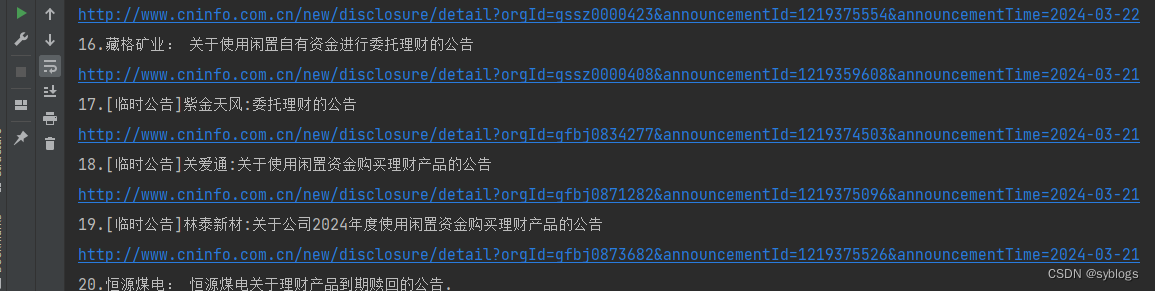
by_*方法的查找方式已经被弃用,需要使用新的方法。“find_element”配合By类来进行元素定位。# 利用Selenium模块模拟鼠标单击"下一页"按钮 from selenium import webdriver from selenium.webdriver.common.by import By import time import re # 1.获取公告总数和单页次数 browser = webdriver.Chrome() url = "http://www.cninfo.com.cn/new/fulltextSearch?notautosubmit=&keyWord=理财" browser.get(url) time.sleep(5) data = browser.page_source p_count = '<span class="total-box" style="">约 (.*?) 条' count = re.findall(p_count, data)[0] pages = int(int(count) / 10) # 2.用Selenium模块模拟单击”下一页“按钮 datas = [] datas.append(data) for i in range(1): browser.find_element( By.XPATH, '//*[@id="fulltext-search"]/div[2]/div/div/div[3]/div[3]/div[2]/div/button[2]', ).click() time.sleep(3) data = browser.page_source datas.append(data) time.sleep(3) # 3.将列表转换为字符串 alldata = "".join(datas) browser.quit() # 4.通过正则表达式提取公告标题和网址 p_title = '<span title="" class="r-title">(.*?)</a>' p_href = '<a target="_blank" href="(.*?)".*?<span title=' # 5.将提取公告标题和网址的正则表达式应用到汇总了所有页面源代码的字符串变量alldata中 title = re.findall(p_title, alldata) href = re.findall(p_href, alldata) # 6.对爬取到的数据进行清洗工作 for i in range(len(title)): title[i] = re.sub("<.*?>", "", title[i]) href[i] = "http://www.cninfo.com.cn" + href[i] href[i] = re.sub("amp;", "", href[i]) print(str(i + 1) + "." + title[i]) print(href[i])"程序运行结果展示"
2.使用Selenium模块下载PDF文件
在搜索”理财“的结果网址:
http://www.cninfo.com.cn/new/fulltextSearch?notautosubmit=&keyWord=理财中,单击任意一个公告标题,打开公告PDF文件的下载页面,网址变更为:
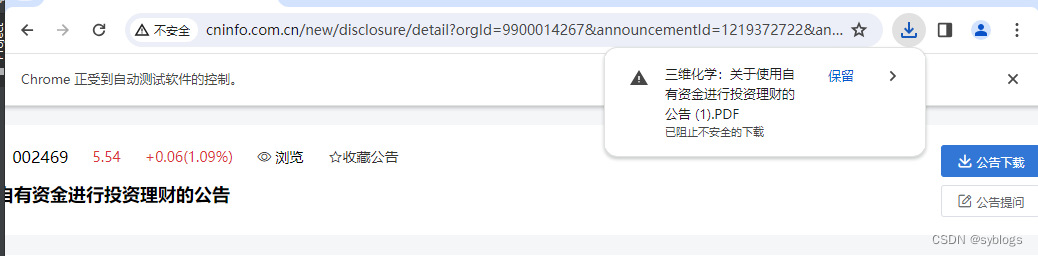
http://www.cninfo.com.cn/new/disclosure/detail?orgId=9900014267&announcementId=1219372722&announcementTime=2024-03-22自动下载页面PDF文件,使用Selenium模块模拟单击页面中的”公告下载“
查看源码,右键获取“公告下载”按钮的XPath内容:
//*[@id="noticeDetail"]/div/div[1]/div[3]/div[1]/button"
文件存在危险,因此 Chrome 已将其拦截 "
"python程序完整代码【单公告】"
# 利用Selenium模块模拟鼠标单击"下一页"按钮 from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.chrome.options import Options from selenium.webdriver.chrome.service import Service import time # 设置Chrome驱动本地目录 chromedriver_path = "C:\\Program Files\\Google\\Chrome\\Application\\chromedriver-win64\\chromedriver.exe" # 创建ChromeOptions对象并设置下载目录 chrome_options = Options() # 启用无头模式,隐藏 Chrome 窗口以在后台执行。 chrome_options.add_argument("--headless") # 禁用 GPU 加速。 chrome_options.add_argument("--disable-gpu") # 这两个参数通常用于 Docker 容器中运行测试。 # chrome_options.add_argument("--no-sandbox") # 运行在没有沙箱的环境中 # chrome_options.add_argument("--disable-dev-shm-usage") # 禁用/dev/shm目录用于临时文件存储 # 隐身模式(无痕模式) chrome_options.add_argument("--incognito") # 设置浏览器的下载参数 chrome_options.add_experimental_option( "prefs", { "download.default_directory": r"D:\pppp\第4章\批量下载的PDF文件\公告", # 指定文件下载路径。 "download.prompt_for_download": False, # 禁用下载提示对话框(直接开始下载)。 "download.directory_upgrade": True, # 启用目录升级,以确保文件下载到指定的文件夹。 "download_restrictions": 0, # 禁用下载保护,允许下载所有类型的内容。 "safebrowsing_for_trusted_sources_enabled": False, # 禁用针对受信任来源的安全浏览。 "safebrowsing.enabled": False, # 禁用安全浏览,允许下载被 Chrome 识别为不安全的文件。 }, ) # 说明: Selenium从4.10以后不再支持executeable_path参数了,需要使用service对象参数代替 browser = webdriver.Chrome(service=Service(chromedriver_path), options=chrome_options) browser.get( "http://www.cninfo.com.cn/new/disclosure/detail?orgId=9900014267&announcementId=1219372722&announcementTime=2024-03-22" ) try: # 找到下载链接并点击下载文件 browser.find_element( By.XPATH, '//*[@id="noticeDetail"]/div/div[1]/div[3]/div[1]/button' ).click() time.sleep(30) # 退出模拟浏览器。quit 必须要有,否则停留后台,需要在任务管理器中手动关闭 browser.quit() print("下载完毕") except: print("没有PDF文件")"python程序完整代码【批量】"
# 利用Selenium模块模拟鼠标单击"下一页"按钮 from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.chrome.options import Options from selenium.webdriver.chrome.service import Service import time import re # 1.获取公告总数和单页次数 browser = webdriver.Chrome() url = "http://www.cninfo.com.cn/new/fulltextSearch?notautosubmit=&keyWord=理财" browser.get(url) time.sleep(5) data = browser.page_source p_count = '<span class="total-box" style="">约 (.*?) 条' count = re.findall(p_count, data)[0] pages = int(int(count) / 10) # 2.用Selenium模块模拟单击”下一页“按钮 datas = [] datas.append(data) for i in range(1): browser.find_element( By.XPATH, '//*[@id="fulltext-search"]/div[2]/div/div/div[3]/div[3]/div[2]/div/button[2]', ).click() time.sleep(3) data = browser.page_source datas.append(data) time.sleep(3) # 3.将列表转换为字符串 alldata = "".join(datas) browser.quit() # 4.通过正则表达式提取公告标题和网址 p_title = '<span title="" class="r-title">(.*?)</a>' p_href = '<a target="_blank" href="(.*?)".*?<span title=' # 5.将提取公告标题和网址的正则表达式应用到汇总了所有页面源代码的字符串变量alldata中 title = re.findall(p_title, alldata) href = re.findall(p_href, alldata) # 6.对爬取到的数据进行清洗工作 for i in range(len(title)): title[i] = re.sub("<.*?>", "", title[i]) href[i] = "http://www.cninfo.com.cn" + href[i] href[i] = re.sub("amp;", "", href[i]) print(str(i + 1) + "." + title[i]) print(href[i]) # 7.批量下载下载PDF文件 def driver_download(): # 设置Chrome驱动本地目录 chromedriver_path = "C:\\Program Files\\Google\\Chrome\\Application\\chromedriver-win64\\chromedriver.exe" # 创建ChromeOptions对象并设置下载目录 chrome_options = Options() # 启用无头模式,隐藏 Chrome 窗口以在后台执行。 chrome_options.add_argument("--headless") # 禁用 GPU 加速。 chrome_options.add_argument("--disable-gpu") # 隐身模式(无痕模式) chrome_options.add_argument("--incognito") # 设置浏览器的下载参数 chrome_options.add_experimental_option( "prefs", { "download.default_directory": r"D:\pppp\第4章\批量下载的PDF文件\公告", # 指定文件下载路径。 "download.prompt_for_download": False, # 禁用下载提示对话框(直接开始下载)。 "download.directory_upgrade": True, # 启用目录升级,以确保文件下载到指定的文件夹。 "download_restrictions": 0, # 禁用下载保护,允许下载所有类型的内容。 "safebrowsing_for_trusted_sources_enabled": False, # 禁用针对受信任来源的安全浏览。 "safebrowsing.enabled": False, # 禁用安全浏览,允许下载被 Chrome 识别为不安全的文件。 }, ) # 说明: Selenium从4.10以后不再支持executeable_path参数了,需要使用service对象参数代替 browser = webdriver.Chrome( service=Service(chromedriver_path), options=chrome_options ) return browser for i in range(len(href)): browser = driver_download() browser.get(href[i]) try: # 找到下载链接并点击下载文件 browser.find_element( By.XPATH, '//*[@id="noticeDetail"]/div/div[1]/div[3]/div[1]/button' ).click() time.sleep(30) # 退出模拟浏览器。quit 必须要有,否则停留后台,需要在任务管理器中手动关闭 browser.quit() print("下载完毕") except: print("没有PDF文件")

3.使用urllib模块来进行网页的下载和保存
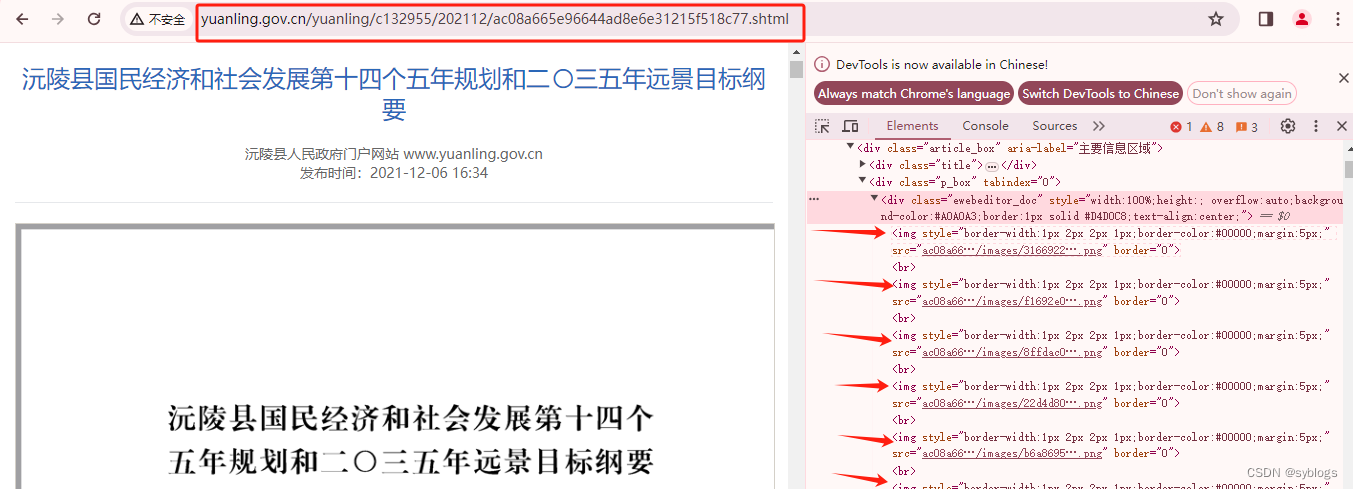
案例:网址:
沅陵县国民经济和社会发展第十四个五年规划和二〇三五年远景目标纲要 - 沅陵县人民政府
“Python程序完整代码”
import os.path from selenium import webdriver from selenium.webdriver.common.by import By from urllib.request import urlretrieve from selenium.webdriver.chrome.service import Service import time # 设置Chrome驱动本地目录 chromedriver_path = "C:\\Program Files\\Google\\Chrome\\Application\\chromedriver-win64\\chromedriver.exe" # 说明: Selenium从4.10以后不再支持executeable_path参数了,需要使用service对象参数代替 browser = webdriver.Chrome(service=Service(chromedriver_path)) url = "http://www.yuanling.gov.cn/yuanling/c132955/202112/ac08a665e96644ad8e6e31215f518c77.shtml" browser.get(url) time.sleep(2) # XPath选择所有图片 img_elements = browser.find_elements( By.XPATH, "/html/body/div[2]/div[2]/div[2]/div/img" ) # 循环遍历图片元素并下载图片 for img in img_elements: src = img.get_attribute("src") print(src.title()) # src为要下载文件的URL地址;filename参数用于指定下载后文件的保存路径和文件名。 urlretrieve(src, filename=os.path.join("D:\\pppp\\test\\", src.split("/")[-1])) # 关闭WebDriver browser.quit()"查看下载图片"
4.使用urllib&Selenium模块判断下载和保存
如果图片是Base64编码的,则会进行解码后保存;否则,会直接根据图片的源地址进行保存。
“Python程序完整代码”
import os.path from selenium import webdriver from selenium.webdriver.common.by import By from urllib.request import urlretrieve from selenium.webdriver.chrome.options import Options from selenium.webdriver.chrome.service import Service import time # 设置Chrome驱动本地目录 chromedriver_path = "C:\\Program Files\\Google\\Chrome\\Application\\chromedriver-win64\\chromedriver.exe" # 创建ChromeOptions对象并设置下载目录 chrome_options = Options() # 启用无头模式,隐藏 Chrome 窗口以在后台执行。 chrome_options.add_argument("--headless") # 禁用 GPU 加速。 chrome_options.add_argument("--disable-gpu") # 隐身模式(无痕模式) chrome_options.add_argument("--incognito") # 设置浏览器的下载参数 chrome_options.add_experimental_option( "prefs", { "download.default_directory": r"D:\pppp\test2", # 指定文件下载路径。 "download.prompt_for_download": False, # 禁用下载提示对话框(直接开始下载)。 "download.directory_upgrade": True, # 启用目录升级,以确保文件下载到指定的文件夹。 "download_restrictions": 0, # 禁用下载保护,允许下载所有类型的内容。 "safebrowsing_for_trusted_sources_enabled": False, # 禁用针对受信任来源的安全浏览。 "safebrowsing.enabled": False, # 禁用安全浏览,允许下载被 Chrome 识别为不安全的文件。 }, ) # 说明: Selenium从4.10以后不再支持executeable_path参数了,需要使用service对象参数代替 browser = webdriver.Chrome(service=Service(chromedriver_path), options=chrome_options) url = "http://www.yuanling.gov.cn/yuanling/c132955/202112/ac08a665e96644ad8e6e31215f518c77.shtml" browser.get(url) time.sleep(2) # XPath选择所有图片 img_elements = browser.find_elements( By.XPATH, "/html/body/div[2]/div[2]/div[2]/div/img" ) # 循环遍历图片元素并下载图片 counter = 1 for img in img_elements: try: # 获取图片的源地址 src = img.get_attribute("src") # 如果图片是Base64编码的,则需要解码并保存 if src.startswith("data:image"): import base64 data = src.split(",")[1] with open(f"image_{counter}.png", "wb") as file: file.write(base64.b64decode(data)) else: # 直接通过源地址保存图片 import urllib.request urllib.request.urlretrieve( src, filename=os.path.join("D:\\pppp\\test2\\", f"image_{counter}.png") ) counter += 1 except Exception as e: print(f"Error saving image: {e}") # 关闭浏览器 browser.quit()“下载保存结果展示”
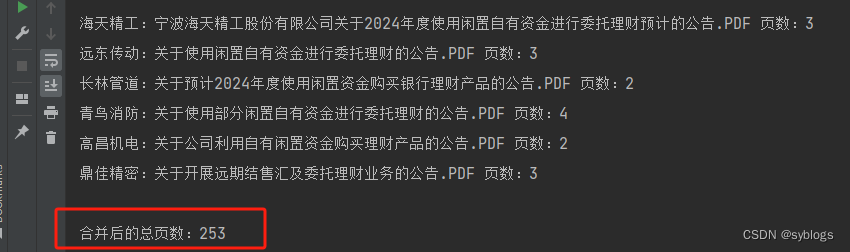
(二)批量合并 PDF 文件
“合并前PDF文件”
“Python完整程序代码”
# 导入pathlib模块中的Path()函数,用于完成路径相关操作 from pathlib import Path # 使用Python第三方模块PyPDF2来操控PDF文件.PdfReader类用于读取PDF文件,PdfMerger类用于合并PDF文件 from PyPDF2 import PdfReader, PdfMerger # 1.设置相关文件夹路径 src_folder = Path("D:\\pppp\\第4章\\批量下载的PDF文件\\公告\\") des_file = Path("D:\\pppp\\第4章\\批量下载的PDF文件\\公告\\合并后的公告文件.PDF") if not des_file.parent.exists(): des_file.parent.mkdir(parents=True) file_list = list(src_folder.glob("*.PDF")) # 2.逐个读取PDF文件并进行合并 merger = PdfMerger() outputPages = 0 for pdf in file_list: inputfile = PdfReader(str(pdf)) merger.append(inputfile) pageCount = len(inputfile.pages) print(f"{pdf.name} 页数:{pageCount}") outputPages += pageCount # 3.将合并后的PDF文件写入指定的路径中 merger.write(str(des_file)) # 4.关闭PdfFileMerger对象,释放占用的系统资源 merger.close() print(f"\n合并后的总页数:{outputPages}")“合并后的PDF文件”


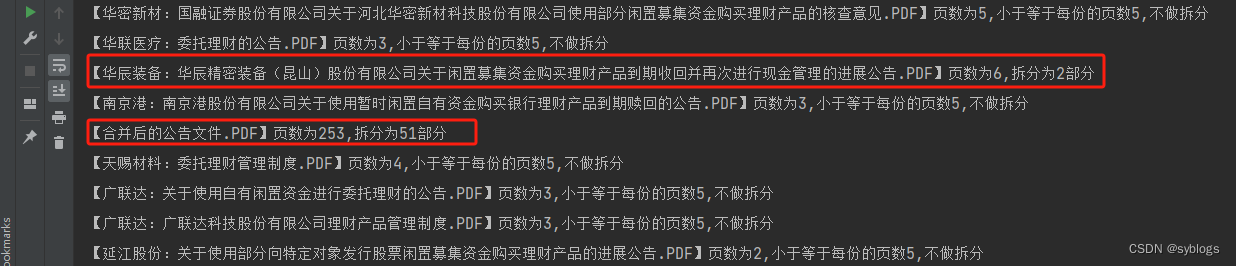
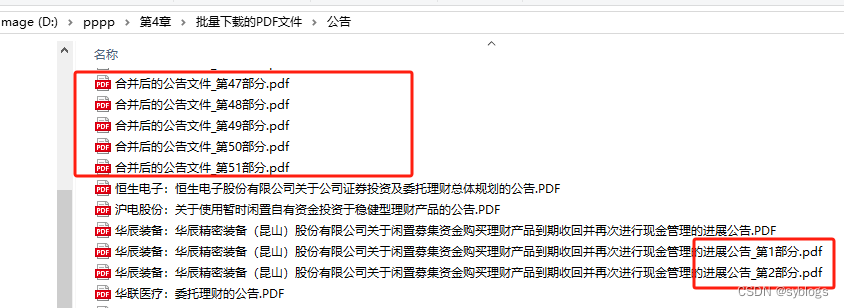
(三)批量拆分 PDF 文件
“Python程序完整代码”
# 采用按照固定页数进行拆分的方式 # 导入pathlib模块中的Path()函数,用于完成路径相关操作 from pathlib import Path # 使用Python第三方模块PyPDF2来操控PDF文件.PdfReader类用于读取PDF文件,PdfWriter类用于输出PDF文件 from PyPDF2 import PdfReader, PdfWriter # 1.0 设置相关文件夹路径 src_folder = Path("D:\\pppp\\第4章\\批量下载的PDF文件\\公告\\") file_list = list(src_folder.glob("*.PDF")) # 2.0 逐个读取PDF文件并获取页数,计算拆分后的份数,每份的页数设置为5 step = 5 for pdf in file_list: inputfile = PdfReader(str(pdf)) pages = len(inputfile.pages) if pages <= step: print(f"【{pdf.name}】页数为{pages},小于等于每份的页数{step},不做拆分") continue parts = pages // step + 1 # 3.0 根据份数进行循环,计算每一份的开始页码和结束页码 for pt in range(parts): start = step * pt if pt != (parts - 1): end = start + step - 1 else: end = pages - 1 # 4.0 拆分PDF文件,调用路径对象的stem属性获取文件的主名 outputfile = PdfWriter() for pn in range(start, end + 1): outputfile.add_page(inputfile.pages[pn]) pt_name = f"{pdf.stem}_第{pt+1}部分.pdf" pt_file = src_folder / pt_name with open(pt_file, "wb") as f_out: outputfile.write(f_out) # 5.0 输出拆分完毕的信息 print(f"【{pdf.name}】页数为{pages},拆分为{parts}部分")“批量拆分后的信息”
(四)批量加密 PDF 文件
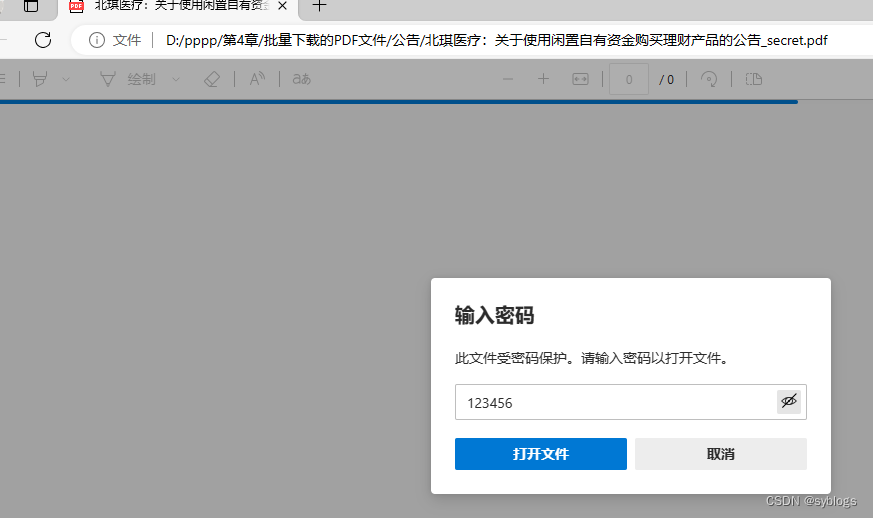
为PDF文件设置打开密码来防止泄密。
“Python完整代码”
""" 为PDF文件设置打开密码来防止泄密 """ # 导入pathlib模块中的Path()函数,用于完成路径相关操作 from pathlib import Path # 使用Python第三方模块PyPDF2来操控PDF文件.PdfReader类用于读取PDF文件,PdfWriter类用于输出PDF文件 from PyPDF2 import PdfReader, PdfWriter # 1.0 设置相关文件夹路径 src_folder = Path("D:\\pppp\\第4章\\批量下载的PDF文件\\公告\\") file_list = list(src_folder.glob("*.PDF")) # 2.0 逐个读取PDF文件 for pdf in file_list: inputfile = PdfReader(str(pdf)) outputfile = PdfWriter() pageCount = len(inputfile.pages) for page in range(pageCount): outputfile.add_page(inputfile.pages[page]) # 3.0 将PDF文件的打开密码设置为“123456” outputfile.encrypt("123456") # 4.0 设置加密后的PDF文件名 des_name = f"{pdf.stem}_secret.pdf" des_file = src_folder / des_name with open(des_file, "wb") as f_out: outputfile.write(f_out)“查看加密文件”
(五)批量为 PDF 文件添加水印
为了防止PDF文件内容被他人随意盗用,可以为PDF文件添加水印。
1.自定义函数创建水印文件
要批量添加水印,需准备一个PDF格式的水印文件。
“Python程序代码”
""" 为PDF文件添加水印,防止他人随意盗用 """ # 导入pathlib模块中的Path()函数,用于完成路径相关操作 from pathlib import Path # 使用Python第三方模块PyPDF2来操控PDF文件.PdfReader类用于读取PDF文件,PdfWriter类用于输出PDF文件 from PyPDF2 import PdfReader, PdfWriter # 使用Python第三方模块reportlab来制作水印文件 from reportlab.lib.units import cm from reportlab.pdfgen import canvas import reportlab.pdfbase.ttfonts def create_watermark(content): """ 自定义函数:创建水印文件,并对水印文字的字体,字号等格式进行设置 """ # 设置水印文件的文件名 file_name = "水印.PDF" # 设置水印文件的页面大小,默认大小是21cm×29.7cm a = canvas.Canvas(file_name, pagesize=(30 * cm, 30 * cm)) # 设置页面的坐标原点,默认(0,0)左下角 a.translate(5 * cm, 0 * cm) # 注册水印文字要使用的字体,注意:如果水印文字为中文,需使用显示中文的字体,否则水印文字会显示为乱码 reportlab.pdfbase.pdfmetrics.registerFont( reportlab.pdfbase.ttfonts.TTFont( "阿里巴巴普惠体", "D:\\pppp\\第4章\\Alibaba-PuHuiTi-Regular.ttf" ) ) # 设置水印文字的字体 a.setFont("阿里巴巴普惠体", 25) # 设置水印文字的旋转角度 a.rotate(30) # 设置水印文字的填充颜色 a.setFillColorRGB(0, 0, 0) # 设置水印文字的透明度 a.setFillAlpha(0.2) # 在页面绘制6行6列的水印文字 for i in range(0, 30, 5): for j in range(0, 30, 5): # drawString()的前两个参数为文字的坐标,第三个参数为文字的内容 a.drawString(i * cm, j * cm, content) a.save() return file_name
2.自定义函数添加水印
为每一页PDF都添加水印。
“Python程序代码”
def add_watermark(pdf_file_in, pdf_file_mark, pdf_file_out): """ 自定义函数:为每一页PDF文件添加水印 """ outputfile = PdfWriter() inputfile = PdfReader(pdf_file_in) pageCont = len(inputfile.pages) markfile = PdfReader(pdf_file_mark) # 读取PDF文件的每一页,与水印文件融合后添加到PdfWriter对象中 for i in range(pageCont): page = inputfile.pages[i] page.merge_page(markfile.pages[0]) outputfile.add_page(page) with open(pdf_file_out, "wb") as f_out: outputfile.write(f_out)
3.使用循环为每个PDF文件添加水印
“Python程序代码”
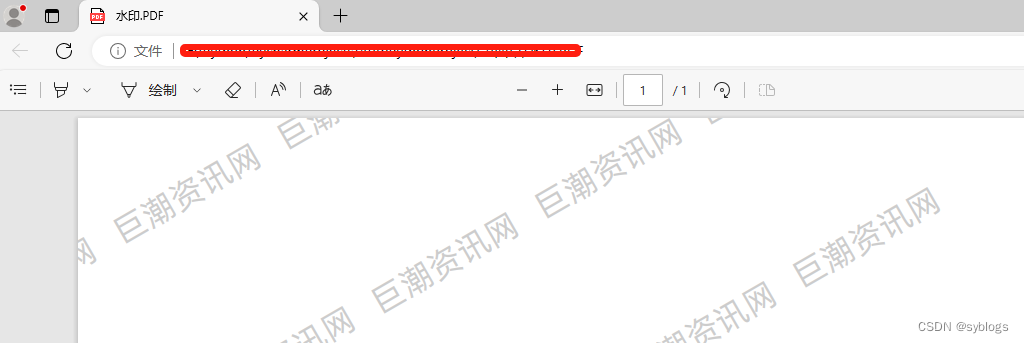
# 1.0 设置相关文件夹路径 src_folder = Path("D:\\pppp\\第4章\\批量下载的PDF文件\\公告\\") des_folder = Path("D:\\pppp\\第4章\\批量下载的PDF文件\\公告添加水印后\\") if not des_folder.exists(): des_folder.mkdir(parents=True) file_list = list(src_folder.glob("*.PDF")) # 2.0依次为每个PDF文件添加水印 for pdf in file_list: pdf_file_in = str(pdf) # 设置水印的文本内容 pdf_file_mark = create_watermark("巨潮资讯网") pdf_file_out = str(des_folder / pdf.name) add_watermark(pdf_file_in, pdf_file_mark, pdf_file_out)“水印文件查看”