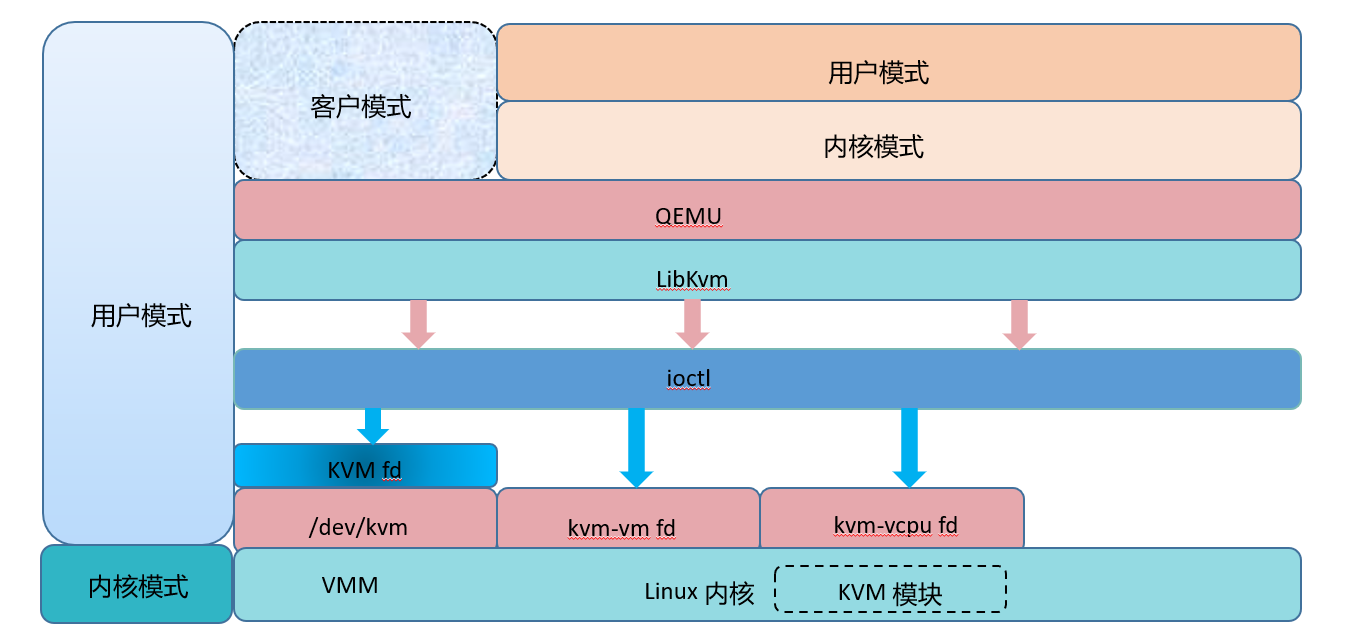
OceanBase作为一款原生分布式数据库,其核心的技术特性之一是高可扩展性,其具体表现在两个方面:
首先,是灵活的扩缩容能力,包括垂直扩缩容和水平扩缩容:
- 垂直扩缩容:指通过调整服务节点上的资源规格来改变服务能力的方法。举例来说,当服务节点在CPU或内存资源上遭遇瓶颈时,我们可以通过灵活地调整每个节点的CPU配置和内存大小,迅速提升服务能力。
- 水平扩缩容:指通过增减服务节点的数量来实现服务能力的调整。例如,从单个服务节点扩展为两个服务节点,可以实现服务能力的扩容。然而只支持服务节点数量的变化是不够的,为了实现业务读写服务能力的水平扩缩容,还需要支持数据重分布,比如从单个服务节点扩展为两个服务节点,让数据均衡地分布在两个服务节点上。反之,当两个服务节点缩容为单个服务节点时,需要让数据重分布到单个服务节点上。
其次,是数据动态均衡能力,即在服务节点不变的情况下,通过调整数据分布,以实现各个服务节点负载动态均衡的能力。例如,随着表和分区的动态创建和删除,不同服务节点上服务的分区个数会有很大差异,导致服务节点的负载不均衡,基于分区动态均衡能力,可以实现分区在各个服务节点上均衡分布,从而实现负载均衡。
无论是水平扩缩容,还是数据的动态均衡,本质上都是通过调整数据的分布以实现服务节点的负载均衡。因此,我们将水平扩缩容和数据动态均衡的能力统称为负载均衡能力。
OceanBase 各版本的负载均衡有何不同
OceanBase从1.x版本开始就具备灵活的扩展性,支持以分区为单位将数据打散分布在多个服务节点上,实现了动态扩缩容和分区自动均衡。
OceanBase 4.0版本升级为单机分布式一体化架构后,引入了自适应日志流概念,扩展性更加灵活,支持单机和分布式形态的动态变换。目前OceanBase 4.0和OceanBase 4.1 的扩展能力还不够完善,由于分区和日志流是静态的绑定关系,不支持动态调整分区分布,从而限制了自动负载均衡的能力,不支持部署形态的灵活变换。
OceanBase 4.2版本是首个完整实现单机分布式一体化架构的版本,具有里程碑意义。
OceanBase采用分区转移技术实现了日志流的分裂和合并,支持了以分区为单位进行跨节点的数据搬迁,完善了负载均衡策略,补齐了可扩展性能力,真正实现了单机和分布式形态的动态变换。
OceanBase支持多租户机制,不同租户间资源隔离,支持租户级别的水平扩缩容和分区均衡,下面将详细介绍OceanBase 4.2版本租户级别的负载均衡特性。
OceanBase v4.2租户级别的负载均衡特性
水平扩缩容
OceanBase支持从两方面来描述租户的服务能力:
- Unit Number,即每个Zone上提供服务的Unit个数。
- Primary Zone,即提供读写服务的Zone列表。
用户通过动态调整Unit Number和Primary Zone,可以实现租户的读写服务能力在Zone内和Zone间的水平扩缩容。负载均衡模块将根据用户服务能力的配置自适应调整日志流和分区分布。
用户可以通过下面的命令来调整租户的Primary Zone。
SQL> ALTER TENANT tenant PRIMARY_ZONE='zone1,zone2;zone3';
SQL> ALTER TENANT tenant PRIMARY_ZONE='RANDOM'; 当Primary Zone为RAMDOM时,调整Locality参数也会导致Primary Zone的变化。例如:Locality为从F@zone1,F@zone2,F@zone3变更为F@zone1,F@zone2,R@zone3时,RANDOM的Primary Zone配置意味着Primary Zone从zone1,zone2,zone3变更为了zone1,zone2。
SQL> ALTER TENANT tenant PRIMARY_ZONE='RANDOM';
SQL> ALTER TENANT tenant LOCALITY='F@zone1,F@zone2,R@zone3';用户可以通过下面的命令来调整租户每个Zone的Unit的个数,4.0版本开始,OceanBase要求每个Zone的Unit个数必须一样,因此,仅支持租户级别调整Unit个数的命令。为了方便统一管理各个Zone的Unit,引入了Unit Group机制,每个Zone相同编号的Unit属于同一个Unit Group。Unit个数的扩缩容本质上是以Unit Group为单位创建和删除Unit。
; 对于缩容场景,随机选择一个Unit Group删除
SQL> ALTER RESOURCE TENANT tenant_name UNIT_NUM = xxx;
; 对于缩容场景,删除 指定的Unit Group
SQL> ALTER RESOURCE TENANT tenant_name UNIT_NUM = xxx DELETE UNIT_GROUP = ( id_list )相比之前的版本,4.2版本新增支持了Unit缩容场景,可以统一减少每个Zone的Unit个数。发起缩容操作后,默认情况下,系统会随机选择一个Unit Group执行删除;用户也可以指定Unit Group列表,删除特定的Unit集合。Unit Group的列表可以在 DBA_OB_UNITS 表中查询。
分区均衡
分区均衡指:在表和分区动态变化的情况下,通过动态调整分区分布,实现分区个数以及存储空间在服务节点上的均衡。
OceanBase 支持多种表类型,包括:非分区表、一级分区表和二级分区表。不同类型的表的均衡策略不一样。为了方便描述均衡效果,OceanBase为不同的表分区划分了均衡组,在各个均衡组内要实现分区个数均衡和存储空间均衡。均衡组之间没有关系,内部自适应调整均衡组之间的分布关系。默认情况下,OceanBase的分区均衡策略如下。
- 一级分区表:每个一级分区表是一个独立的均衡组,表的所有一级分区打散分布在各个服务节点上。
- 二级分区表:每个一级分区下的所有二级分区形成一个独立的均衡组,每个一级分区下的所有二级分区打散分布在各个服务节点上。
- 非分区表:所有的非分区表统一考虑,有且只有一个均衡组,所有的非分区表打散分布在各个服务节点上。
另外,为了更加灵活描述不同表数据之间的聚集和打散关系,引入了TableGroup机制。
TableGroup机制
用户手册:OceanBase分布式数据库-海量数据 笔笔算数
OceanBase从1.x版本开始就引入了Table Group概念:Table Group是一个逻辑对象,代表一组表的集合,他们在物理存储上有临近关系。Table Group的引入是为了解决Partition Wise Join需求。多张具有关联关系的表往往遵守相同的分区规则,通过将相同规则的分区聚集分布在一起,可以实现Partition Wise Join,极大地优化读写性能。
从4.2版本开始,TableGroup概念有较大调整。
首先,不再支持Table Group上的分区属性,不再通过分区属性限制一个Table Group的表的分区方式,也不再支持Table Group相关的分区管理操作。
其次,为了兼容老版本创建Table Group的语法,带分区属性创建Table Group时并不会报错,会忽略分区属性。在OceanBase 4.0和OceanBase 4.1中如果创建了带分区属性的Table Group,升级到4.2版本后,将默认转换为不带分区属性的Table Group,行为上自动兼容。
再次,视图也进行了调整:DBA_OB_TABLEGROUPS的分区属性字段将不再有含义,展示为NULL;DBA_OB_TABLEGROUP_PARTITIONS/DBA_OB_TABLEGROUP_SUBPARTITIONS视图将废弃,不再展示数据。CDB相关视图调整同上。
最后,Table Group内分区的聚集和打散语义不再相同,OceanBase 4.2版本为Table Group引入了SHARDING属性,用于控制Table Group内表数据的聚集和打散关系。
那么,什么是SHARDING属性,在不同场景中它的取值和意义分表是什么?
Table Group中SHARDING属性的取值
Table GroupSHARDING属性有三种取值:NONE、PARTITION、ADAPTIVE。下面基于场景来描述OceanBase 4.2版本Table GroupSHARDING属性的取值和意义。
SHARDING属性的取值和意义
场景1:Table Group内所有表聚集在一起。
用户希望将任意类型的表聚集在一台机器上,以满足业务单机访问的需求。采用SHARDING = NONE的Table Group可以实现将任意类型的表聚集在一起。
SHARDING = NONE的Table Group含义如下:
- 支持加入任意分区类型的表,包括非分区表、一级分区表、二级分区表。
- 加入Table Group的所有表的所有分区聚集在一起,系统保证调度在一台机器上。
场景2:Table Group内表数据水平打散。
当单机无法承载单个业务的数据时,用户希望将数据打散分布在多台机器,实现水平扩展。OceanBase默认为不同分区类型的表提供了水平扩展和自动负载均衡的能力。
- 非分区表:所有的非分区表打散均匀分布在多台机器上。
- 一级分区表:表的所有一级分区打散分布在多台机器上。
- 二级分区表:每个一级分区的所有二级分区打散分布在多台机器上,不同一级分区间随机打散。
默认情况下,不同表之间数据是随机分布的,但无妨。如果希望多张具有关联关系的表数据分布相同,则需要明确不同表分区之间的对齐规则,从而将不同表的分区聚集在同一台server,实现Partition Wise Join,提升性能。采用SHARDING不为NONE的Table Group可以满足该需求。
SHARDING = NONE的Table Group描述了所有表的所有分区聚集在同一台server,并且不限制表的分区类型。
SHARDING不为NONE时,Table Group内每一张表的数据打散分布在多台机器上。为了保证所有表的数据分布相同,Table Group要求所有表的分区方式一致,包括分区类型、分区个数、分区Value。系统会调度具有相同分区属性的分区聚集(对齐)分布在同一台Server,从而实现Partition Wise Join。
下面描述不同SHARDING取值的含义以及对Table Group内表的影响。
PARTITION:按一级分区打散,如果是二级分区表,一级分区下的所有二级分区聚集在一起。- 分区方式要求:一级分区的分区方式相同,如果是二级分区表,也只校验一级分区的分区方式。因此,一级分区表和二级分区表可以同时存在,只要他们的一级分区的分区方式相同即可。
- 分区对齐规则:相同一级分区Value的分区聚集在一起,包括一级分区表的一级分区和二级分区表的对应一级分区下的所有二级分区。
ADAPTIVE:自适应打散方式。如果Table Group内是一级分区表,则按一级分区打散;如果Table Group内是二级分区表,则每个一级分区下的二级分区打散。- 分区方式要求:要么全部是一级分区表,要么全部是二级分区表。如果是一级分区表,则要求一级分区的分区方式相同;如果是二级分区表,则要求一级和二级分区方式都相同。
- 分区对齐规则:对于一级分区表,一级分区Value相同的分区聚集在一起;对于二级分区表,一级分区Value相同,并且二级分区Value相同的分区聚集在一起。
了解了SHARDING属性的取值和意义后,我们以具体示例来看如何使用。
SHARDING属性的取值示例
示例一:SHARDING = NONE。
SHARDING = NONE的Table Group内,无论何种分区方式的表的分区,都会聚集为一个Partition Group,分布在一台机器上。
SQL> CREATE TABLEGROUP TG1 SHARDING = 'NONE';
# 非分区表
SQL> CREATE TABLE T_NONPART (pk int primary key) tablegroup = TG1;
# 一级分区表
SQL> CREATE TABLE T_PART_2 (pk int primary key) tablegroup = TG1 partition by hash(pk) partitions 2;
# 二级分区表
SQL> CREATE TABLE T_SUBPART_2_2 (pk int, c1 int, primary key(pk, c1)) tablegroup = TG1 partition by hash(pk) subpartition by hash(c1) subpartitions 2 partitions 2;| Table | Partition Group |
| 0 | |
| T_NONPART | P0 |
| T_PART_2 | P0, P1 |
| T_SUBPART_2_2 | P0SP0, P0SP1, P1SP0, P1SP1 |
示例二:SHARDING = PARTITION。
SHARDING = PARTITION的Table Group里所有表都会看成是一级分区表,要求所有表的一级分区方式相同,而一级分区属性相同的分区会聚集成一个Partition Group。
SQL> CREATE TABLEGROUP TG1 SHARDING = 'PARTITION';
# 一级分区表
SQL> CREATE TABLE T_PART_2 (pk int primary key) tablegroup = TG1 partition by hash(pk) partitions 2;
# 二级分区表
SQL> CREATE TABLE T_SUBPART_2_2 (pk int, c1 int, primary key(pk, c1)) tablegroup = TG1 partition by hash(pk) subpartition by hash(c1) subpartitions 2 partitions 2;| Table | Partition Group | |
| 0 | 1 | |
| T_PART_2 | P0 | P1 |
| T_SUBPART_2_2 | P0SP0, P0SP1 | P1SP0, P1SP1 |
示例三:SHARDING = ADAPTIVE
Table Group要求所有表的一级和二级分区方式完全一致。一级分区表和二级分区表不支持在一个Table Group中。
一级分区表的Table Group:
SQL> CREATE TABLEGROUP TG_PART SHARDING = 'ADAPTIVE';
# 一级分区表
SQL> CREATE TABLE T1_PART_2 (pk int primary key) tablegroup = TG_PART partition by hash(pk) partitions 2;
# 一级分区表
SQL> CREATE TABLE T2_PART_2 (pk int primary key, c1 int) tablegroup = TG_PART partition by hash(pk) partitions 2;| Table | Partition Group | |
| 0 | 1 | |
| T1_PART_2 | P0 | P1 |
| T2_PART_2 | P0 | P1 |
二级分区表的Table Group:
SQL> CREATE TABLEGROUP TG_SUBPART SHARDING = 'ADAPTIVE';
# 二级分区表
SQL> CREATE TABLE T1_SUBPART_2_2 (pk int, c1 int, primary key(pk, c1)) tablegroup = TG_SUBPART partition by hash(pk) subpartition by hash(c1) subpartitions 2 partitions 2;
# 二级分区表
SQL> CREATE TABLE T2_SUBPART_2_2 (pk int, c1 int, c2 int, primary key(pk, c1)) tablegroup = TG_SUBPART partition by hash(pk) subpartition by hash(c1) subpartitions 2 partitions 2;| Table | Partition Group | |||
| 00 | 01 | 10 | 11 | |
| T1_SUBPART_2_2 | P0SP0 | P0SP1 | P1SP0 | P1SP1 |
| T2_SUBPART_3_3 | P0SP0 | P0SP1 | P1SP0 | P1SP1 |
相关视图
| 视图名称 | 说明 |
| DBA/CDB_OB_TABLE_LOCATIONS | 分区副本分布,包含分区详细信息。最常用的视图之一 |
| DBA/CDB_OB_LS_LOCATIONS | 日志流副本分布 |
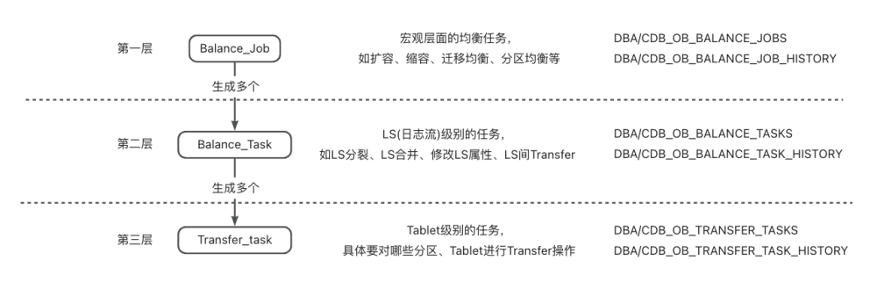
| DBA/CDB_OB_BALANCE_JOBS | 正在执行的负载均衡任务,如扩容、缩容、分区均衡等 |
| DBA/CDB_OB_BALANCE_JOBS_HISTORY | 负载均衡任务历史 |
| DBA/CDB_OB_BALANCE_TASKS | 正在执行的LS均衡任务,如LS分裂、LS合并等 |
| DBA/CDB_OB_BALANCE_TASK_HISTORY | LS均衡任务历史 |
| DBA/CDB_OB_TRANSFER_TASKS | 正在执行的分区转移(transfer)任务,tablet级别 |
| DBA/CDB_OB_TRANSFER_TASK_HISTORY | 分区转移(transfer)任务历史 |
| GV$OB_UNITS | unit分布及资源使用情况 |
| GV$OB_SERVERS | server分布及资源使用情况 |
负载均衡配置参数enable_rebalance
在上述负载均衡过程中,涉及一个控制参数enable_rebalance,该参数在OceanBase 4.2前的版本用于控制租户间的均衡是否开启。为了支持控制租户内的均衡,我们决定将enable_rebalance配置项变更为租户级别,不同租户下的配置项控制不同的均衡操作。
1. 在系统租户下控制是否做租户间均衡。
false:不会进行后台的unit迁移操作,但是在机器永久下线或者处于DELETING状态时,unit迁移不受配置项控制。true:机器可以通过unit迁移达到均衡态。
2. 在用户租户下控制是否做租户下的均衡。
false:租户内不在进行负载均衡操作,已经在进行中的均衡操作会取消。用户如果发起扩缩容操作时会报错,例如:- 租户的Unit Number增大缩小。
- 第一优先级的Primary Zone发生变化,如果第一优先级的Primary Zone不发生变化,则不会报错。
- Primary Zone为
RANDOM的情况下,F副本个数发生变化。
true:租户内可以执行负载均衡操作,如下。
# 均衡都关闭
alter system set enable_rebalance = false tenant = ALL;
#只开启租户间均衡
alter system set enable_rebalance = true tenant='sys';
#关闭租户间均衡,但是可以进行租户内均衡
alter system set enable_rebalance = false tenant='sys';
alter system set enable_rebalance = true tenant='mysql_tenant';总结
OceanBase 4.2版本的分区转移功能支持了以分区为单位灵活的跨节点搬迁数据的能力,弥补了因OceanBase 4.0版本架构升级而引入的问题,即无法在日志流间负载均衡的缺陷,真正实现了单机分布式一体化的灵活转化。
分区转移的源端日志流会有数秒卡DDL和用户写入,后续会优化为支持用户写入。 如果分区转移有跨节点的负载均衡任务,那么耗时和分区个数和数据量正相关。 需要转移的分区个数越多,转移的速度就越慢;需要转移的数据量越大,跨节点拷贝的速度也会越慢,主要受限于磁盘、网络的带宽瓶颈(网络限速默认参数为实际带宽的60%)。
需要说明的是,OceanBase 4.2版本的分区转移不支持活跃事务,预计在4.3版本实现支持。但是,提供了两种模式以满足不同使用的场景。
第一种模式是非紧急状态下的负载均衡,默认配置下,分区转移操作在业务低峰期没有活跃事务的时候执行。此操作对于业务是基本无感知的。
第二种模式是紧急运维负载均衡,需要用户手动开启分区转移主动杀事务的配置,分区转移会主动“杀死”对应日志流上的活跃事务,保证分区转移的顺利进行,但会对业务运行有一定影响。
另外,分区转移期间禁止部分DDL操作,如删除分区/Truncate分区、/删除表/Truncate表;分区分裂、合并;添加、删除局部索引;以及第一次添加LOB列,都会引发阻塞。