关联阅读博客文章:探讨在大数据体系中API的通信机制与工作原理
关联阅读博客文章:深入解析大数据体系中的ETL工作原理及常见组件
关联阅读博客文章:深度剖析:计算机集群在大数据体系中的关键角色和技术要点
关联阅读博客文章:深入理解HDFS工作原理:大数据存储和容错性机制解析
引言:
在当今数字化时代,数据已经成为企业成功的关键要素之一。随着数据量的不断增长和数据处理需求的不断提高,构建高效、可靠的大数据体系成为了企业面临的重要挑战之一。在这个过程中,Apache Kafka作为一个分布式流处理平台,扮演着至关重要的角色。它不仅提供了高吞吐量、低延迟的消息传输服务,还支持实时数据流处理和复杂的事件驱动架构。

概要:
从Kafka的工作原理、集群架构和应用场景三个方面对其进行深入探讨。首先,我们将介绍Kafka的基本概念和核心组件,包括Producer、Consumer、Broker等,并深入探讨其消息存储和分发机制。接着,我们将详细解析Kafka集群的架构设计,包括ZooKeeper的角色、分区和副本的管理以及故障恢复机制。最后,我们将探讨Kafka在大数据领域的应用场景,包括实时日志处理、数据管道和ETL、实时推荐系统、分布式事务处理以及流式数据处理等,并通过实际案例展示其在不同场景下的应用和价值。
1. Kafka的基本概念
在开始深入了解Kafka的工作原理之前,需要了解一些基本概念:
- Producer(生产者): 将数据发布到Kafka主题(Topic)的应用程序。
- Consumer(消费者): 从Kafka主题中读取数据的应用程序。
- Broker(代理): Kafka集群中的服务器,负责存储数据和处理数据传输。
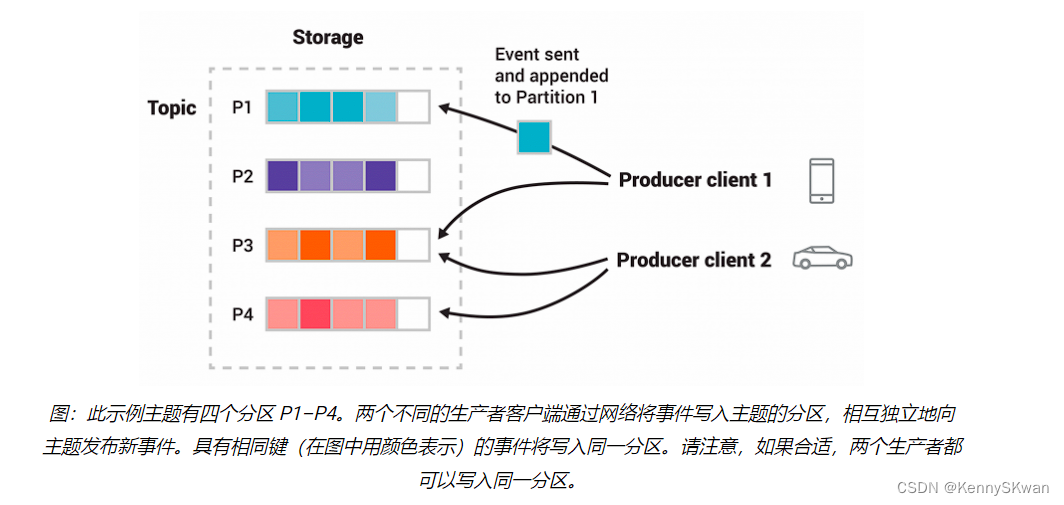
- Topic(主题): 数据发布的类别或分区。
- Partition(分区): 主题被分割成多个分区,每个分区在不同的服务器上。
- Offset(偏移量): 每个消息在分区中的唯一标识。
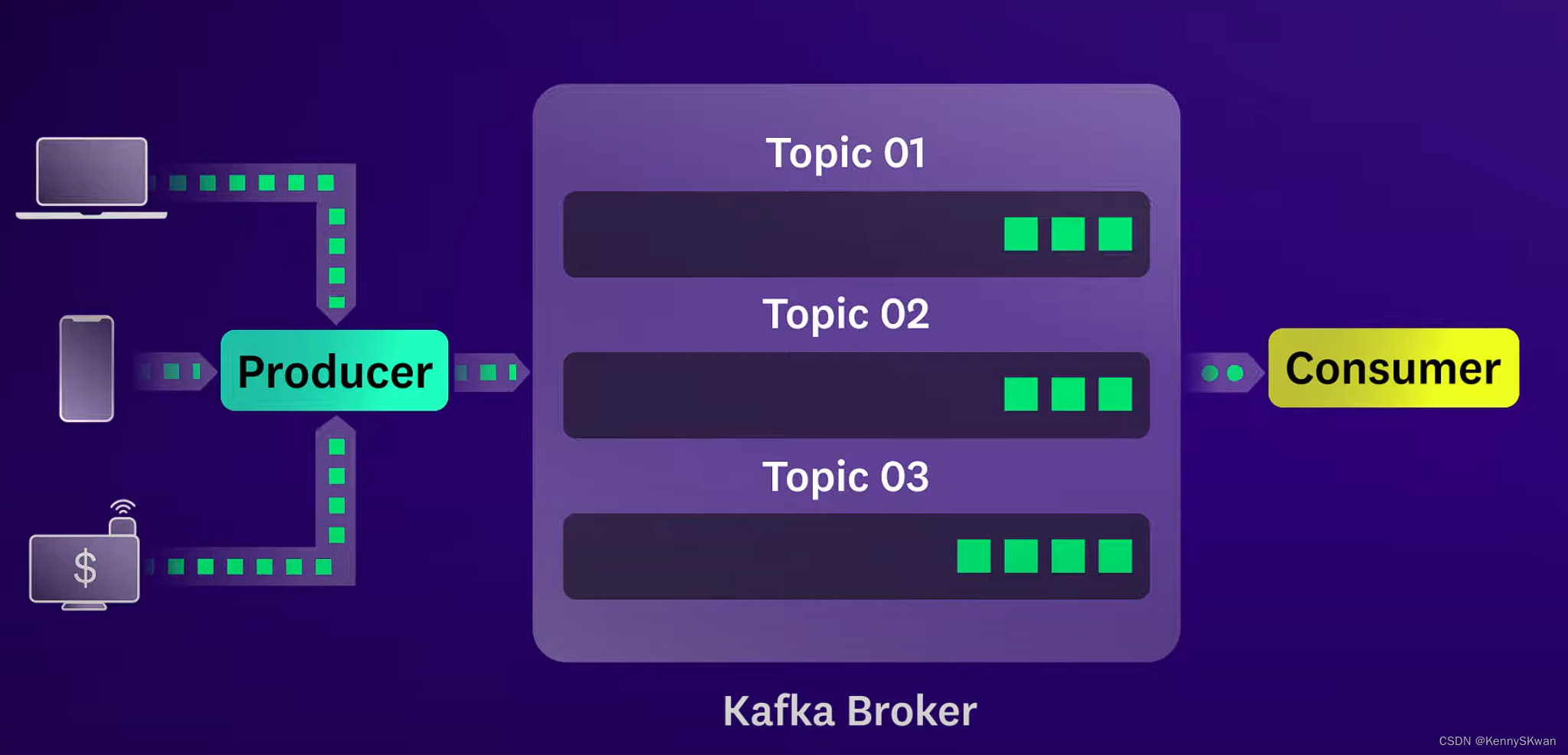
Kafka消息存储
- Kafka的消息存储是基于日志的,每个主题被分成一个或多个分区,每个分区是一个有序的消息队列。消息被追加到分区的末尾,并且保留一段时间(可以配置)。这种设计使得Kafka能够处理大量数据,并支持高吞吐量。
生产者发布消息
- 当生产者发送消息到Kafka时,它们首先连接到Kafka集群的一个Broker,并根据特定的分区策略将消息发布到一个或多个主题中的分区。生产者可以选择指定消息的键,这样消息将被发送到特定的分区,或者Kafka将基于负载均衡策略自动选择分区。
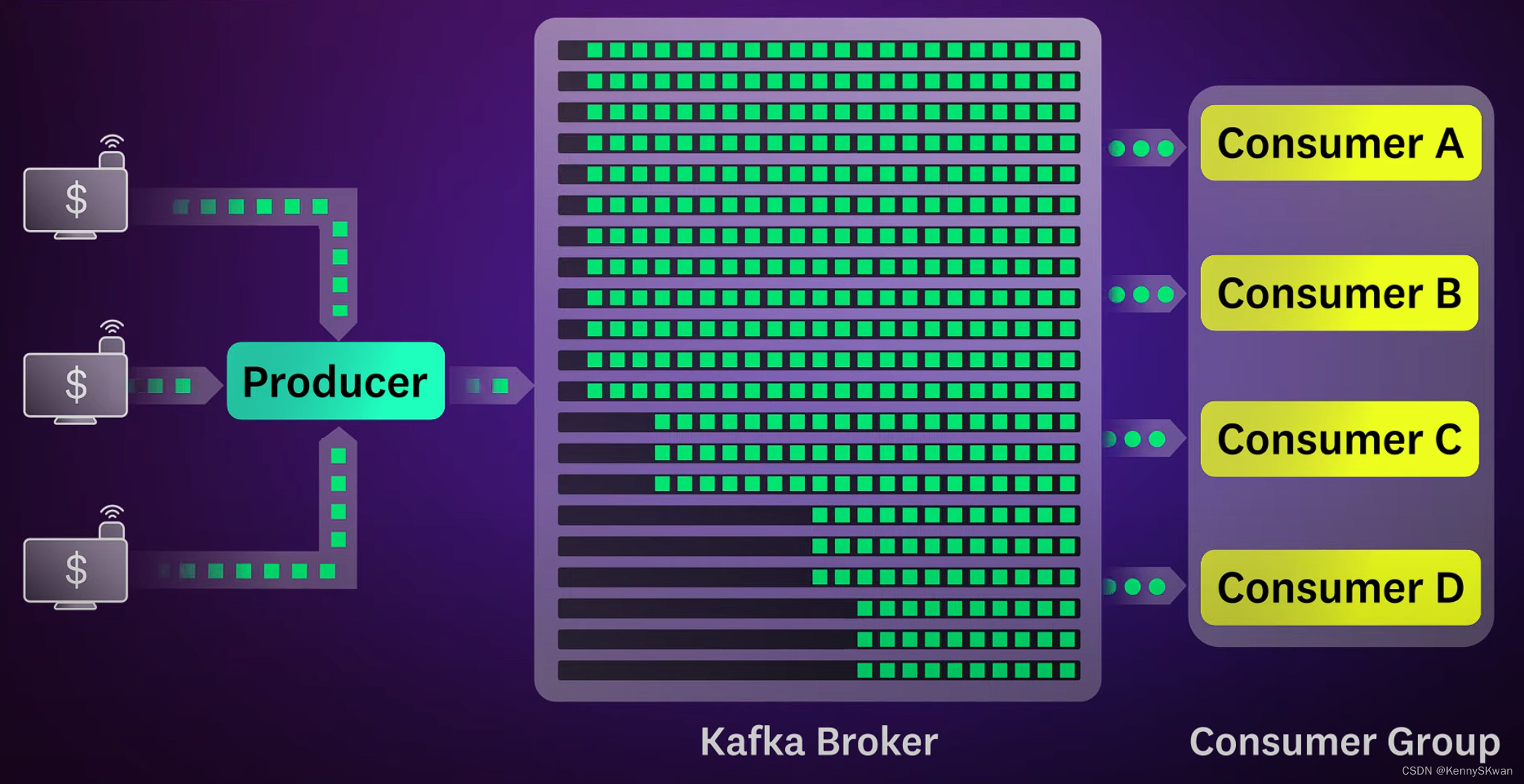
消费者消费消息
- 消费者从Kafka订阅一个或多个主题,并且会被分配到每个主题的一个或多个分区。消费者定期轮询Kafka Broker,拉取新的消息。一旦消费者拉取到消息,它们就会处理这些消息,并提交偏移量来记录自己的消费位置。
Kafka的水平扩展性
- Kafka通过分区和复制来实现水平扩展性和高可用性。分区允许数据水平分布在集群中的多个Broker上,从而允许Kafka处理大量数据。同时,Kafka通过复制每个分区到多个Broker上来提供容错性和可靠性。
2.Kafka集群组件
一个典型的Kafka集群包含以下组件:
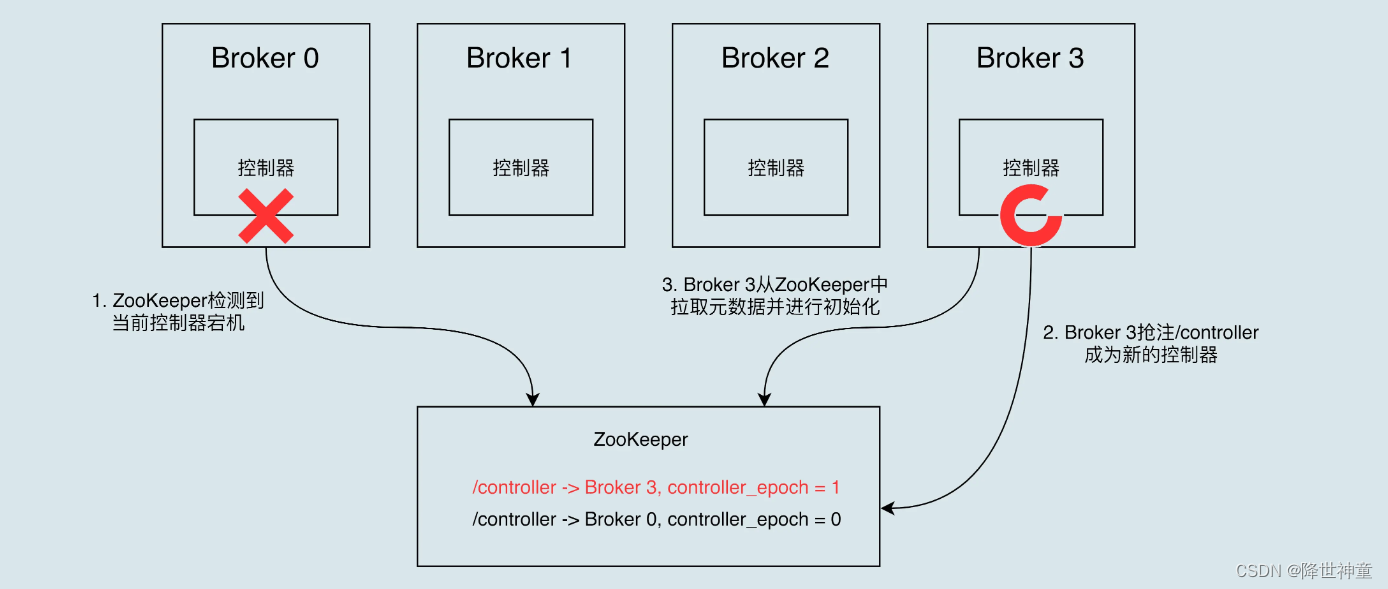
- ZooKeeper:
ZooKeeper是一个分布式协调服务,Kafka依赖它来进行集群管理和领导者选举。ZooKeeper保存了Kafka集群的元数据(如主题、分区、副本分配等),并且监控Kafka Broker的健康状态。 - Broker:
Broker是Kafka集群中的服务器节点,负责存储和处理数据。每个Broker都是一个独立的Kafka服务器,它们共同组成了整个Kafka集群。 - Topic:
Topic是消息发布的类别或分区。在集群中,每个Topic都被分成一个或多个分区,这些分区分布在不同的Broker上。 - Partition:
Partition是Topic的子集,每个分区都是一个有序的消息队列。分区允许数据在多个Broker上进行并行处理,从而提高了吞吐量和可扩展性。
Kafka集群工作原理
- 启动:
当Kafka Broker启动时,它会向ZooKeeper注册自己的信息,包括主机名、端口号等。ZooKeeper会维护所有Broker的信息,并监控它们的健康状态。 - 元数据管理:
ZooKeeper保存了Kafka集群的元数据,包括Topic、分区、副本分配等信息。这些元数据被用来协调Broker之间的消息路由和复制。 - Leader-Follower模式:
对于每个分区,Kafka会选举出一个Broker作为Leader,并将其他Broker设置为Follower。Leader负责处理所有的读写请求,而Follower则负责复制Leader的数据。当Leader失效时,ZooKeeper会协助选举新的Leader。 - 消息发布和消费:
生产者将消息发布到指定的Topic,Kafka根据分区策略将消息分配到各个分区中。消费者从Topic订阅消息,并根据分配的分区拉取数据。Kafka会保证消息的顺序性和一致性,以及消费者的负载均衡。 - 水平扩展:
Kafka通过增加Broker节点和分区来实现水平扩展。每个Broker负责处理一部分数据和请求,从而提高了集群的吞吐量和容量。
Kafka集群的可靠性和容错性
- 副本复制:
每个分区都有多个副本,它们分布在不同的Broker上。当Leader失效时,Kafka会自动选择一个副本作为新的Leader,从而保证数据的可用性。 - ISR机制:
Kafka使用ISR(In-Sync Replicas)机制来确保副本之间的一致性。只有处于ISR中的副本才会被选举为新的Leader,这样可以防止数据丢失和不一致。 - 故障恢复:
当Broker或者分区发生故障时,Kafka会自动进行故障恢复,包括重新选举Leader和同步数据等操作。
3.Kafka在大数据的应用场景
实时日志处理
- 实时日志处理是Kafka的一个典型应用场景。许多大型互联网企业和在线服务需要实时收集、处理和分析海量日志数据,以监控系统运行状况、进行故障排查和提供用户行为分析等功能。Kafka作为一个高吞吐量、低延迟的消息队列,可以用来收集和传输日志数据,同时支持流式处理引擎(如Apache Spark、Apache Flink等)进行实时分析和计算。
数据管道和ETL
- Kafka常用于构建数据管道和ETL(Extract, Transform,Load)流程,用于将数据从源系统提取、转换和加载到目标系统中。例如,一个企业可能需要将来自各种数据源(如数据库、日志文件、传感器等)的数据集成到一个数据湖或数据仓库中,以支持数据分析和决策制定。Kafka可以作为数据管道的中间件,用来传输和缓存数据,并保证数据的可靠性和一致性。
实时推荐系统
- 实时推荐系统需要快速响应用户行为,并向用户推荐个性化的内容或产品。Kafka可以用来收集和分析用户行为数据,并将结果传输给推荐算法模型进行实时计算和推荐。通过结合Kafka与实时计算引擎(如Apache Storm、Apache Samza等),可以实现高效的实时推荐服务,提升用户体验和业务价值。
分布式事务处理
- Kafka提供了分布式事务支持,可以用来实现分布式系统中的事务性消息处理。这在金融领域、电子商务等需要确保数据一致性和可靠性的场景中尤为重要。通过Kafka的事务功能,可以实现跨多个服务和系统的原子性操作,确保数据的完整性和一致性。
流式数据处理
- Kafka与流式处理引擎(如Apache Kafka Streams、Apache Flink等)的集成,可以实现实时数据流的处理和分析。这对于实时监控、实时预测和实时反馈等场景非常有用,例如智能工厂的实时生产监控、智能交通的实时流量调度等。
Kafka的局限性
- 复杂性:Kafka的分布式特性、多种配置和调优参数使得设置、维护和操作变得复杂。
- 有限的数据保留:Kafka并不是为长期数据存储而设计的。其主要功能是实时数据处理和消息传递。
- 有限的查询能力:与数据库不同,Kafka不支持查询能力。它只是一个消息传递系统。
- 缺乏完整的安全措施:Kafka缺乏某些安全功能,例如基于角色的访问控制,并且缺乏一些更高级的安全功能。
扩展阅读:
kafka官方手册