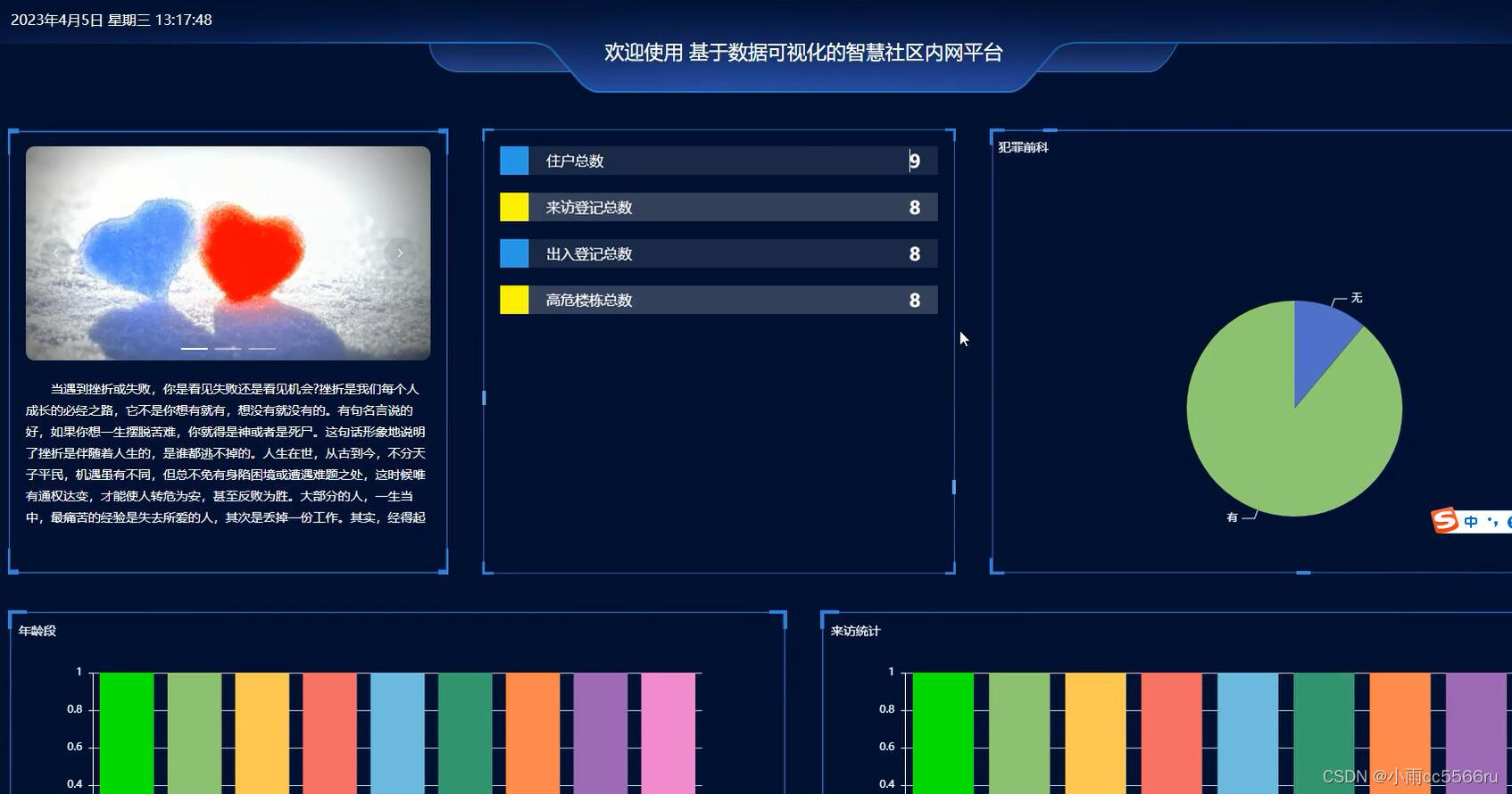
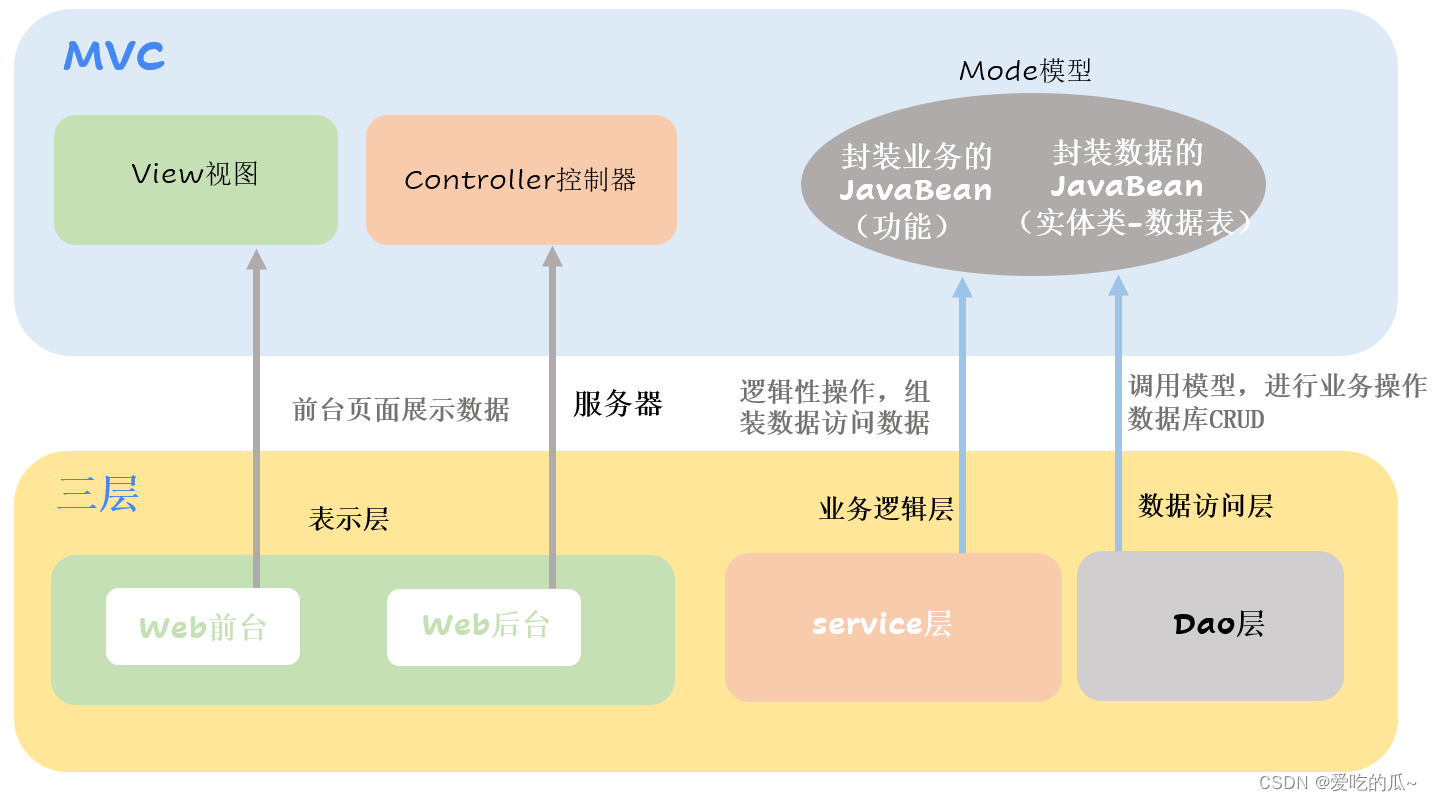
在介绍存储引擎之前我们先了解了解MySQL的体系结构:

-
连接层
最上层是一些客户端和链接服务,主要完成一些类似于连接处理、授权认证、及相关的安全方案。服务器也会为安全接入的每个客户端验证它所具有的操作权限
-
服务层
第二层架构主要完成大多数的核心服务功能,如SQL接口,并完成缓存的查询,SQL的分析和优化,部分内置函数的执行,所有跨存储引擎的功能也在这一层实现,如过程、函数
-
引擎层
存储引擎真正的负责了MySQL中数据的存储和提取,服务器通过API和存储引擎进行通信,不同的存储引擎具有不同的功能,可根据所需选取合适的存储引擎
-
存储层
主要是将数据存储在文件系统之上,并完成存储引擎的交互
存储引擎的一些常用命令
- 查看MySQL提供的所有存储引擎:
mysql> show engines; 从上图我们可以查看出 MySQL 当前默认的存储引擎是InnoDB,并且在5.7版本所有的存储引擎中只有 InnoDB 是事务性存储引擎,也就是说只有 InnoDB 支持事务。
从上图我们可以查看出 MySQL 当前默认的存储引擎是InnoDB,并且在5.7版本所有的存储引擎中只有 InnoDB 是事务性存储引擎,也就是说只有 InnoDB 支持事务。 - 查看MySQL当前默认的存储引擎
mysql> show variables like '%storage_engine%'; - 查看表的存储引擎
show table status like "table_name";
存储引擎简介
存储引擎就是存储数据、建立索引、更新/查询数据等技术实现方式,存储引擎是基于表的,而不是基于库的所以存储引擎,也可以被称为表类型
InnoDB存储引擎
-
介绍:InnoDB是一种兼顾高可靠性高和高性能的通用存储引擎,在MySQL5.5之后,InnoDB是默认的MySQL存储引擎
-
特点
DML(增删改)操作遵循ACID(事务四大特性)模型,支持事务;
行级锁,提高并发访问性能
支持外链FORELGN KEY约束,保证数据的完整性和正确性
-
文件
xxx.ibd:xxx代表的是表明,innoDB引擎的每张表都会对应这样一个表空间文件,存储该表的表结构、数据和索引
-

MyISAM存储引擎
-
介绍:MyISAM是MySQL早期的默认存储引擎
-
特点
-
不支持事务,不支持外键
-
支持表锁,不支持行锁
-
访问速度快
-
-
文件
-
xxx.sdi:存储表结构信息
-
xxx.MYD:存储数据
-
xxx.MYI:存储索引
-
Memory
-
介绍:Memory引擎的表数据时存储在内存中,由于受到硬件问题、或断电问题的影响,只能将这些表作为临时表或缓存使用。
-
特点
-
内存存放
-
hash索引
-
-
文件
-
xxx.sdi:存储表结构信息(其它信息在内存中)
-
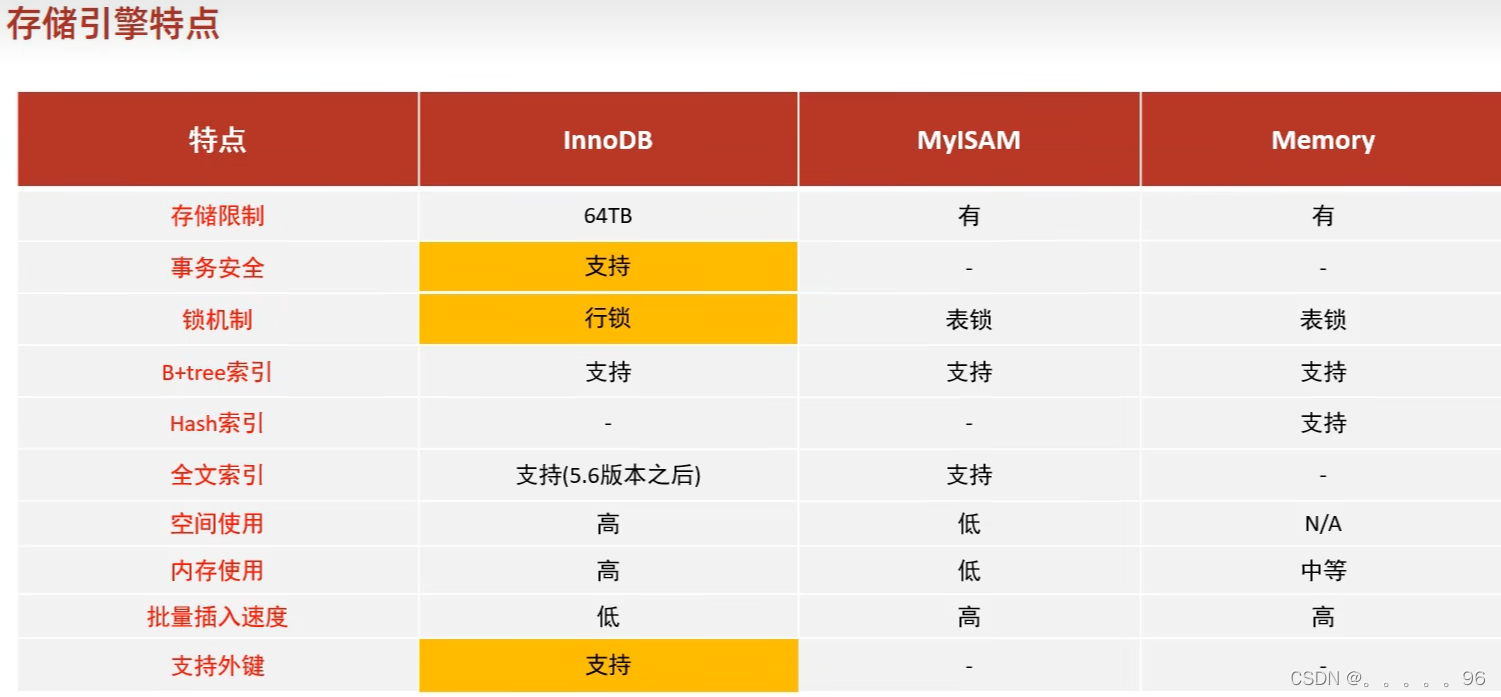
MyISAM和InnoDB区别
MyISAM是MySQL的默认数据库引擎(5.5版之前)。虽然性能极佳,而且提供了大量的特性,包括全文索引、压缩、空间函数等,但MyISAM不支持事务和行级锁,而且最大的缺陷就是崩溃后无法安全恢复。不过,5.5版本之后,MySQL引入了InnoDB(事务性数据库引擎),MySQL 5.5版本后默认的存储引擎为InnoDB。
大多数时候我们使用的都是 InnoDB 存储引擎,但是在某些情况下使用 MyISAM 也是合适的比如读密集的情况下。(如果你不介意 MyISAM 崩溃恢复问题的话)。
两者的对比:
-
是否支持行级锁 : MyISAM 只有表级锁(table-level locking),而InnoDB 支持行级锁(row-level locking)和表级锁,默认为行级锁。
-
是否支持事务和崩溃后的安全恢复: MyISAM 强调的是性能,每次查询具有原子性,其执行速度比InnoDB类型更快,但是不提供事务支持。但是InnoDB 提供事务支持,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
-
是否支持外键: MyISAM不支持,而InnoDB支持。
-
是否支持MVCC :仅 InnoDB 支持。应对高并发事务, MVCC比单纯的加锁更高效;MVCC只在
READ COMMITTED和REPEATABLE READ两个隔离级别下工作;MVCC可以使用 乐观(optimistic)锁 和 悲观(pessimistic)锁来实现;各数据库中MVCC实现并不统一。 -
索引:
-
MyISAM: B+Tree 叶节点的data域存放的是数据记录的地址。在索引检索的时候,首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
-
InnoDB: 其数据文件本身就是索引文件。相比MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按B+Tree组织的一个索引结构,树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。这被称“聚簇索引(或聚集索引)”。而其余的索引都作为辅助索引,辅助索引的data域存储相应记录主键的值而不是地址,这也是和MyISAM不同的地方。在根据主索引搜索时,直接找到key所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。
-