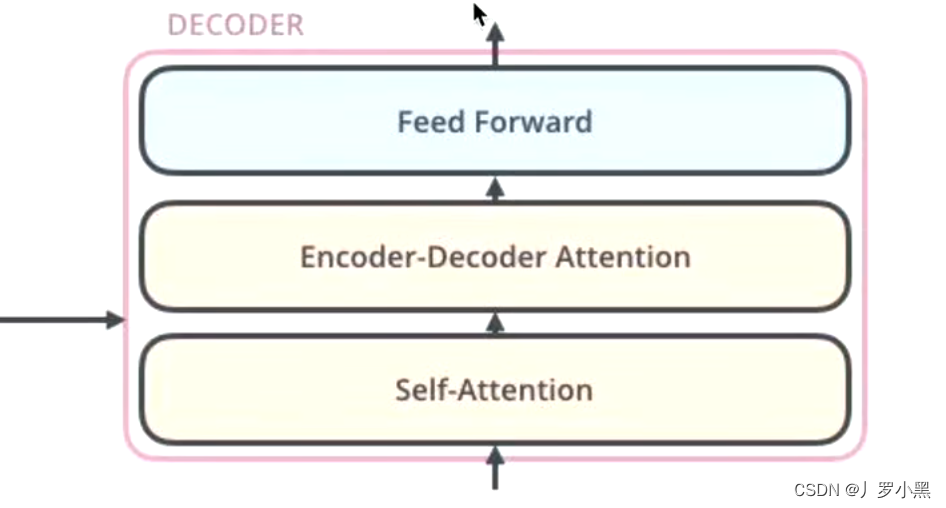
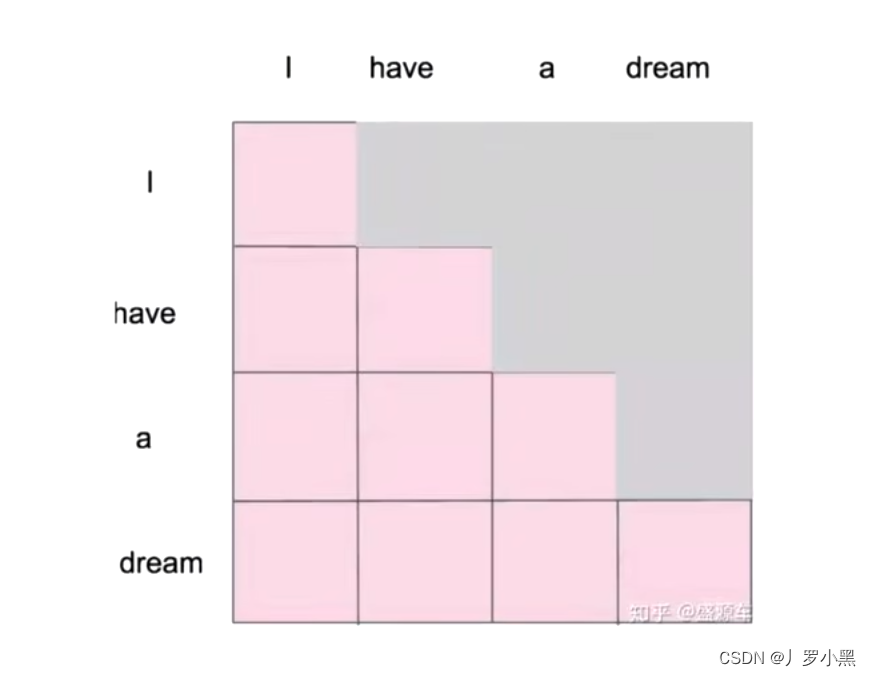
Transformer的Decoder为什么要用掩码(Masked Self-Attention)
- 机器翻译中:源语句(我爱中国),目标语句(I love China)
- 为了解决训练阶段和测试阶段不匹配的问题:
- 在训练阶段,我们已知目标语句,而且解码器的输入是目标语句,也就是会把将要生成的句子给解码器,为了让解码器的参数更加适配,让解码器更好的生成,即在训练阶段,每一次都会把目标语句的所有信息告诉解码器
- 在测试阶段,我们不知道目标语句,但是解码器也有输入,此时的输入为已经生成的词,所以每生成一个词,就会多一个词作为输入放进解码器,即在测试阶段,每一次都会把目标语句的部分信息告诉解码器
- 综上,为了解决这个不匹配的问题,我们使用Masked Self-Attention,把不应该提前告诉解码器的部分先隐藏起来
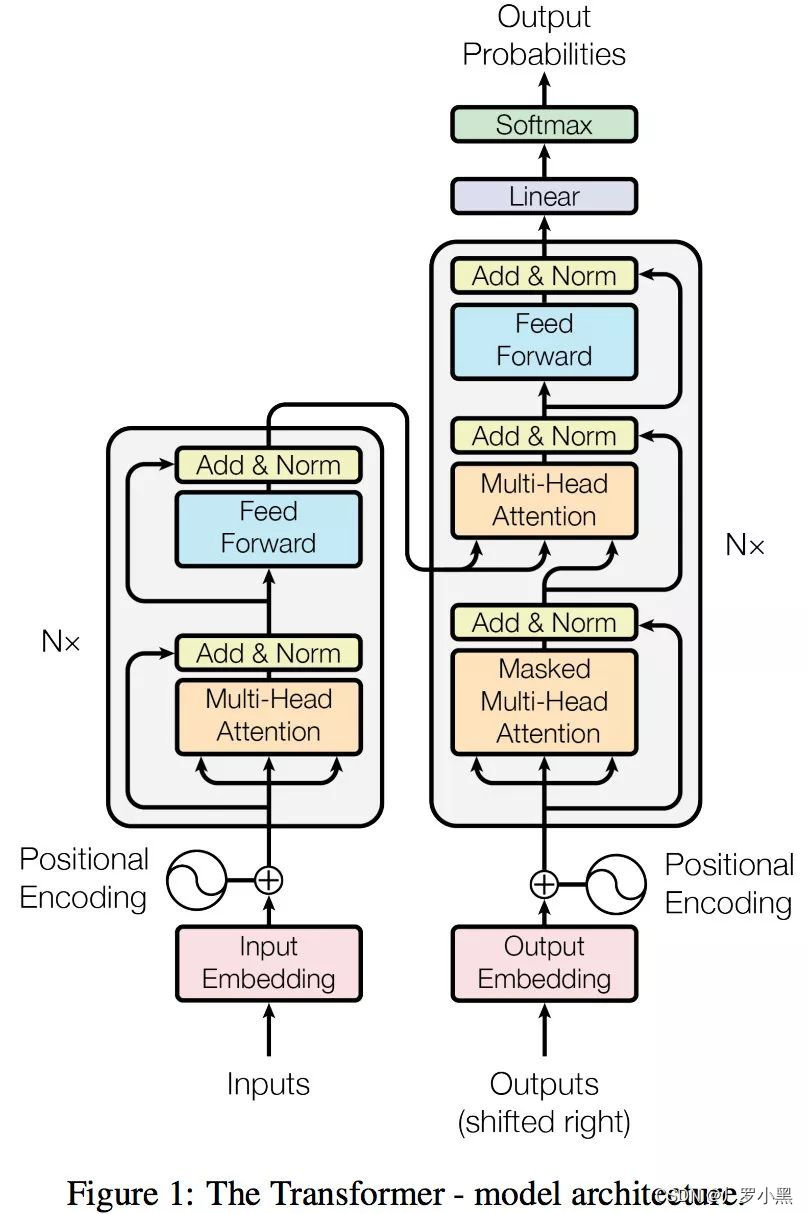
Transformer的Encoder给与Decoder的为什么是K、V矩阵
- 首先此处的Attention并不是自注意力,由于K、V同源,但是Q与K、V不同源,所以不能做自注意力
- Q是查询变量,即已经生成的词,K=V是源语句,
- 因此当我们要生成这个词的时候,通过Q和K、V做注意力,就能确定源语句中哪些词对将要生成的词更有作用
- 相反,如果Encoder给Decoder的是Q矩阵,那么我们生成的词作为K、V在Q中查询,这相当于用全部信息在部分信息里查询,这做反了。
Transformer的输入输出是什么
- 由于计算机只认识01,所以我们不能将现实世界的东西直接输入进模型,同时模型的输出也不直接是现实世界的东西,需要进行转换,如模型的输入输出为张量
- 机器学习的本质是:wx+b,深度学习的本质是:sigma ( wx+b ) ,即AI的本质是将现实世界的某个东西能映射到空间中的某个点,模型就相当于一个映射机,而训练的过程就是不断修正映射关系
- 在机器翻译中,inputs指现实世界中的语句,而input embedding是将它张量化后的张量,同时由于模型会反向传播来更新参数,所以输入张量可以任选,Word2Vec、ELMO、one-hot、甚至随机初始化也可,只是模型最后训练次数以及训练效果有差异。output probabilities为词典大小的概率向量,如下:
总结
- Transformer解决了以前seq2seq框架的问题,以前用lstm做编码器,再用lstm做解码器,这种方法每一次生成词,都是通过编码器生成的源语句全部信息的词向量,而lstm会有长依赖问题,所以前面的信息会有丢失,而Attention可以重点寻找,这解决了seq2seq框架的问题
参考文献
- 19 Transformer 解码器的两个为什么(为什么做掩码、为什么用编码器-解码器注意力)