本篇博客对应“2.3 会话管理”小节
视频名称:会话管理
视频链接
什么是HTPP协议?
HTTP,Hpyer Text Transfer Protocl:定义了浏览器怎样从(万维网客户进程)怎样向Web服务器(万维网服务器)请求Web文档(万维网文档),以及万维网服务器怎样把万维网文档传送给浏览器。
使用用户主机访问百度的万维网服务器,可以看成是用户主机中的浏览器进程(即客户进程),与服务器中的服务器进程,基于因特网的通信。
1、浏览器进程首先发起与服务器进程的tcp连接,使用熟知端口号80
2、基于这条已建立好的tcp连接,浏览器进程向服务器进程发送http请求报文。
3、服务器进程收到后,执行相应操作。然后给浏览器发送http响应报文。
http报文格式,http是面向文本的,报文中的每一个字段都是一些ASCII码串,并且每个字段的长度都是不确定的。什么是ASCII码?我们终端上看到的各种字符、文字在计算机底层都是二进制数,哪一个符号对应哪一个二进制数,这都是有编码的。
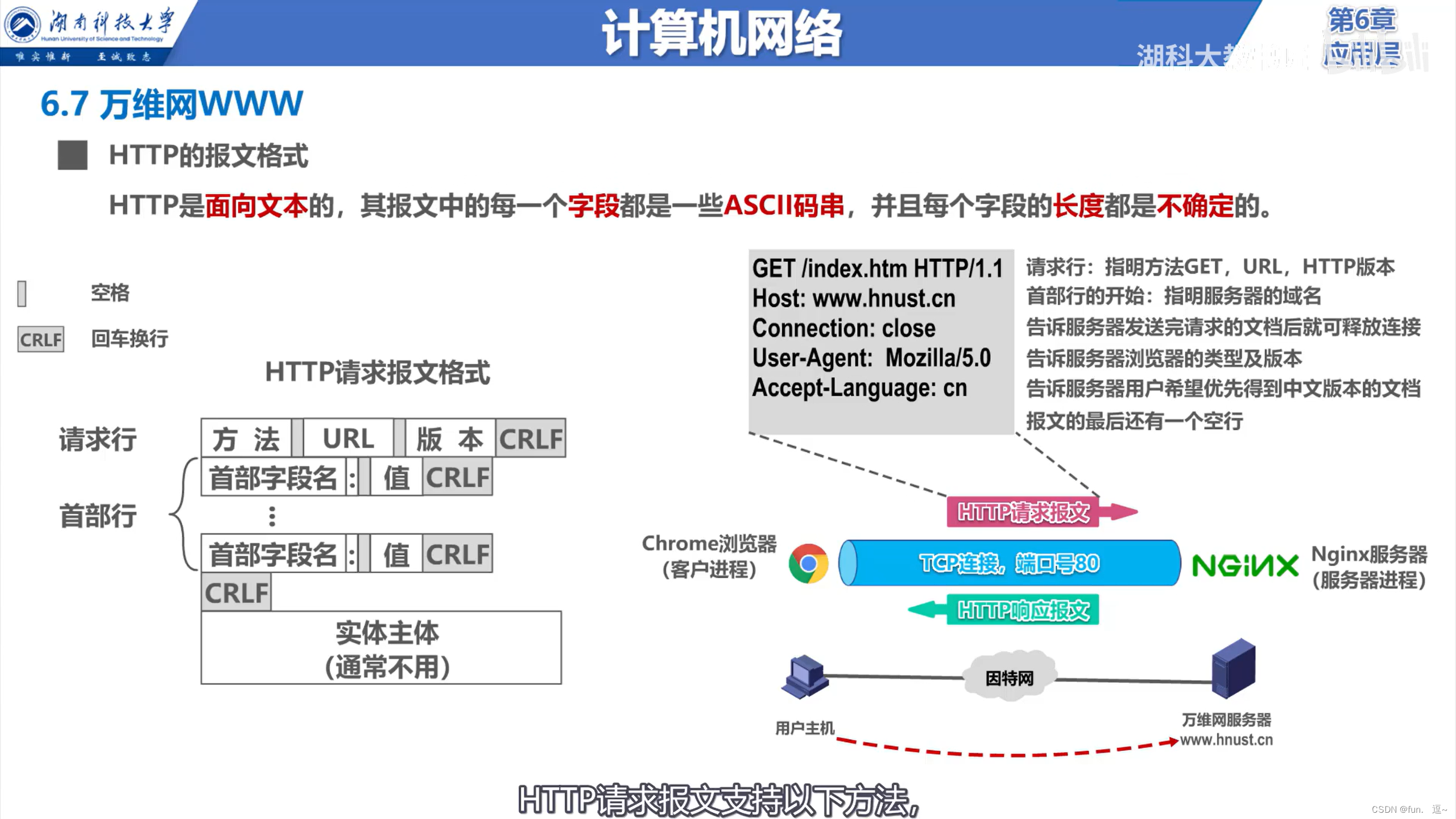
图片来源:https://www.bilibili.com/video/BV1c4411d7jb?p=73&vd_source=4429c4782cfe0a22523a00fa5bf3f7e6
HTTP响应报文格式

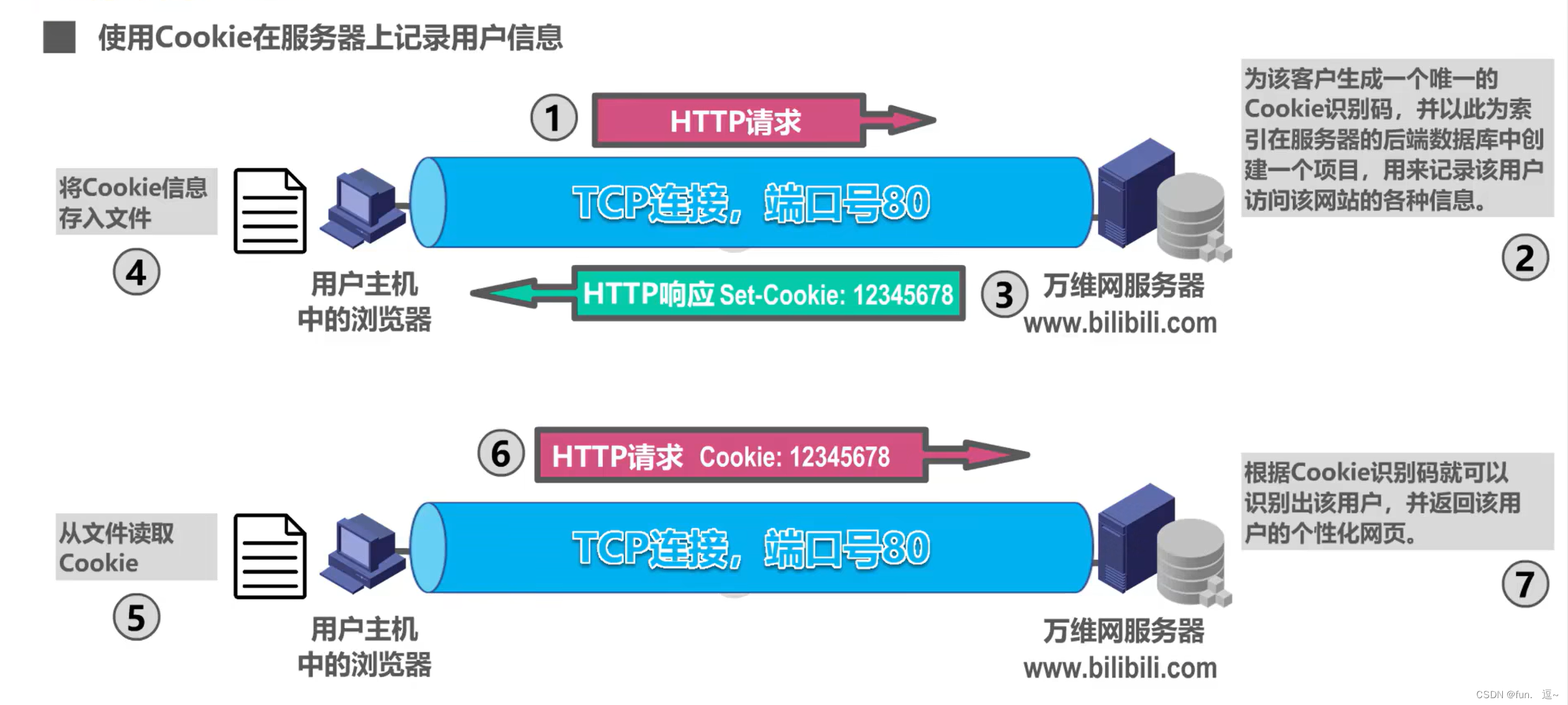
在我们浏览网站时,浏览器通常会使用Cookie在服务器上记录用户信息
由于历史原因,早期的万维网应用非常简,用户仅仅是查看存放在不同服务器上的各种静态文档,所以用户的前后操作之间是没有关系的。每一次操作都是一次http请求,所以早期的时候设计者认为前后两次http请求是没有关联的。因此,http被设计成为一种无状态协议,这样可以简化服务器的设计。
随着网页变得越来越复杂,电商网站这类出现,必须要让服务器识别到前后两次请求是同来自同一个一个用户的,它们是有关联的。而由于http本身已经被设计成为无状态,无法从http请求报文中看出它与哪个请求有关联。
例如:
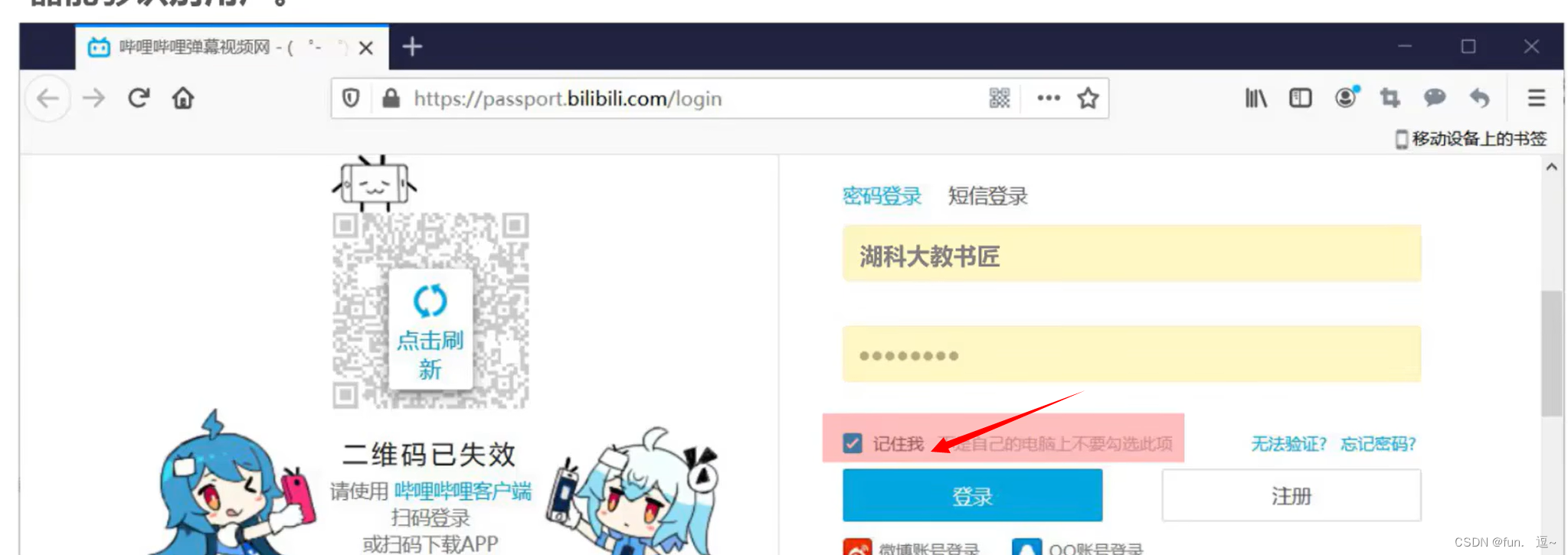
选择记住我选项,在第一次登录请求通过后,关闭该页面,再次访问b站,又是一次新的请求。这次请求在用户看来,我已经登录过了前后两次请求是有关联的,都是我这个用户在请求。但是,http是无状态,服务器无法仅通过http请求报文知道这次请求是和上次登录请求是有关联的。这就需要用到Cookie技术。
Cookie提供了了一种机制,使得万维网服务器能够记住用户,而无需用户主动提供用户表示信息。也就是说:Cookie是一种对无状态的http协议进行状态话的技术。
Cookie的工作原理:
- 用户主机中的浏览器进程,与万维网服务器中的服务器进程建立tcp连接
- 当用户的浏览器进程初次向服务器进程发送http请求报文时,服务器进程会为其产生一个唯一的Cookie识别码。并以此为索引,在服务器的后端数据库中,创建一个项目,用来记录该用户访问该网站的各种信息。
- 服务器进程向浏览器发回http响应报文,在响应报文中,包含有一个首部字段为set-cookie的首部字段行。该字段的取值,就是Cookie识别码。
- 浏览器进程收到该响应报文之后,就在一个特定的Cookie文件中添加一行。记录该服务器的域名和Cookie的识别码。
- 当用户再次使用这个浏览器访问这个网站时,每发送一个http请求报文,浏览器都会从这个Cookie文件中,取出该网站的Cookie识别码,并放到gttp请求报文的Cookie首部行中。服务器根据Cookie识别码,就可以识别出该用户。并返回该用户的个性化网页
服务器发送的http响应,set-cookie字段通常是这样:Set-Cookie: key=value
HTTP的基本性质
HTTP是简单的
HTTP是可扩展的
HTTP是无状态的,有会话的
HTTP是无状态的:在同一个连接中,两个执行成功的请求之间是没有关系的。这就带来了一个问题,用户没有办法在同一个网站中进行连续的交互,比如在一个电商网站里,用户把某个商品加入到购物车,切换一个页面后再次添加了商品,这两次添加商品的请求之间没有关联,浏览器无法知道用户最终选择了哪些商品。而使用HTTP的头部扩展, HTTP Cookies就可以解决这个问题。把Cookies添加到头部中,创建一个会话让每次请求都能共享相同的上下文信息,达成相同的状态。
注意,HTTP本质是无状态的,使用Cookies可以创建有状态的会话。
业务是连续的,请求报文是无状态的。 Cookie使得浏览器与服务器之间的请求是连贯的,而不是割裂的
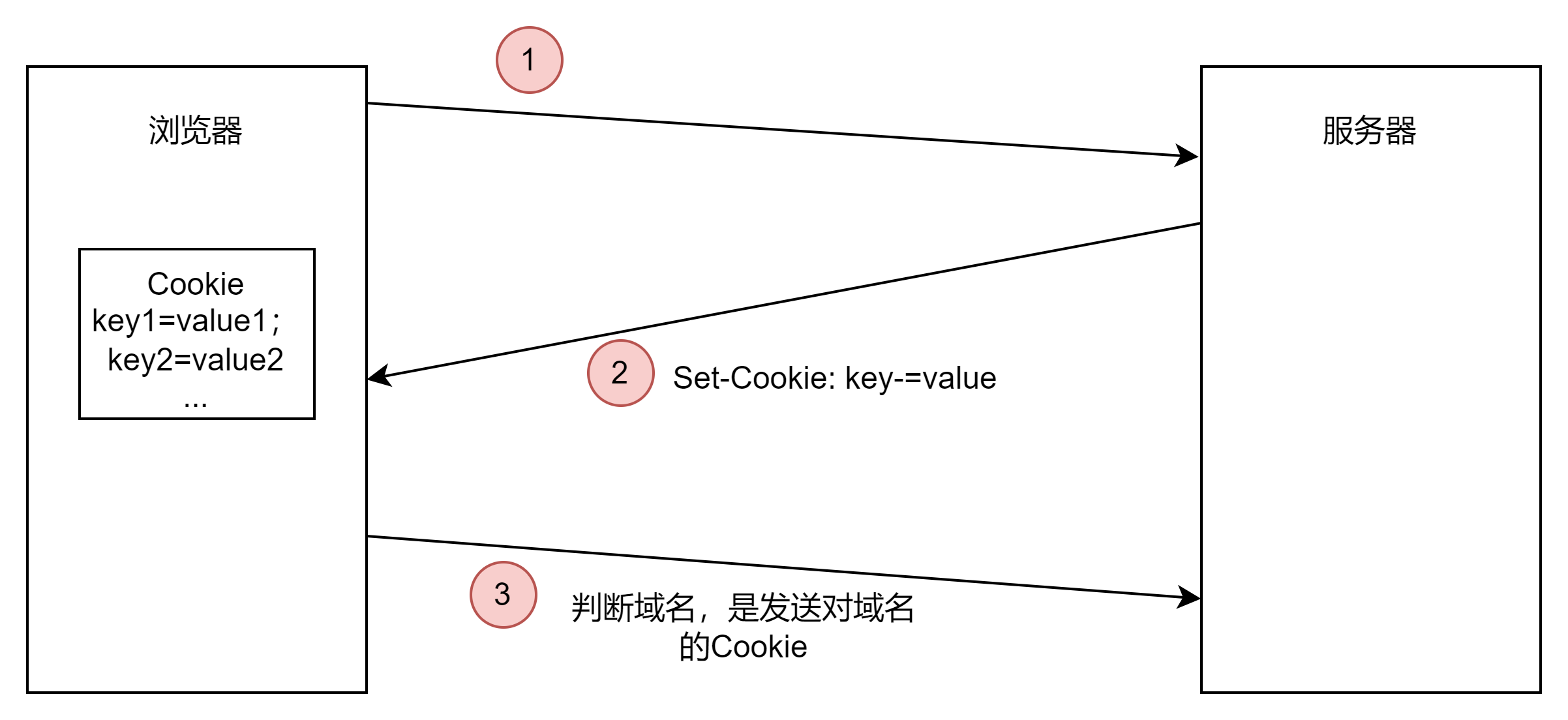
Cookie
服务器发送到浏览器,并保存在浏览器端的一小块数据
浏览器下次访问该服务器时,会自动写的该块数据,将其发送给服务器
什么是Cookie?
Cookie是服务器发送到用户浏览器并保存在本地的一小块数据。它会在浏览器下一次向同一服务器再发起请求时被携带并发送到服务器上。通常,Cookie用于告知浏览器,两个请求是否来自同一个浏览器,如保持用户的登录状态。
Cookie示例
在AlphaController类中添加以下方法:
// cookie示例
@RequestMapping(path = "/cookie/set", method = RequestMethod.GET)
@ResponseBody
public String setCookie(HttpServletResponse response) {
// 创建cookie
/*
* 创建cookie对象,一个cookie对象都是key=value形式
* code=CommunityUtil.generateUUID()
* */
Cookie cookie = new Cookie("code", CommunityUtil.generateUUID());
// 设置cookie生效的范围
/*
* 浏览器访问哪些路径才会发,如果不指定,所有路径都会发该cookie,浪费的网络资源。
* 不需要这个cookie的路径就让他无效即可。
*
* 在该路径/community/alpha和其子路径有效。
* */
cookie.setPath("/community/alpha");
// 设置cookie的生存时间
/*
* 浏览器得到cookie之后,会存在内存里面,当浏览器进程结束,cookie就没了
* 如果想让其时间久一点,可以设置生存时间,浏览器就会对其持久化操作,保存到硬盘里面
* 知道生成时间结束
* localhost8080/community/alpha/cookie/set
* code=esce7cbbeae34dadbcf541b26975da1;Mx-Age=m600;Expires=Mon 10-un-2019 14:29:49 GMT; Path=/community/alpha
* */
cookie.setMaxAge(60 * 10);
// 发送cookie
response.addCookie(cookie);
return "set cookie";
}
Cookie 需要用HttpServletResponse对象来设置
再添加有一个方法,获取浏览器第二次传过来的cookie 值
@RequestMapping(path = "/cookie/get", method = RequestMethod.GET)
@ResponseBody
public String getCookie(@CookieValue("code") String code) {
/*
* 通过注解的方式,根据key获取对应的value
* */
System.out.println(code);
return "get cookie";
}

Cookie的缺点?
1、Cookie这个数据是存到浏览器上,存到客户端的,而存到客户端的数据不是安全的,安全程度远远不如服务器。因此,基于Cookie的不安不安全性,Cookie不应该存放很敏感的隐私数据,比如密码。否则很容易被盗
2、Cookie在很多请求中都会主动将Cookie数据发给服务器,每次请求都会加上额外的Cookie 数据,对网络性能,对流量带宽都有一定的的占用。每次访问服务器会增加数据量,对流量、对性能产生一定影响。
因为Cookie有这些,缺点,JavaEE引入了Session这个概念。
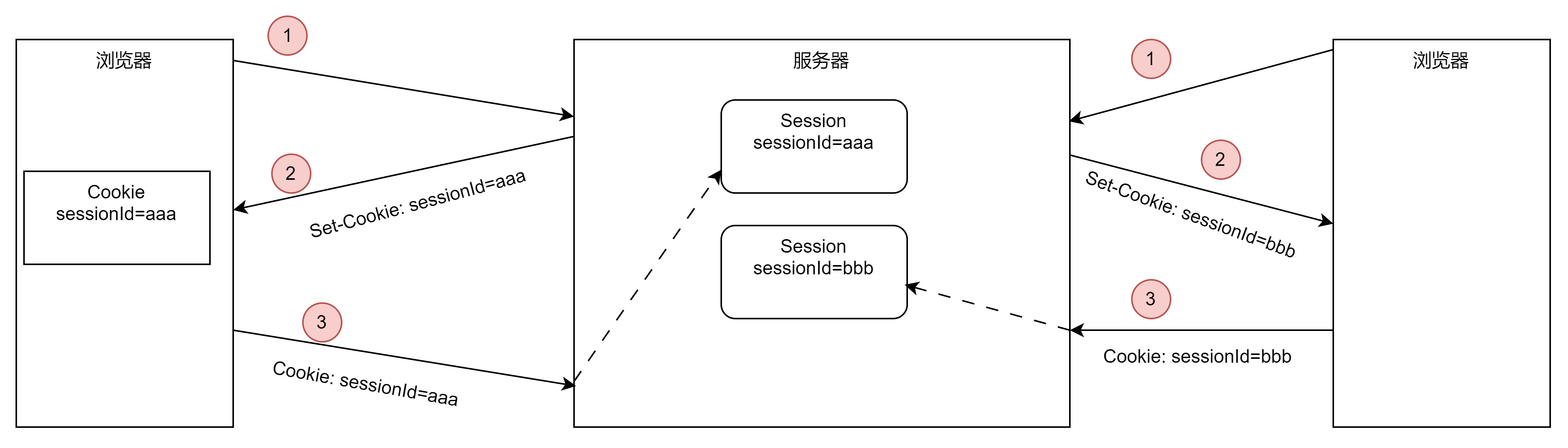
Session
JavaEE的标准,用于在服务端记录客户端信息
注意Session不是htttp协议的标准!
数据存放在服务端会更加安全,但是也会增加服务端的内存压力
Sessiono的缺点就是会占用服务端的内存, 服务端内存的压力就会增大,但更加安全
session示例
在AlphaController中添加测试方法
设置session的key-value值
@RequestMapping(path = "/session/set", method = RequestMethod.GET)
@ResponseBody
/*
* 只需要声明,HttpSession session,spring会自动帮我们进行注入
*
* session可以存储任意类型的数据。
* 自动生成一个SessionI: JSESSIONID=666348E637AFAFA87648668F23E8C174;
* */
public String setSession(HttpSession session) {
session.setAttribute("id", 1);
session.setAttribute("name", "Test");
return "set session";
}
取出session中的值
@RequestMapping(path = "/session/get", method = RequestMethod.GET)
@ResponseBody
public String getSession(HttpSession session) {
System.out.println(session.getAttribute("id"));
System.out.println(session.getAttribute("name"));
return "get session";
}

直接在方法声明处,加上HttpSession session参数,当请求到达该方法时:
- 如果携带的Cooike没有JSESSIONID字段,则会自动创建一个Session对象,并生成一个JSESSIONID,响应时带上Set-Cookie首部行,JSESSIONID=xxx。
- 如果携带的Cooike有JSESSIONID字段,则会根据JSESSIONID去内存中查找对应的Session对象
为什么在分布式部署下,Session用的比较少了?
在部署的时候,如果使用nginx反向代理部署多个服务器实例实现负载均衡,session就会出现问题。和分布式部署有关。
在分布式部署下,会部署多态服务器,同时跑这个应用,同向像浏览器提供支持。
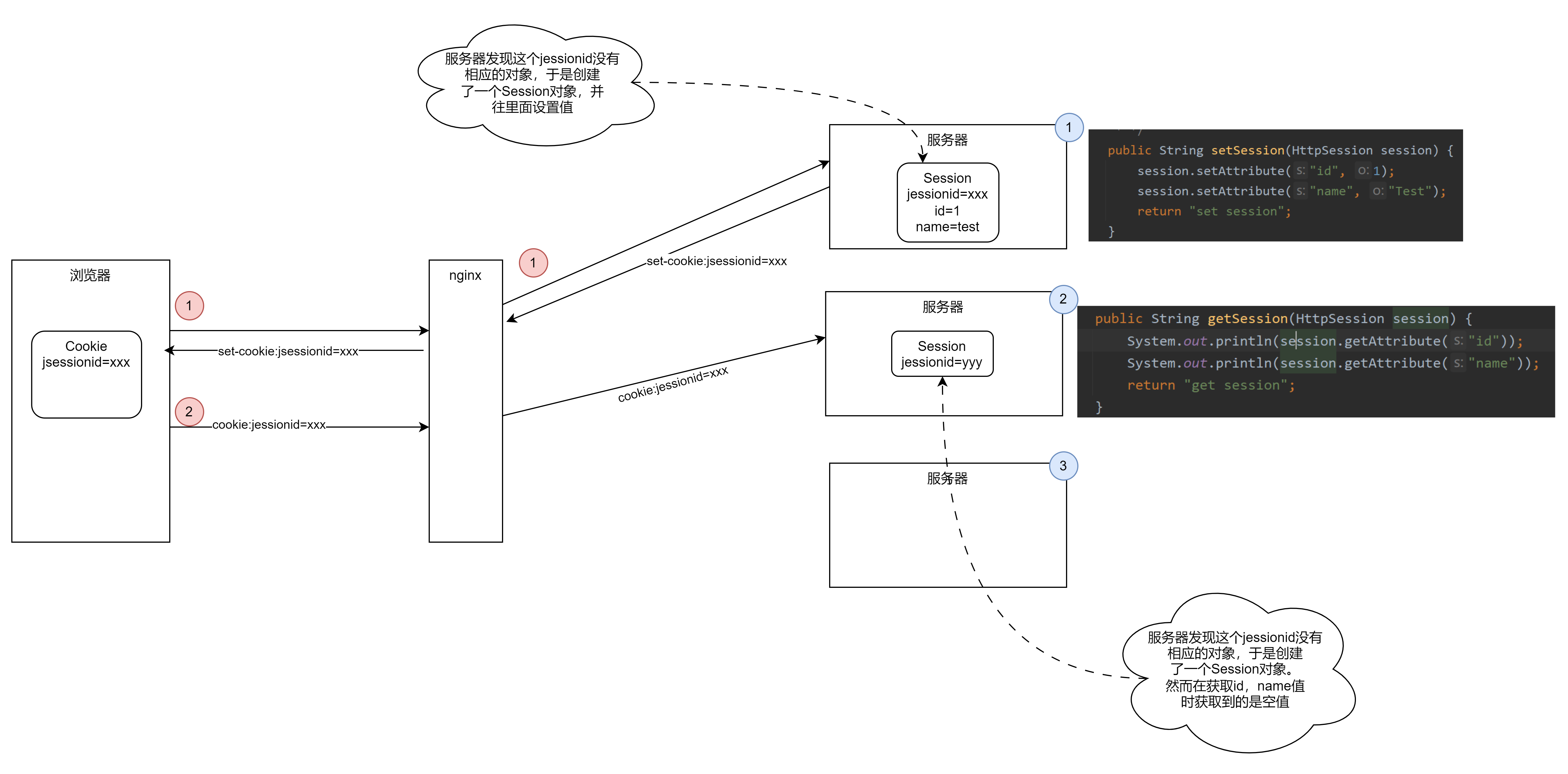
我们用什么方法解决Sesison的问题?
1、黏性session,在nginx反向代理使用负载均衡时采用ip哈希算法,每一个请求,ngxin会按照用户访问的ip地址的哈希结果来分配一台服务器。当下一次,来自同一个IP地址的用户请求,会被同一天服务器处理,此后这个IP地址的请求都是固定这台服务器来处理。总之就是,如果请求来自同一个IP,则固定来自这个IP的请求用同一台服务器处理。有效解决分布式不是seesion的问题,这种解决办法也叫黏性session
该方法缺点:因为请求又固定下来了,所以很难保证服务器时负载均衡的,因为不是平均分的。性能并没有那么好。
2、同步session,当某个服务器创建session、或者对session对象做了修改之后,它会把这个操作同步给其他服务器。这样分布式部署的服务器之间的session就统一了。浏览器无论访问哪个服务器,都会得到相同属性的session。
缺点:需要做同步,一台服务器处理完后需要同步到其他服务器,如果有很多太服务器,会给服务器的性能产生影响。其次,服务器和服务器会产生一些关联,会产生一些耦合,不那么独立了,这对部署会有一些影响。所以,这种方式也不太理想。
3、共享session,我们可以单独创建一台服务器,它是专门用来存储session的。当浏览器访问服务器,需要创建或获取session时,我们把session统一交给这台服务器处理,然后别的服务器向这台服务器申请session即可,它专门处理session。
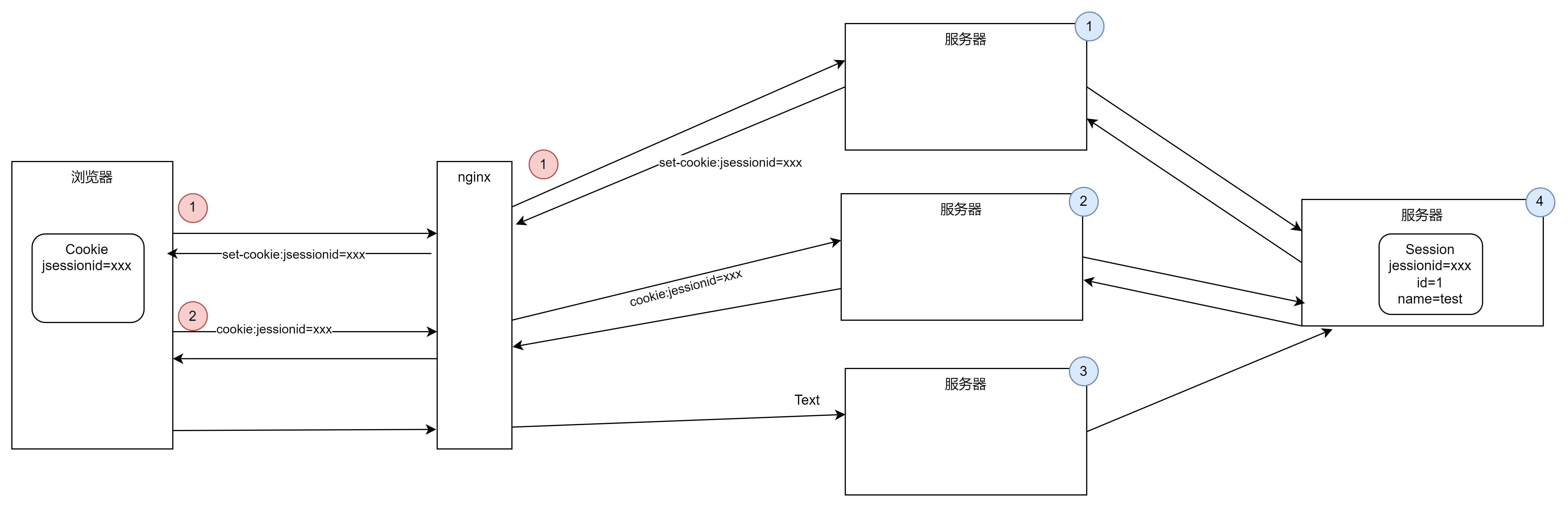
缺点:万一单独处理session的服务器(服务器4)挂了,就糟了,因为其他服务器都依赖于它,其他服务器都没法工作了。我们用分布式部署的初衷是为了解决单体服务器的瓶颈,现在这样搞,又把服务器的瓶颈拜托在一台单体服务器了。
如果单独处理session的服务器再搞个集群同步session的话又回到了第2个解决方案,还是有问题。
4、把客户端身份的数据,不存到session里面。能存到cookie里面就存到cookie里,尽量不使用session,那一些敏感数据怎么办?我们把客户端身份中敏感数据存到数据库里,数据库可以做一个集群或者主从备份,数据库之间共享性能是ok的。
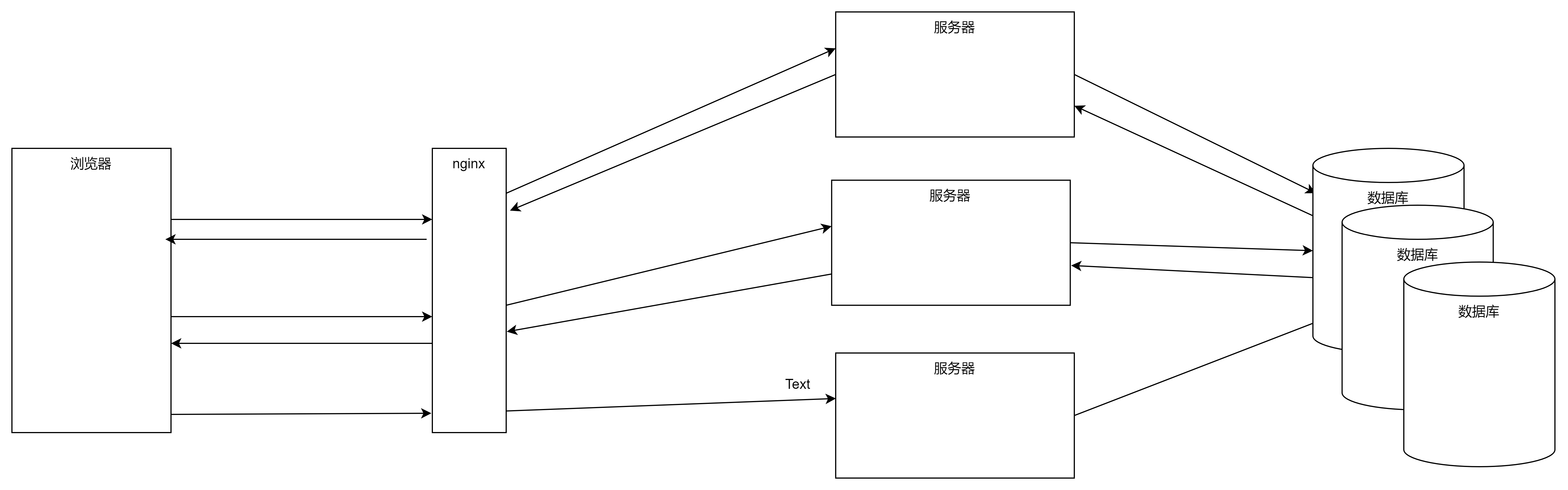
所有的服务器,都可以访问数据库的集群,来得到关于客户端的会话的数据。
缺点:传统的关系型数据库,数据是存放在磁盘中的,而从磁盘中读数据性能是比较慢的,在并发量较大时,磁盘IO也是瓶颈。所以,还是没有直接在内存中操作数据来的快。
5、将客户身份中的敏感信息存入redis中
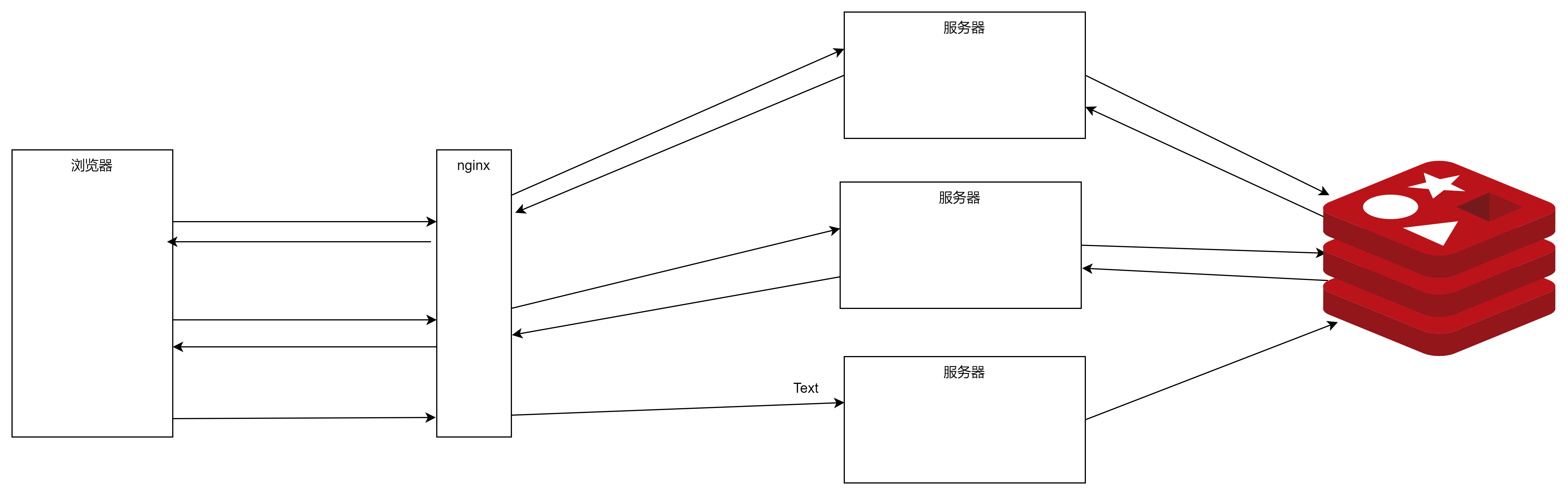








![16进制的字符串转byte[]数组 以及将字节数组转换成十六进制的字符串](https://img-blog.csdnimg.cn/direct/71f70e101dd14f7ab0c0183ba0d3f914.png)