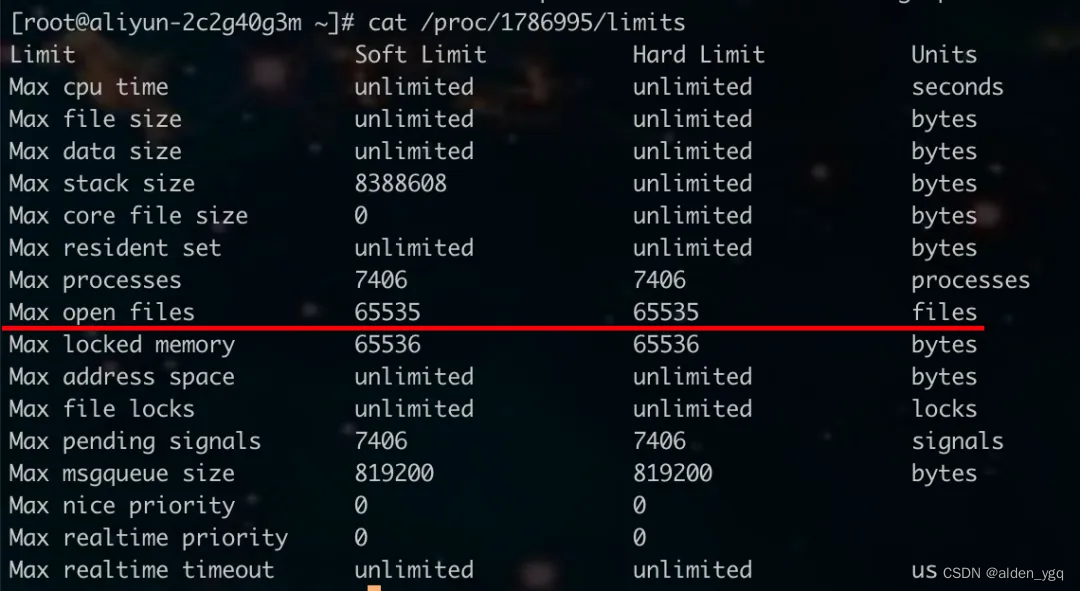
文章目录
- ArrayList源码
- 总:
- 构造方法
- 扩容机制
- remove
- HashMap
- 总:
- 构造方法
- 细节问题
- putVal()方法
- resize()方法
- Hash值
- HashMap常见问题
- ConcurrentHashMap
- 总:
- putVal()方法
- 自己的测试
- 为什么重写HashCode和equals
ArrayList源码
总:
**ArrayList**底层是使用名为 **elementData的Object动态数组进行实现,与Java中的数组相比,她的容量能够动态的进行增长。在我们更新元素的时候,我们会通过ensureCapacityInternal()方法来确保我们的容量够用,如果容量不够则调用grow()**方法对我们的数组进行扩容为1.5倍,然后将我们原来的的数组复制过去。
ArrayList 和 Vector 的区别?
ArrayList是List的主要实现类,底层使用Object[]存储,适用于频繁的查找工作,线程不安全 。Vector是List的古老实现类,底层使用Object[]存储,线程安全。
ArrayList 可以添加 null 值吗?
ArrayList 中可以存储任何类型的对象,包括 null 值。不过,不建议向ArrayList 中添加 null 值, null 值无意义,会让代码难以维护比如忘记做判空处理就会导致空指针异常。
Arraylist 与 LinkedList 区别?
Arraylist 和 LinkedList都是实现了 List接口,都是线程不安全的。
不同点:
- Arraylist底层是通过object数组进行实现,而LinkedList底层是通过双向链表进行实现
- AL实现了随机读取接口,能够随机进行读取,用来查询的效率高,LL不能进行随机读取,只能遍历进行读取,但是她的插入效率高
- 内存空间的占用上,AL的预留空间会占用一定的位置,而LL会占用更多的空间,因为要保存其他的一些位置信息
构造方法
Arraylist有有参构造方法也有无参构造方法,有参的构造方法会将我们的容器大小设置为设置的大小
无参构造方法先是将提前创建好的空数组给他,后续使用的时候在进行扩容操作
扩容机制
这里每次add操作的时候都会使用ensure CapacityInternal()方法进行容量判断,如果不足则会使用grow进行扩容

private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
这里的calculate Capacity方法主要是判断容器是否是已经初始化过
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
这里计算所需的最小容量是否大于当前的容器容量
private void ensureExplicitCapacity(int minCapacity) {
// 用来记录遍历的时候时候,集合有没有进行改变
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
这里先将数组扩容为原来的1.5倍,判断是否够用,或者有没有超过最大的容量
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
hugeCapacity()方法 当我们容量超过了当前容器设置的最大值的时候执行
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ? // 这里的MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
如果不够的话,也只能最多再添加8个了
remove
Arraylist 集合移除元素时候执行的函数,然后使用 **System.arraycopy()**方法将数组进行复制再将原来位置设置为null方便进行 gc
public E remove(int index) {
rangeCheck(index); // 判断移除的元素是否越界
modCount++; // 判断当前的集合是否被修改
E oldValue = elementData(index);
int numMoved = size - index - 1; // 确定移除位置
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index, numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
HashMap
总:
HashMap在 jdk1.8之前是由Node数组+链表组成的,在jdk1.8以后更改了解决hash冲突的方式,是由Node数组+链表或者红黑树实现。元素添加是通过**putVal()方法添加,HashMap通过扰动函数处理得到Hash值,如果发生hash冲突的时候就会先判断当前节点的链表大小如果超过8,然后调用treeifBin()**如果hashMap总的容量大于64则会转为红黑树进行存储。
为什么不使用多路平衡二叉树?
- 红黑树是一种平衡二叉树,多路平衡二叉树需要存储更多的节点信息,空间上会使用更多的空间
- 操作的复杂性,红黑树不是严格的平衡二叉树,两边子节点的高度差没有完全的差1,插入的时候更好的处理
- 红黑树的查询表现已经可以了,不需要多路平衡二叉树的B+树的范围查询了
构造方法
构造方法有三个,关键就是携带参数的问题,有没有 **initialCapacity初始化容量**和 loadFactor扩容阈值
细节问题
默认的大小是16,AL是10,扩容每次为一倍,AL每次扩容1.5倍
putVal()方法

resize()方法
计算出新的**Capacity**和 threshold的值,然后创建一个新的数组,将我们原来的数组的值复制进去
**threshold**的值是通过 Capacity的值与设置的阈值0.75相乘得出来的
Hash值
hashCode()方法返回的是int整数类型,其范围为
-(2 ^ 31)~(2 ^ 31 - 1),而HashMap的容量范围是在16(初始化默认值)~2 ^ 30,HashMap通常情况下是取不到最大值的,并且设备上也难以提供这么多的存储空间,从而导致通过hashCode()计算出的哈希值可能不在数组大小范围内,进而无法匹配存储位置;
那怎么解决呢?
HashMap自己实现了自己的hash()方法,通过两次扰动使得它自己的哈希值高低位自行进行异或运算,降低哈希碰撞概率也使得数据分布更平均;
在保证数组长度为2的幂次方的时候,使用hash()运算之后的值与运算(&)(数组长度 - 1)来获取数组下标的方式进行存储,这样一来是比取余操作更加有效率,二来也是因为只有当数组长度为2的幂次方时,h&(length-1)才等价于h%length,三来解决了“哈希值与数组大小范围不匹配”的问题;
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
HashMap常见问题
为什么线程不安全
因为可能会造成数据丢失的问题,假如两个线程同时进行插入,并且产生了Hash碰撞,那么线程1判断完成以后插入之前挂起,同时线程2进行插入,这时线程1插入的将会覆盖线程2
ConcurrentHashMap
总:
ConcurrentHashMap是一个并发容器,能够解决多个线程使用HashMap造成的线程安全问题,底层的**putVal函数**是通过 Cas操作和Synchronized操作来保证线程的安全性。其他的结构和HashMap一样。
putVal()方法
和HashMap的过程基本一致
只是如果计算出hash值原位置没有的话,直接使用cas操作进行插入
如果后续碰撞则使用synchronized进行插入
自己的测试
自己使用了四个线程,分别进行100万次随机位置的写入,查看每个线程的完成时间,平均每个线程的完成时间将会降低百分之30左右。
为什么重写HashCode和equals
因为两个相等的对象的 hashCode 值必须是相等。也就是说如果 equals 方法判断两个对象是相等的,那这两个对象的 hashCode 值也要相等。
如果重写 equals() 时没有重写 hashCode() 方法的话就可能会导致 equals 方法判断是相等的两个对象,hashCode 值却不相等。
思考:重写 equals() 时没有重写 hashCode() 方法的话,使用 HashMap 可能会出现什么问题。
总结:
equals方法判断两个对象是相等的,那这两个对象的hashCode值也要相等。- 两个对象有相同的
hashCode值,他们也不一定是相等的(哈希碰撞)。





![16进制的字符串转byte[]数组 以及将字节数组转换成十六进制的字符串](https://img-blog.csdnimg.cn/direct/71f70e101dd14f7ab0c0183ba0d3f914.png)