文章目录
- Word Vectors
- 1. import repos
- 2. Read corpus and calculate co-occurrence matrices
- 2-1 read_corpus
- 2-2 vocabulary
- 2-3 co occurrence matrices
- 2-4. dimensionality reduction
- 完整性检查
- 3. Prediction-Based Word Vectors
- 余弦相似度
Word Vectors
1. import repos
from gensim.models import KeyedVectors
from gensim.test.utils import datapath
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = [10, 5]
import nltk
from nltk.corpus import reuters
import numpy as np
import random
import scipy as sp
from sklearn.decomposition import TruncatedSVD
from sklearn.decomposition import PCA
START_TOKEN = '<START>'
END_TOKEN = '<END>'
np.random.seed(0)
random.seed(0)
Word Vectors和Word Embeddings通常可以互换使用- 词向量通常用作下游NLP任务的基本组成部分,例如问题回答,文本生成,翻译等,因此对它们的优缺点进行一些直观了解非常重要。
- 在这里,您将探索两种类型的词向量: 从
co-occurrence matrices派生的词向量,以及GloVe现成的词向量。gensim是一个加载现成词向量的库,nltk库可用于加载各种语料, 作为示例, 这里使用reuters(路透社, 商业和金融新闻)语料库。 - 如下展示了一个
co-occurrence matrices的示例, 窗口大小为 1, 对于一个文档内的某一个单词w(token), 我们每次都统计w周围 n 个单词(左边n个加上右边n个:[w-n, w+n])与之共同出现的次数.
Document 1: "all that glitters is not gold"
Document 2: "all is well that ends well"
| * | <START> | all | that | glitters | is | not | gold | well | ends | <END> |
|---|---|---|---|---|---|---|---|---|---|---|
<START> | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| all | 2 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| that | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 |
| glitters | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| is | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 |
| not | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
| gold | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| well | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 |
| ends | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
<END> | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 |
这里, all和 <START> 共同出现的次数为2, 可以看到矩阵是对称而且稀疏的, 并且其大小为 V, V 是语料库中所有可能出现的单词数量. 注意: 在NLP中,我们经常添加 <START> 和 <END> 标记来表示句子,段落或文档的开头和结尾。在这种情况下,我们想象 <START> 和 <END> 标记封装每个文档,例如,“<START> All that glitters is not gold <END>”,并将这些 token 包括在我们的共现计数中。
2. Read corpus and calculate co-occurrence matrices
2-1 read_corpus
在这里,我们将使用路透社 (商业和金融新闻) 语料库。语料库由10,788个新闻文档组成,总计130万个单词。这些文档涵盖90个类别,分为train和test。有关详细信息,请参阅 https://www.nltk.org/book/ch02.html 我们在下面提供了一个 read_corpus 函数,该函数仅从 “黄金” 类别 (即有关黄金,采矿等的新闻文章) 中提取文章。该函数还向每个文档添加 <START> 和 <END> 标记,以及将单词转为小写。您不必执行任何其他类型的预处理。
def read_corpus(category="gold"):
files = reuters.fileids(category)
return [[START_TOKEN] + [w.lower() for w in list(reuters.words(f))] + [END_TOKEN] for f in files]
reuters_corpus = read_corpus()
print(reuters_corpus[1])
"""
['<START>', 'belgium', 'to', 'issue', 'gold', 'warrants', ',', 'sources', 'say', 'belgium', 'plans',
'to', 'issue', 'swiss', 'franc', 'warrants', 'to', 'buy', 'gold', ',', 'with', 'credit', 'suisse',
'as', 'lead', 'manager', ',', 'market', 'sources', 'said', '.', 'no', 'confirmation', 'or',
'further', 'details', 'were', 'immediately', 'available', '.', '<END>']
"""
2-2 vocabulary
遍历语料库 reuters_corpus 统计所有出现的单词, 为它们排序, 返回词表和词表长度.
def distinct_words(corpus):
corpus_words = []
n_corpus_words = -1
for doc in corpus:
corpus_words += doc
corpus_words = list(set(corpus_words))
corpus_words.sort()
n_corpus_words = len(corpus_words)
return corpus_words, n_corpus_words
2-3 co occurrence matrices
为词汇表的每个词汇建立索引, 该索引对应于 co occurrence matrices 中单词的索引, 因此若词表的大小为 V, 则 co occurrence matrices 的大小为 (V, V).
def compute_co_occurrence_matrix(corpus, window_size=4):
words, n_words = distinct_words(corpus)
M = np.zeros((n_words, n_words))
word2ind = {}
# word index map
for i, w in enumerate(words):
word2ind[w]=i
# second, fill the co-occurrence matrix. remind that <Start> and <End> are also included
for doc in corpus:
for wi in range(len(doc)):
s = (wi-window_size) if (wi-window_size)>0 else 0
e = (wi+window_size) if (wi+window_size)<len(doc) else len(doc)-1
for i in range(s,e+1):
if i != wi:
M[word2ind[doc[wi]]][word2ind[doc[i]]] += 1
return M, word2ind
2-4. dimensionality reduction
通过 SVD 分解将共现矩阵降维至2维, 可以进行一定的可视化.
def reduce_to_k_dim(M, k=2):
n_iters = 10
print("Running Truncated SVD over %i words..." % (M.shape[0]))
svd = TruncatedSVD(n_components=k, n_iter=n_iters)
svd.fit(M)
M_reduced = svd.transform(M)
print("Done.")
return M_reduced
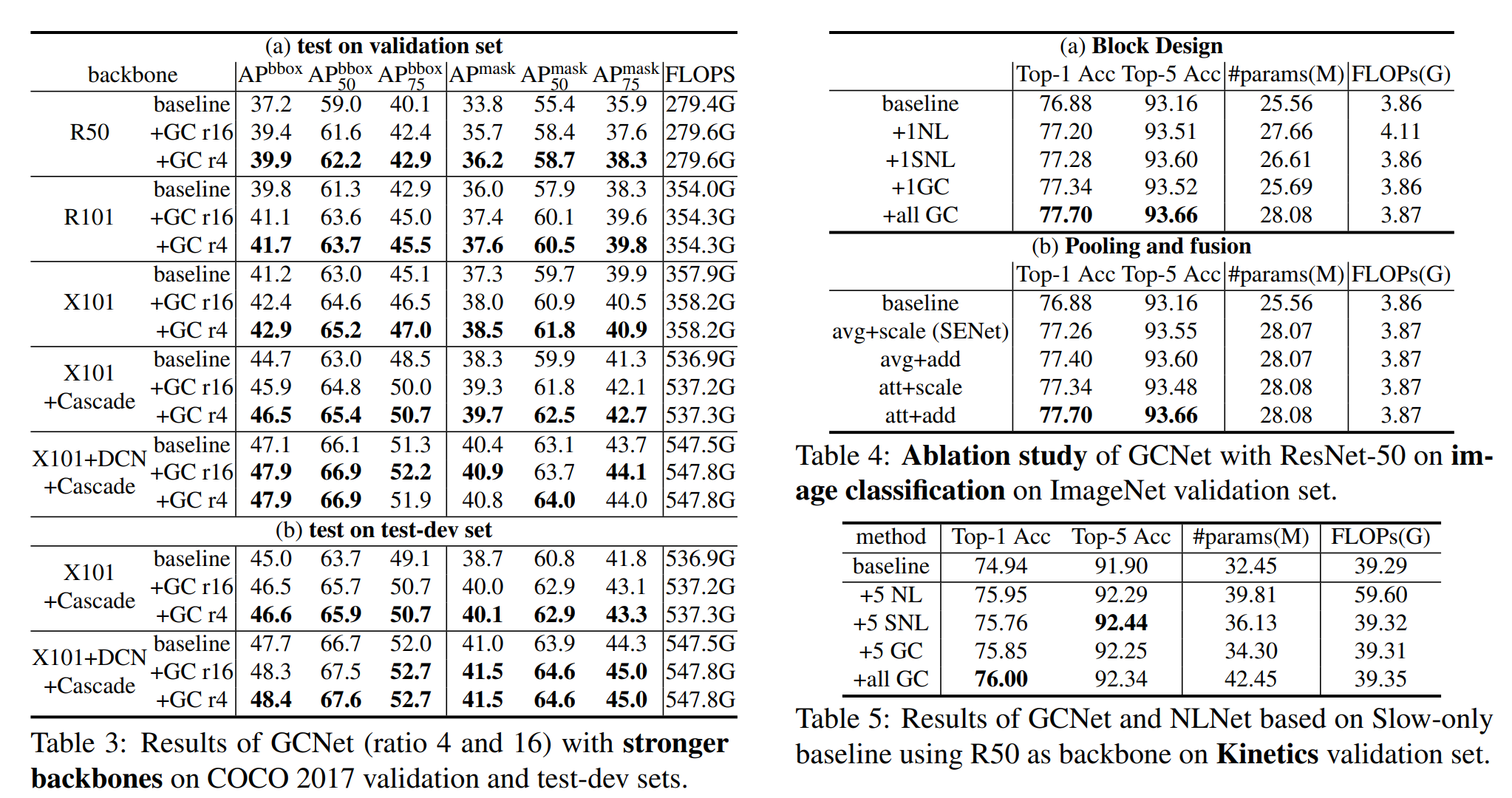
def plot_embeddings(M_reduced, word2ind, words):
for w in words:
wi = word2ind[w]
plt.scatter(M_reduced[wi,0], M_reduced[wi,1], marker='x', c='r')
plt.text(M_reduced[wi,0], M_reduced[wi,1], w, alpha=0.8)
plt.show()
plt.close()
完整性检查
接下来读入词库, 生成词表, 计算共现矩阵, 最后执行降维, 挑选一部分词汇将他们可视化。
reuters_corpus = read_corpus()
M_co_occurrence, word2ind_co_occurrence = compute_co_occurrence_matrix(reuters_corpus)
M_reduced_co_occurrence = reduce_to_k_dim(M_co_occurrence, k=2)
# Rescale (normalize) the rows to make them each of unit-length
M_lengths = np.linalg.norm(M_reduced_co_occurrence, axis=1)
M_normalized = M_reduced_co_occurrence / M_lengths[:, np.newaxis] # broadcasting
words = ['value', 'gold', 'platinum', 'reserves', 'silver', 'metals', 'copper', 'belgium', 'australia', 'china', 'grammes', "mine"]
plot_embeddings(M_normalized, word2ind_co_occurrence, words)

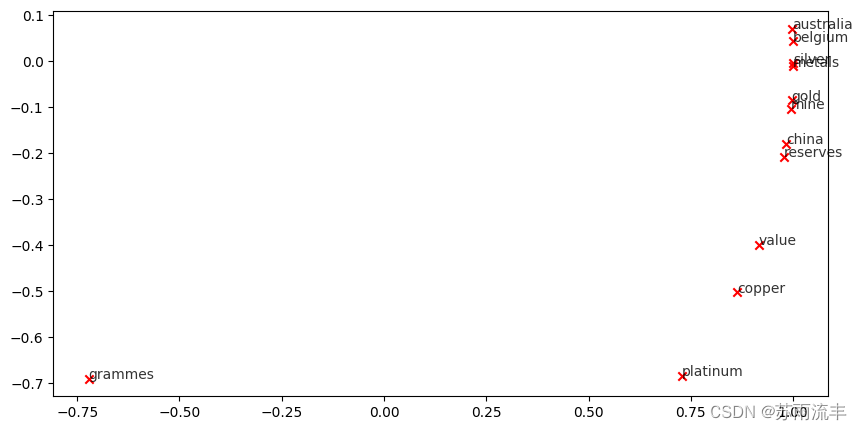
相似的聚集的单词:
第一组,copper和platinum,它们都属于金属矿物
第二组,belgium 和 australia,它们都属于国家名
类似的但没有聚集的单词:
第一组,gold 和 sliver
第二组,belgium 和china
3. Prediction-Based Word Vectors
加载 GloVe 词向量库, 它包含 400000 个单词的200维向量编码. 为了避免内存不足, 这里先随机采样 10000 个单词, 把它们合并为矩阵, 同时返回单词编号字典.
def get_matrix_of_vectors(wv_from_bin, required_words):
import random
words = list(wv_from_bin.index_to_key)
print("Shuffling words ...")
random.seed(225)
random.shuffle(words)
words = words[:10000]
print("Putting %i words into word2ind and matrix M..." % len(words))
word2ind = {}
M = []
curInd = 0
for w in words:
try:
M.append(wv_from_bin.get_vector(w))
word2ind[w] = curInd
curInd += 1
except KeyError:
continue
for w in required_words:
if w in words:
continue
try:
M.append(wv_from_bin.get_vector(w))
word2ind[w] = curInd
curInd += 1
except KeyError:
continue
M = np.stack(M)
print("Done.")
return M, word2ind
随后, 我们同样应用降维到 M 矩阵, 并应用一些可视化分析.
M, word2ind = get_matrix_of_vectors(wv_from_bin, words)
M_reduced = reduce_to_k_dim(M, k=2)
# Rescale (normalize) the rows to make them each of unit-length
M_lengths = np.linalg.norm(M_reduced, axis=1)
M_reduced_normalized = M_reduced / M_lengths[:, np.newaxis] # broadcasting
words = ['value', 'gold', 'platinum', 'reserves', 'silver', 'metals', 'copper', 'belgium', 'australia', 'china', 'grammes', "mine"]
plot_embeddings(M_reduced_normalized, word2ind, words)
余弦相似度
现在我们有了词向量,我们需要一种方法来量化单个词之间的相似性,根据这些向量。一种这样的度量是余弦相似性。我们将使用它来找到彼此 “接近” 和 “远离” 的单词。
s
s
s between two vectors
p
p
p and
q
q
q is defined as:
s
=
p
⋅
q
∣
∣
p
∣
∣
∣
∣
q
∣
∣
,
where
s
∈
[
−
1
,
1
]
s = \frac{p \cdot q}{||p|| ||q||}, \textrm{ where } s \in [-1, 1]
s=∣∣p∣∣∣∣q∣∣p⋅q, where s∈[−1,1]
print(wv_from_bin.most_similar("light"))
"""
[('bright', 0.6242774724960327), ('dark', 0.6141002178192139), ('lights', 0.6013951897621155), ('lighter', 0.558175265789032), ('heavy', 0.5408364534378052), ('sunlight', 0.5362919569015503), ('blue', 0.5349379777908325), ('colored', 0.5282376408576965), ('sky', 0.5239452719688416), ('color', 0.513929009437561)]
"""
light 常见含义灯光、轻的、轻松的、点燃等等含义, 从输出来看, 这包含了它的同义词和反义词, 反义词例如 dark 是黑暗的, heavy 是重的, bule 忧郁的等等.
在考虑余弦相似性时,通常更方便地考虑余弦距离,即简单的1-余弦相似性。Find three words ( w 1 , w 2 , w 3 ) (w_1,w_2,w_3) (w1,w2,w3) where w 1 w_1 w1 and w 2 w_2 w2 are synonyms and w 1 w_1 w1 and w 3 w_3 w3 are antonyms, but Cosine Distance ( w 1 , w 3 ) < (w_1,w_3) < (w1,w3)< Cosine Distance ( w 1 , w 2 ) (w_1,w_2) (w1,w2).
w1 = "love"
w2 = "like"
w3 = "hate"
w1_w2_dist = wv_from_bin.distance(w1, w2)
w1_w3_dist = wv_from_bin.distance(w1, w3)
print("Synonyms {}, {} have cosine distance: {}".format(w1, w2, w1_w2_dist))
print("Antonyms {}, {} have cosine distance: {}".format(w1, w3, w1_w3_dist))