Kibana是一个开源的分析与可视化平台,设计出来用于和Elasticsearch一起使用的。你可以用kibana搜索、查看存放在Elasticsearch中的数据。
Kibana与Elasticsearch的交互方式是各种不同的图表、表格、地图等,直观的展示数据,从而达到高级的数据分析与可视化的目的。
Elasticsearch、Logstash和Kibana这三个技术就是我们常说的ELK技术栈,可以说这三个技术的组合是大数据领域中一个很巧妙的设计。
一种很典型的MVC思想,模型持久层,视图层和控制层。Logstash担任控制层的角色,负责搜集和过滤数据。Elasticsearch担任数据持久层的角色,
负责储存数据。而我们这章的主题Kibana担任视图层角色,拥有各种维度的查询和分析,并使用图形化的界面展示存放在Elasticsearch中的数据。
1.1 Elasticsearch 安装
官网
Elasticsearch 平台 — 大规模查找实时答案 | Elastic
Install Elasticsearch with Docker | Elasticsearch Guide [7.5] | Elastic
es下载地址
https://www.elastic.co/cn/downloads/past-releases#elasticsearch
1.2 Elasticsearch ik 安装
ik官网
https://github.com/infinilabs/analysis-ik
ik下载地址
Release v6.4.3 · infinilabs/analysis-ik · GitHub
1.3 kibana下载
Kibana 官方网址:https://www.elastic.co/cn/products/kibana
Kibana 官方下载地址:https://www.elastic.co/cn/downloads/kibana
官方 docker 镜像地址:https://www.docker.elastic.co/
1.4 libreOffice下载(预览pdf)
Index of /libreoffice/old
单机版:
compose-prq-es.yml文件
本章以elasticsearch:7.9.0、kibana:7.9.0、libreoffice/online:latest为例
注意kibana的版本要和es一致
# yaml 配置
version: '3'
services:
elasticsearch:
image: "elasticsearch:7.9.0"
container_name: "elasticsearch"
restart: always
privileged: true
environment:
- "discovery.type=single-node" # 单机模式
- "ES_JAVA_OPTS=-Xms512m -Xmx1024m" #表示elasticsearch的内存占用大小从512mb~1024mb
# - bootstrap.memory_lock=true
volumes:
- "/home/docker/volumes/ioms_data/_data/elasticsearch_data/plugins:/usr/share/elasticsearch/plugins"
- "/home/docker/volumes/ioms_data/_data/elasticsearch_data/data:/usr/share/elasticsearch/data"
- "/home/docker/volumes/ioms_data/_data/elasticsearch_data/logs:/usr/share/elasticsearch/logs"
- "/etc/localtime:/etc/localtime"
- "/etc/timezone:/etc/timezone"
ports:
- 9200:9200
- 9300:9300
kibana:
image: "kibana:7.9.0"
container_name: "kibana"
restart: always
depends_on:
- elasticsearch
environment:
ELASTICSEARCH_HOSTS: http://10.194.17.106:9200
I18N_LOCALE: zh-CN
ports:
- 5601:5601
libreoffice:
image: "libreoffice/online:latest"
container_name: "libreoffice"
ports:
- "9980:9980"
restart: always
privileged: true
volumes:
- "/etc/localtime:/etc/localtime"
- "/etc/timezone:/etc/timezone"
- "/home/docker/volumes/ioms_data/_data/libreoffice_data/loolwsd.xml:/etc/loolwsd/loolwsd.xml"
environment:
- domian=domain.com
- username=admin
- password=123456
cap_add:
- MKNOD
install.sh脚本
#!/bin/bash
echo "current shell execute direcoty:`pwd`"
updatedb
path=`dirname $variable_path`
echo "swich direcoty to prq shell directory:${path}"
cd ${path}
pwd
image_home="./images"
image_kibana="kibana-7.9.0.tar.gz"
image_libreoffice="libreoffice-online.tar.gz"
image_es="elasticsearch-7.9.0.tar.gz"
# prq文件映射路径 prq_data_path
prq_data_path="/home/docker/volumes/prq_data/_data"
echo "Loading docker images ..."
docker load -i ${image_home}/${image_es}
docker load -i ${image_home}/${image_libreoffice}
docker load -i ${image_home}/${image_kibana}
echo "Creating volumes ..."
docker volume create prq_data
echo "preparing for envrionment ..."
mkdir -vp ${prq_data_path}/elasticsearch_data/plugins/ik ${prq_data_path}/elasticsearch_data/data ${prq_data_path}/elasticsearch_data/logs ${prq_data_path}/elasticsearch_data/config
cp ${image_home}/elasticsearch-analysis-ik-7.9.0.zip ${prq_data_path}/elasticsearch_data/plugins/ik
cd ${prq_data_path}/elasticsearch_data/plugins/ik
unzip elasticsearch-analysis-ik-7.9.0.zip
cd ${path}
mkdir -vp ${prq_data_path}/libreoffice_data/
chmod -R 777 ${prq_data_path}/libreoffice_data
echo ">>> copy config file to destination location start <<<"
cp conf/loolwsd.xml ${prq_data_path}/libreoffice_data/
echo ">>> config file copy finished <<<"
echo "grant permisssion ..."
chmod 777 -R ${prq_data_path}
sysctl vm.overcommit_memory=1
echo "=============Starting containers...========== "
echo "=============creating other containers ...==================="
docker-compose -f compose-prq-es.yml up -d可以看到,我们需要用到的目录为:
config:配置文件
data:数据存储的目录
plugins:插件的目录,目前我们放入IK的分词插件,需要将elasticsearch-analysis-ik-7.9.0.zip在plugins/ik目录下解压
测试 显示如下页面则成功了,安装的ip:port
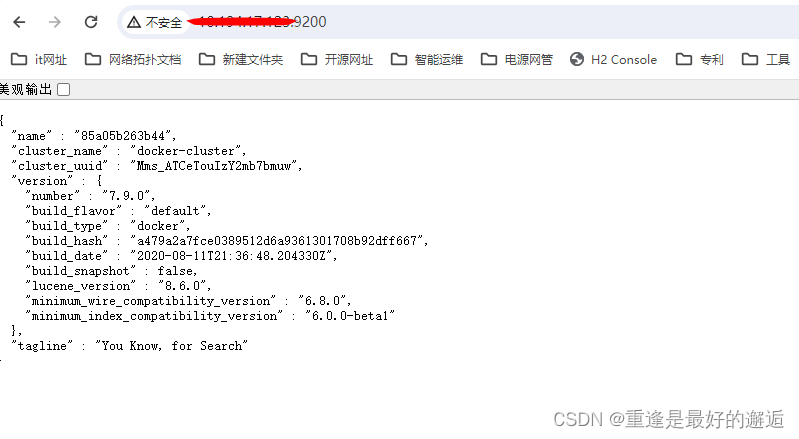
ik安装成功
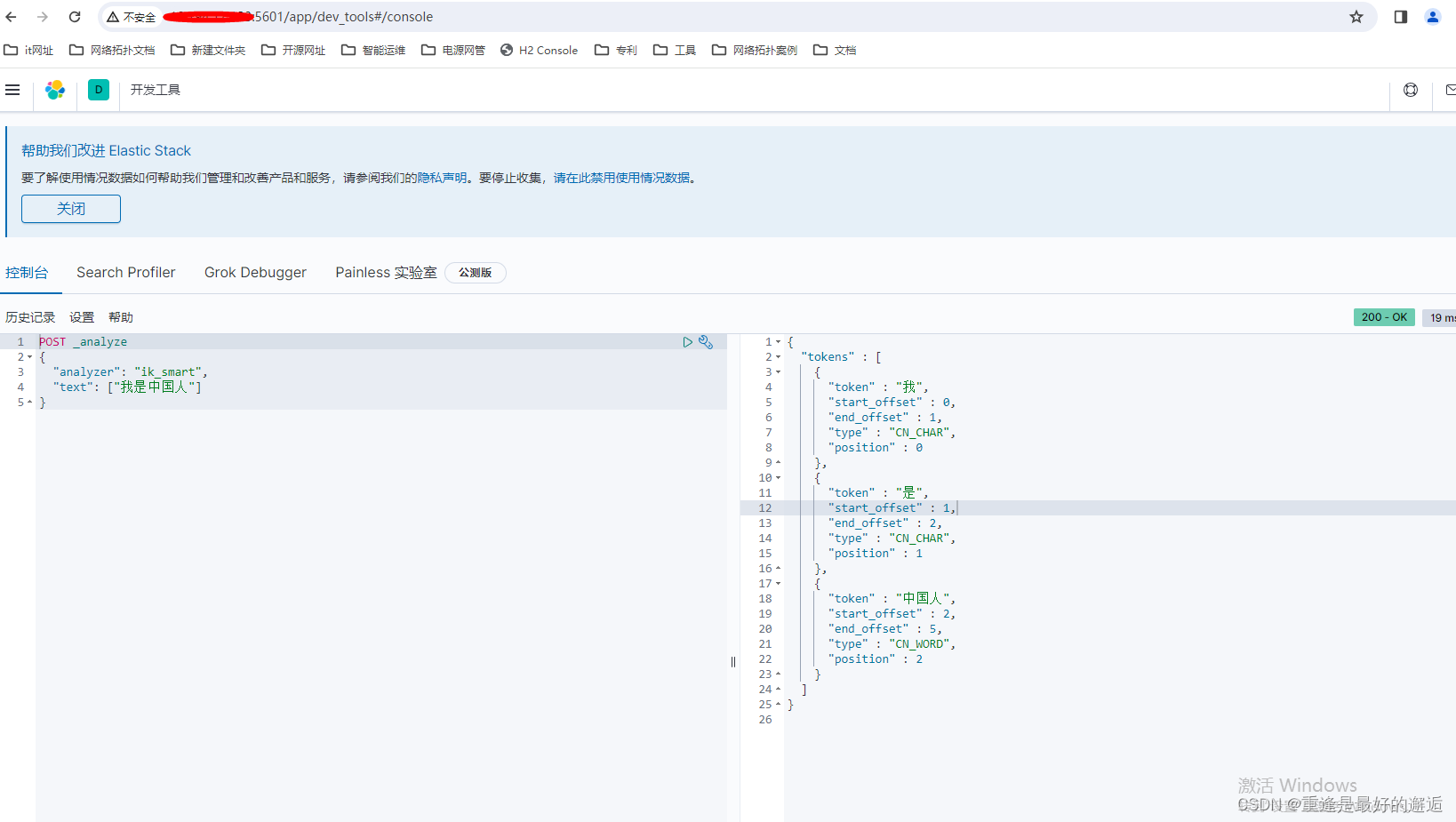
或者用postman测试ik是否安装成功
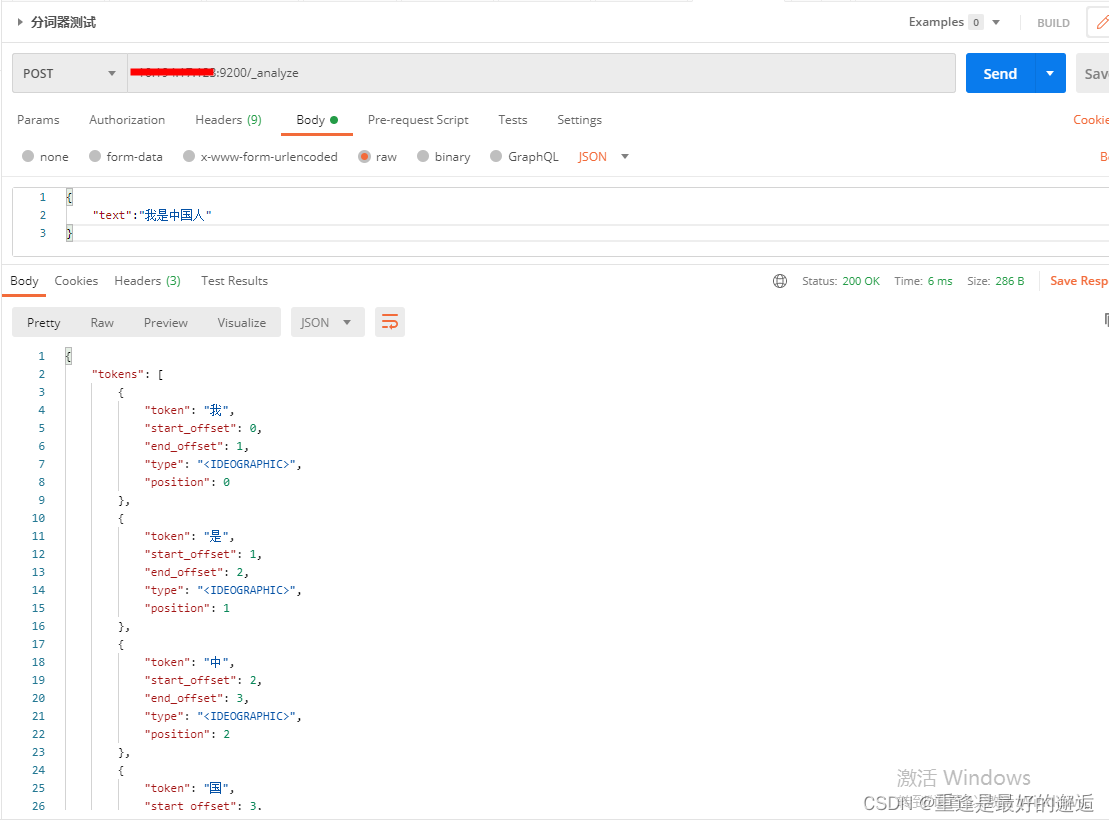
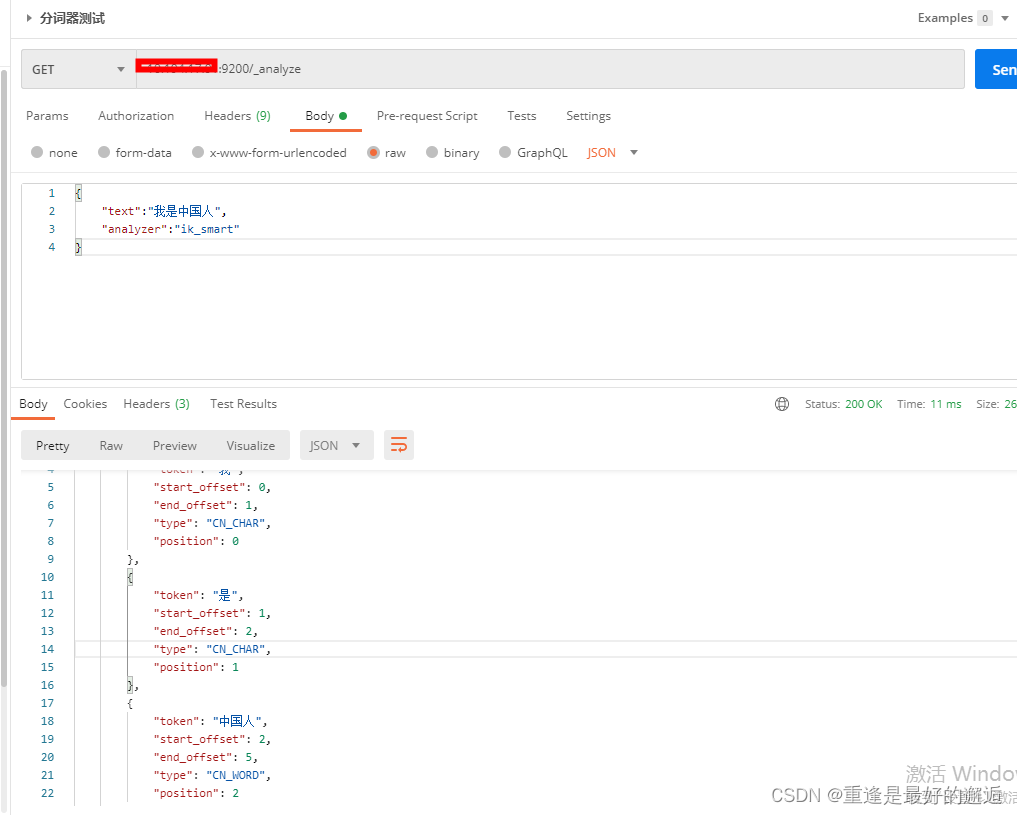
两个postman不同点是多了分词器analyzer,不加分词器,默认是standand,即一个字一个字解析。
ik分词器模式介绍
1. 细粒度分词模式(ik_smart):
这是默认的分词模式,它会尽可能地将句子切分为最小的词语单元。它不仅可以识别普通词汇,还可以识别一些常见的专有名词、地名、人名等。
2. 智能分词模式(ik_max_word):
这种模式会在细粒度分词的基础上,对长词进行进一步的切分。它可以识别更多的词语,但也会增加一些不必要的词语。