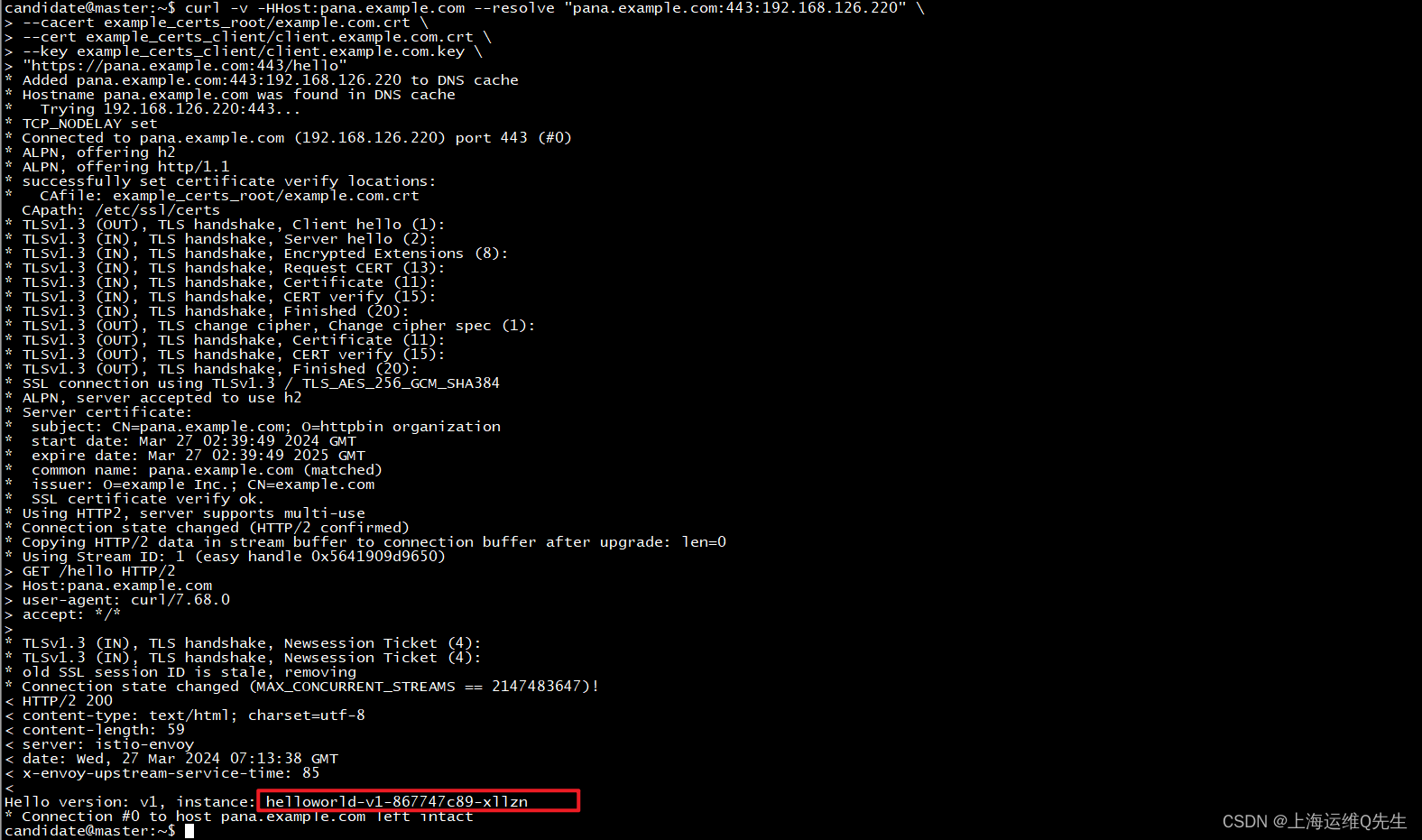
前言
之前笔者在[1]中曾经介绍过BLIP2,其采用Q-Former的方式融合了多模态视觉信息和LLM,本文作者想要简单介绍一个在BLIP2的基础上进一步加强了图文指令微调能力的工作——InstructBLIP,希望对诸位读者有所帮助。如有谬误请见谅并联系指出,本文遵守CC 4.0 BY-SA版权协议,转载请联系作者并注明出处,谢谢。
∇ \nabla ∇ 联系方式:
-
e-mail: FesianXu@gmail.com
-
github: https://github.com/FesianXu
-
github page: https://fesianxu.github.io/
-
知乎专栏: 计算机视觉/计算机图形理论与应用
-
微信公众号:机器学习杂货铺3号店
之前我们介绍过BLIP2模型[1],其特点是采用Q-Former的方式在LLM中融合了多模态视觉信息,其中的learnable query可视为是一种软提示词(soft prompt)。如Fig 1. (b)所示,在整个BLIP2体系下,笔者个人认为可视为用学习出来的learnable query结合Q-Former,提炼出视觉表达,而这个视觉表达可视为也是一种软提示词,对参数固定的LLM进行提示,从而在LLM中融入多模态视觉信息。因此这个learnable query作为一种弱提示词是否学习得足够好,是影响后续MLLM表现的一个关键性因素之一。在BLIP2中的视觉特征提取是指令无关的,也即是Q-Former无法感知到不同指令的区别,在不同指令下都只能产出相同的视觉特征,这一点对一些细粒度的指令需求非常不友好。举例来说,一张图片的信息量是很丰富的,而人类在某次对话中的指令则可能只聚焦在这图片中的某个层面的细节上,如Fig 2所示,一个指令去请求模型回答名画的作者亦或是名画的作画细节,对图片视觉特征提取的要求是截然不同的,如果Q-Former无法对不同的指令进行感知,那么其提取出来的视觉特征则很难保证其能很好地满足指令的需求。instructBLIP在这个思考下,对Q-Former进行了改造使得其产出的视觉特征对指令敏感,如Fig 1 (a)所示,具体来说就是令Q-Former的learnable query同时配合指令进行输入,而learnable query和instruction之间通过自注意力机制进行关联,这样能保证提取的视觉特征具有一定的指令敏感性,这个思路可谓是相当直接。


当然,为了引入更好的指令微调能力,不可避免地需要收集更大范围的指令微调数据,在instructBLIP中,作者汇总了包含了11个任务类别的26个数据集,如Fig 3所示,其中的LLaVa-Instruct-150k则是来自于工作[3]。为了进行更准确的任务迁移能力测试,作者对这26个数据集进行了留内集(held-on set)和留外集(held-out set)的划分(留内集会参与训练,而留外集则作为任务迁移能力的测试,不参与训练),这个划分有一些考虑:
- 任务粒度的划分: 作者按照任务粒度进行划分,其中visual reasoning、visual conversation QA、video question answering和image classification任务上都是作为留外集
- 数据集内部的划分:在以上提到的其他任务种类上,则在任务本身内进行划分,如image captioning上就将4个数据集划分为了2个留内集和2个留外集。
因此整个训练&测试的流程为:
- 在被划分为留内集的数据集本身的训练集中进行指令微调,然后通过这些留内集的验证集或者测试集进行留内验证(held-in evaluation)。
- 在留外验证(held-out evaluation)中,根据我们刚才的数据划分,有两种类型:
- 数据集未被模型使用,但是有相同任务的数据集参与了训练
- 数据集未被模型使用,同时也无相同任务的数据集参与了训练
注意到这些数据集本身可能并不是为了指令微调设计的(除了llava-instruct-150k),因此需要构建一些提示词模版(prompt template),在原文中作者构建了10到15个指令提示词模版,如下所示。注意到一些公开数据集中更青睐于短回答,因此在模版构建中使用了类似于"short"或者"briefly"的字眼去减少模型总是生成短答案的风险,当然更好的方法还是应该去收集一些长答案的训练集,笔者觉得也许通过GPT4去扩展/修正短回答也是一种可行的思路?
| 编号 | image captioning的任务模版 | VQA的任务模版 | VQG的任务模版 |
|---|---|---|---|
| 1 | A short image caption: | {Question} | Given the image, generate a question whose answer is: {Answer}. Question: |
| 2 | A short image description: | Question: {Question} | Based on the image, provide a question with the answer: {Answer}. Question: |
| 3 | A photo of | {Question} A short answer to the question is | Given the visual representation, create a question for which the answer is “{Answer}” |
| 4 | An image that shows | Q: {Question} A: | From the image provided, craft a question that leads to the reply: {Answer}. Question: |
| 5 | Write a short description for the image | Question: {Question} Short answer: | Considering the picture, come up with a question where the answer is: {Answer}. |
| 6 | Write a description for the photo. | Given the image, answer the following question with no more than three words. {Question} | Taking the image into account, generate an question that has the answer: {Answer}. Question: |
| 7 | Provide a description of what is presented in the photo. | Based on the image, respond to this question with a short answer: {Question}. Answer: | |
| 8 | Briefly describe the content of the image. | Use the provided image to answer the question: {Question} Provide your answer as short as possible: | |
| 9 | Can you briefly explain what you see in the image? | What is the answer to the following question? “{Question}” | |
| 10 | Could you use a few words to describe what you perceive in the photo? | The question “{Question}” can be answered using the image. A short answer is | |
| 11 | Please provide a short depiction of the picture. | ||
| 12 | Using language, provide a short account of the image. | ||
| 13 | Use a few words to illustrate what is happening in the picture. |
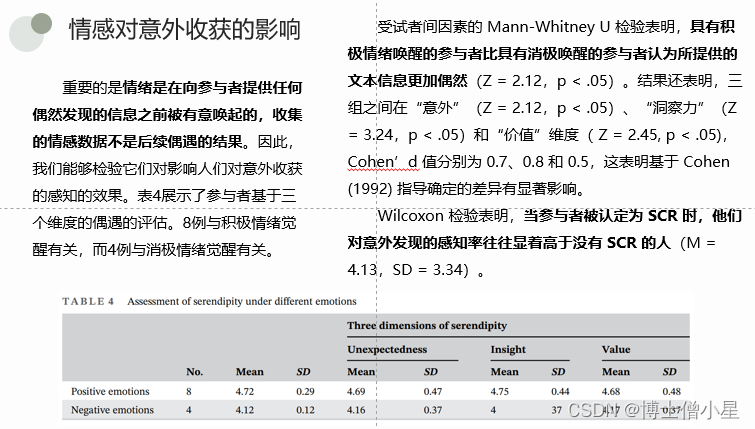
由于训练集混合了多种数据来源,每个数据集的尺度都差别很大,如果均匀混在一起进行训练,在训练一定数量的token情况下,模型会见更多次小规模数据集,这导致模型容易倾向于小数据集的任务,而忽略大规模数据集的任务。为了解决这种问题,作者提出采用数据集规模的方式进行采样,假设 D D D个数据集的尺寸为 { S 1 , ⋯ , S D } \{S_1,\cdots,S_D\} {S1,⋯,SD},那么第 d d d个训练集的采样概率则为 p d = S d ∑ i = 1 D S i p_d = \dfrac{\sqrt{S_d}}{\sum_{i=1}^D \sqrt{S_i}} pd=∑i=1DSiSd。为了减少某些特定任务数据集带来的风险,比如A-OKVQA (是一个多选择的问答任务)就需要手动降低权重,而会手动调高OKVQA数据集的权重。

在训练过程中,作者采用BLIP2的checkpoint作为热启,固定了LLM底座和图片编码器,只微调Q-Former的参数,从动机上看,就是想要通过引入指令敏感的能力提高软提示词的效果。作者首先进行了模型zero-shot能力的测试,如Fig 4所示,在留外集上进行测试的结果验证了instructBLIP的领先性,而且在所有测试集上的提升均不少。

作者对文中提到的指令敏感Q-Former的引入、指令微调、数据平衡等方式进行了消融实现。首先看到指令微调和多任务训练方式的对比,在多任务训练方式中,数据不进行指令模版的格式化,如Fig 5所示,我们可以发现无论是多任务还是指令微调方式,都在留内集上表现接近,这意味着这两种方式都有同样的输入模式学习效果。但是在留外集上指令微调方式明显优于多任务学习方式,而后者表现与BLIP2基线接近,这意味着指令微调这种方式是加强LLM模型的zero-shot通用能力的关键。

如Fig 6所示,作者在不同的LLM底座(FlanT5和Vicuna-7B)下,进行了去除指令敏感Q-Former和数据均衡策略的消融试验,试验证明这两者对性能的提升都是关键性的,其中指令敏感Q-Former的去除,在依赖于空间视觉推断的ScienceQA和时间视觉推断的iVQA任务上性能损失最大,这意味着引入指令敏感Q-Former模块的确能够提取更适合该指令下的图像视觉特征。

总得来看,本文的贡献点主要是:
- 针对图文多模态的指令微调任务,设计了指令敏感的Q-Former模块,可以提取指令敏感的视觉特征。
- 针对图文多模态的指令微调任务,收集了一个由多个公开数据集组成的指令微调数据集。
- 采用一种数据均衡方式协调了数据集中的尺度大小不一的问题,提高了训练稳定性。
Reference
[1]. https://blog.csdn.net/LoseInVain/article/details/136013909, 《BLIP2——采用Q-Former融合视觉语义与LLM能力的方法》
[2]. Dai, Wenliang, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N. Fung, and Steven Hoi. “Instructblip: Towards general-purpose vision-language models with instruction tuning.” Advances in Neural Information Processing Systems 36 (2024). aka InstructBLIP
[3]. Liu, Haotian, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. “Visual instruction tuning.” Advances in neural information processing systems 36 (2024). aka llava

![[flask]请求全局钩子](https://img-blog.csdnimg.cn/direct/f4b46ae8e5d344a78629c62b55816f49.png)