import torch
import torch.nn as nn
import torchvision
from torchvision import transforms,datasets
import os,PIL,pathlib,warnings
#忽略警告信息
warnings.filterwarnings("ignore")
# win10系统
device = torch.device("cuda"if torch.cuda.is_available()else"cpu")
device
import pandas as pd
# 加载自定义中文数据
train_data= pd.read_csv('./data/train2.csv',sep='\t',header=None)
train_data.head()
# 构造数据集迭代器
def coustom_data_iter(texts,labels):
for x,y in zip(texts,labels):
yield x,y
x = train_data[0].values[:]
#多类标签的one-hot展开
y = train_data[1].values[:]
from gensim.models.word2vec import Word2Vec
import numpy as np
#训练word2Vec浅层神经网络模型
w2v=Word2Vec(vector_size=100#是指特征向量的维度,默认为100。
,min_count=3)#可以对字典做截断。词频少于min_count次数的单词会被丢弃掉,默认为5
w2v.build_vocab(x)
w2v.train(x,total_examples=w2v.corpus_count,epochs=20)
# 将文本转化为向量
def average_vec(text):
vec =np.zeros(100).reshape((1,100))
for word in text:
try:
vec +=w2v.wv[word].reshape((1,100))
except KeyError:
continue
return vec
#将词向量保存为Ndarray
x_vec= np.concatenate([average_vec(z)for z in x])
#保存Word2Vec模型及词向量
w2v.save('data/w2v_model.pk1')
train_iter= coustom_data_iter(x_vec,y)
len(x),len(x_vec)
label_name =list(set(train_data[1].values[:]))
print(label_name)
text_pipeline =lambda x:average_vec(x)
label_pipeline =lambda x:label_name.index(x)
text_pipeline("你在干嘛")
label_pipeline("Travel-Query")
from torch.utils.data import DataLoader
def collate_batch(batch):
label_list,text_list=[],[]
for(_text,_label)in batch:
# 标签列表
label_list.append(label_pipeline(_label))
# 文本列表
processed_text = torch.tensor(text_pipeline(_text),dtype=torch.float32)
text_list.append(processed_text)
label_list = torch.tensor(label_list,dtype=torch.int64)
text_list = torch.cat(text_list)
return text_list.to(device),label_list.to(device)
# 数据加载器,调用示例
dataloader = DataLoader(train_iter,batch_size=8,
shuffle =False,
collate_fn=collate_batch)
from torch import nn
class TextclassificationModel(nn.Module):
def __init__(self,num_class):
super(TextclassificationModel,self).__init__()
self.fc = nn.Linear(100,num_class)
def forward(self,text):
return self.fc(text)
num_class =len(label_name)
vocab_size =100000
em_size=12
model= TextclassificationModel(num_class).to(device)
import time
def train(dataloader):
model.train()#切换为训练模式
total_acc,train_loss,total_count =0,0,0
log_interval=50
start_time= time.time()
for idx,(text,label)in enumerate(dataloader):
predicted_label= model(text)
# grad属性归零
optimizer.zero_grad()
loss=criterion(predicted_label,label)#计算网络输出和真实值之间的差距,label
loss.backward()
#反向传播
torch.nn.utils.clip_grad_norm(model.parameters(),0.1)#梯度裁剪
optimizer.step()#每一步自动更新
#记录acc与loss
total_acc+=(predicted_label.argmax(1)==label).sum().item()
train_loss += loss.item()
total_count += label.size(0)
if idx % log_interval==0 and idx>0:
elapsed =time.time()-start_time
print('Iepoch {:1d}I{:4d}/{:4d} batches'
'|train_acc {:4.3f} train_loss {:4.5f}'.format(epoch,idx,len(dataloader),total_acc/total_count,train_loss/total_count))
total_acc,train_loss,total_count =0,0,0
start_time = time.time()
def evaluate(dataloader):
model.eval()#切换为测试模式
total_acc,train_loss,total_count =0,0,0
with torch.no_grad():
for idx,(text,label)in enumerate(dataloader):
predicted_label= model(text)
loss = criterion(predicted_label,label)# 计算loss值
# 记录测试数据
total_acc+=(predicted_label.argmax(1)== label).sum().item()
train_loss += loss.item()
total_count += label.size(0)
return total_acc/total_count,train_loss/total_count
from torch.utils.data.dataset import random_split
from torchtext.data.functional import to_map_style_dataset
# 超参数
EPOCHS=10#epoch
LR=5 #学习率
BATCH_SIZE=64 # batch size for training
criterion = torch.nn.CrossEntropyLoss()
optimizer= torch.optim.SGD(model.parameters(),lr=LR)
scheduler=torch.optim.lr_scheduler.StepLR(optimizer,1.0,gamma=0.1)
total_accu = None
# 构建数据集
train_iter= coustom_data_iter(train_data[0].values[:],train_data[1].values[:])
train_dataset = to_map_style_dataset(train_iter)
split_train_,split_valid_= random_split(train_dataset,[int(len(train_dataset)*0.8),int(len(train_dataset)*0.2)])
train_dataloader =DataLoader(split_train_,batch_size=BATCH_SIZE,
shuffle=True,collate_fn=collate_batch)
valid_dataloader = DataLoader(split_valid_,batch_size=BATCH_SIZE,
shuffle=True,collate_fn=collate_batch)
for epoch in range(1,EPOCHS+1):
epoch_start_time = time.time()
train(train_dataloader)
val_acc,val_loss = evaluate(valid_dataloader)
# 获取当前的学习率
lr =optimizer.state_dict()['param_groups'][0]['1r']
if total_accu is not None and total_accu>val_acc:
scheduler.step()
else:
total_accu = val_acc
print('-'*69)
print('|epoch {:1d}|time:{:4.2f}s |'
'valid_acc {:4.3f} valid_loss {:4.3f}I1r {:4.6f}'.format(epoch,
time.time()-epoch_start_time,
val_acc,val_loss,lr))
print('-'*69)
# test_acc,test_loss =evaluate(valid_dataloader)
# print('模型准确率为:{:5.4f}'.format(test_acc))
#
#
# def predict(text,text_pipeline):
# with torch.no_grad():
# text = torch.tensor(text_pipeline(text),dtype=torch.float32)
# print(text.shape)
# output = model(text)
# return output.argmax(1).item()
# # ex_text_str="随便播放一首专辑阁楼里的佛里的歌"
# ex_text_str="还有双鸭山到淮阴的汽车票吗13号的"
# model=model.to("cpu")
# print("该文本的类别是:%s"%label_name[predict(ex_text_str,text_pipeline)])
以上是文本识别基本代码
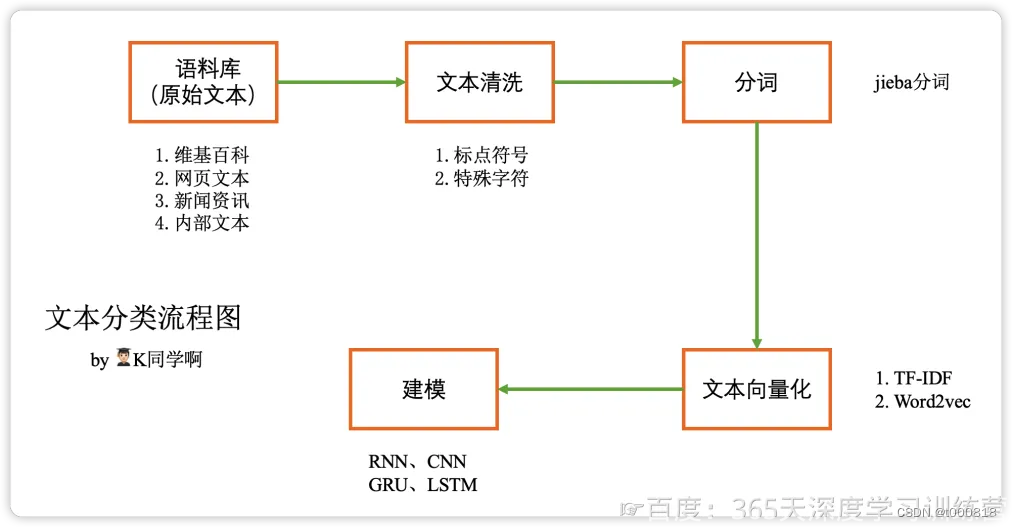
输出:
[[-0.85472693 0.96605204 1.5058695 -0.06065784 -2.10079319 -0.12021151
1.41170089 2.00004494 0.90861696 -0.62710127 -0.62408304 -3.80595499
1.02797993 -0.45584389 0.54715634 1.70490362 2.33389823 -1.99607518
4.34822938 -0.76296186 2.73265275 -1.15046433 0.82106878 -0.32701646
-0.50515595 -0.37742117 -2.02331601 -1.365334 1.48786476 -1.6394971
1.59438308 2.23569647 -0.00500725 -0.65070192 0.07377997 0.01777986
-1.35580809 3.82080549 -2.19764423 1.06595343 0.99296588 0.58972518
-0.33535255 2.15471306 -0.52244038 1.00874437 1.28869729 -0.72208139
-2.81094289 2.2614549 0.20799019 -2.36187895 -0.94019454 0.49448857
-0.68613767 -0.79071895 0.47535057 -0.78339124 -0.71336574 -0.27931567
1.0514895 -1.76352624 1.93158554 -0.85853558 -0.65540617 1.3612217
-1.39405773 1.18187538 1.31730198 -0.02322496 0.14652854 0.22249881
2.01789951 -0.40144247 -0.39880068 -0.16220299 -2.85221207 -0.27722868
2.48236791 -0.51239379 -1.47679498 -0.28452797 -2.64497767 2.12093259
-1.2326943 -1.89571355 2.3295732 -0.53244872 -0.67313893 -0.80814604
0.86987564 -1.31373079 1.33797717 1.02223087 0.5817025 -0.83535647
0.97088164 2.09045361 -2.57758138 0.07126901]]
6输出结果并非为0